改进大语言模型的方法
原创

这是一篇关于适应开源大语言模型(LLMs)的三部系列博客的第一篇。本文探讨将LLM适应领域数据的各种方法。
- 第二部分讨论如何确定微调(fine-tuning)是否适合您的用例。
- 第三部分探讨策划良好训练数据集的一些经验法则。
0 引言
大语言模型(LLMs)在多种语言任务和自然语言处理(NLP)基准测试中展示了出色的能力。基于这些“通用”模型的产品应用正在增加。本文为小型AI产品团队提供指导,帮助他们将LLM适应并整合到他们的项目中。首先,澄清围绕LLM的(常常令人困惑的)术语,然后简要比较现有的不同适应方法,最后推荐一个逐步流程图,助你识别适合你的用例的方法。
1 适应LLM的方法
1.1 预训练
预训练是从头开始。
使用数万亿数据tokens训练LLM的过程。该模型使用自监督(self-supervised)算法进行训练。最常见的训练方式是通过自回归预测下一个token(又称因果语言建模)。预训练通常需要数千小时的GPU(105 – 107 [source1,source2]),并且分布在多个GPU上。预训练输出的模型被称为基础模型。
1.2 持续预训练
持续预训练(又称第二阶段预训练)涉及使用新的、未见过的领域数据对基础模型进行进一步训练。使用与初始预训练相同的自监督算法。通常所有模型权重都会参与其中,并且会将一部分原始数据与新数据混合进行训练。
1.3 微调(fine-tuning)
微调是使用带有注释的数据集以监督方式或使用基于强化学习的技术来适应预训练语言模型的过程。与预训练的主要区别:
- 使用带有正确标签/答案/偏好的带注释数据集进行监督训练,而不是自监督训练
- 所需tokens数量较少(成千上万或数百万,而预训练需要数十亿或数万亿),主要目的是增强如指令跟随、人类对齐、任务执行等能力
理解微调的当前格局可以从两个维度进行:改变的参数百分比以及微调结果带来的新功能。
1.4 改变的参数百分比
根据改变的参数数量,微调分为:
- 全量微调:顾名思义,它涵盖了模型的所有参数,包括像 XLMR 和 BERT(100 – 300M 参数)等小型模型上的传统微调,以及像Llama 2、GPT3(1B+ 参数)等大型模型上的微调
- 参数高效微调(PEFT):与微调所有LLM权重不同,PEFT算法只微调少量附加参数或更新预训练参数的子集,通常为1 – 6%的总参数
1.5 为基础模型添加的功能
微调的目的是为预训练模型添加功能,例如指令跟随、人类对齐等。Chat-tuned Llama 2是一个通过微调添加了指令跟随和对齐能力的模型示例。
1.6 检索增强生成(RAG)
企业也可以通过添加特定领域的知识库来适应LLM。RAG本质上是“基于搜索的LLM文本生成”。RAG使用一个根据用户问题检索到的动态提示上下文,并将其注入LLM提示中,从而引导其使用检索到的内容,而不是其预训练的(可能过时的)知识。Chat LangChain是一个基于RAG的LangChain文档问答聊天机器人。
1.7 上下文学习(ICL)
在ICL中,通过在提示中放置示例来适应LLM。研究表明,通过示例进行演示是有效的。示例可以包含不同种类的信息:
还有多种修改提示的策略,提示工程指南中提供了详细的概述。
2 选择正确的适应方法
为了确定上述方法中的哪一种适合特定应用,应考虑各种因素:所需的模型能力、训练成本、推理成本、数据集类型等。以下流程图总结了如何选择合适的LLM适应方法:
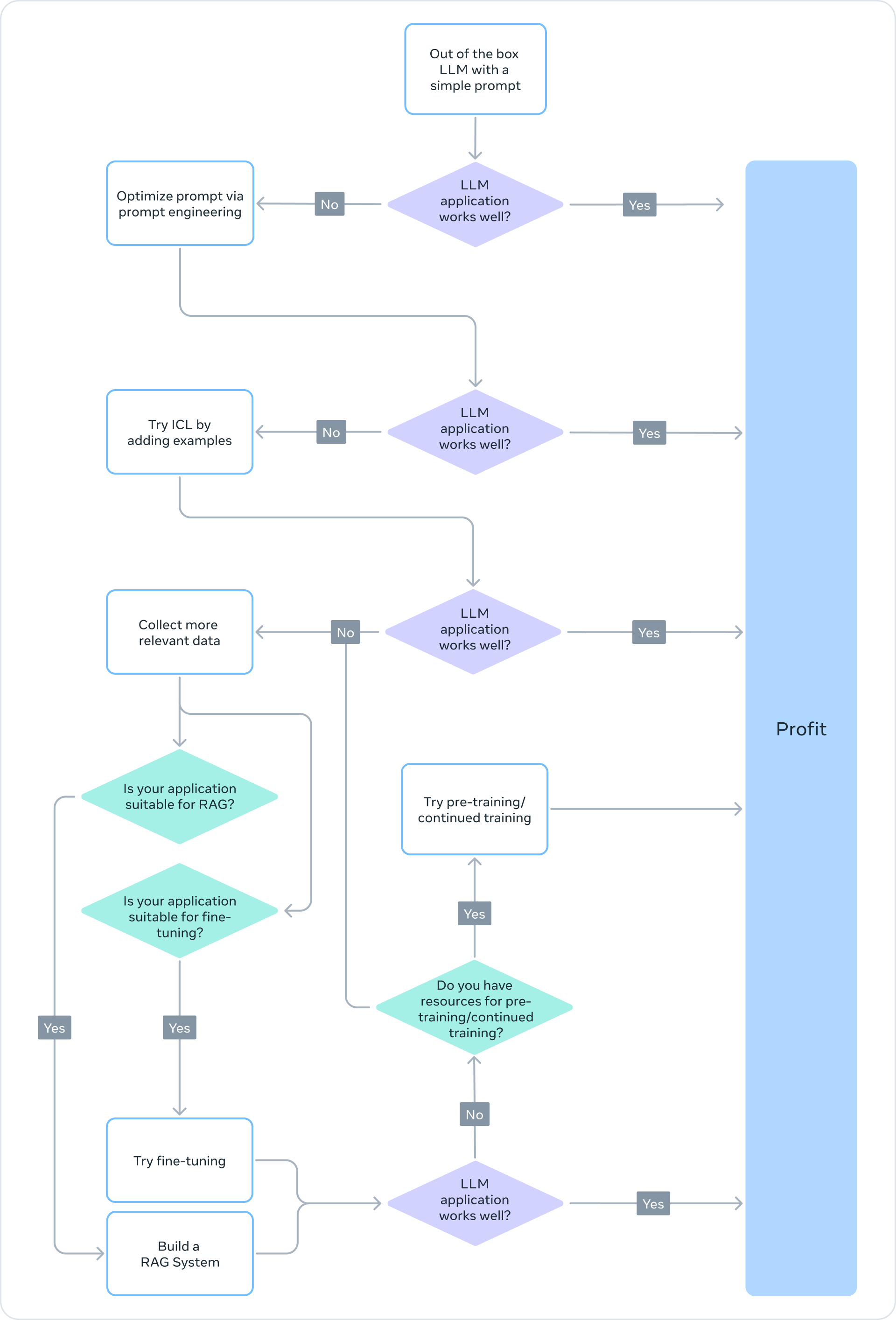
3 总结
创建基于LLM的系统是一个迭代过程。建议从简单的方法开始,并逐步增加复杂性,直到实现目标。上面的流程图为你的LLM适应策略提供了坚实的基础。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号