Spark重要知识汇总
原创
Spark重要知识汇总
原创
Lansonli
发布于 2024-08-02 16:46:03
发布于 2024-08-02 16:46:03
Spark重要知识汇总
一、Spark 是什么
大规模数据处理的统一分析引擎,也可说是分布式内存迭代计算框架。
二、Spark 四大特点
- 速度快(内存计算)
- 易于使用(支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语言)
- 通用性强(提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库)
- 运行方式多(包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark 2.3开始支持)上)
三、Spark框架模块介绍
- Spark Core(实现了 Spark 的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。数据结构:RDD)
- Spark SQL(可以使用 SQL操作数据。数据结构:Dataset/DataFrame = RDD + Schema)
- Spark Streaming(用来操作数据流的 API。 数据结构:DStream = Seq[RDD])
- Spark MLlib(提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。 数据结构:RDD或者DataFrame)
- Spark GraphX(用于图计算的API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。数据结构:RDD或者DataFrame)
- Structured Streaming(结构化流处理模块,针对流式结构化数据封装到DataFrame中进行分析)
3.1、Spark Core的RDD详解
3.1.1、什么是RDD
RDD(Resilient Distributed Dataset)弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
3.1.2、RDD是怎么理解的
1、概念:RDD是弹性分布式数据集(Resilient Distributed Dataset)
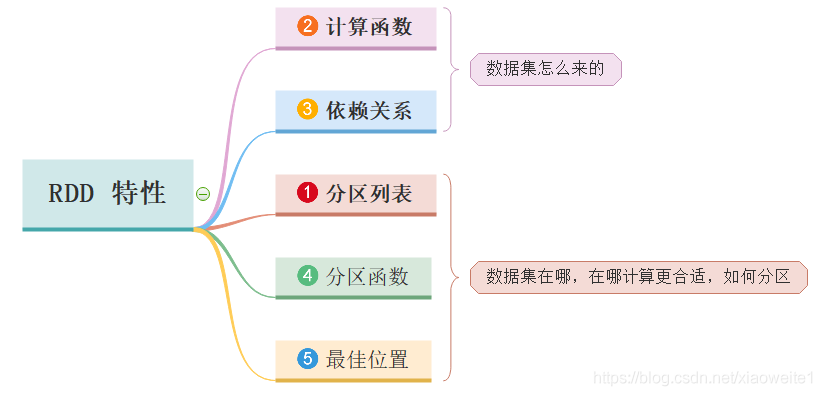
2、RDD有五大特性:
分区列表(A List of Partitions)
- 一组分片(Partition)/一个分区(Partition)列表,即数据集的基本组成单位。
- 对于RDD来说,每个分片都会被一个计算任务处理,分片数决定并行度。
- 用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。
计算函数(A Function for Computing Each Partition)
- 一个函数会被作用在每一个分区。
- Spark中RDD的计算是以分片为单位的,compute函数会被作用到每个分区上。
依赖关系(Lineage/Dependency)
- 一个RDD会依赖于其他多个RDD。
- RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算(Spark的容错机制)。
分区函数(Partitioner for Key-Value RDDs,可选)
- 可选项,对于KeyValue类型的RDD会有一个Partitioner,即RDD的分区函数。
- 当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。
- 只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。
- Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
- 对key-value的类型RDD的默认分区HashPartitoner。
位置优先性(Location Preference,可选)
- 可选项,一个列表,存储存取每个Partition的优先位置(preferred location)。
- 对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。
- 按照"移动数据不如移动计算"的理念,Spark在进行任务调度的时候,会尽可能选择那些存有数据的worker节点来进行任务计算。(数据本地性)
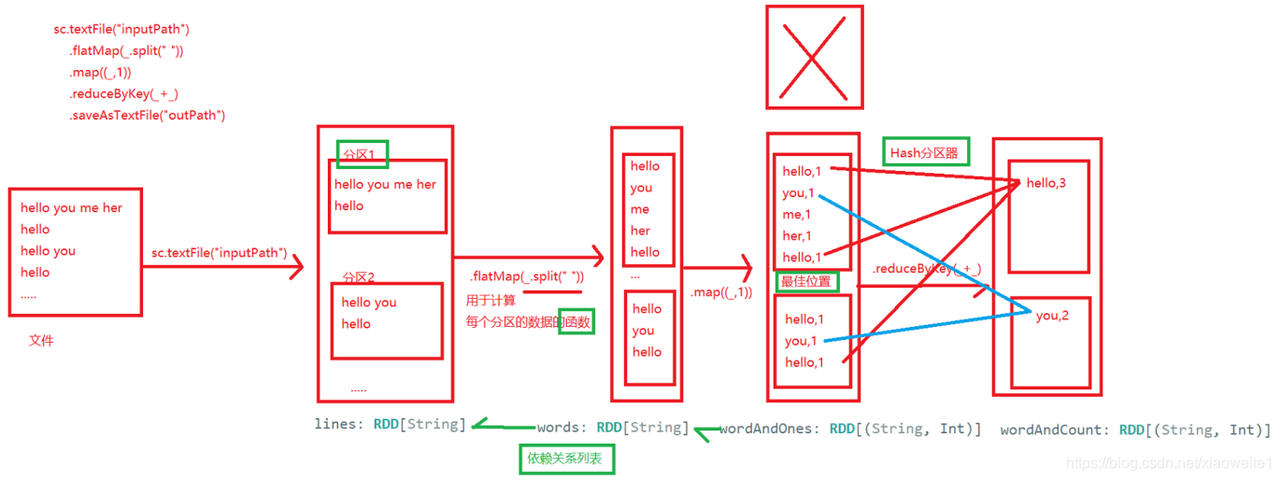
WordCount中RDD
sc.textFile().flatmap().map().reduceByKey()在内部,每个RDD都有五个主要特性:
- 分区列表:每个RDD都有会分区的概念,类似于HDFS的分块, 分区的目的:提高并行度。
- 用于计算每个分区的函数:用函数来操作各个分区中的数据。
- 对其他RDD的依赖列表:后面的RDD需要依赖前面的RDD。
- 可选地,键值RDDs的分区器。(例如,reduceByKey中的默认的Hash分区器)
- 可选地,计算每个分区的首选位置列表/最佳位置。(例如HDFS文件)
3、RDD的宽依赖和窄依赖:
窄依赖定义:
窄依赖指的是每一个父RDD的Partition(分区)最多被子RDD的一个Partition使用。这种依赖关系形象地比喻为“独生子女”,即一个父RDD的分区只对应一个子RDD的分区(或几个父RDD的分区对应一个子RDD的分区,但仍然是“一对一”的关系)。
特点:
- 高效执行:窄依赖支持在一个节点上管道化执行,例如,在filter之后可以直接执行map操作,无需移动数据。
- 快速容错:当子RDD的某个分区数据丢失时,只需要重新计算对应的父RDD分区即可,不需要重新计算整个RDD。
- 操作类型:常见的窄依赖操作包括map、filter、union(特定条件下)等。
宽依赖定义:
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition。这种依赖关系形象地比喻为“超生”,即一个父RDD的分区会被多个子RDD的分区所使用。
特点:
- Shuffle操作:宽依赖通常涉及Shuffle操作,即数据需要在不同节点间重新分布。Shuffle操作是耗时的,因为它涉及磁盘I/O、数据序列化和网络I/O。
- 低效容错:当子RDD的某个分区数据丢失时,由于宽依赖的特性,可能需要重新计算父RDD的所有分区才能恢复数据。
- 操作类型:常见的宽依赖操作包括groupByKey、reduceByKey、sortByKey、join(输入未协同划分)等。
注意:根据父RDD有一个或多个子RDD对应,因为窄依赖可以在任务间并行,宽依赖会发生Shuffle,并不是所有的bykey算子都会产生shuffle?需要注意的是(1)分区器一致(2)分区个数一致
4、RDD血缘关系linage:
linage会记录当前RDD依赖于上一个RDD,如果一个RDD失效可以重建RDD,容错关键。
RDD血缘关系的作用
- 容错机制:RDD血缘关系的主要作用是支持Spark的容错机制。由于RDD是不可变的,并且只支持粗粒度转换(即在大量记录上执行的单个操作),因此当RDD的某个分区数据丢失时,Spark可以根据血缘关系图重新计算丢失的数据分区,而无需重新计算整个RDD。
- 优化执行计划:Spark的执行引擎可以利用RDD血缘关系来优化作业的执行计划。例如,通过识别窄依赖和宽依赖,Spark可以决定如何切分作业为不同的阶段(Stages),并在不同的节点上并行执行这些阶段。
RDD的缓存:cache和persist,cache会将数据缓存在内存中,persist可以指定多种存储级别,cache底层调用的是persist。
- cache()方法:这是RDD缓存的简化形式,它等价于调用
persist(StorageLevel.MEMORY_ONLY)。即,将数据以未序列化的Java对象形式存储在JVM的堆内存中。 - persist()方法:这是一个更通用的方法,允许用户指定缓存的级别。通过传递一个
StorageLevel对象作为参数,用户可以控制数据是存储在内存中、磁盘上,还是两者都存储,以及是否进行序列化等。
缓存级别
Spark提供了以下几种缓存级别(StorageLevel):
- MEMORY_ONLY:将RDD以未序列化的Java对象形式存储在JVM的堆内存中。如果内存不足,则某些分区可能不会被缓存,而是会在需要时重新计算。
- MEMORY_AND_DISK:将RDD以未序列化的Java对象形式存储在JVM的堆内存中。如果内存不足,则将未缓存的分区存储在磁盘上。
- MEMORY_ONLY_SER:将RDD以序列化的Java对象形式存储(每个分区为一个字节数组)。这种方式比未序列化的对象更节省空间,但读取时会增加CPU的负担。
- MEMORY_AND_DISK_SER:类似于MEMORY_ONLY_SER,但如果内存不足,则将溢出的分区存储在磁盘上。
- DISK_ONLY:将RDD仅存储在磁盘上。
- OFF_HEAP:将数据存储在堆外内存中,这通常涉及额外的配置和可能的内存管理问题。
5、RDD的检查点机制:
Checkpoint会截断所有的血缘关系,而缓存会将血缘的关系全部保存在内存或磁盘中。
5.1、检查点机制的基本概念
检查点机制允许用户将RDD的中间结果持久化到可靠的文件系统(如HDFS)中,以便在出现节点故障或数据丢失时,能够快速地恢复RDD的状态,而不需要重新计算整个RDD的依赖链。这可以大大减少数据恢复的时间和计算资源的消耗。
5.2、检查点机制的工作流程
- 设置检查点目录:首先,需要使用
SparkContext的setCheckpointDir()方法设置一个检查点目录,该目录用于存储检查点数据。这个目录应该是可靠的文件系统,如HDFS。 - 标记RDD为检查点:然后,使用需要持久化的RDD的
checkpoint()方法将该RDD标记为检查点。此时,并不会立即执行检查点操作,而是会在遇到第一个行动操作(如collect()、count()等)时触发。 - 执行检查点操作:当遇到第一个行动操作时,Spark会启动一个新的作业来计算被标记为检查点的RDD,并将其结果写入之前设置的检查点目录中。同时,Spark会移除该RDD的所有依赖关系,因为在未来需要恢复该RDD时,可以直接从检查点目录中读取数据,而不需要重新计算依赖链。
- 数据恢复:如果在后续的计算过程中出现了节点故障或数据丢失,Spark可以根据需要从检查点目录中恢复RDD的状态,从而继续执行后续的计算任务。
5.3、检查点机制的优点
- 提高容错性:通过将RDD的中间结果持久化到可靠的文件系统中,可以在出现节点故障或数据丢失时快速恢复RDD的状态,从而提高Spark作业的容错性。
- 减少计算开销:在宽依赖的RDD上设置检查点可以显著减少计算开销,因为当需要恢复宽依赖的RDD时,只需要重新计算从检查点开始的部分,而不是整个RDD的依赖链。
- 优化性能:通过将经常使用的RDD持久化到外部存储中,可以避免在多次计算中重复计算相同的RDD,从而优化Spark作业的性能。
四、Spark 运行模式
- 本地模式-Local Mode(Task运行在一个本地JVM Process进程中,通常开发测试使用)
- 集群模式-Cluster Mode(Hadoop YARN集群,Spark 自身集群Standalone及Apache Mesos集群)
- Kubernetes 云服务模式-Cloud(AWS 阿里云 腾讯云 等等云平台都提供了 EMR产品)
4.1、Spark本地模式介绍
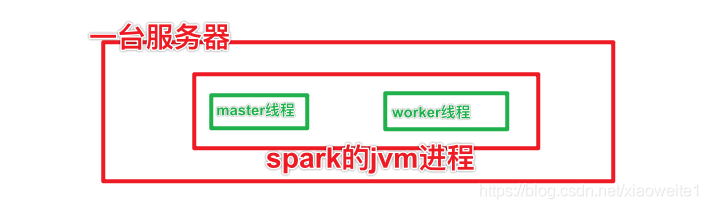
两类角色:
一个是Master类似Namenode做管理
一个是Worker类似DataNode是干活的
Local模式就是,以一个JVM进程,去模拟整个Spark的运行环境,就是讲Master和Worker角色以线程的形式运行在这个进程中。
WEB UI监控页面,默认端口号 4040
4.2、Spark集群模式 Standalone
Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理
两个角色:master和worker
架构:
Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。
WEB UI页面 8080
SparkContext web UI 4040
Master的IP和提交任务的通信端口 7077
4.3、Spark集群模式 Standalone HA
高可用HA
文件系统的单点恢复(Single-Node Recovery with Local File System)只能用于开发或测试环境
基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)可以用于生产环境
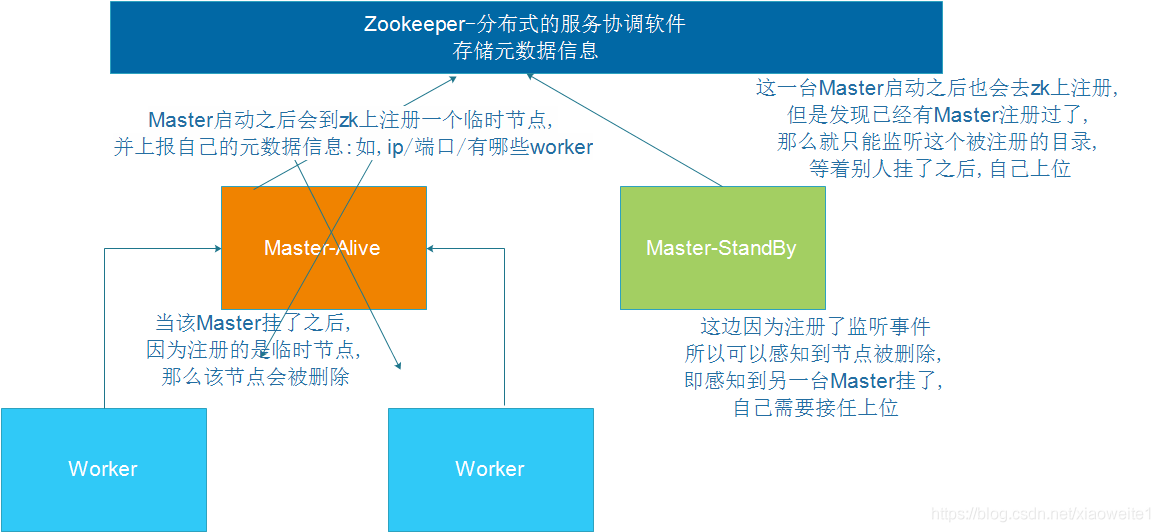
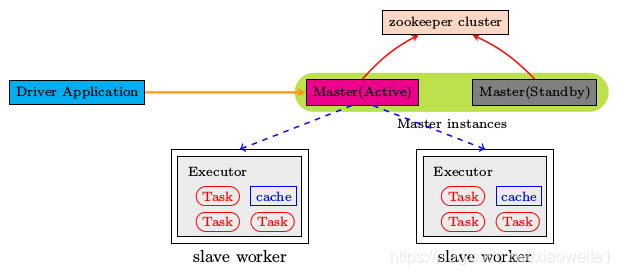
4.4、Spark集群模式 Spark on YARN介绍
Spark运行在YARN上是有2个模式的, 1个叫 Client模式 一个叫Cluster模式
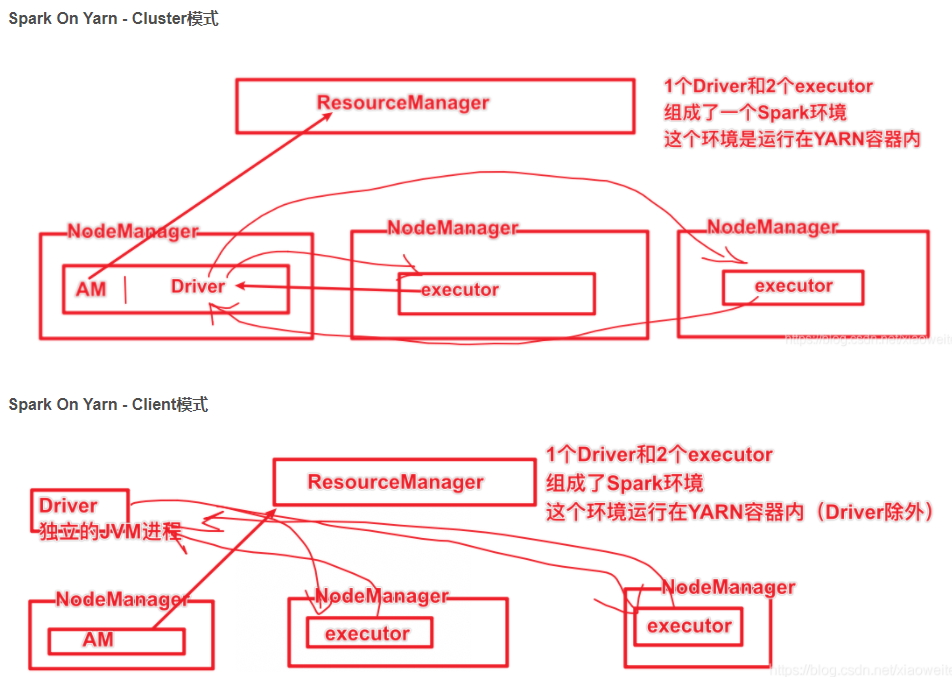
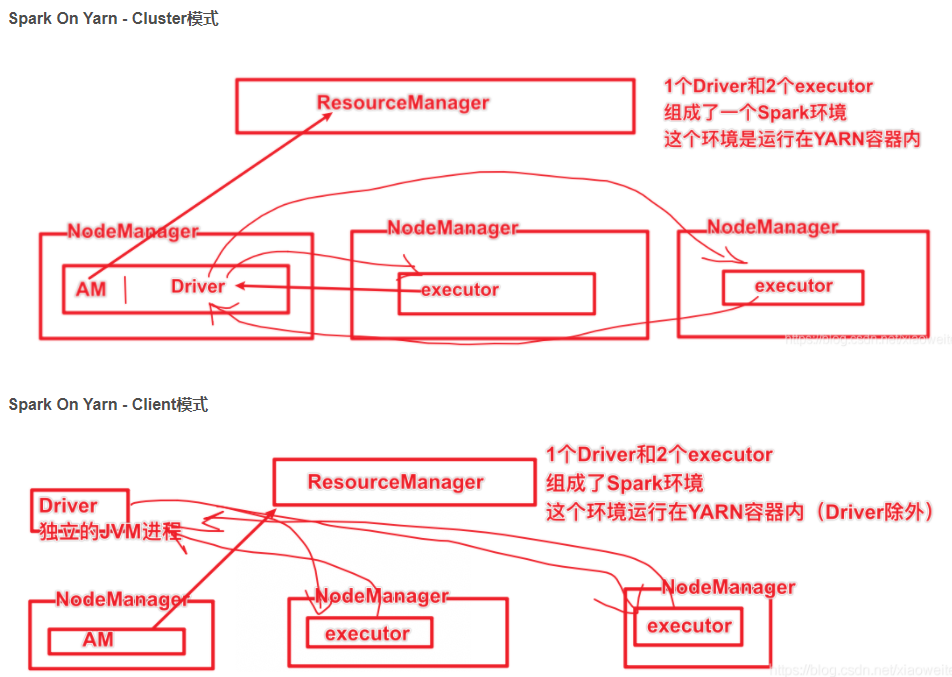
Spark HistoryServer服务WEB UI页面端口 18080
总结:
Spark On Yarn 不需要搭建Spark集群,只需要:Yarn+单机版Spark,当然还要一些配置。
4.5、Spark On Yarn两种模式总结
cluster和client模式最最本质的区别是:Driver程序运行在哪里
而Driver程序运行的位置可以通过--deploy-mode 来指定
企业实际生产环境中使用cluster
client 模式
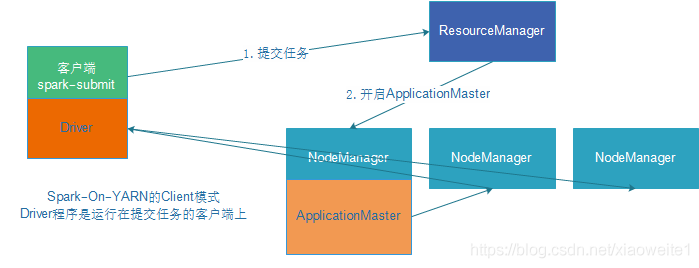
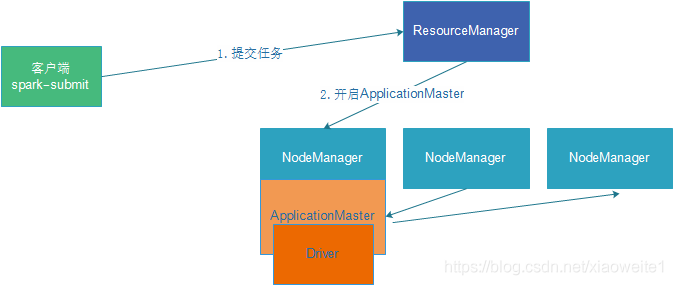
cluster 模式
Client模式:学习测试时使用,开发不用,了解即可
- Driver运行在Client上,和集群的通信成本高
- Driver输出结果会在客户端显示
Cluster模式:生产环境中使用该模式
- Driver程序在Yarn集群中,和集群的通信成本低
- Driver输出结果不能在客户端显示
- 该模式下Driver运行ApplicattionMaster这个节点上,由Yarn管理,如果出现问题,Yarn会重启ApplicattionMaster(Driver)
五、Spark应用架构基本介绍
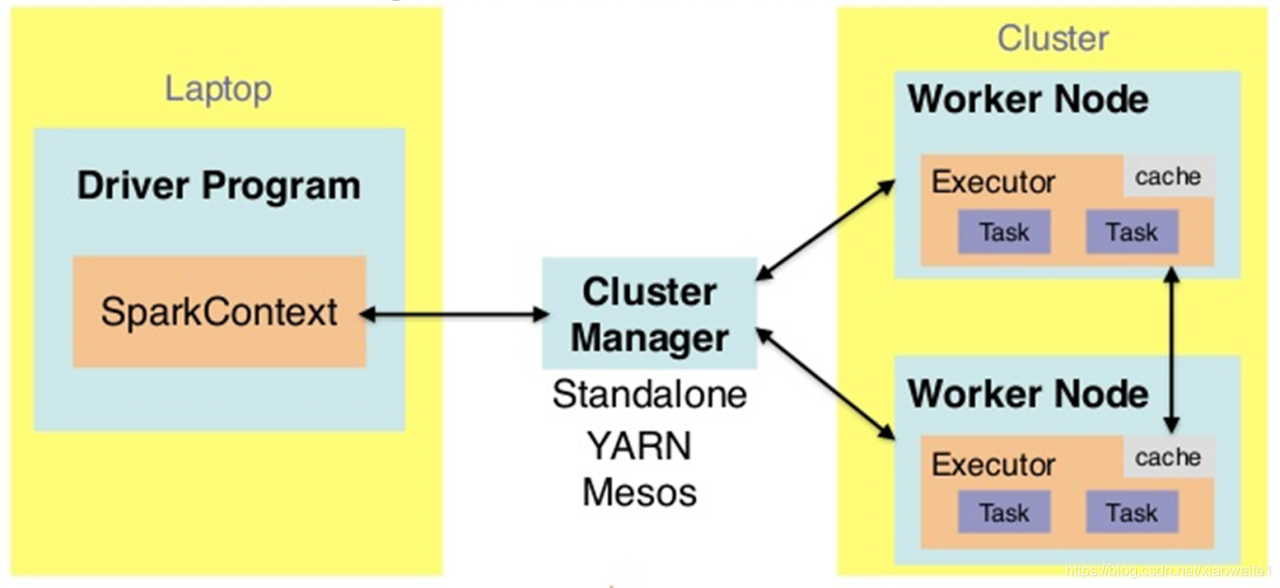
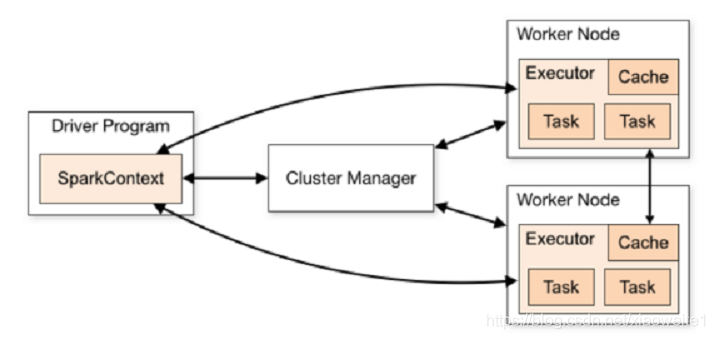
用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
- 用户程序创建 SparkContext 时,新创建的 SparkContext 实例会连接到 ClusterManager。 Cluster Manager 会根据用户提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动 Executor。
- Driver会将用户程序划分为不同的执行阶段Stage,每个执行阶段Stage由一组完全相同Task组成,这些Task分别作用于待处理数据的不同分区。在阶段划分完成和Task创建后, Driver会向Executor发送 Task。
- Executor在接收到Task后,会下载Task的运行时依赖,在准备好Task的执行环境后,会开始执行Task,并且将Task的运行状态汇报给Driver。
- Driver会根据收到的Task的运行状态来处理不同的状态更新。 Task分为两种:一种是Shuffle Map Task,它实现数据的重新洗牌,洗牌的结果保存到Executor 所在节点的文件系统中;另外一种是Result Task,它负责生成结果数据;
- Driver 会不断地调用Task,将Task发送到Executor执行,在所有的Task 都正确执行或者超过执行次数的限制仍然没有执行成功时停止。
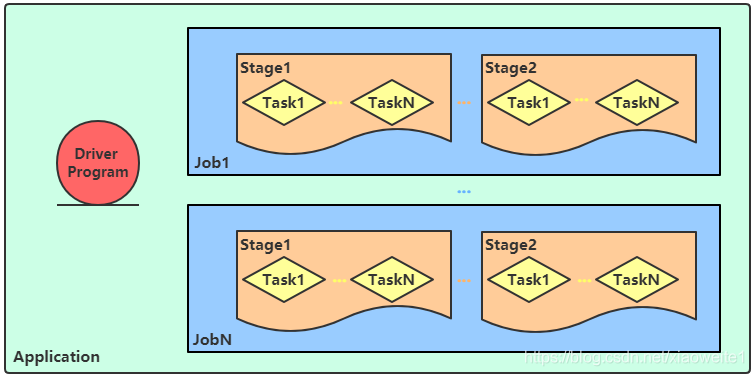
Job、DAG和Stage:
一个Spark Application中,包含多个Job,每个Job有多个Stage组成,每个Job执行按照DAG图进行的,其中每个Stage中包含多个Task任务,每个Task以线程Thread方式执行,需要1Core CPU。
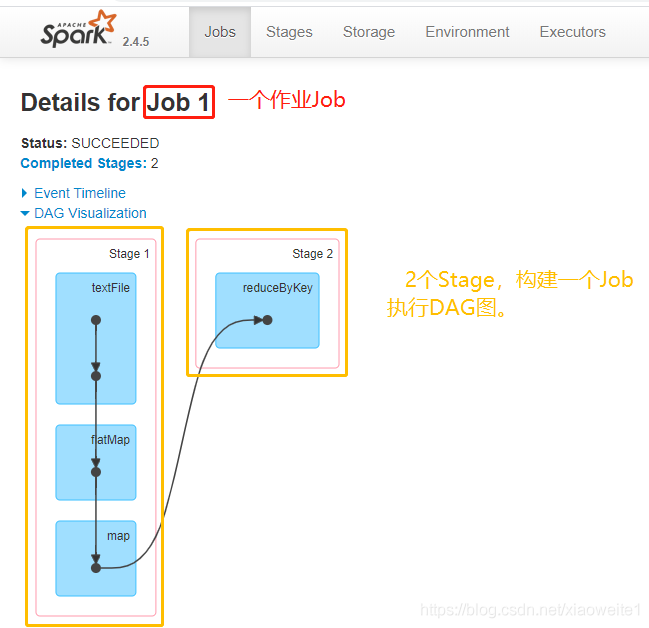
Spark Application程序运行时三个核心概念:Job、Stage、Task,说明如下:
Task:被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一般来说有多少个 Paritition,就会有多少个 Task,每个 Task 只会处理单一分支上的数据。
Job:由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect),会生成一个 Job。
Stage:Job 的组成单位,一个 Job 会切分成多个 Stage,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多个 Task 的集合,类似 map 和 reduce stage。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号