「EMR 开发指南」之 Hue 配置工作流
原创

说明
本文描述问题及解决方法同样适用于 弹性 MapReduce(EMR)。
概述
本文将通过一个简单,并且具有典型代表的例子,描述如何使用EMR产品中的Hue组件创建工作流,并使该工作流每天定时执行。
进入Hue控制台
为了使用HUE组件管理工作流,请先登录HUE控制台页面,具体步骤如下:
1) 登录腾讯官网控制台 2) 进入EMR控制页面,点击左侧组件管理页面
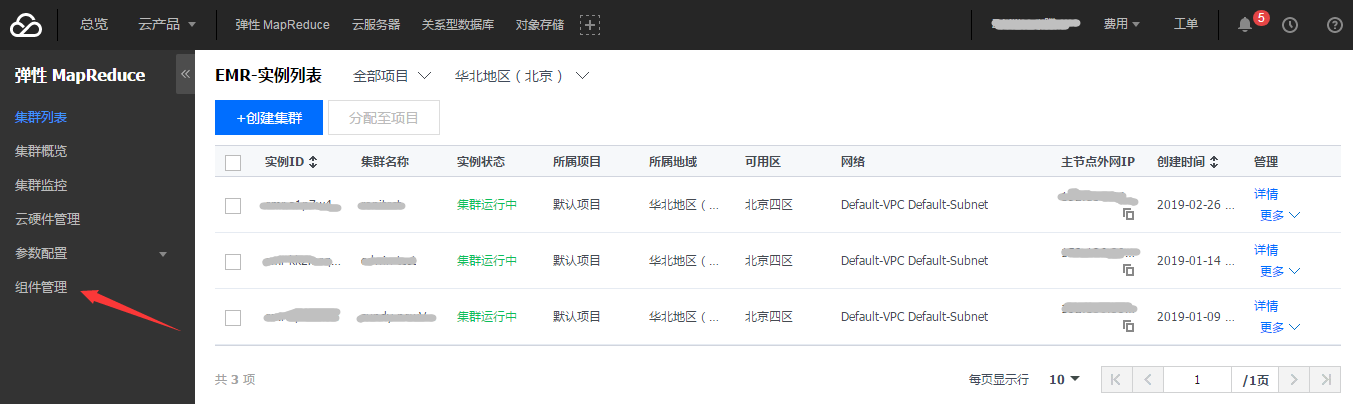
3) 找到Hue组件,点击“原生WebUI访问地址”进入Hue页面
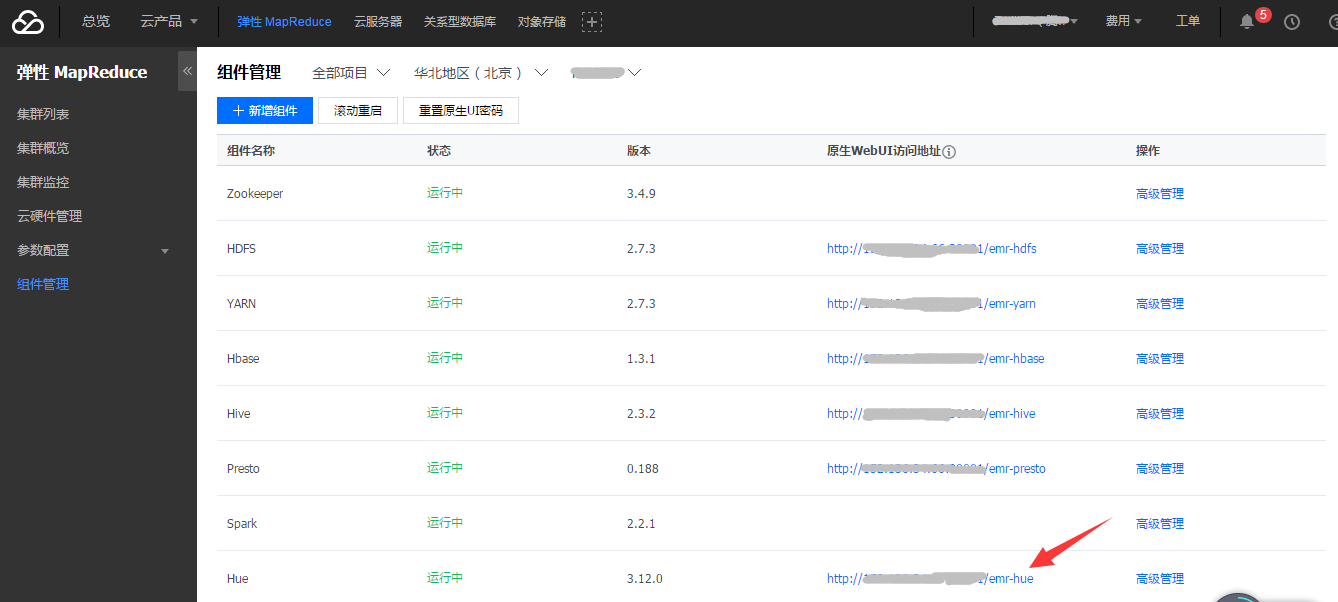
4) 首次登陆HUE控制台页面,请使用root账号,密码为创建集群时候提供的密码。
注意:由于EMR产品的组件启动账号为hadoop。请在首次以root账号登录HUE控制台后,新建hadoop账户。后续所有作业通过hadoop账号来提交。

在HUE上创建Workflow
一个Workflow 包含多个作业。目前支持Hive, MR, Spark, Shell, Java 可执行程序等多种类型的作业。
本文设计一个简单的Workflow, 包含4种类型作业:Shell、MR、Spark、Hive. 作为例子,上述四个作业直接并无数据相互依赖。
登录Hue控制台页面,具体步骤见进入Hue控制台章节。
在菜单栏选择Workflows->Editors->Workflows 进入编辑Workflow页面, 点击Create按钮:

进入Workflows编辑页面后,给新建Workflow增加名字,以及描述:

点击图中(1) 填写Workflow名称,点击(2)填写该Workflow的描述。
我们创建一个名为hello-workflow的Workflow, 共包含4个作业:Shell类型作业、MR类型左右、Spark类型作业、HIVE类型作业。这些作业依次执行。
接下来,分别介绍不同类型作业创建过程。
创建Shell类型作业
Hue 可以提交Shell类型作业,事先将Shell脚本存放至HDFS中。
具体步骤如下:
1)在Workflow编辑页面中,选择Shell作业类型图标,用鼠标拖动到编辑区:
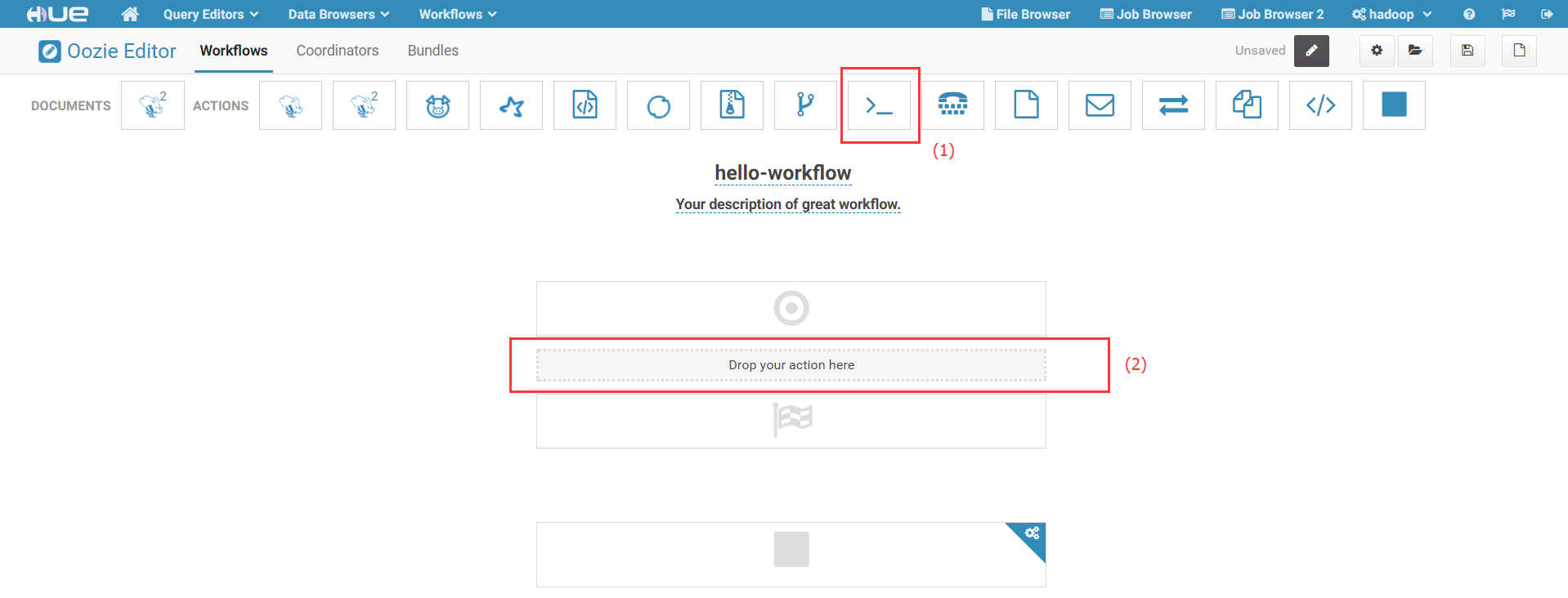
2)填写作业参数:
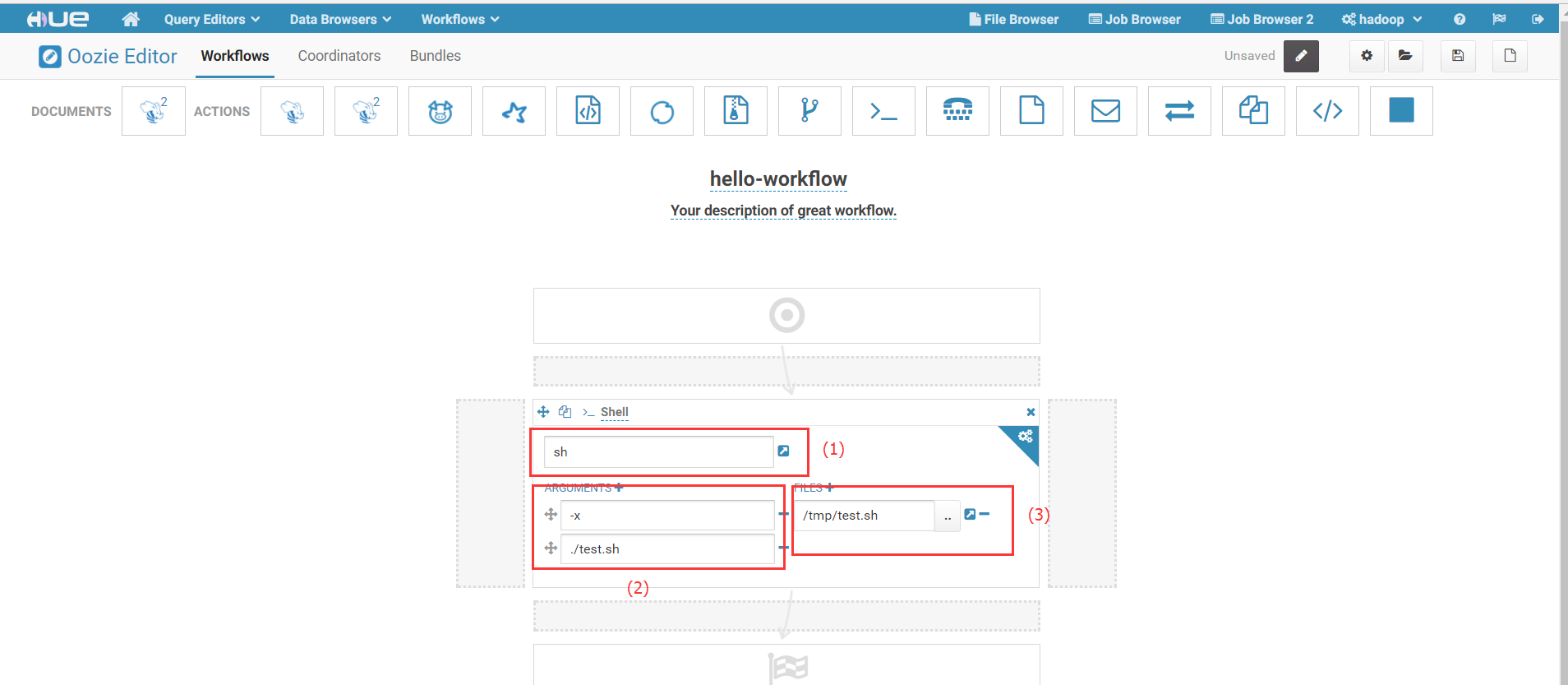
其中,(1)填写执行Shell脚本的命令,这里我们填写sh; (2)填写执行sh命令所需的参数;(3)填写脚本路径,注意是在HDFS上的路径。
3)点击右上角保存按钮,保存当前作业配置:
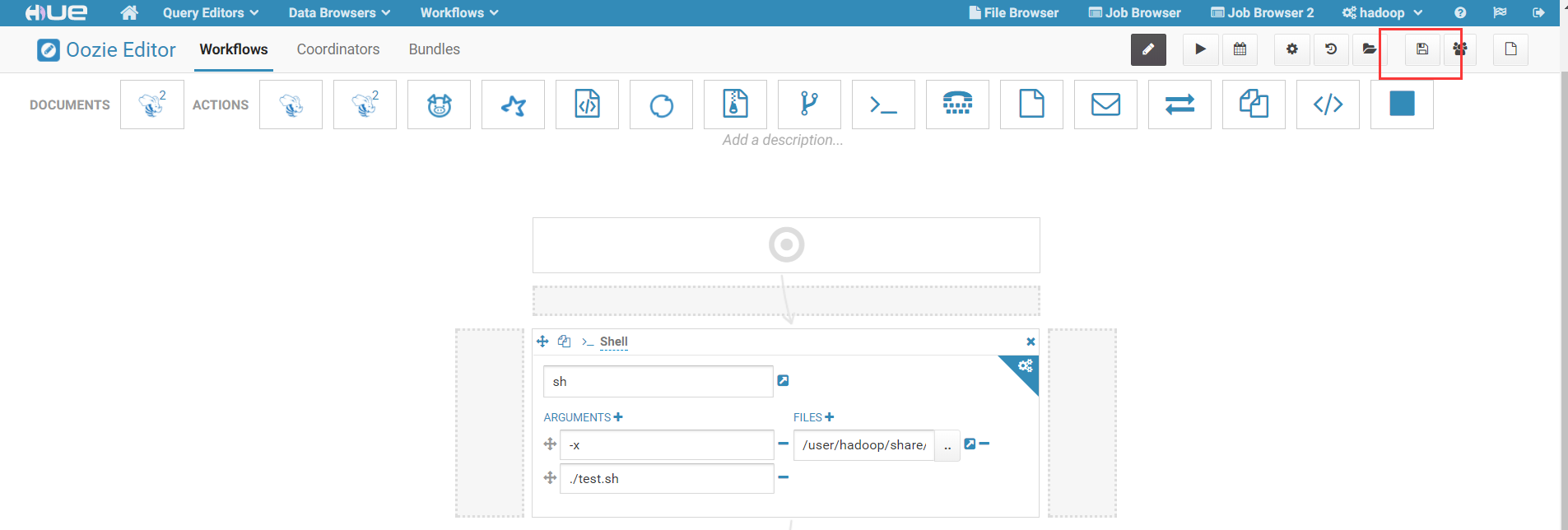
至此,我们已经在hello-workflow中增加了一个Shell类型的作业了。
创建MapReduce类型作业
在创建MapReduce类型作业前,我们需要把可执行Jar, 以及数据存放在HDFS上。
具体创建作业步骤如下:
1) 在Workflow编辑页面中,选择MapReduce作业类型图标,用鼠标拖动到编辑区:
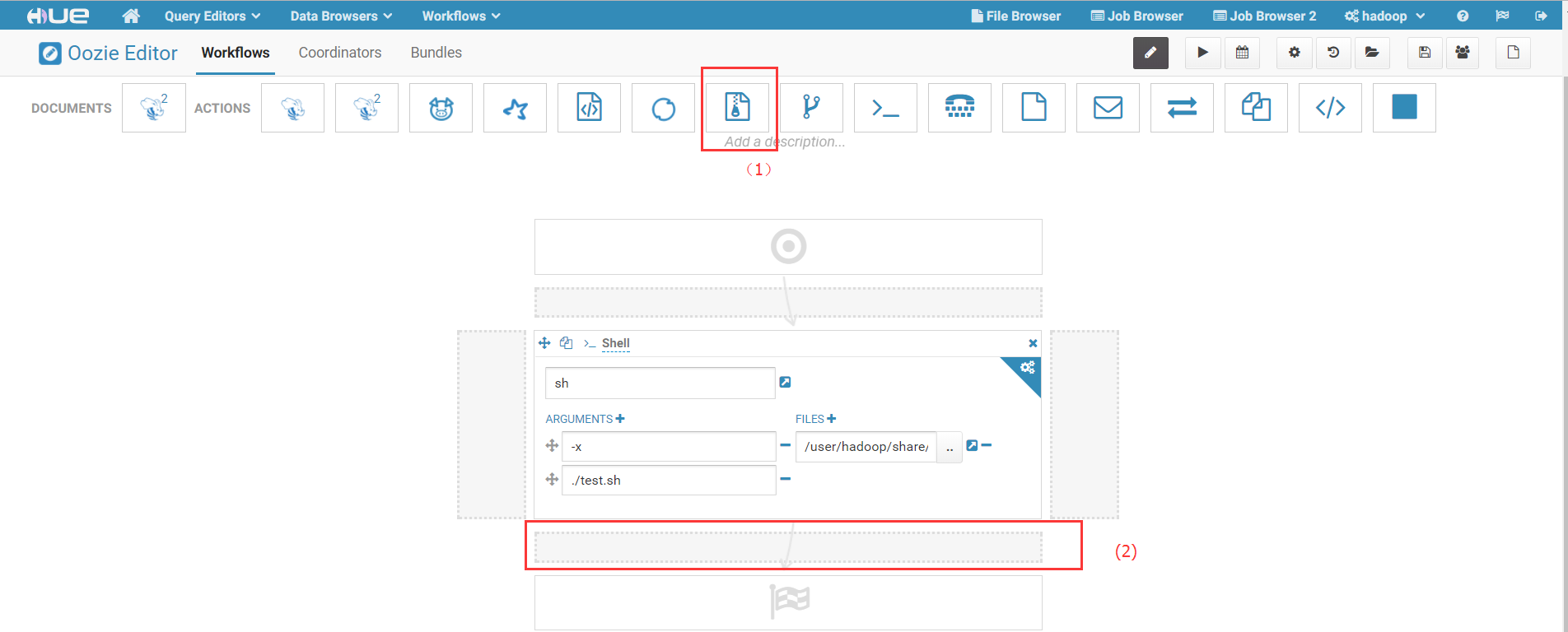
其中,(1)选择MapReduce类型作业;(2)使用鼠标将(1)处图标拖拽至(2)所在区域。
2) 填写Jar路径,注意是HDFS上的路径,填写作业参数:
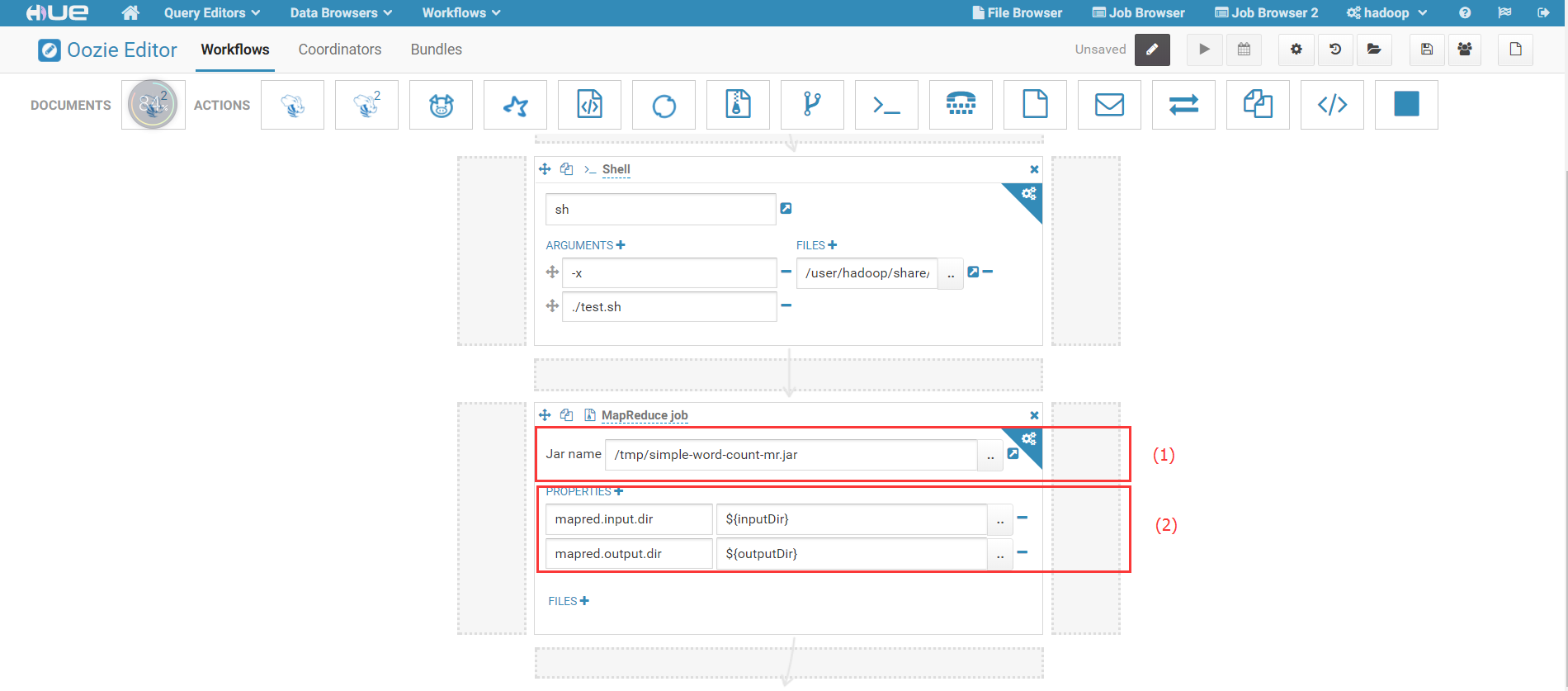
其中,(1)填写可执行Jar在HDFS中的路径;(2)填写Jar所需参数,在本例子中是数据输入和输出路径。
3) 点击右上角保存按钮,保存当前作业配置。 至此,我们在Hello-workflow中又增加了一个MR类型的作业。
创建HIVE类型作业
在创建Hive类型作业前,请确认EMR实例中已经部署了Hive组件,否则作业执行将失败。
具体步骤如下:
1)将要执行的Hive存放在HDFS中;在本例子中,我们将Hive脚本存放在HDFS的/tmp/simple-hive-query.sql;
2)拖拽Hive作业图标至Workflow编辑区;
3) 填写Hive脚本所在路径:
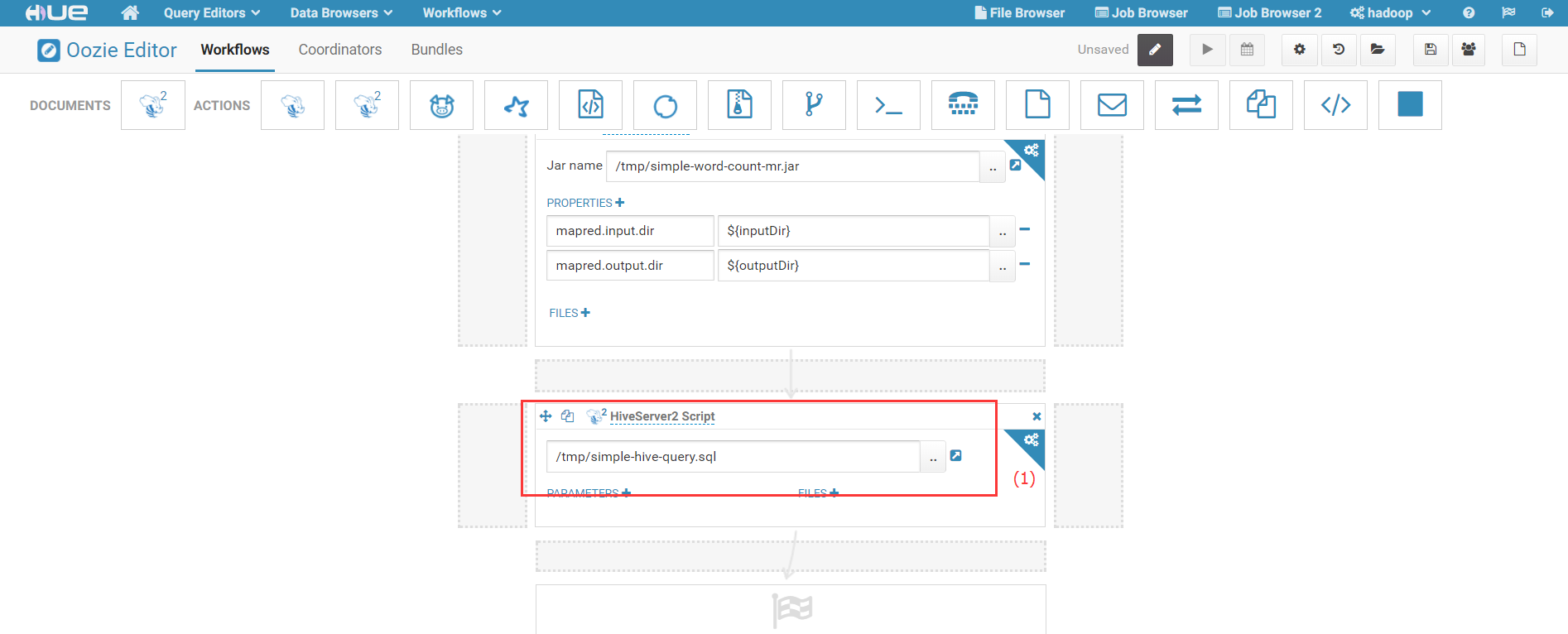
4)点击右上角保存按钮,保存作业配置。
创建Spark类型作业
在创建Spark作业前,请确认EMR实例中已经部署了Spark组件,否则作业将执行失败;
具体步骤如下:
1)将要执行的Spark作业可执行文件存放至HDFS中;在本例子中,我们将Spark作业可执行文件存放在HDFS的/tmp/spark-terasort-1.1-SNAPSHOT-jar-with-dependencies.jar
2) 将代表Spark类型作业的图片,用鼠标拖拽至Workflow编辑区:
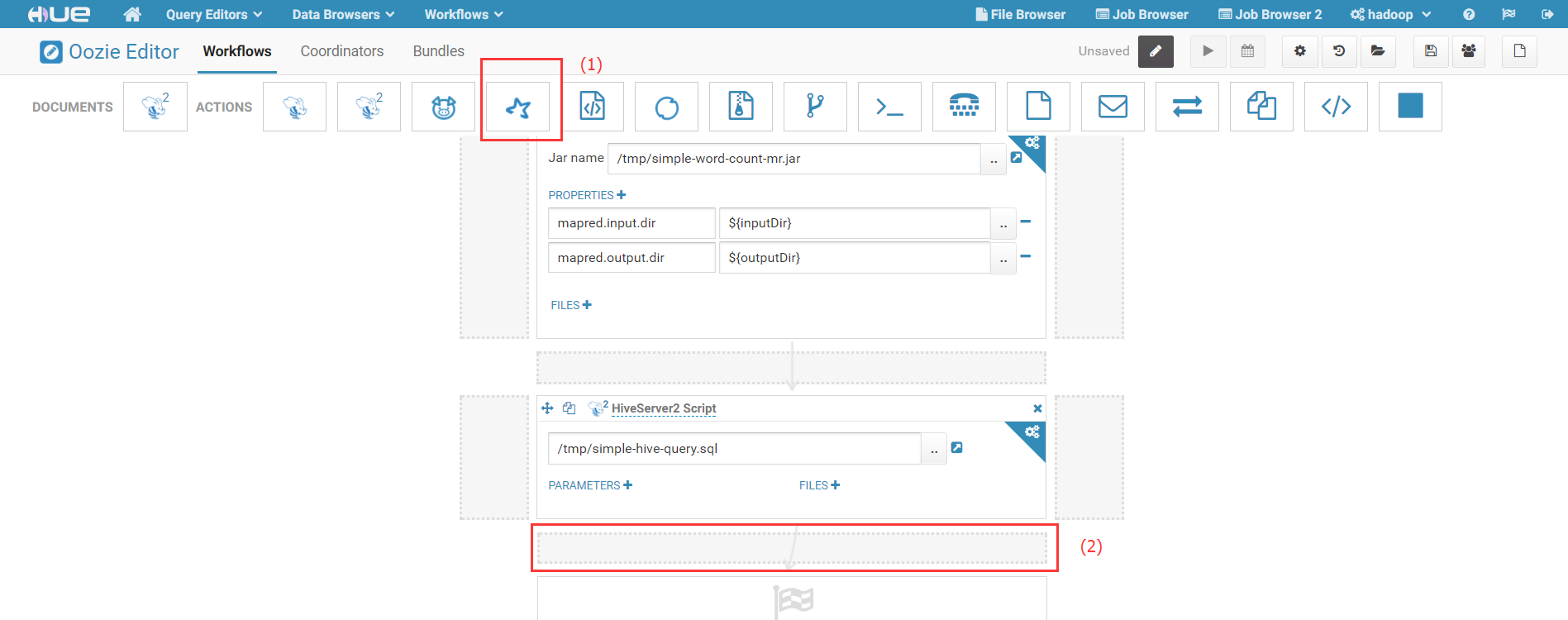
3)填写作业参数:
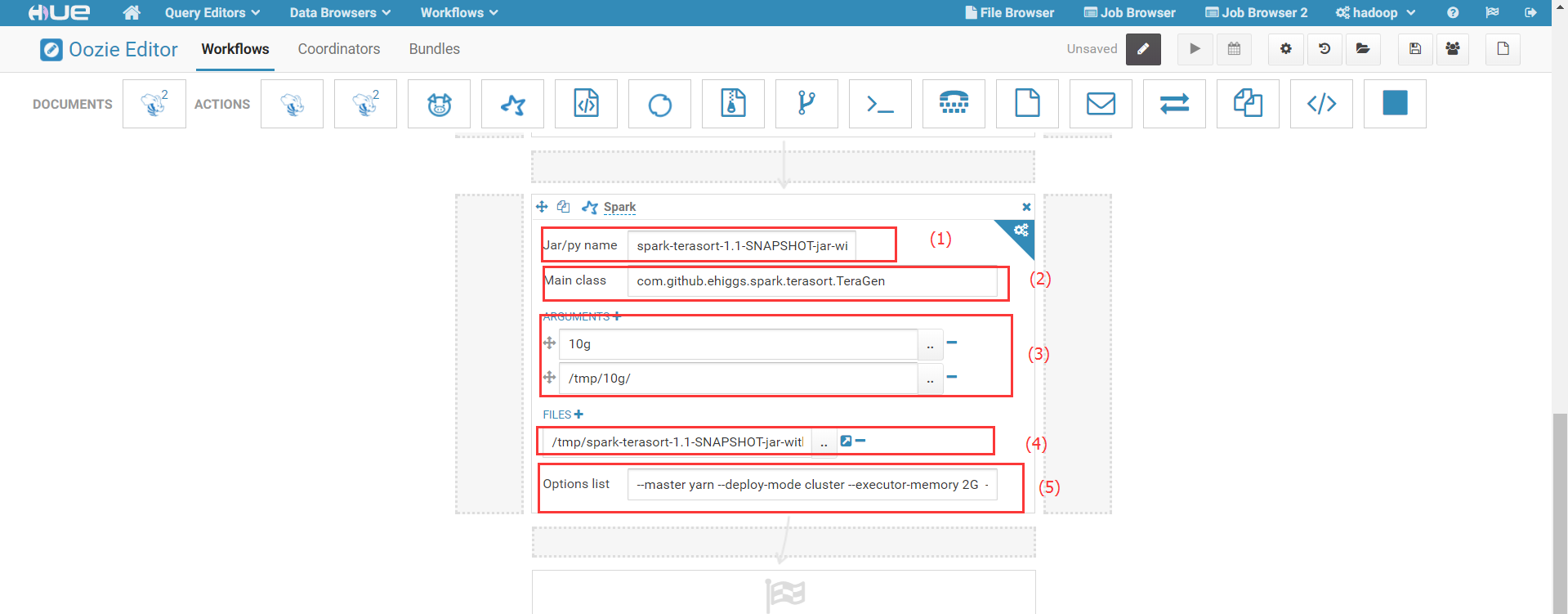
其中,(1)处填写可执行程序名称,本例中是Jar包名称;(2)填写Jar包的Main Class名称;(3)填写可执行程序所需参数,注意参数顺序与程序参数顺序一致;(4)填写可执行程序在HDFS中的路径;(5)填写Spark任务所需参数,本例中填写的为:--master yarn --deploy-mode cluster --executor-memory 2G --conf spark.default.parallelism=512
4)点击右上角保存按钮,保存作业配置。 至此,我们为hello-workflow 增加了Spark类型作业。
运行Workflow
对于创建完成的Workflow, 我们可以手工点击提交按钮,启动Workflow; 也可以配置定时调度方式执行。
当我编辑好Workflow,并保存后。该Workflow将展现在Workflows->Editors->Workflows 页面下的列表里。

手动触发Workflow运行
具体步骤如下:
1)选择将运行的Workflow, 点击Submit按钮:

2)配置Workflow中作业需要的参数。在我们的例子中,只有MapReduce类型作业需要2个参数:
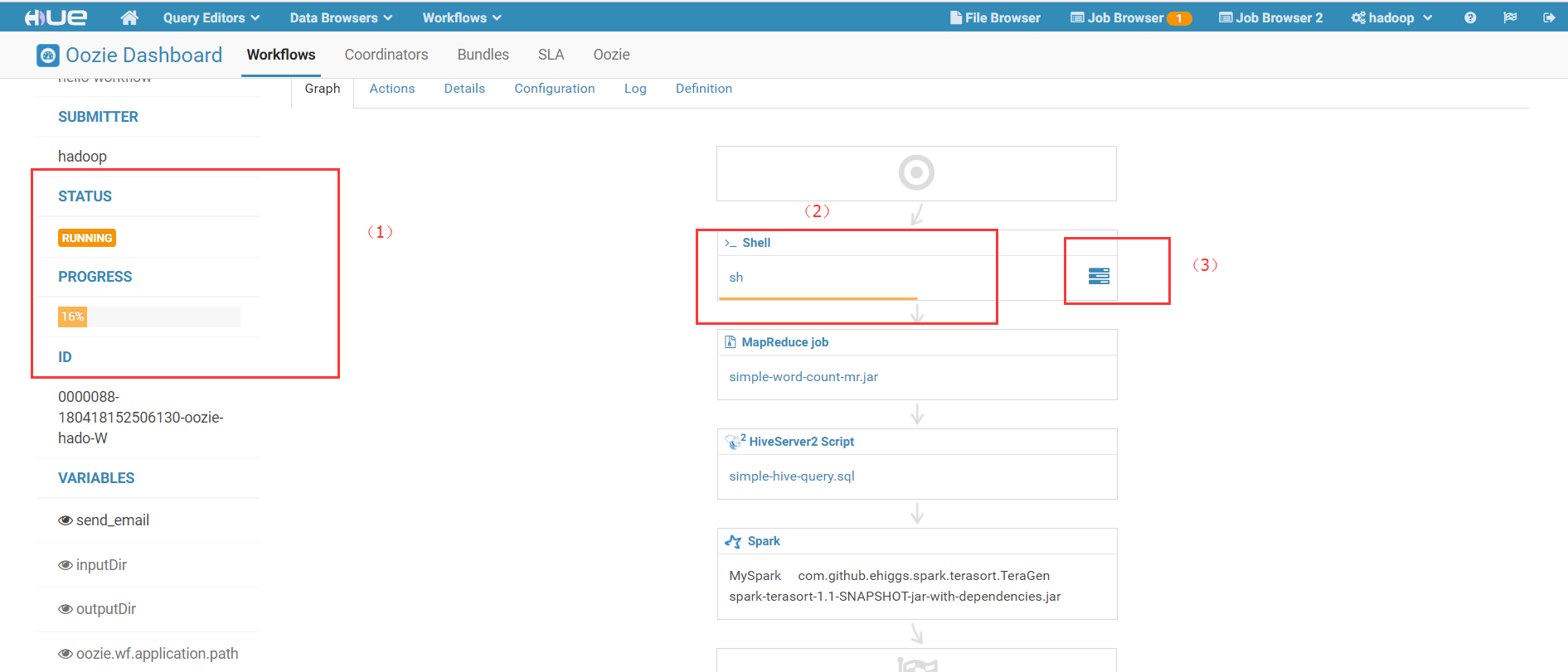
3)点击Submit按钮后,就可以提交Workflow,进入准备执行阶段:
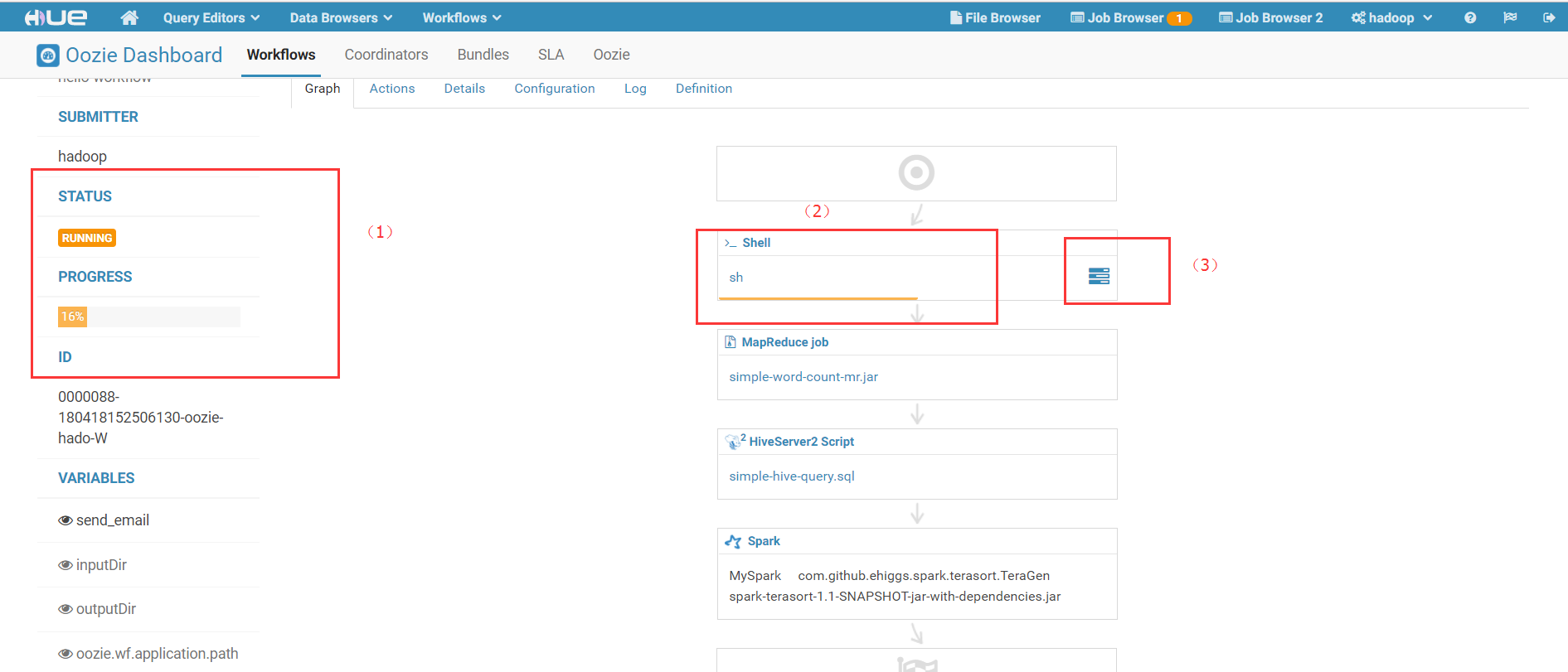
其中,(1)展示了Workflow整体执行状况,包括进度等信息;(2)展示了当前正在执行的作业的执行进度;(3)是产科作业执行日志的链接
4)查看作业执行结果:
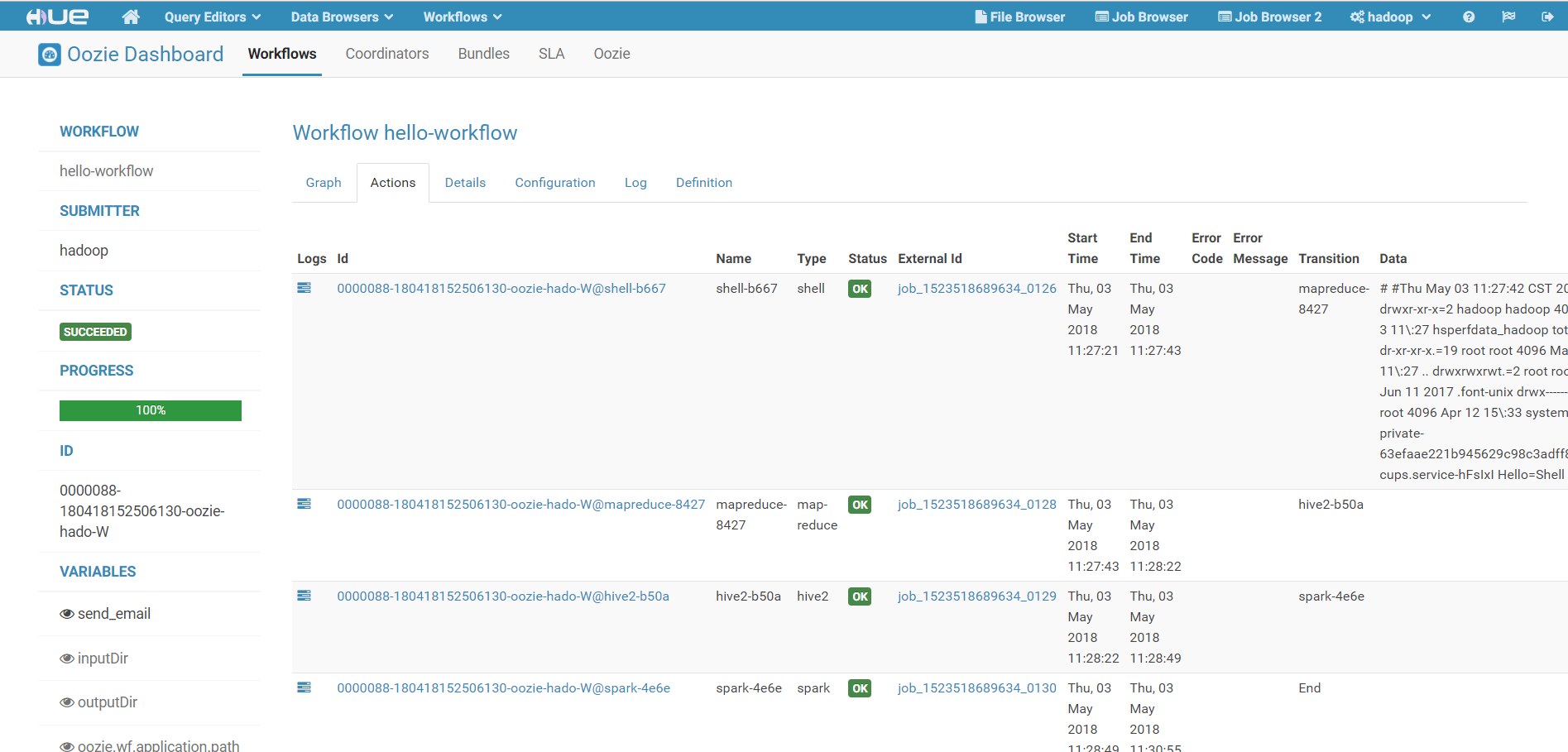
定时触发Workflow执行
使用Hue控制台,我们很方便配置定时执行的Workflow。Hue提供一个叫Coordinator的抽象,管理Workflow定时执行。我们需要借助控制台页面创建一个Coordinator来定时触发在之前创建的hello-workflow。 具体步骤如下:
1)点击Workflows->Editors->Coordinators,进入Coordinators Editor 页面:

2)填写Coordinator 名称,填写相应的描述,选择需要调度的Workflow, 设置调度时间:
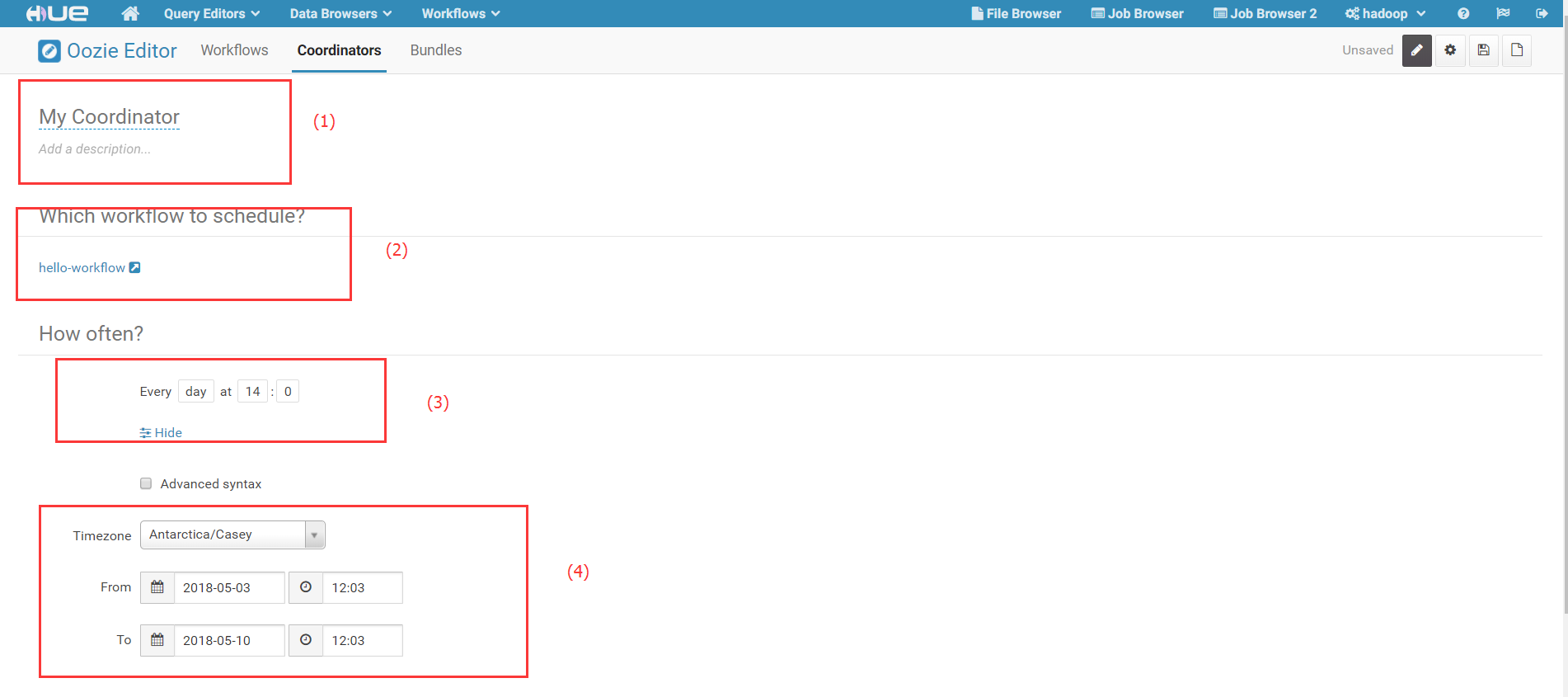
其中,(1)可以命名Coordinator 和 增加描述; (2)选择需要调度的Workflow; (3)设置调度周期;(4)可以设置时间区,设置开始时间和结束时间。
3)配置Workflow中作业需要的参数,通常这些参数包含HDFS上数据路径,以时间作为分区参数:
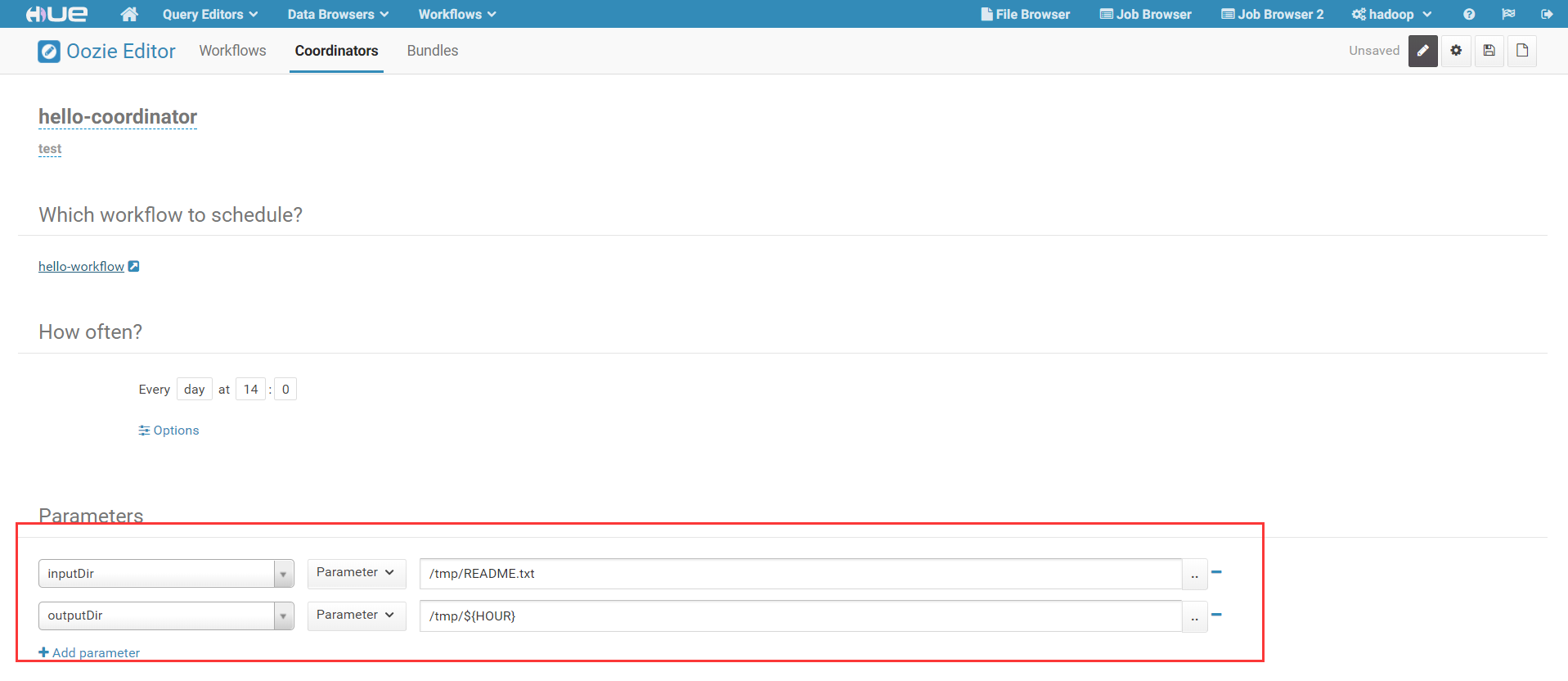
在我们的工作流的作业中,定义了两个变量,这里需要配置对应的变量值。
4)点击左下角“Save”按钮,保存配置; 5)最后在Coordinator Editor页面下的列表里,展示出该用户下所有的Coordinator。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号