大数据组件:Lucene全文索引与搜索
原创

背景介绍
Lucene是一款高性能、可扩展的信息检索工具库,是用于全文检索和搜寻的Java开放源码程序库,最初是由Doug Cutting所撰写,2000年发行了第一个开源版本,2005年成为Apache顶级项目。虽然经过近20年,Lucene在全文检索领域还是独领风骚,蓬勃发展。
优秀的搜索引擎需要复杂的架构和算法,用来支撑对海量数据的存储和搜索,并同时保证搜索质量。搜索引擎最重要的一个数据结构:倒排索引(Inverted Index)(实现单词->文档的存储形式),能高效实现全文搜索,并且索引数据是"一次检索,可多次搜索"。
Lucene的主要功能包括:
- 文档索引:用户基于原始文档,创建文档对象Document,Lucene将Document文档对象解析成Index索引文件并持久化到文件系统
- 搜索查询:用户传入查询语句,Lucene转成Query对象,基于Index索引文件搜索并汇总

Lucene仅提供检索工具包,不提供额外的检索应用功能,在Lucene之上构建的应用项目主要有:
- Apache Nutch:提供可扩展的开源Web爬虫应用
- Apache Solr:基于Lucene提供企业级搜索引擎,支持分布式部署
- Elasticsearch:基于Lucene提供企业级搜索引擎,支持分布式部署,并提供 Elastic Stack服务:包括数据采集、检索、展示、APM全链路跟踪
核心概念
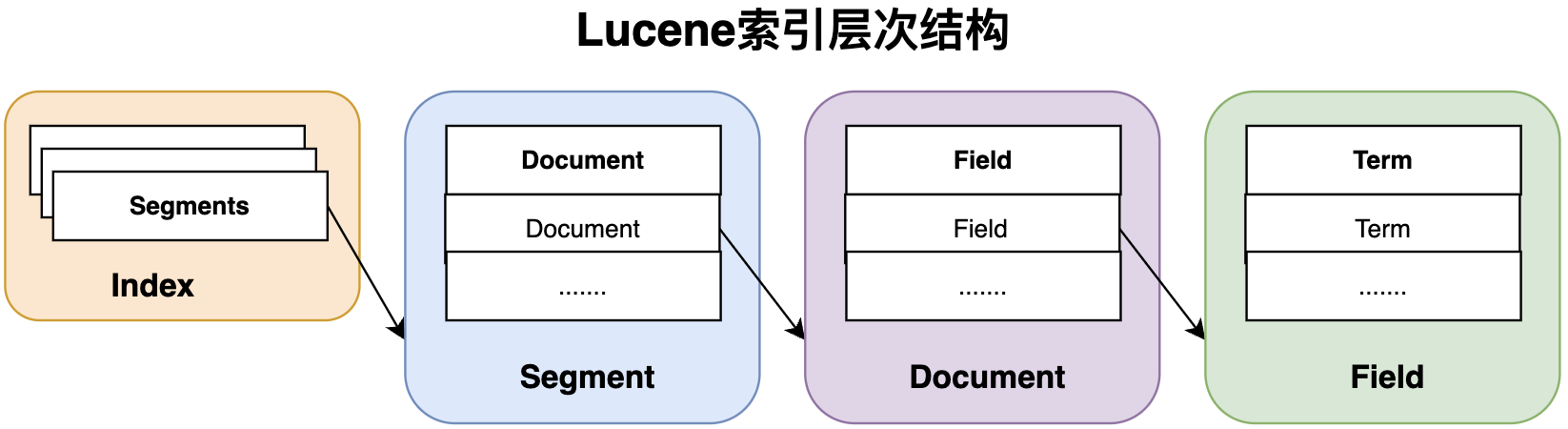
Lucene索引层级结构主要包括:Index(索引),Segment(索引段),Document(索引文档),Field(索引域),Term(索引项),它们之间关系如下:
Index
Index(索引):原始文档经过Lucene的索引流程后,以Index形式存储在文件系统,支持对保存的数据进行快速随机访问。 一个Index由多个Segment(索引段)构成,每个Segment包含多个Document(索引文件)。Index是逻辑概念,是一个索引目录下,所有索引文件的总和,可表示Document文档数据的集合,不同的Document数据结构,建议使用不同的Index。
Segment
Segment(索引段):每个Lucene Index包括多个Segment,每个Segment都是一个独立的索引,是整个Index索引的子集,因此在搜索时支持对每个Segment进行单独访问,最后对结果进行汇总。Segment是逻辑概念,是一系列索引文件的集合,属于同个Segment的索引文件具有相同的文件前缀,各个独立的索引文件组成索引的不同部分(存储Field、词向量、倒排索引等)。
索引流程中基于Segment的主要功能包括:
- 新增/更新Document会创建新的Segment;
- 刷新/合并已存在的Segment;
- 同个Segment下,不同索引文件合成;
Document
Document(索引文档):包含多个Field对象的集合容器,是Lucene索引和搜索的原子单元。Lucene基于Document Numbers(文档编号)对每个Document编号,初始变化为0,后续其编号依次增长1。
Field
Field(索引域):是Document的一部分,里面包含真正搜索的内容,每个Field包括三个部分:name(标识名称)、type(Field属性描述)、value。 Field被分词为Term对象进行索引保存。
Field常用的数据结构子类如下
类型 | 说明 |
|---|---|
IntPoint | 以int索引,只索引不存储,支持精确/range查询,基于KD-tree 加速range查询速度 |
LongPoint | 以long索引,其他同上 |
FloatPoint | 以float索引,其他同上 |
DoublePoint | 以double索引,其他同上 |
TextField | 可以Reader或String索引,索引并分词,主要用于全文索引 |
StringField | 以String索引,只索引不分词,直接以整个字符串作为一个分词 |
SortedDocValuesField | 以String索引并存储,用于排序(sorting)操作 |
SortedSetDocValuesField | 以String索引并存储,用于聚合(faceting)、分组(grouping)、关联(joining)操作 |
NumericDocValuesField | 以long索引并存储,用于评分、排序和值检索 |
SortedNumericDocValuesField | 与NumericDocValuesField,常用于搜索结果排序 |
StoredField | 存储Field值 |
Field中以FieldType定义索引的属性描述,包括以下内容:
- indexOptions:Field是否分词
- stored:Field是否存储
- tokenized:Field是否分词
- docValuesType:Field的DocValue类型
- omitNorms:是否忽略Norm统一因子
- storeTermVectors:TermVector相关的属性
- storeTermVectorOffsets:TermVector相关的属性,存储的偏移量
- storeTermVectorPositions:TermVector相关的属性,存储的位置信息
- storeTermVectorPayloads:TermVector相关的属性,存储负载
- frozen:Field是否冻结
- dimensionCount:字段的维度数量
- indexDimensionCount:索引的维度数量
- dimensionNumBytes:每个维度的字节数
Term
Term(词汇项):索引过程中,经过Analyzer分析器,将Field解析成Token,基于Token添加额外索引信息等操作后,得到Term对象进行索引。Term是最小搜索单元,是实现倒排表Posting的基本元素,由两部分组成:词汇的文本信息、词汇所属Field名称。
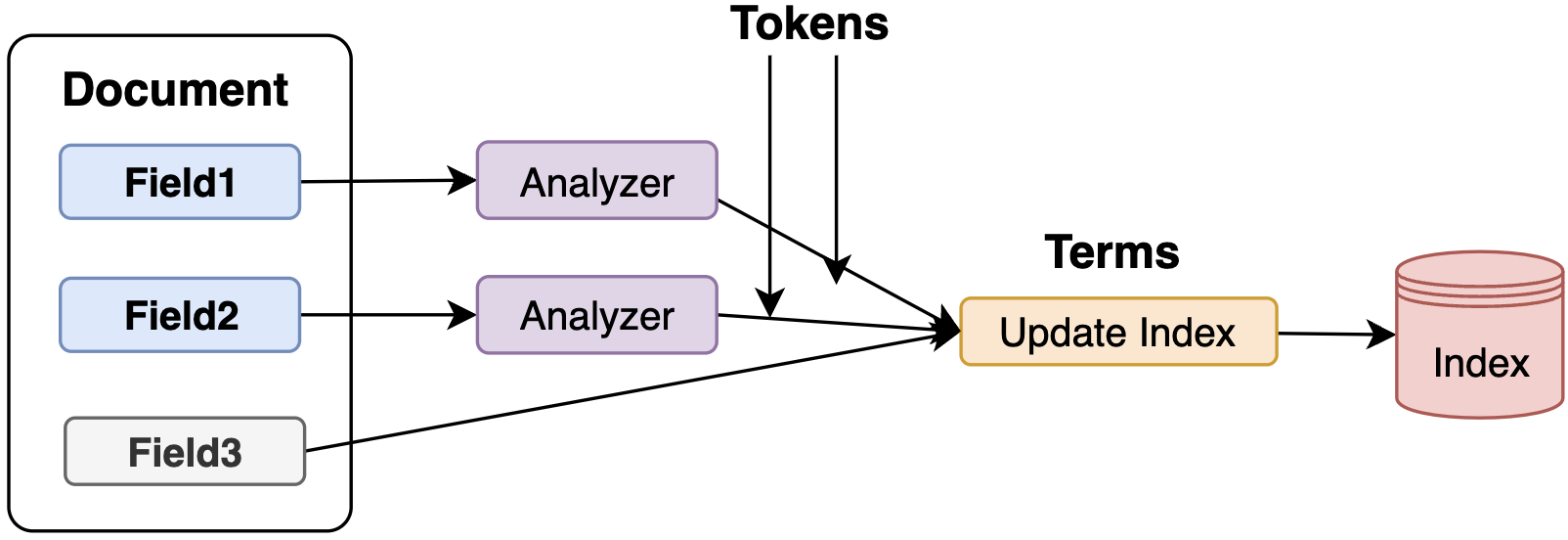
解析流程如下图:Field1、Field2基于分词操作,从Token转成Term,Field3设置不分词,其FiledValue直接转成独立的Term。
Analyzer
Analyzer(分词器):是由一组TokenStream串行组成的词汇分析链,定义将Field文本解析为搜索单元Term的策略,可通过IndexWriter构造方法指定Field的分词器。 用户可以很简单的对不同TokenStream组合和实现,得到自定义分词器。
TokenStream是分词处理流的抽象类,主要有两个子类:Tokenizer(定义分词逻辑),TokenFilter(定义分词后的转换操作)。Analyzer一般由一个Tokenizer和多个TokenFilter组成,其中Tokenizer是TokenFilter的前置。

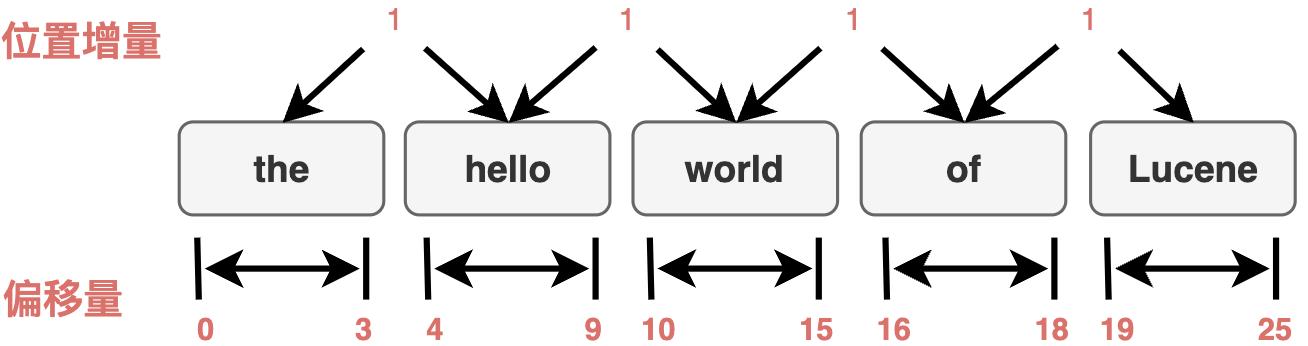
Token
Token(词汇单元):在词汇解析过程中,由Tokenizers和TokenFilters过程中产生的分词对象,包括一系列的Attribute属性信息,定义该分词对象的关注属性,如偏移量、位置、词性等。
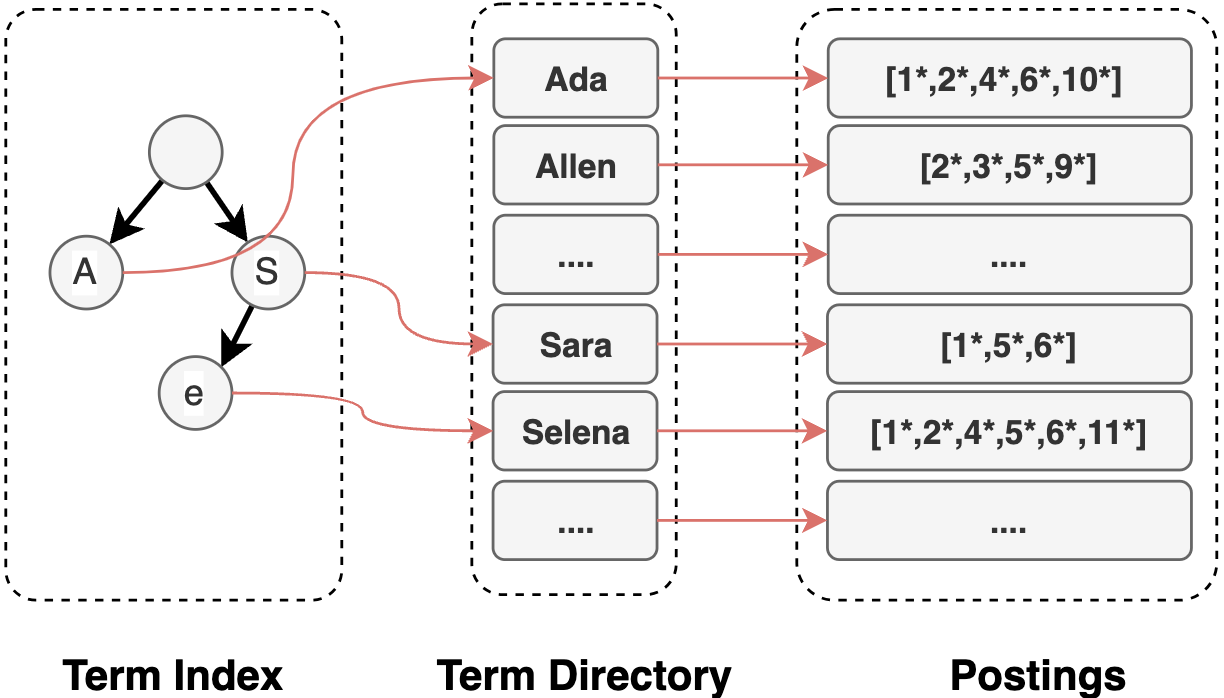
倒排索引
Inverted Index(倒排索引):是搜索引擎的核心数据结构,对文档进行逆向排列,以文档Term为Key信息,关联包含该Term的文档信息,即文档原本的数据结构为:document -> terms,而倒排索引的数据结构为:term -> documents,使得基于term-based的全文检索更加高效。
Lucene的倒排索引主要有以下三部分构成:
- Term Index(Term索引):是Term Directory的索引,使得Term可以被随机访问,判断Term是否存在,从Lucene4后,其数据结构使用FST,为每个Field维护一个FST树
- Term Directory(Term字典):是Term的列表,每个Term包括了该Term下的统计信息(如文档频次)及元数据(如Term对应的Postings倒排表指针信息),该字典列表是按顺序存储的
- Postings(倒排表):Term对应的倒排信息,主要包括:包含该Term的所有Document,每个Doc下的词频(TF),Term在Doc下的位置(Position),Term的Payload、Offsets等
整体架构
功能架构
Lucene功能主要包括两部分:索引,搜索
- 索引:主要基于IndexWriter为执行入口,由DWPT(DocumentsWriterPerThread)实现了并发写,每个DWPT都有独立的内存空间执行索引链流程
- 搜索:主要基于IndexSearcher为执行入口,可指定查询Executor实现并发搜索,每个搜索线程下,基于LeafReader以Segment为单位进行Term匹配读取
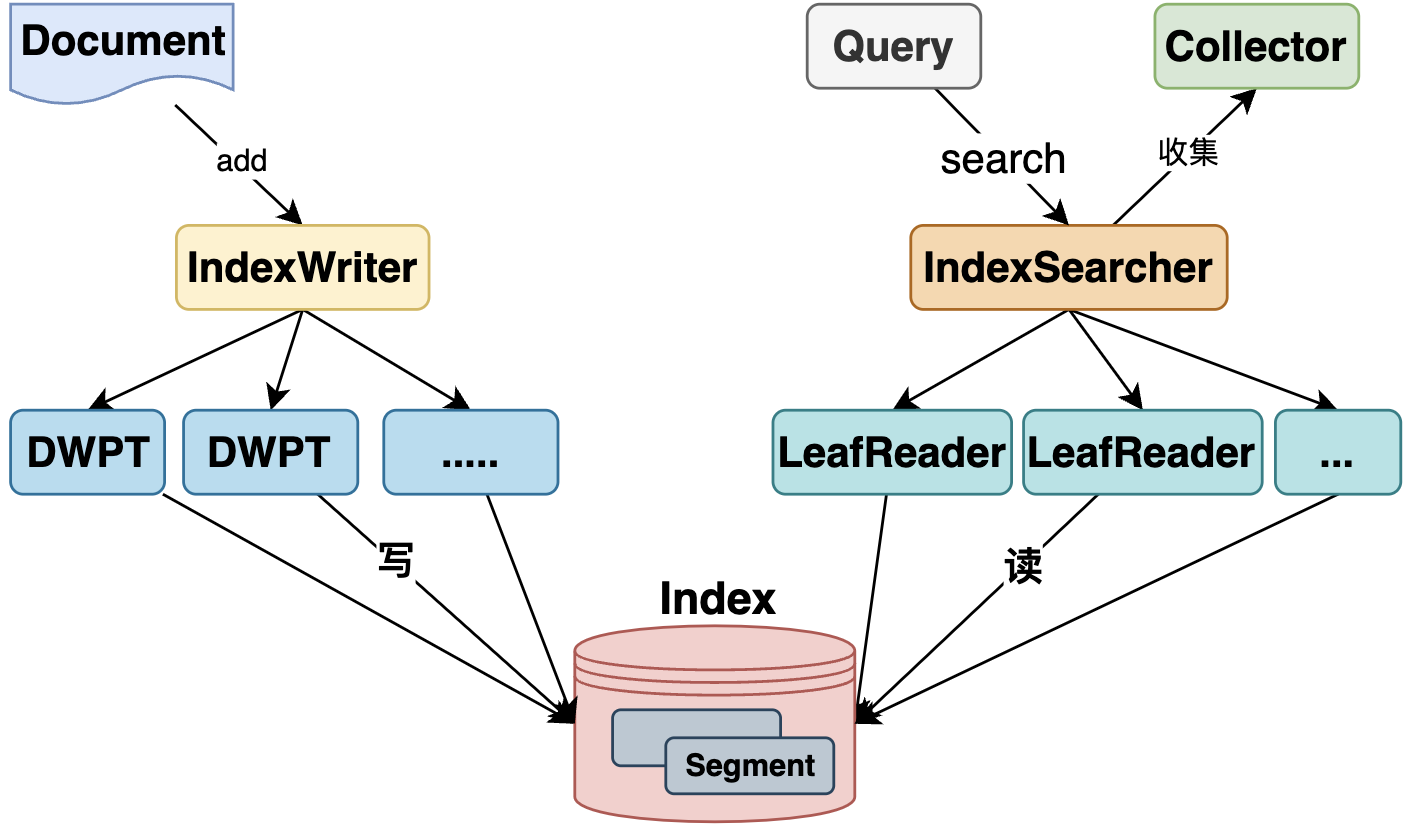
逻辑架构
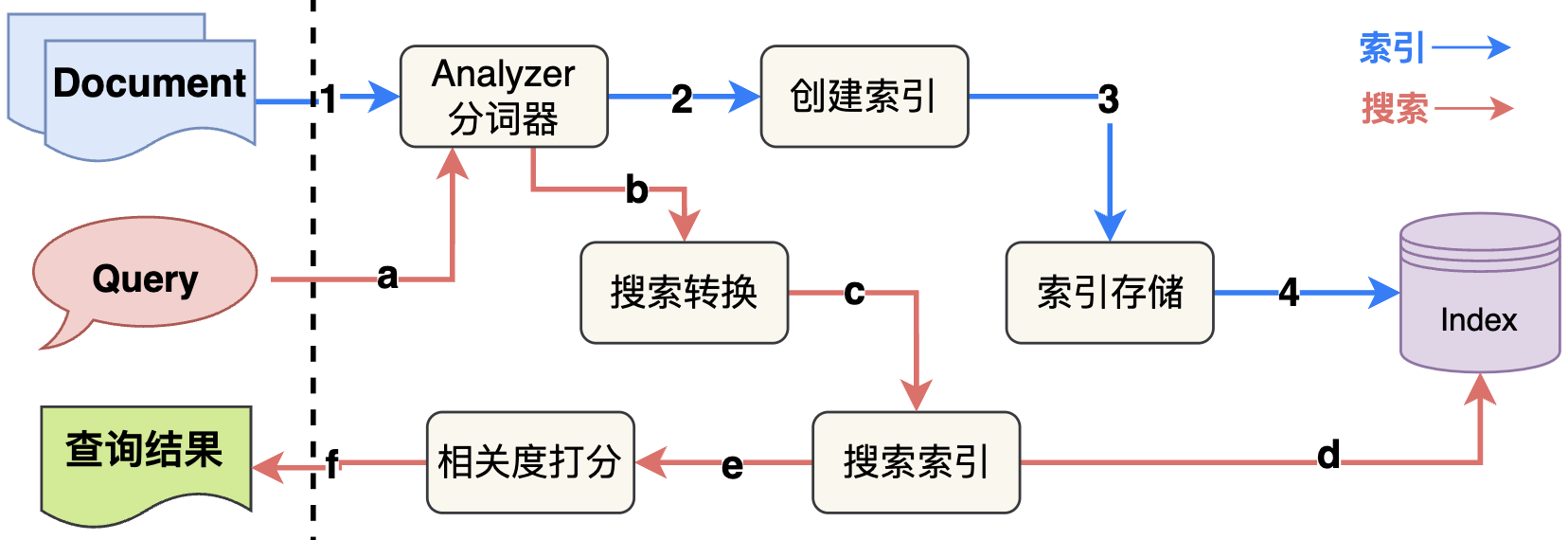
索引 和 搜索的逻辑架构图如下所示:
Lucene的核心功能索引和搜索都是在lucene.core子项目下实现,对应的源码包关系图如下:
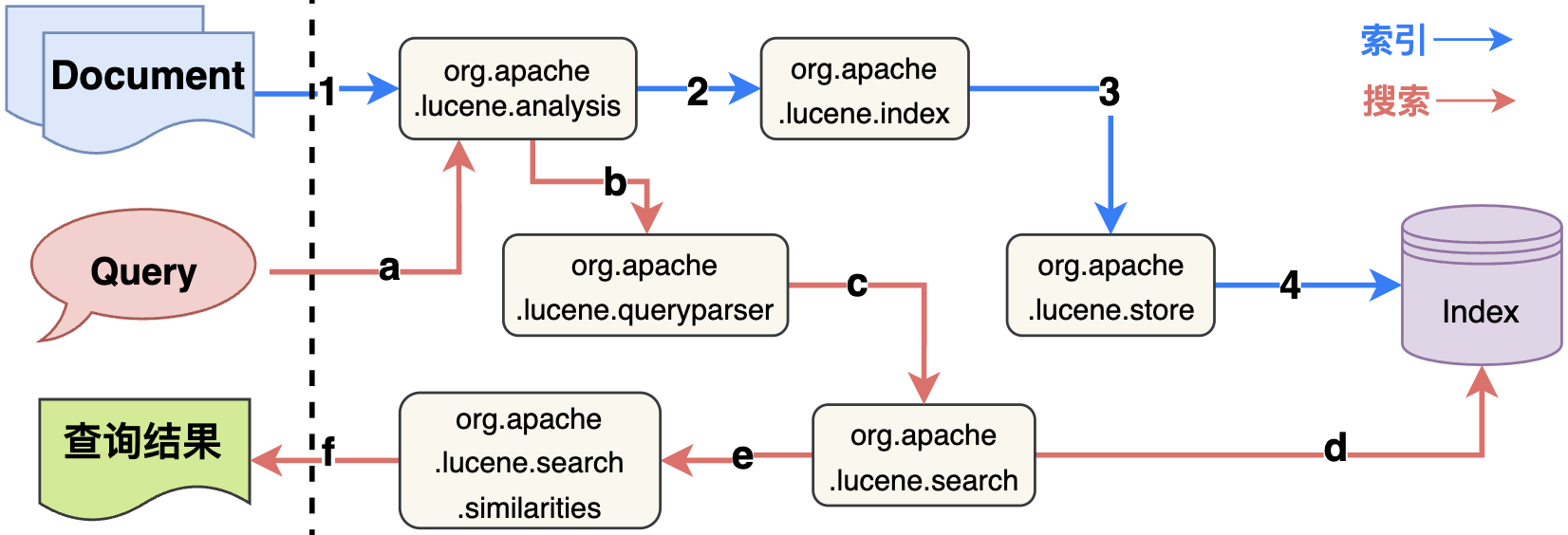
Lucene核心包说明如下(官方文档):
- org.apache.lucene.analysis:分词解析,定义Analyzer(分析器),从Reader对象读取数据并解析为TokenStream和对应的Attributes(Token属性);
- org.apache.lucene.codecs:索引编解码,定义Lucene的不同索引文件的数据结构读写方式(编解码),定义抽象类和对应的各种实现;
- org.apache.lucene.document:索引文件的对象,从Reader读取获取Document对象,Document对象可看做Field的集合;
- org.apache.lucene.index:索引执行流程,提供两个主要类:IndexWriter创建索引,IndexReader访问读取索引;
- org.apache.lucene.search:搜索执行流程,提供搜索对象Query和索引搜索的执行入口IndexSearcher,返回搜索结果TopDocs;
- org.apache.lucene.store:索引存储,定义持久化数据的抽象类Directory,并提供了多种实现方式,其中常用FSDirectory从本地磁盘进行索引读写;
- org.apache.lucene.util:提供处理数据结构的工具类;
使用操作
索引操作
创建索引
@Test
public void create() throws Exception {
String content = "hello world index";
String indexPath = "test/index";
IndexWriterConfig iwc = new IndexWriterConfig(new StandardAnalyzer());
try (Directory dir = FSDirectory.open(Paths.get(indexPath));
IndexWriter writer = new IndexWriter(dir, iwc);
) {
Document doc = new Document();
doc.add(new StringField("path", indexPath, Field.Store.YES));
doc.add(new TextField("content", content, Field.Store.YES));
doc.add(new LongPoint("modified", Clock.systemUTC().millis()));
writer.addDocument(doc);
}更新索引
根据指定Term更新索引信息
@Test
public void update() throws Exception {
String content = "world index";
String indexPath = "test/index";
IndexWriterConfig iwc = new IndexWriterConfig(new StandardAnalyzer());
try (Directory dir = FSDirectory.open(Paths.get(indexPath));
IndexWriter writer = new IndexWriter(dir, iwc);
) {
Document doc = new Document();
doc.add(new StringField("path", indexPath + "_update", Field.Store.YES));
doc.add(new TextField("content", content, Field.Store.YES));
doc.add(new LongPoint("modified", Clock.systemUTC().millis()));
writer.updateDocument(new Term("path", indexPath), doc);
}
}删除索引
@Test
public void delete() throws Exception {
String fieldName = "content";
String indexPath = "test/index";
IndexWriterConfig iwc = new IndexWriterConfig(new StandardAnalyzer());
try (Directory dir = FSDirectory.open(Paths.get(indexPath));
IndexWriter writer = new IndexWriter(dir, iwc);
) {
QueryParser parser = new QueryParser(fieldName, new StandardAnalyzer());
Query query = parser.parse("hello world");
long deleteCounts = writer.deleteDocuments(query);
System.out.println("delete doc by query of count=" + deleteCounts);
}
}搜索操作
读取索引信息
@Test
public void read() throws Exception {
String indexPath = "test/index";
Directory dir = FSDirectory.open(Paths.get(indexPath));
DirectoryReader reader = DirectoryReader.open(dir);
IndexReader indexReader = new IndexSearcher(reader).getIndexReader();
//获取索引信息
System.out.println("索引leaves信息:" + indexReader.getContext().leaves());
System.out.println("索引中文档数量:" + indexReader.numDocs());
System.out.println("索引中文档的最大值:" + indexReader.maxDoc());
System.out.println("索引中被删除文档数量:" + indexReader.numDeletedDocs());
}简单搜索
@Test
public void search() throws Exception {
String indexPath = "test/index";
String fieldName = "content";
Directory dir = FSDirectory.open(Paths.get(indexPath));
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(dir));
QueryParser parser = new QueryParser(fieldName, new StandardAnalyzer());
Query query = parser.parse("hello world");
TopDocs docs = searcher.search(query, 10);
System.out.println("匹配的搜索条数:" + docs.totalHits.value);
for (int i = 0; i < docs.scoreDocs.length; i++) {
ScoreDoc scoreDoc = docs.scoreDocs[i];
System.out.println("获取Document文档 docId=" + scoreDoc.doc + ",匹配打分=" + scoreDoc.score);
Document doc = searcher.doc(scoreDoc.doc);
Iterator<IndexableField> iterator = doc.iterator();
while (iterator.hasNext()) {
IndexableField field = iterator.next();
String fieldValue = doc.get(field.name());
System.out.println("[fieldName]=" + field.name() + ",[fieldValue]=" + fieldValue);
}
System.out.println();
}
}多条件搜索
多条件搜索基于BooleanQuery实现,示例如下:
@Test
public void booleanSearch() throws Exception {
String indexPath = "test/index";
Directory dir = FSDirectory.open(Paths.get(indexPath));
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(dir));
Query queryContent = new QueryParser("content", new StandardAnalyzer()).parse("hello world");
BoostQuery boost = new BoostQuery(queryContent, 100);
Query queryPath = new QueryParser("path", new SimpleAnalyzer()).parse("test\\/index");
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(queryContent, BooleanClause.Occur.MUST);
builder.add(boost, BooleanClause.Occur.SHOULD);
builder.add(queryPath, BooleanClause.Occur.MUST);
BooleanQuery query = builder.build();
TopDocs docs = searcher.search(query, 10);
System.out.println("匹配的搜索条数:" + docs.totalHits.value);
for (int i = 0; i < docs.scoreDocs.length; i++) {
ScoreDoc scoreDoc = docs.scoreDocs[i];
System.out.println("获取Document文档 docId=" + scoreDoc.doc + ",匹配打分=" + scoreDoc.score);
Document doc = searcher.doc(scoreDoc.doc);
Iterator<IndexableField> iterator = doc.iterator();
while (iterator.hasNext()) {
IndexableField field = iterator.next();
String fieldValue = doc.get(field.name());
System.out.println("[fieldName]=" + field.name() + ",[fieldValue]=" + fieldValue);
}
System.out.println();
}
}总结
Lucene 建立了大数据检索的基础,其基于奥卡姆剃刀的原则,提供检索工具包而不提供更多应用功能。使得Lucene项目能够更专注于构建索引和搜索,也便于其他应用项目的集成与扩展。
参考附录
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号