五、XPath实战:快速定位网页元素
原创
五、XPath实战:快速定位网页元素
原创
小馒头学Python
发布于 2023-11-14 08:20:11
发布于 2023-11-14 08:20:11
🍀分析网站
本节我们来爬取豆瓣电影,在实战开始前,我们需要搞懂爬取的流程,在清楚爬取的步骤后,我们方可事半功倍
- 导入需要的库
- 分析获取网站URL
- 获取HTML页面
- etree解析
- 使用Xpath插件进行测试标签
- 编写Xpath语法,并存储数据
🍀获取每页URL
首页需要导入我们需要的库
import requests
from lxml import etree接下来需要获取前5页的URL,下面我们可以一起来看看它们之间的规律

不难看出规律为0,20,40,60,80,那么我们获取这几页URL就好办了
urls = []
for i in range(0,5,1):
i*=20
url = 'https://movie.douban.com/review/best/?start={}'.format(i)
urls.append(url)🍀获取每页URL中的影评URL
接下来我们需要获取每页中影评的具体URL
右击鼠标点击检查,我们就会看到具体的URL,为了测试Xpath语法,我们需要打开Xpath插件(本文结尾我会奉上下载链接)
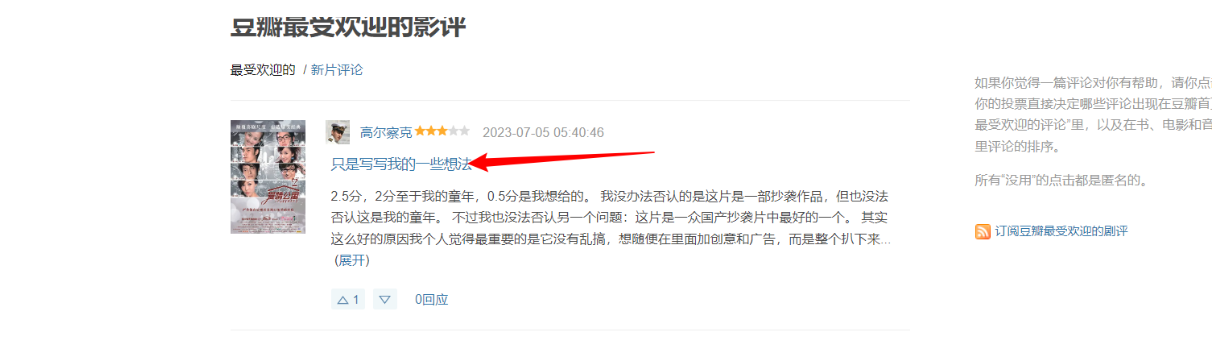
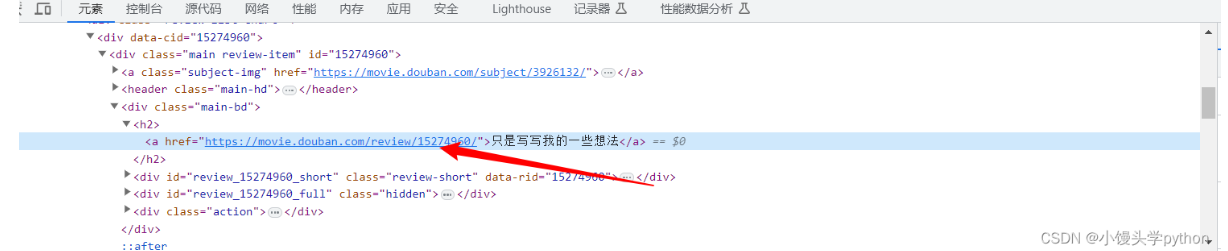
不难分析此URL可以从,总的h2标签下的,a标签中的,href属性下手

detail_urls = []
for d_url in urls:
reponse = requests.get(d_url, headers=_headers)
# 编码转码
content = reponse.content.decode('utf8')
# 解析html字符串
html = etree.HTML(content)
# 利用Xpath提取每个电影影评的url
detail_url = html.xpath('//h2/a/@href')
detail_urls.append(detail_url)🍀获取电影影评数据
做完先前的工作,这里可以说是核心的步骤了,获取真正有用的数据
获取电影名
title = html.xpath('//div[@class="subject-title"]/a/text()')[0][2:]这里会有人好奇为什么后面需要切一下,原因如下,前面有一些无用的数据,需要清除

获取评论者和评分
commenter = html.xpath('//header/a/span/text()')[0]
rank = html.xpath('//header//span/@title')[0]
if len(rank) == 0:
_rank = weidafen
else:
_rank = rank获取影评
comment = html.xpath('//div[@id="link-report"]//p/text()')
comment = ''.join(comment) # 拼接因为影评不是连续的,所有需要用.join()进行拼接一下
获取评价时间
time = html.xpath('//header/span[3]/text()')[0]🍀修饰+完整代码
从前辈那里学到了一个技巧,使用异常处理模块,完整代码如下
import requests
from lxml import etree
# 获取5页的url
urls = []
for i in range(0,5,1):
i*=20
url = 'https://movie.douban.com/review/best/?start={}'.format(i)
urls.append(url)
# 获取每一页url中,每个影评的具体url
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
detail_urls = []
for d_url in urls:
reponse = requests.get(d_url, headers=_headers)
# 编码转码
content = reponse.content.decode('utf8')
# 解析html字符串
html = etree.HTML(content)
# 利用Xpath提取每个电影影评的url
detail_url = html.xpath('//h2/a/@href')
detail_urls.append(detail_url)
# 获取电影影评的数据
moives=[]
weidafen = "未打分"
i = 0
for page in detail_urls:
for url in page:
try:
response = requests.get(url, headers=_headers)
content = response.content.decode('utf8')
html = etree.HTML(content)
# 抓取电影名
title = html.xpath('//div[@class="subject-title"]/a/text()')[0][2:]
# 抓取评论者和评分
commenter = html.xpath('//header/a/span/text()')[0]
rank = html.xpath('//header//span/@title')[0]
if len(rank) == 0:
_rank = weidafen
else:
_rank = rank
# 抓影评
comment = html.xpath('//div[@id="link-report"]//p/text()')
comment = ''.join(comment) # 拼接
# 抓评价时间
time = html.xpath('//header/span[3]/text()')[0]
movie = {
"title": title,
"commenter": commenter,
"rank": _rank,
"comment": comment,
"time": time
}
moives.append(movie)
except:
continue
i+=1
print("-------第{}页已爬取-------".format(i))
print(moives)🍀保存数据到csv
保存后的数据有一点问题,愿大佬指正
import requests
from lxml import etree
import csv
# 获取5页的url
urls = []
for i in range(0,5,1):
i*=20
url = 'https://movie.douban.com/review/best/?start={}'.format(i)
urls.append(url)
# 获取每一页url中,每个影评的具体url
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
detail_urls = []
for d_url in urls:
reponse = requests.get(d_url, headers=_headers)
# 编码转码
content = reponse.content.decode('utf8')
# 解析html字符串
html = etree.HTML(content)
# 利用Xpath提取每个电影影评的url
detail_url = html.xpath('//h2/a/@href')
detail_urls.append(detail_url)
fp = open('data.csv', 'w', newline="", encoding="utf-8-sig")
writer = csv.writer(fp)
writer.writerow(('电影名','评分者', '评分', '评论', '时间'))
# 获取电影影评的数据
moives=[]
weidafen = "未打分"
i = 0
for page in detail_urls:
for url in page:
try:
response = requests.get(url, headers=_headers)
content = response.content.decode('utf8')
html = etree.HTML(content)
# 抓取电影名
title = html.xpath('//div[@class="subject-title"]/a/text()')[0][2:]
# 抓取评论者和评分
commenter = html.xpath('//header/a/span/text()')[0]
rank = html.xpath('//header//span/@title')[0]
if len(rank) == 0:
_rank = weidafen
else:
_rank = rank
# 抓影评
comment = html.xpath('//div[@id="link-report"]//p/text()')
comment = ''.join(comment) # 拼接
# 抓评价时间
time = html.xpath('//header/span[3]/text()')[0]
# movie = {
# "title": title,
# "commenter": commenter,
# "rank": _rank,
# "comment": comment,
# "time": time
# }
moives.append([title,commenter,rank,comment,time])
except:
continue
i+=1
print("-------第{}页已爬取-------".format(i))
# 写入数据
for rows in moives:
writer.writerow(rows)
fp.close()注意:Xpath提取数据返回结果是列表,后续操作需要使用列表操作
🍀总结
Xpath的主要流程可以用下图表示

🍀Xpath插件
链接:https://pan.baidu.com/s/1Pn3dmJgJADIUKcjsDs8cJw?pwd=zsjw 提取码:zsjw –来自百度网盘超级会员V5的分享
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号