手把手入门教程:YOLOv8如何训练自己的数据集,交通信号灯识别
原创
手把手入门教程:YOLOv8如何训练自己的数据集,交通信号灯识别
原创
AI小怪兽
发布于 2023-11-03 16:24:48
发布于 2023-11-03 16:24:48
1.Yolov8介绍
Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO成功基础上,并引入了新功能和改进,以进一步提升性能和灵活性。它可以在大型数据集上进行训练,并且能够在各种硬件平台上运行,从CPU到GPU。
具体改进如下:
- Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
- PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
- Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
- Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
- 损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
- 样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式
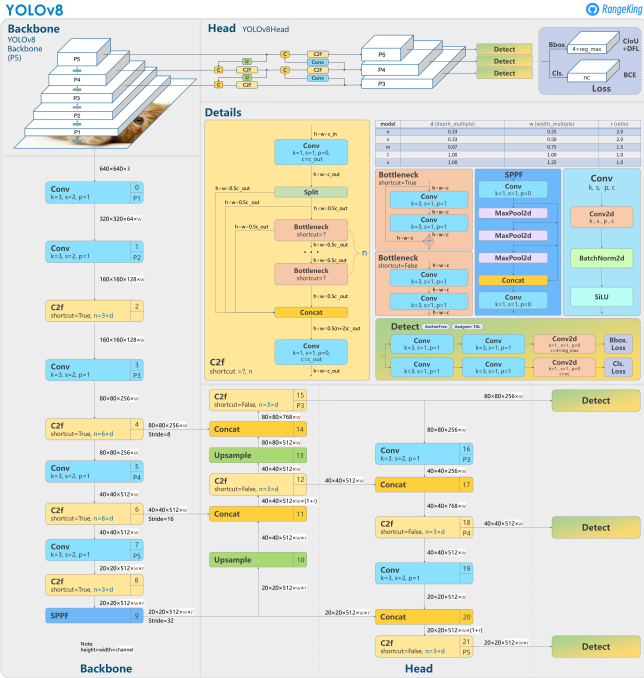
框架图提供见链接:Brief summary of YOLOv8 model structure · Issue #189 · ultralytics/ultralytics · GitHub
2.交通信号灯数据集介绍
数据集大小:877张,train、test、val按照8:1:1进行划分
类别:speedlimit、crosswalk、trafficlight、stop
2.1数据集划分
通过split_train_val.py得到trainval.txt、val.txt、test.txt
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/trainval.txt', 'w')
ftest = open('ImageSets/test.txt', 'w')
ftrain = open('ImageSets/train.txt', 'w')
fval = open('ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
2.2 通过voc_label.py得到适合yolov8训练需要的
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train','test']
classes = ['speedlimit','crosswalk','trafficlight','stop']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id))
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('images/%s.png\n' % (image_id))
convert_annotation(image_id)
list_file.close()
2.3生成内容如下
3.如何训练
训练启动:
from ultralytics.cfg import entrypoint
arg="yolo detect train model=ayolov8n.yaml data=ultralytics/cfg/datasets/traffic.yaml"
entrypoint(arg)超参数修改default.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# Default training settings and hyperparameters for medium-augmentation COCO training
task: detect # YOLO task, i.e. detect, segment, classify, pose
mode: train # YOLO mode, i.e. train, val, predict, export, track, benchmark
# Train settings -------------------------------------------------------------------------------------------------------
model: # path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: # path to data file, i.e. coco128.yaml
epochs: 200 # number of epochs to train for
patience: 50 # epochs to wait for no observable improvement for early stopping of training
batch: 16 # number of images per batch (-1 for AutoBatch)
imgsz: 640 # size of input images as integer or w,h
save: True # save train checkpoints and predict results
save_period: -1 # Save checkpoint every x epochs (disabled if < 1)
cache: False # True/ram, disk or False. Use cache for data loading
device: # device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
workers: 0 # number of worker threads for data loading (per RANK if DDP)
project: # project name
name: # experiment name, results saved to 'project/name' directory
exist_ok: False # whether to overwrite existing experiment
pretrained: False # whether to use a pretrained model
optimizer: SGD # optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp', 'Lion']
verbose: True # whether to print verbose output
seed: 0 # random seed for reproducibility
deterministic: True # whether to enable deterministic mode
single_cls: False # train multi-class data as single-class
image_weights: False # use weighted image selection for training
rect: False # support rectangular training if mode='train', support rectangular evaluation if mode='val'
cos_lr: False # use cosine learning rate scheduler
close_mosaic: 10 # disable mosaic augmentation for final 10 epochs
resume: False # resume training from last checkpoint
amp: True # Automatic Mixed Precision (AMP) training, choices=[True, False], True runs AMP check
# Segmentation
overlap_mask: True # masks should overlap during training (segment train only)
mask_ratio: 4 # mask downsample ratio (segment train only)
# Classification
dropout: 0.0 # use dropout regularization (classify train only)
# Val/Test settings ----------------------------------------------------------------------------------------------------
val: True # validate/test during training
split: val # dataset split to use for validation, i.e. 'val', 'test' or 'train'
save_json: False # save results to JSON file
save_hybrid: False # save hybrid version of labels (labels + additional predictions)
conf: # object confidence threshold for detection (default 0.25 predict, 0.001 val)
iou: 0.7 # intersection over union (IoU) threshold for NMS
max_det: 300 # maximum number of detections per image
half: False # use half precision (FP16)
dnn: False # use OpenCV DNN for ONNX inference
plots: True # save plots during train/val
# Prediction settings --------------------------------------------------------------------------------------------------
source: # source directory for images or videos
show: False # show results if possible
save_txt: False # save results as .txt file
save_conf: False # save results with confidence scores
save_crop: False # save cropped images with results
hide_labels: False # hide labels
hide_conf: False # hide confidence scores
vid_stride: 1 # video frame-rate stride
line_thickness: 3 # bounding box thickness (pixels)
visualize: False # visualize model features
augment: False # apply image augmentation to prediction sources
agnostic_nms: False # class-agnostic NMS
classes: # filter results by class, i.e. class=0, or class=[0,2,3]
retina_masks: False # use high-resolution segmentation masks
boxes: True # Show boxes in segmentation predictions
# Export settings ------------------------------------------------------------------------------------------------------
format: torchscript # format to export to
keras: False # use Keras
optimize: False # TorchScript: optimize for mobile
int8: False # CoreML/TF INT8 quantization
dynamic: False # ONNX/TF/TensorRT: dynamic axes
simplify: False # ONNX: simplify model
opset: # ONNX: opset version (optional)
workspace: 4 # TensorRT: workspace size (GB)
nms: False # CoreML: add NMS
# Hyperparameters ------------------------------------------------------------------------------------------------------
lr0: 0.01 # initial learning rate (i.e. SGD=1E-2, Adam=1E-3 ,Lion=1E-4)
lrf: 0.01 # final learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 7.5 # box loss gain
cls: 0.5 # cls loss gain (scale with pixels)
dfl: 1.5 # dfl loss gain
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
label_smoothing: 0.0 # label smoothing (fraction)
nbs: 64 # nominal batch size
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
# Custom config.yaml ---------------------------------------------------------------------------------------------------
cfg: # for overriding defaults.yaml
# Debug, do not modify -------------------------------------------------------------------------------------------------
v5loader: False # use legacy YOLOv5 dataloader
# Tracker settings ------------------------------------------------------------------------------------------------------
tracker: botsort.yaml # tracker type, ['botsort.yaml', 'bytetrack.yaml']
4.训练结果分析
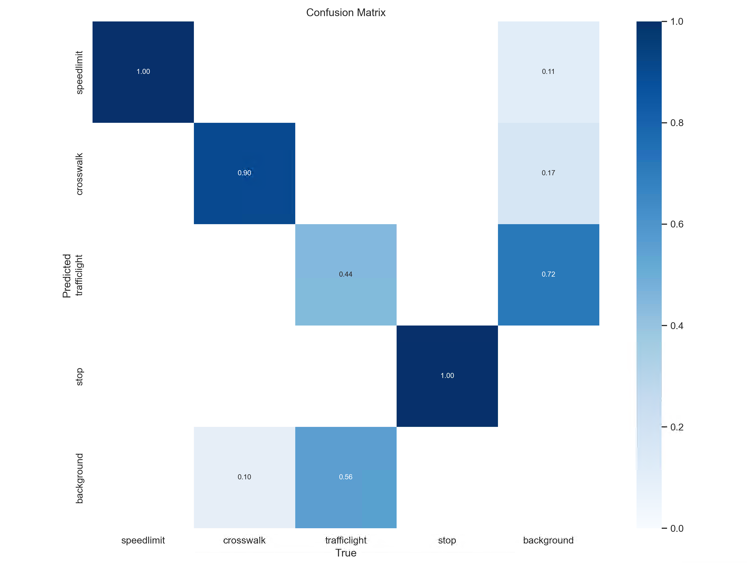
confusion_matrix.png :列代表预测的类别,行代表实际的类别。其对角线上的值表示预测正确的数量比例,非对角线元素则是预测错误的部分。混淆矩阵的对角线值越高越好,这表明许多预测是正确的。
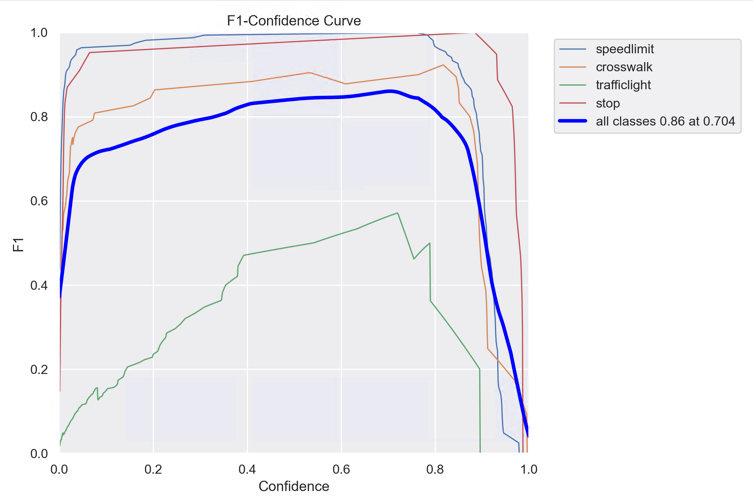
F1_curve.png:F1分数与置信度(x轴)之间的关系。F1分数是分类的一个衡量标准,是精确率和召回率的调和平均函数,介于0,1之间。越大越好。
TP:真实为真,预测为真;
FN:真实为真,预测为假;
FP:真实为假,预测为真;
TN:真实为假,预测为假;
精确率(precision)=TP/(TP+FP)
召回率(Recall)=TP/(TP+FN)
F1=2*(精确率*召回率)/(精确率+召回率)
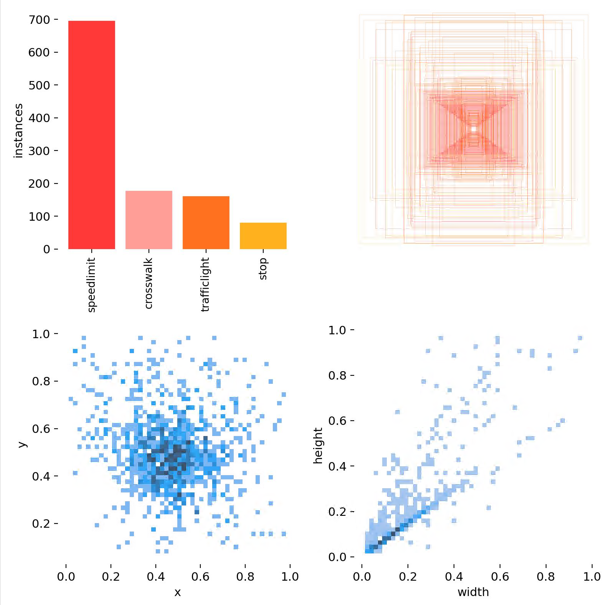
labels_correlogram.jpg :显示数据的每个轴与其他轴之间的对比。图像中的标签位于 xywh 空间。
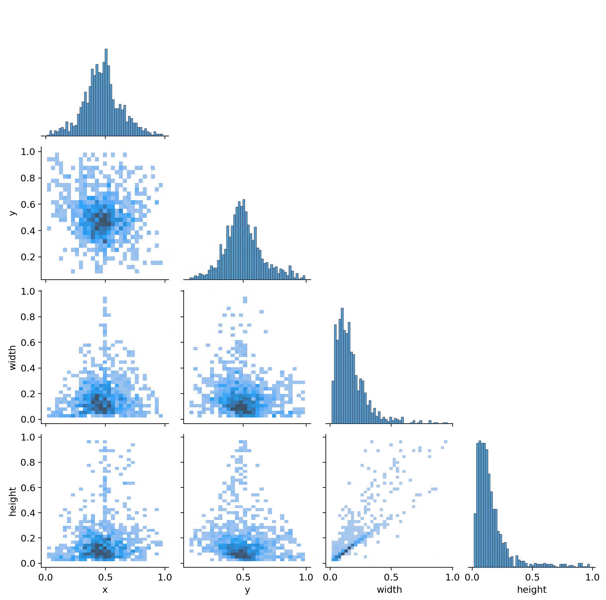
labels.jpg :
(1,1)表示每个类别的数据量
(1,2)真实标注的 bounding_box
(2,1) 真实标注的中心点坐标
(2,2)真实标注的矩阵宽高
P_curve.png:表示准确率与置信度的关系图线,横坐标置信度。由下图可以看出置信度越高,准确率越高。

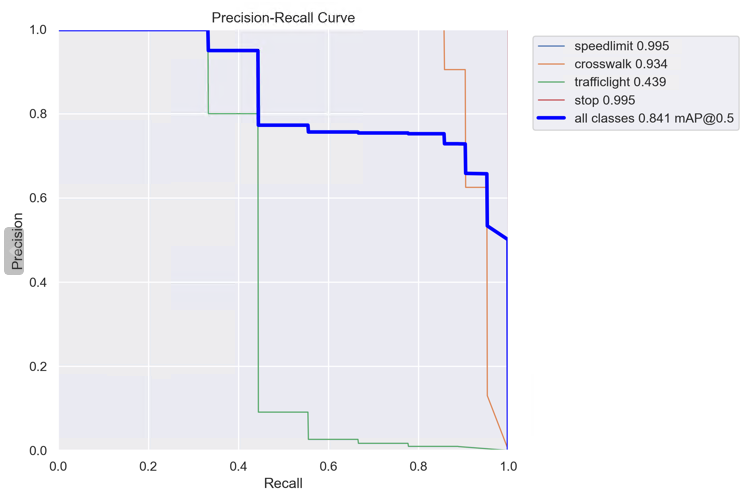
PR_curve.png :PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系。
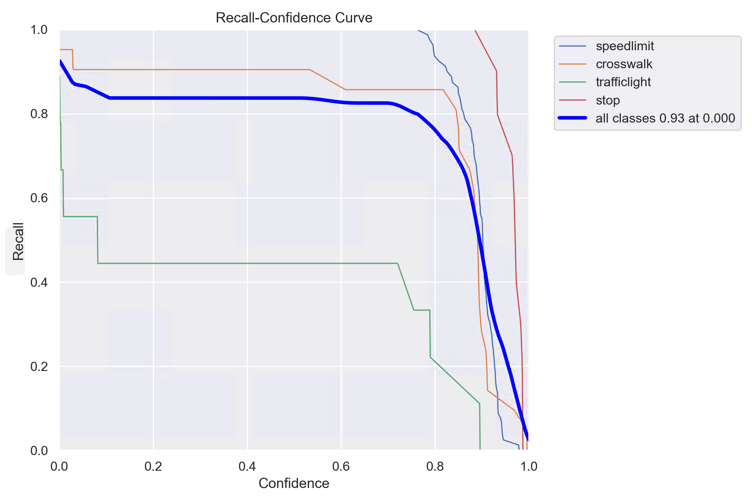
R_curve.png :召回率与置信度之间关系
预测结果:

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号