重大活动期间Redis稳定性保障思路
原创

马上十一、中秋双节,很多客户开始做节日活动,基本都有一个共性需求:活动期间,流量预计翻N备,由此引发了一轮Redis的容量治理与保障。
在这个过程中,感受最深的是,大家在事前不重视Redis的维护,期望发生事故时,云平台可以力挽狂澜,但实际这是不合理的,主要原因是Redis是单线程服务,当某个指令阻塞了后续的指令,你不能像MySQL一样,把慢sql杀掉,所以你也就失去了进一步处理的能力。所以最好还是做好事前的保障。
1、一个故障场景
曾经有个客户使用云Redis时,选择了某个开源框架,开源框架中有执行lua脚本,lua脚本里面包含了keys *操作,最终卡死了Redis主实例,导致了主从切换;但由于主实例卡死了一个指令,导致切换过去后,从实例并不能提供服务。此时只好联系云厂商,强制把Redis重启,才恢复了业务。从事件可以看出,Redis卡住后,基本上没有什么好的手段,让它恢复。
2、事前治理思路
2.1 消除人为因素
我曾经在给一个业界有名的客户护航时遇到了一个问题:当时是客户的重大活动期间,前三天一切平稳,到最后快结束的一个中午,有开发登陆了生产的Redis集群,执行了key *,然后集群就切换了。。。
所以事前治理,我认为最重要的是管控人为因素,限制登陆生产Redis的人员、可执行的命令等。
2.2 容量
保障cpu/内存的冗余,用空间换时间
副本只读
2.3 慢查询监控
这里主要的监控,是指把慢
redis配监控,基于业务可以接受的超时时间;proxy-slowlog的配置阈值和监控的阈值一致,方便排查/redis也有慢查询设置、优先看proxy,要看细节再看redis的;因为proxy是最先接受客户请求的。开启慢查询日志
2.4 消除慢key、热key、大key
在Redis中,"慢key" 是指Redis数据库中处理速度较慢的key,"大key" 是指一个存储在数据库中的特别大的数据结构,"热key" 是指在Redis数据库中非常频繁被访问的key,这些key通常引发了较长的查询或写入操作,可能导致Redis性能下降,造成请求延迟或资源争夺。
所以,日常可以借助监控,把暴露出来的异常key,都给治理掉。
2.5 联合业务做好压测
由于有压力和无压力下,暴露出来的问题是不一样的,最好是能联合业务,在生产环境做一次压测,把Redis的性能隐患充分暴露出来、然后有针对性治理
3、事中应急手段
3.1 紧急扩容
从经验来看,这应该是最有效的应急手段了,通过云平台的紧急扩容能力,用资源量将请求扛过去,避免业务崩溃
操作步骤:
登陆控制台,找到实例详情,选配置变更

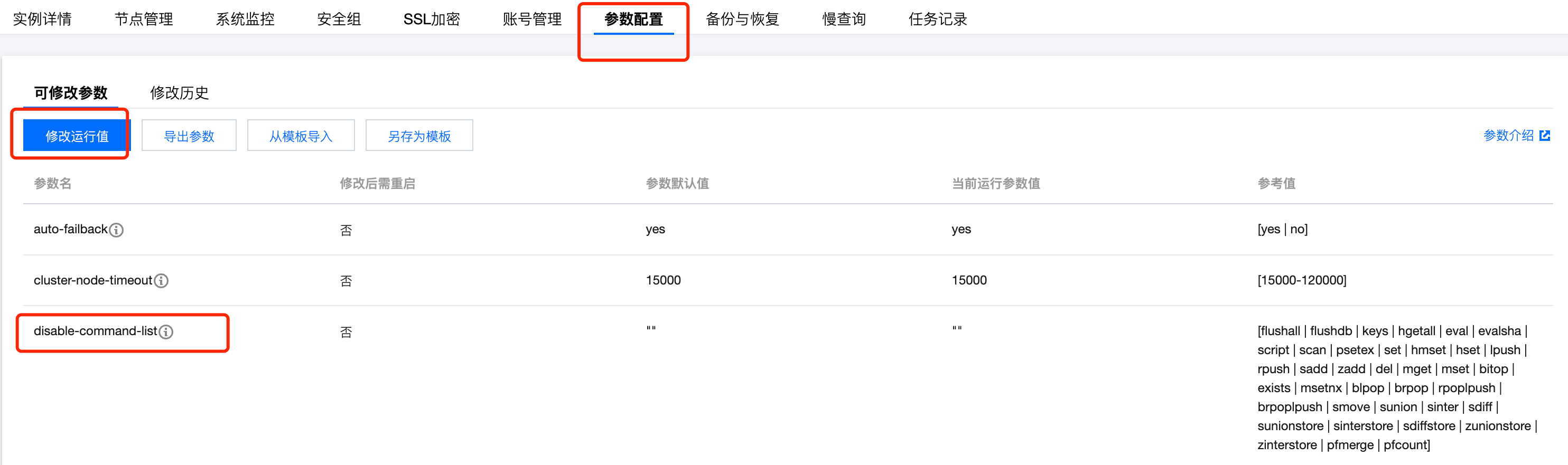
3.2 添加禁用命令
临时将引起 Redis性能问题的命令禁用掉,但这种方式有较大的隐患,因为一个命令可能在多个业务场景使用。谨慎操作
操作步骤:
登陆控制台,找到需要操作的redis实例,进入详情,选择参数配置
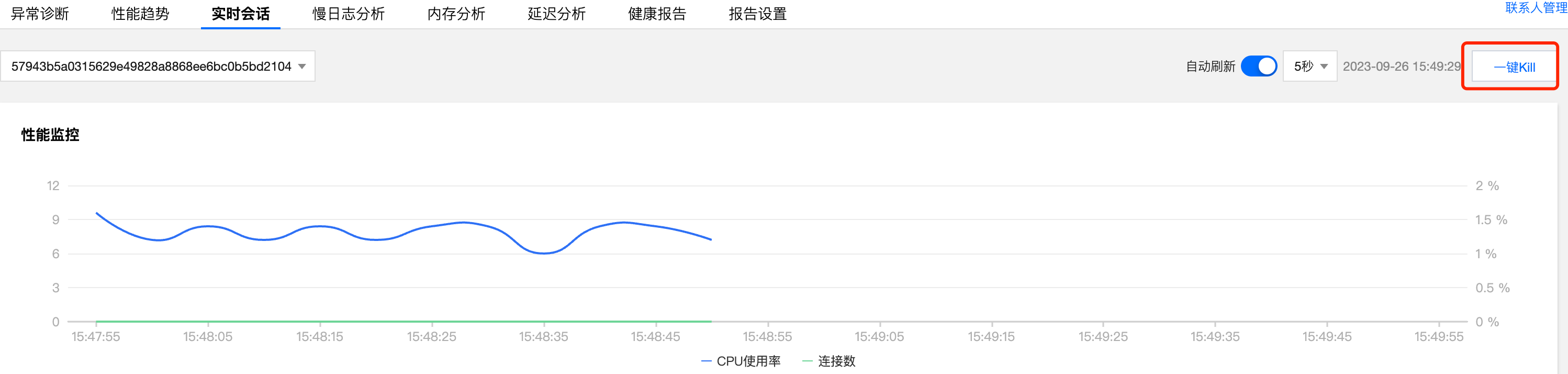
3.3 一键kill
Redis卡主后,为了避免进一步恶化,可以将队列中的后续指令kill掉(队列里面的指令实际并没有开始处理,业务相对安全)。这种方式实测效果不大,聊胜于无
操作步骤:
登陆控制台,找到你的实例,进入详情页
进入一键诊断->实时会话,一键kill
总结
从上面的文章可以看出,redis出现生产上的性能问题后,一般有效的应急手段很少了,最重要的还是平常做好观测和预防。
我正在参与 腾讯云开发者社区数据库专题有奖征文
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号