Transformer中的FPN-Swin Transformer

Transformer中的FPN-Swin Transformer

YoungTimes
发布于 2023-09-01 08:57:43
发布于 2023-09-01 08:57:43
Transformer从NLP领域迁移到Vision领域,要解决几个主要问题:1) 尺度问题。同样的物体在同一张图像中的尺寸会有差异;2) 图像的分辨率问题。分辨率太大,直接用Transformer处理的计算代价太大。
“Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
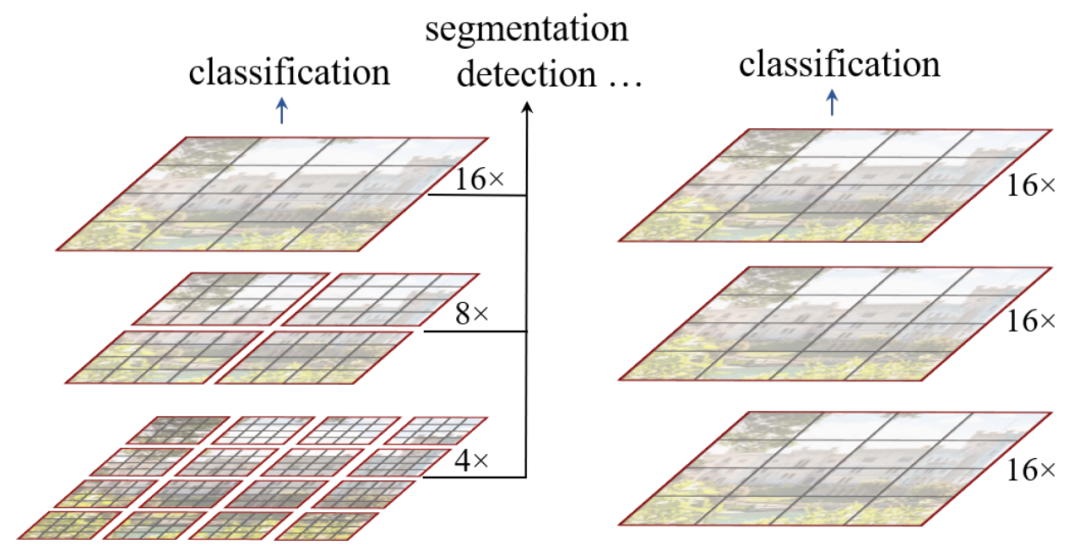
Swin Transformer VS VIT
在VIT中,Transformer生成的Feature Map是单一固定分辨率,并且由于对整张图片计算Self-Attention,因此它的计算复杂度随着输入图片大小的增加而平方级增加。
Swin Transformer只针对单个Local Window计算Self-Attention,并且每个Local windows的大小是固定的,因此它的计算复杂度与输入图片大小是线性关系;
不同层Layer之间类似于Pooling的Patch-Merging操作以及同层内的Local Window shift操作,使得Swin Transformer也具备类似于FPN的局部和全局的多尺度对象的建模能力。
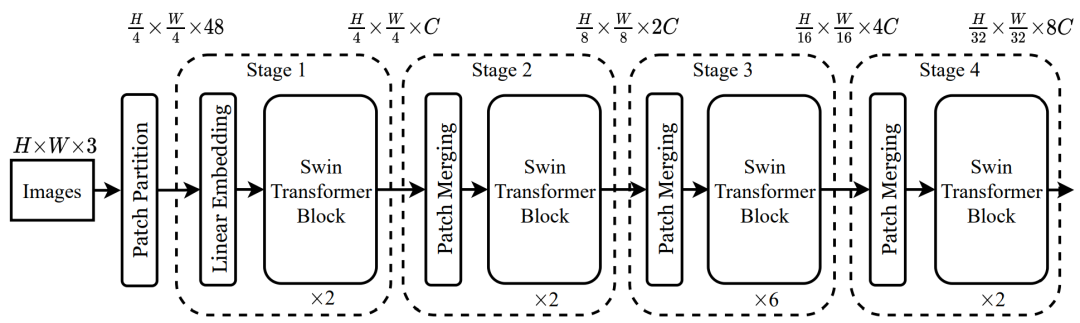
Overall Architecture
Swin Transformer的网络结构如下图所示。
首先它将Image(HxWx3)切分成一个个的小Patch,论文中每个Patch的大小是4x4,切分后的Patch维度为(H/4, W/4, 48=4x4x3);
然后,切分后的图像经过线性投射层(Linear Embedding Layer)将维度转换为(H/4, W/4, C);
之后,再经过Swin Transformer Block处理后,进行Patch Merging操作,再进入下一个Block;
Patch Merging
Patch Merging的具体做法如下:
“patch merging layer concatenates the features of each group of 2 × 2 neighboring patches, and applies a linear layer on the 4C-dimensional concatenated features. This reduces the number of tokens by a multiple of 2×2 = 4 (2× downsampling of resolution), and the output dimension is set to 2C.

图片来源:跟李沐学AI【1】
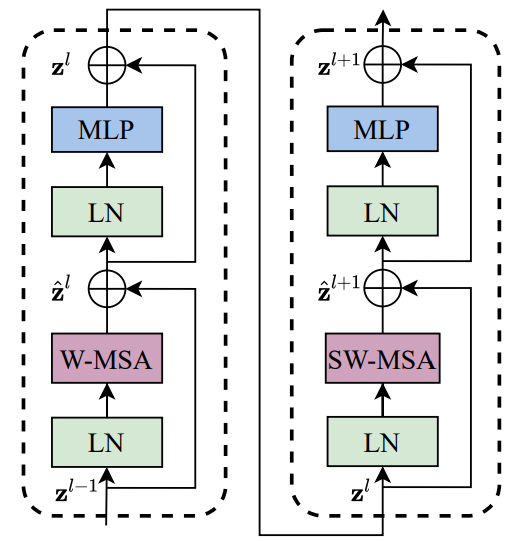
Swin Transformer Block
Swin Transformer Block包含两部分:标准的Multi-Head Self Attention(MSA)和使用shifted Window改造的Multi-Head Self Attention(MSA)。下图中的W-MSA是指基于窗口的多头自注意力。
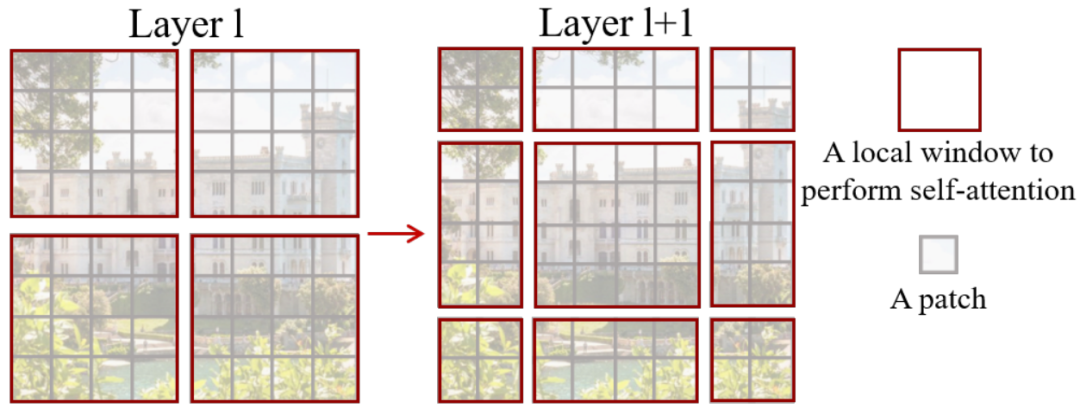
Shifted Window Partitioning
在Shift Windows之前(Layer l),Local Window的大小是相同的;在Shift Windows之后,Local Window的大小变得不一致了,并且Local Window的数量也由4个变成了9个,计算复杂度增加了2.25倍。
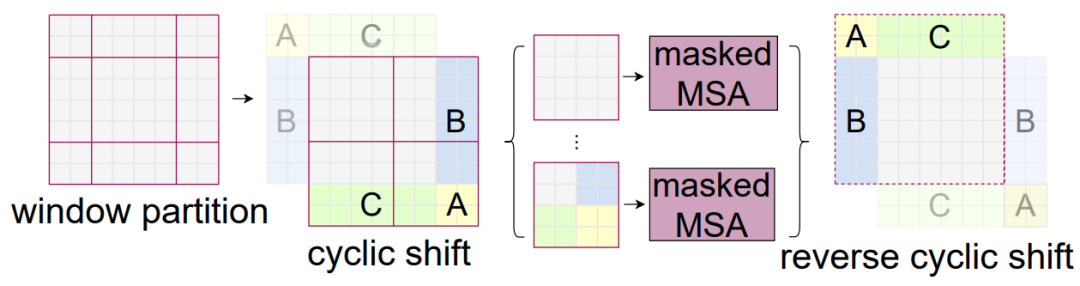
为了解决Shifted Windows后的计算量问题,论文中提出了Cyclic-Shift的方法(如下图所示),并通过Masked MSA来区分不相邻的图像区域。
Attention掩码的可视化效果如下:
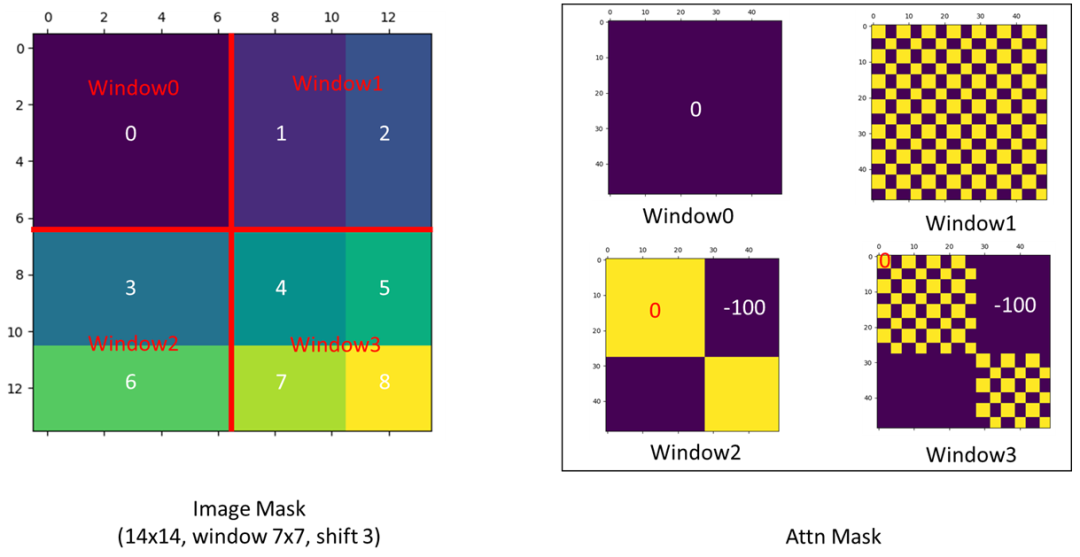
图片来源: https://github.com/microsoft/Swin-Transformer/issues/38
通过Cyclic-Shift的方法和巧妙设计的掩码方法,作者实现了仅用4个Windows一次前向传播就完成了所有计算,既没有增加窗口数量,也没有增加计算复杂度。
论文&代码
论文名称: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
论文链接: https://arxiv.org/pdf/2103.14030.pdf
代码链接: https://github.com/microsoft/Swin-Transformer
参考链接
1、https://www.bilibili.com/video/BV13L4y 1475U/?spm_id_from=333.999.0.0&vd_source =1d9b64fe4364c876447c45cfc4b99467
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号