2023年tuxera ntfs mac官方版 v2022中文版
原创
2023年tuxera ntfs mac官方版 v2022中文版
原创
用户10548106
发布于 2023-05-08 20:56:10
发布于 2023-05-08 20:56:10
当我们每次购买新的Mac时,它只能读取Windows NTFS格式的USB驱动器,那么如果要将文件添加、保存或写入Mac,您还需要附加的NTFS驱动程序。而tuxera ntfs mac官方版可以很好的帮助用户在Mac上打开,编辑,复制,移动或删除存储在Windows NTFS格式的USB驱动器上的文件,实现苹果Mac OS X系统读写Microsoft Windows NTFS文件系统,在硬盘、U盘等外接设备中进行全面访问、删除、修改等相关操作,同时还包括开源磁盘管理器等简单的格式和硬盘维修检查和修复。 并且,在tuxera ntfs mac官方版中还支持macOS 12 El Capitan以及磁盘管理等功能,在操作上带来更多的可能。对于经常需要对移动硬盘内容进行读写的人来说,这款工具软件无非是帮了大忙了,安装软件后,直接就可以对硬盘进行操作了就和在windows一样,感兴趣的朋友欢迎下载体验。
tuxera ntfs for mac介绍
一、基本功能 支持对Windows的NTFS外置存储器进行智能读取、修改操作 支持自动翻译文件名称 支持验证和修复NTFS卷 创建NTFS分区 创建NTFS磁盘映像 支持NTFS扩展属性 支持磁盘管理 挂载和取消挂载NTFS卷 二、软件兼容性 支持所有的NTFS版本 支持NTFS格式移动硬盘、U盘、磁盘等 支持32位内核模式 支持64位内核模式 任何第三方软件,兼容虚拟化和加密解决方案
tuxera ntfs for mac怎么用
首先打开该软件的主界面,如下图1所示,左侧是Mac系统磁盘列表,包括了虚拟磁盘、本地磁盘和外接磁盘,右侧是所选磁盘的具体信息和软件实用工具,包括了磁盘的验证、修复和格式转换。
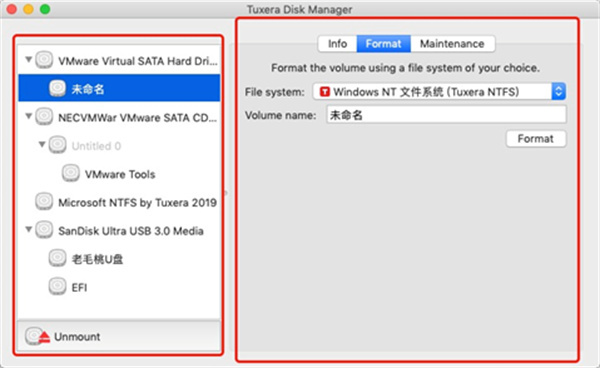
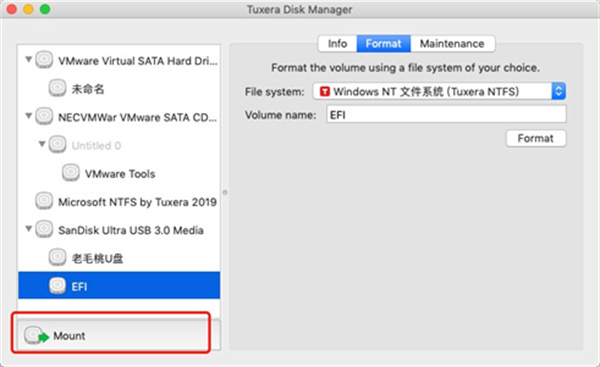
上图1左侧下方的“Unmount”按钮,通过它可以挂载或取消挂载磁盘,磁盘已被挂载时,此按钮显示为“Unmount”,磁盘未被挂载时按钮显示为“Mount”,如下图2。
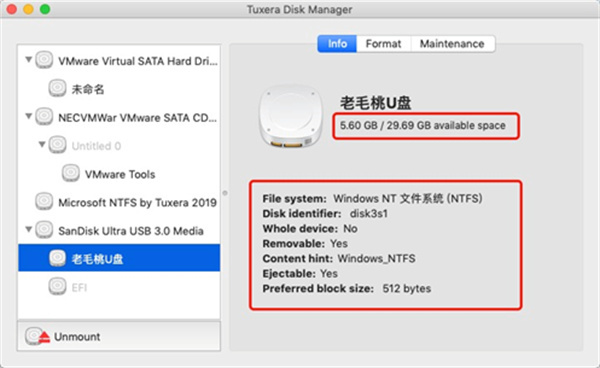
此时,选中左侧的某个磁盘,从右侧的“Info”项可以显示该所选磁盘的详细信息,如下图3。磁盘名字下方显示磁盘的总空间和剩余空间大小,右侧界面下方显示磁盘的文件系统格式、磁盘识别码、是否是完整的设备、是否可被移动、文件提示、是否可退出挂载和首选块字节大小。
第二项Format可对磁盘进行格式转换,其中的File System为要转换后的磁盘格式,Volume name为磁盘的名称,使用Tuxera NTFS For Mac软件可转换磁盘的格式如下图4红框所示。
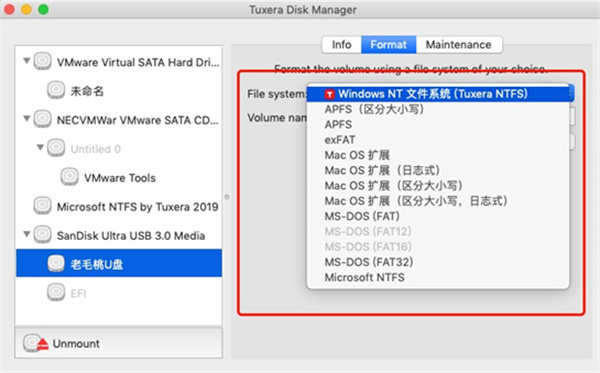
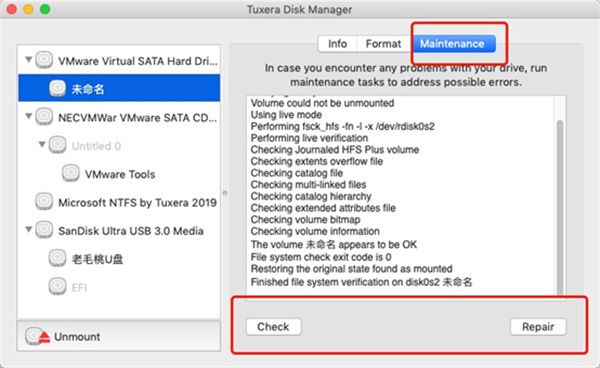
1、第一个和最后一个为NTFS格式,是Windows支持读写的格式,在Mac上不支持读写; 2、第二和第三个为APFS格式,是Mac系统支持读写的格式,这里所谓的区分大小写,指的是在Mac系统上,认为at.txt和AT.txt文件是不是不同的文件,一般需要选区分大小写; 3、第四个是exFAT格式,为FAT32的升级格式,支持Mac系统和Windows系统双系统读写,一般在外接磁盘上需要选择该格式,是非常重要的格式,缺点是无法对低版本的Windows系统做兼容,如Windows XP系统,不过7以上就开始兼容了,只要不是特别旧的电脑系统都是可以的。 4、第五到第八个是Mac OS扩展格式,区别在于是否支持日志功能和是否区分大小写,这里支持日志功能以后,会把系统启动,软件安装及故障等保存为日志文件,但会占用磁盘空间。 5、最后第九到第十二为MS-DOS格式,支持DOS命令行操作系统,是计算机系统早期的一种文件系统,现在非常少用。最后要介绍的是“Maintenance”项,这一项用于验证磁盘和磁盘修复,如下图5,下方的“Check”按钮用于磁盘验证检查,“Repair”按钮用于磁盘错误修复,使用起来也是傻瓜式操作,非常简单。
以上就是关于NTFS For Mac软件怎么用以及如何正确使用的相关教程了,希望本教程能对使用该软件的大家带来帮助,关于本软件,大家可到软件中文网站上了解更多详细信息。
软件特色
1、在Mac上读写Windows NTFS文件系统 tuxera ntfs 2016提供完全读写NTFS磁盘功能,并兼容跨越Mac和Windows平台。实现苹果Mac OS X系统读写Microsoft Windows NTFS文件系统,在硬盘、U盘等外接设备中进行全面访问、删除、修改等相关操作。 2、快速全面的数据保护 tuxera ntfs 2016提供了最快的NTFS文件传输速度,同时保护您的数据是最新的智能缓存。 3、超强兼容性 支持所有从OS X 10.4 Tiger开始的Mac平台,包括OS X El Capitan、macOS 10.12 (Sierra)。 同时兼容流行的虚拟化和加密解决方案,包括Parallels Desktop和VMware Fusion。
软件亮点
1、快速全面的数据保护 Tuxera NTFS提供了最快的NTFS文件传输速度,同时保护您的数据师最新的智能缓存。 2、挂载和取消挂载 NTFS 卷 在完成安装之后,会覆盖系统内置的 NTFS 驱动并且自动挂载连接系统 的 NTFS 卷。任何苹果 NTFS 挂载的卷应该被挂载,无需任何用户的干预。 3、创建 NTFS 文件系统 Tuxera NTFS for Mac 集成了用于创建文件系统的操作系统实用程序。在OS X 10.11,可以使用 Tuxera Disk Manager 创建和格式化 NTFS 文件系统。 4、检查和修复 NTFS 文件系统 Tuxera NTFS for Mac 包含 Tuxera 的 NTFS 修复工具--ntfsck,如果你的 NTFS 卷无法挂载或出现问题,可以使用该工具。如果正在运行 El Capitan,可以使用Tuxera Disk Manager 及其“维护”选项卡检查和修复驱动器。
下载地址
Tuxera NTFS for Mac- 2022-安装包:https://souurl.cn/QLBotD
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号