K8s Pod优雅关闭,没你想象的那么简单!

K8s Pod优雅关闭,没你想象的那么简单!

用户5166556
发布于 2023-03-18 14:18:30
发布于 2023-03-18 14:18:30
更新部署服务时,旧的 Pod 会终止,新 Pod 上位。如果在这个部署过程中老 Pod 有一个很长的操作,我们想在这个操作成功完成后杀死这个 pod(优雅关闭),如果无法做到的话,被杀死的 pod 可能会丢失一定的流量,或者外界无法感知到该 Pod 被杀死。特别是,如果我们有一个接收大量流量的 API,错误率在部署过程中会显著增加。
其实这也挺简单的,添加一个优雅关闭就行了,之前写过优雅关闭的最佳实践K8S Pod流量的优雅无损切换实践,后来在发现还是不够优雅........
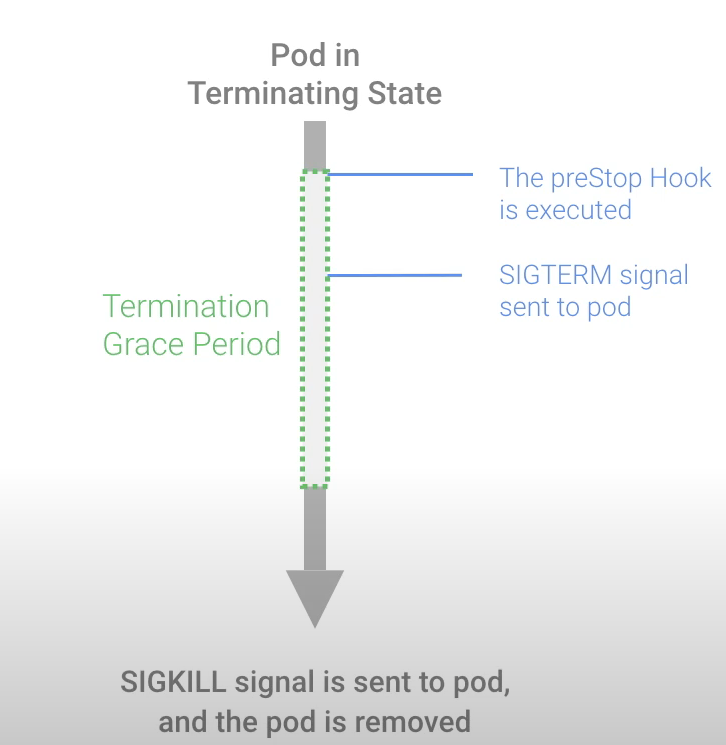
当 Kubernetes 杀死一个 pod 时,会发生以下 5 个步骤:
1、 Pod 切换到终止状态并停止接收任何新流量,容器仍在 pod 内运行。
2、 preStop 钩子是一个特殊的命令或 HTTP 请求被执行,并被发送到 pod 内的容器。
3、 SIGTERM 信号被发送到 pod,容器意识到它将很快关闭。
4、 Kubernetes 等待宽限期 (terminationGracePeriodSeconds)。此等待与 preStop hook 和 SIGTERM 信号执行并行(默认 30 秒)。因此,Kubernetes 不会等待这些完成。如果这段时间结束,则直接进入下一步。正确设置宽限期的值非常重要。
5、向 pod 发送 SIGKILL 信号,然后移除 pod。如果容器在宽限期后仍在运行,则 Pod 被 SIGKILL 强行移除,终止完成。
总结下大致分为两步,第一步定义 preStop,一般情况下可以休眠 30s,用于处理残余流量;第二步发送 SIGTERM 信号,服务收到信号后进行服务的收尾工作处理。比如:关闭连接、通知第三方注册中心服务关闭.....
有同学疑问,既然 pod 已经终止了,同时 K8s 的网络 endpoint 也摘除了,为什么还会进来流量呢?
因为这个网络接口的摘除是异步的,这也是为什么会首先执行 preStop,然后发送 SIGTERM 信号的原因所在。
这样做基本上能够保证流量无损,但是这样做的前提是服务能够收到 SIGTERM 信号。
理想情况下,一个容器只有一个进程,但是在现实场景下很难做到,比如,我会用一个 shell 脚本去管理和启动 Java 进程,除了 shell 脚本主进程之外,还要运行监控、日志收集等子进程,这样一个容器里面就运行了多个进程。
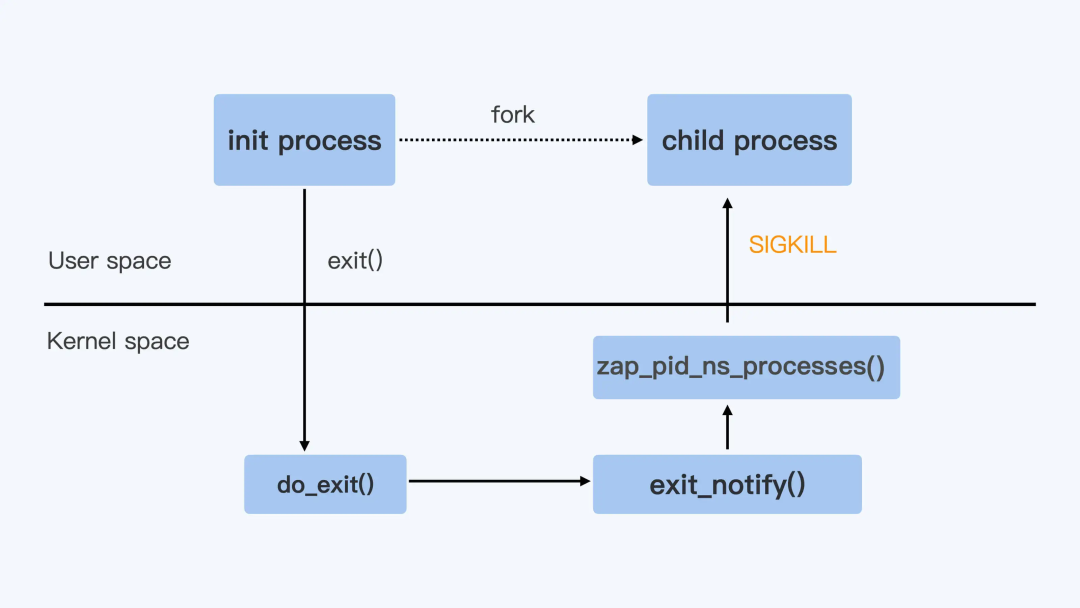
系统底层默认会向主进程发送 SIGTERM 信号,而对剩余子进程发送 SIGKILL 信号。系统这样做的大概原因是因为大家在设计主进程脚本的时候都不会进行信号的捕获和传递,这会导致容器关闭时,多个子进程无法被正常终止,所以系统使用 SIGKILL 这个不可屏蔽信号,而是为了能够在没有任何前提条件的情况下,能够把容器中所有的进程关掉。
具体可以使用strace -p pid去跟踪服务调用情况。
也就是说如果主进程自身不是服务本身,可能会导致是被强制Kill的,解决的方法也很简单,也就是在主进程中对收到的信号做个转发,发送到容器中的其他子进程,这样容器中的所有进程在停止时,都会收到 SIGTERM,而不是 SIGKILL 信号了。
具体如何实现呢?比如下面的trap信号,就是一种实现方式,这里有一篇最佳实践http://veithen.io/2014/11/16/sigterm-propagation.html。
#startup.sh
...
trap 'kill -TERM $child' TERM
nohup java $JAVA_OPTS -jar ./xxx.jar --server.port=8080 &
child=$!
wait $child
wait $child当然很多成熟的框架都实现了优雅关闭功能,比如spring的CustomHealthCheck类扩展了AbstractHealthIndicator类,并允许我们通过覆盖doHealthCheck()方法来构建自定义健康检查结构。根据我们从HealthService收到的标志,我们将系统的健康状态设置为up或down。
这样的话,我们可以通过preStop调用该接口实现另外一种方式的优雅关闭。
lifecycle:
preStop:
httpGet:
path: /unhealthy
port: http最后服务端收到优雅关闭信号后可以进行一些善后处理工作。
这就是K8s,自身很简单,但是它的低层牵涉了Linux内核、进程、网络、存储等方方面面的知识,但并不会在Kubernetes的文档中交代清楚。可偏偏就是它们,才是容器技术的精髓所在。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2021-09-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号