三、数据结构:向量
原创

生信技能树学习之数据结构:向量
数据结构包括:向量 数据框 矩阵 列表
一、向量定义。
数据框中单独拿出来的一列就是向量,视为一个整体。一串同一类型的数据。
一个向量只能有一种数据类型,可以有重复值。
二、向量的生成
2.1 用合集直接生成
用 c() 逐一放到一起,结合到一起
c(2,5,6,2,9) #数值型向量[1] 2 5 6 2 9
c("a","f","md","b") ##字符型向量[1] "a" "f" "md" "b"
2.2 连续的数字用冒号“:”
1:5 [1] 1 2 3 4 5
2.3 有重复的用rep(),有规律的序列用seq(),随机数用rnorm()
rep("x",times=3) [1] "x" "x" "x"
seq(from=3,to=21,by=3) [1] 3 6 9 12 15 18 21
rnorm(n=3) ##随机数,每次运行出来,结果都不一样。[1] 0.5240832 -1.9169955 -1.5442292
2.4 通过组合,产生更为复杂的向量。
paste0(rep("x",times=3),1:3) [1] "x1" "x2" "x3"
paste0 无缝连接,一一对应的连接 paste 有缝连接
paste(rep("x",times=3),1:3) [1] "x 1" "x 2" "x 3"
paste默认的分割符是空格sep=" "(冒号里面是空格) 可以改成其他任何东西, eg: sep=","
paste(rep("x",times=3),1:3,sep = ",")[1]"x,1""x,2""x,3"
练习题: # 1.生成1到15之间所有偶数
seq(from = 1,to = 15,by = 2) ### [1] 1 3 5 7 9 11 13 15
seq(from = 2,to = 15,by = 2) ### [1] 2 4 6 8 10 12 14#2.1生成向量,内容为:"student2" "student4" "student6" "student8" "student10" "student12" "student14"
提示:用paste0 ##无缝连接
paste0(rep("student",times = 7),seq(from = 2, to = 15,by = 2))[1] "student2" "student4" "student6" "student8" "student10" "student12" "student14"
注意:times输入的数值会按rep和seq的最大数值发生循环补齐。
# 3.将两种不同类型的数据用c()组合在一起,看输出结果
c(1,"a") ### [1] "1" "a" 数值型和字符型放在一起输出时,数值型会转换为字符型
c(TRUE,"a") ### [1] "TRUE" "a" 逻辑性和字符型放在一起输出时,逻辑性转换为字符型
c(1,TRUE) ### [1] 1 1 逻辑型和数值型放在一起输出时,逻辑性转换为数值型。TRUE 转为1,FALSE转换为0,
as.numeric(TRUE) ### [1] 1
as.numeric(FALSE) ### [1] 0三、对单个向量进行的操作
3.1 赋值给一个变量名
x = c(1,3,5,1) #随意的写法
x[1] 1 3 5 1
x <- c(1,3,5,1) #规范的赋值符号 Alt+减号
x[1] 1 3 5 1
###赋值+输出一起实现
x <- c(1,3,5,1);x ##[1] 1 3 5 1
(x <- c(1,3,5,1)) ##[1] 1 3 5 13.2 简单数学计算
> x+1 [1] 2 4 6 2
> log(x) [1] 0.000000 1.098612 1.609438 0.000000
> sqrt(x) [1] 1.000000 1.732051 2.236068 1.000000
3.3 根据某条件进行判断,生成等长的逻辑型向量
> x>3 [1] FALSE FALSE TRUE FALSE
> x==3 [1] FALSE TRUE FALSE FALSE
3.4 初级统计
> max(x) #最大值 [1] 5
> min(x) #最小值 [1] 1
> mean(x) #均值 [1] 2.5
> median(x) #中位数 [1] 2
> var(x) #方差 [1] 3.666667
> sd(x) #标准差 [1] 1.914854
> sum(x) #总和 [1] 10
> length(x) #长度 [1] 4
> unique(x) #去重复 [1] 1 3 5 一个向量从左向右看,第一次出现叫做没重复,第二次或第多次出现叫重复。
> duplicated(x) #判断对应元素是否重复,没重复返回FALSE,重复返回TRUE,即第一次出现返回FALSE。
[1] FALSE FALSE FALSE TRUE
> table(x) #重复值统计
x
1 3 5
2 1 1
> sort(x) [1] 1 1 3 5 默认值decreasing = FALSE
> sort(x,decreasing = F) [1] 1 1 3 5
> sort(x,decreasing = T) [1] 5 3 1 1
## R语言里的函数思想:能用函数代替,就不要用手去数,除非这个代码只用一次。
四、对两个向量进行的操作
> x = c(1,3,5,1)
> y = c(3,2,5,6)
4.1 比较运算,生成等长的逻辑向量
> x == y [1] FALSE FALSE TRUE FALSE
> y == x [1] FALSE FALSE TRUE FALSE ###x和y写的先后顺序没有影响。
4.2 数学计算
> x + y [1] 4 5 10 7
4.3 连接
> paste(x,y,sep=",") [1] "1,3" "3,2" "5,5" "1,6"
#paste与paste0的区别. paste0无缝连接 paste有缝连接,可以设置成无缝。
paste的sep值默认的是空格,paste0的sep值默认的没有空格
> paste(x,y) [1] "1 3" "3 2" "5 5" "1 6"
> paste0(x,y) [1] "13" "32" "55" "16"
> paste(x,y,sep = "") [1] "13" "32" "55" "16"
> paste(x,y,sep = ",") [1] "1,3" "3,2" "5,5" "1,6"
#当两个向量长度不一致
x = c(1,3,5,6,2)
y = c(3,2,5)
x == y [1] FALSE FALSE TRUE FALSE TRUE
Warning message: In x == y : 长的对象长度不是短的对象长度的整倍数
#循环补齐
#利用循环补齐简化代码 就是当x和y不一样长时,发生循环补齐。
paste0(rep("x",3),1:3) [1] "x1" "x2" "x3"
paste0("x",1:3) [1] "x1" "x2" "x3"
4.4 交集、并集、差集
intersect(x,y) ### 交集 [1] 3 5 2
union(x,y) ### 合集 [1] 1 3 5 6 2 ###取交集或者合集的时候会自动去重复。
setdiff(x,y) ### 指仅在x中存在,不在y中存在的元素 [1] 1
setdiff(y,x) ### 指仅在y中存在,不在x中存在的元素 [1] 1 6
x %in% y ### x的每个元素在y中存在吗,返回的逻辑值和前面的一样,谁在前面就是按照谁的长度生成逻辑值。
[1] FALSE TRUE TRUE FALSE TRUE
y %in% x ### y的每个元素在x中存在吗
[1] TRUE TRUE TRUE
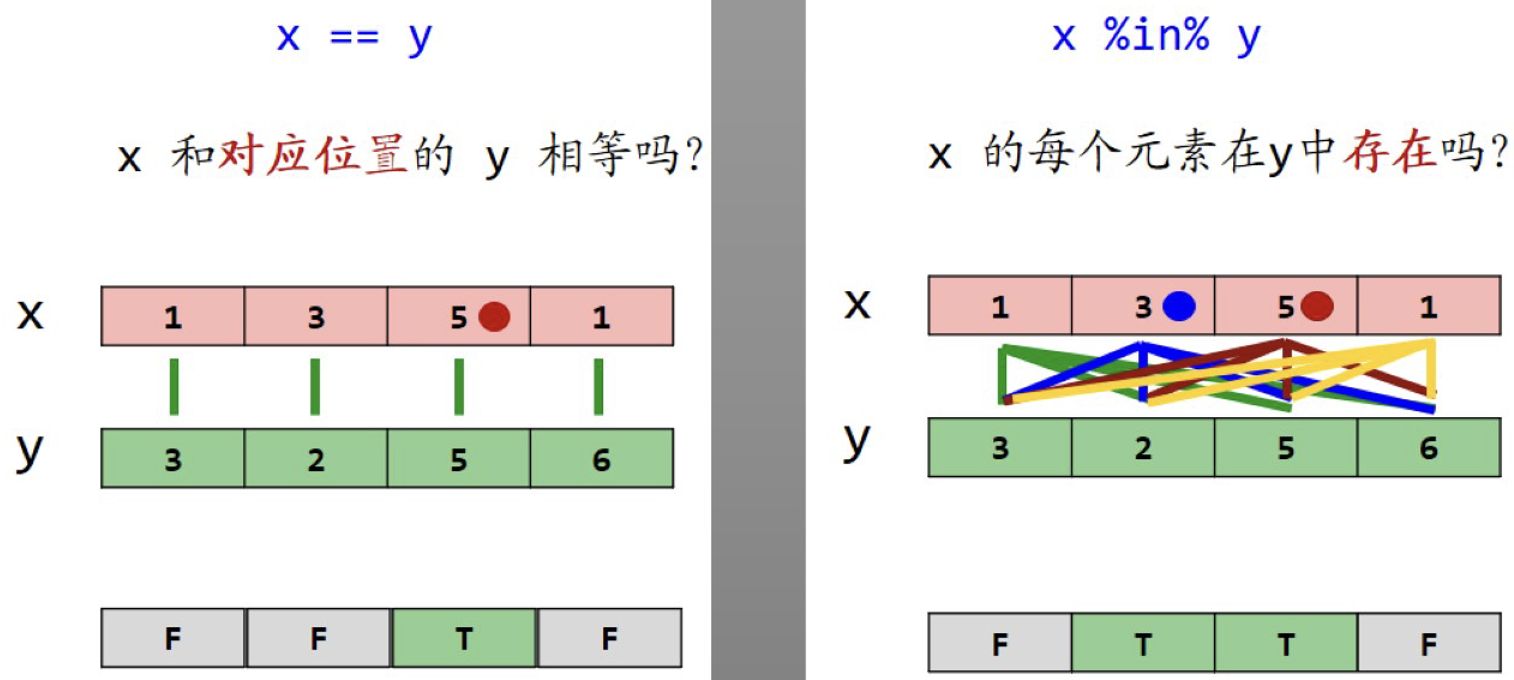
==和%in%的区别
五、向量取子集
> x <- 8:12 [1] 8 9 10 11 12.
5.1 根据逻辑值取子集
[] 默认的是将TRUE对应的值挑选出来,FALSE丢弃
> x[x==10] [1] 10
> x[x<12] [1] 8 9 10 11
> x[x %in% c(9,13)] [1] 9
5.2 根据位置取子集
下标,第几个元素下标就是几。
> x[4] ## 取出x中的第四个元素。 [1] 11
> x[2:4] [1] 9 10 11 ## 取出x中的第2和4个元素
> x[c(1,5)] [1] 8 12
> x[-4] [1] 8 9 10 12
> x[-(2:4)] [1] 8 12
按照逻辑值取向量时:中括号里是与x等长且一一对应的逻辑值向量;
按照位置取向量时:中括号里是由x的下标组成的向量。

2:4是单独的向量能单独运行,而1,5不是向量,不能运行,所以不能单独用来取子集。
从13个球中选出颜色是蓝色和绿色的球。13个球的颜色赋值给x,“蓝色”和“绿色”赋值给y
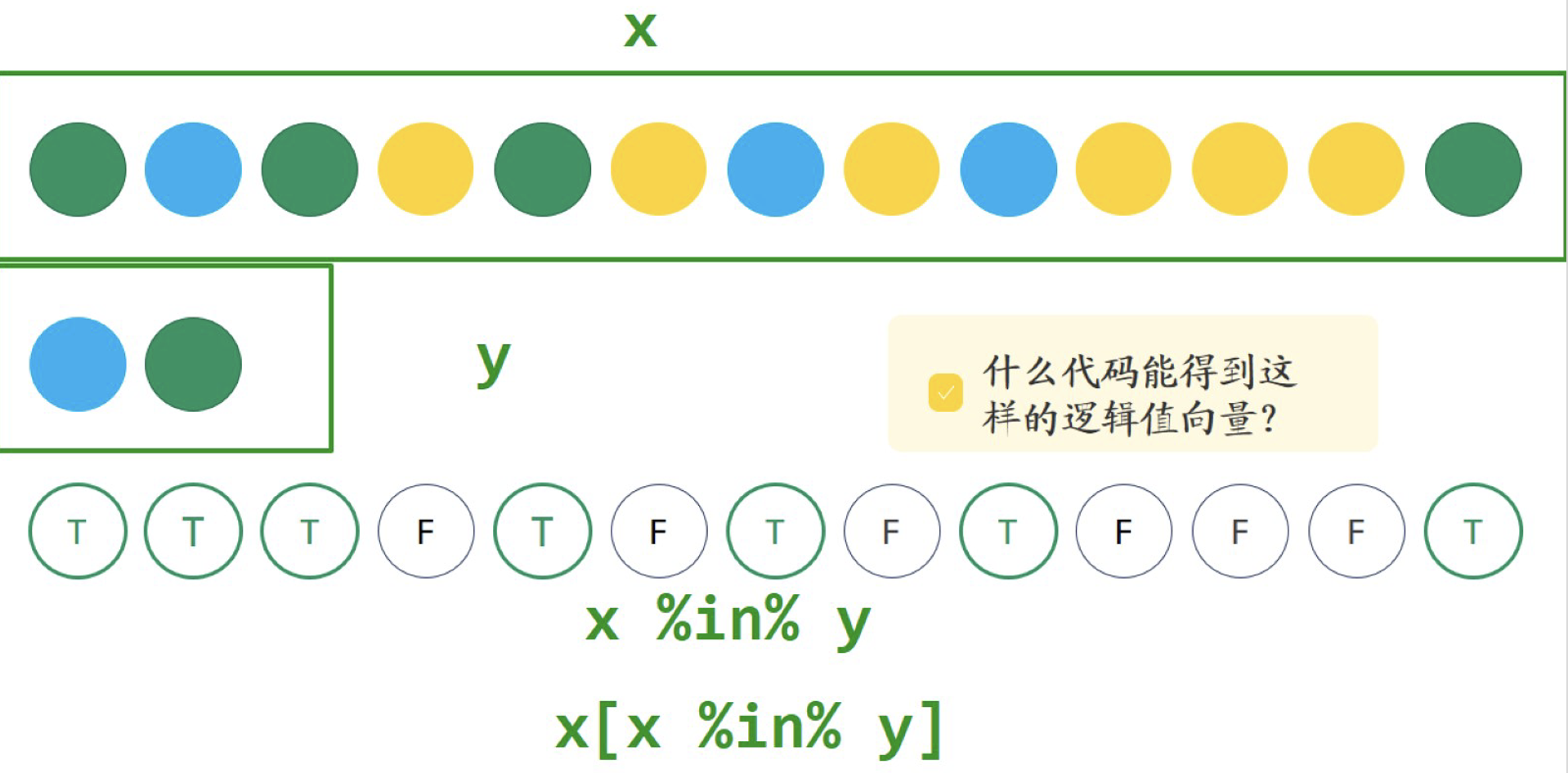
==不能用,是因为==要求位置相等,要求第一个是蓝色,第二个是绿色的
六、修改向量中的某个/某些元素:取子集+赋值
> x [1] 8 9 10 11 12
R语言里的所有修改都要经过赋值,没有赋值就相当于没有发生过。
6.1 改一个元素
x[4] <- 40 #把第四个元素改成40> x [1] 8 9 10 40 12
6.2 改多个元素
> x[c(1,5)] <- c(80,20) #把第一个元素改成80,把第二个元素改成20
> x [1] 80 9 10 40 20
七、简单向量作图
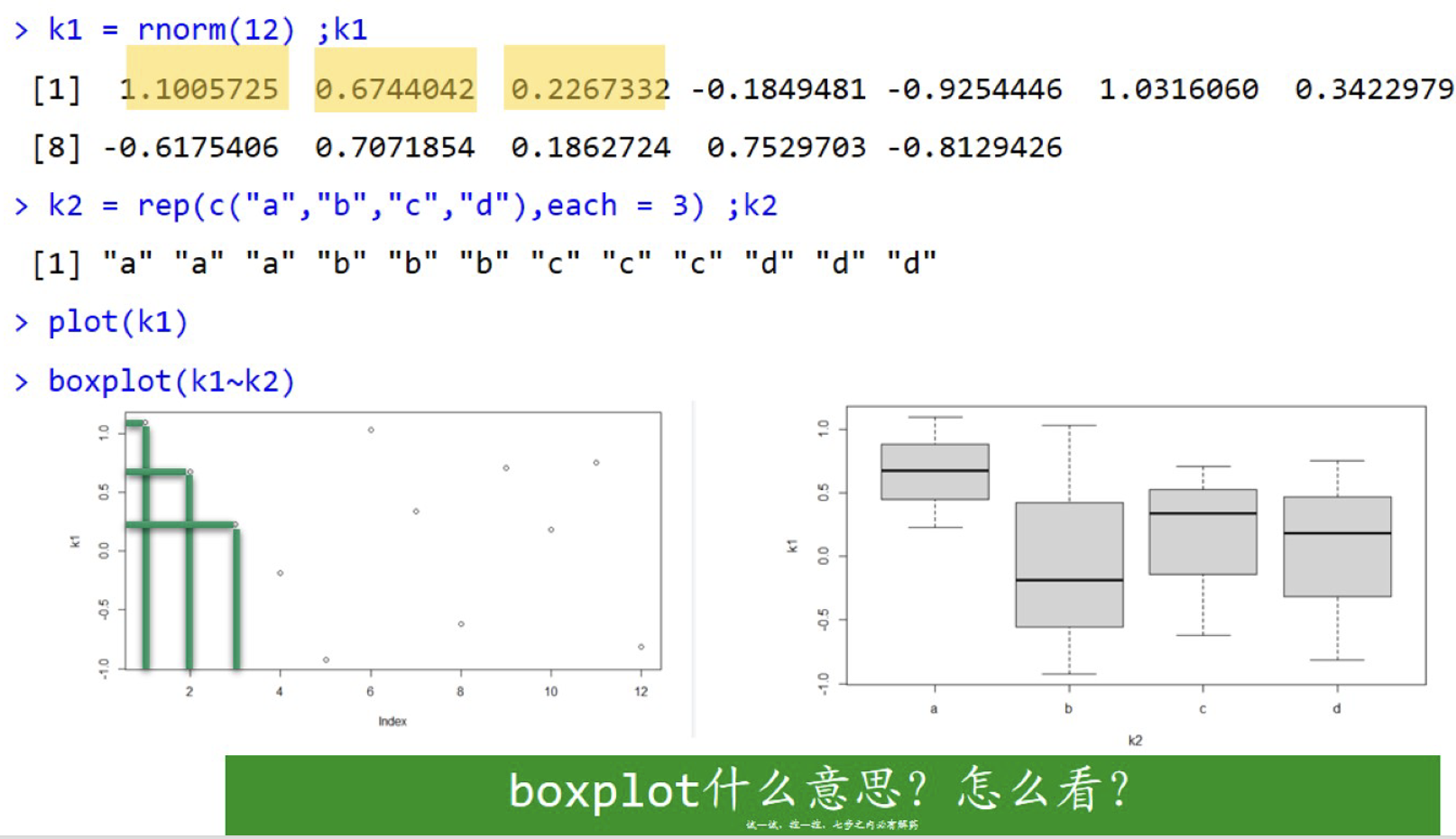
k1 = rnorm(12);k1
k2 = rep(c("a","b","c","d"),each = 3);k2
plot(k1) ### K1做了纵坐标而k1的下标默认做了横坐标。
boxplot(k1~k2) ###默认k1是纵坐标,k2是横坐标。[1] 0.8005420 1.2091388 1.2006316 -0.6671420 -0.3112836 1.1842604 0.3015444 0.6596160
[9] 0.8199846 -1.6260995 1.7780082 -0.3889134
[1] "a" "a" "a" "b" "b" "b" "c" "c" "c" "d" "d" "d"
# 练习题:运行load("gands.Rdata"),即可得到和使用我准备的向量g和s,如报错,说明你的代码写错或project没有正确打开
load("gands.Rdata")
# 1.用函数计算向量g的长度
length(g)
# 2.筛选出向量g中下标为偶数的基因名。
seq(2,100,2) ###先写出为偶数的下标
g[seq(2,100,2)]# 3.向量g中有多少个元素在向量s中存在(要求用函数计算出具体个数)?将这些元素筛选出来 # 提示:%in%
table(g%in%s)
g[g%in%s]# 4.生成10个随机数: rnorm(n=10,mean=0,sd=18),用向量取子集的方法,取出其中小于-2的值
z=rnorm(n=10,mean=0,sd=18)
z
z[z< -2]
z[z< (-2)]补充知识点
(1:10)[c(T,F)] [1]1,3,5,7,9
(1:10)[c(F,T)] [1]2,4,6,8,10
(1:10)[c(T,F,T,F,T,F,T,F,T,F)] [1]1,3,5,7,9 ###发生了循环补齐原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号