湖仓一体电商项目(十):业务实现之编写写入DWD层业务代码
原创
湖仓一体电商项目(十):业务实现之编写写入DWD层业务代码
原创
Lansonli
发布于 2022-09-09 07:58:41
发布于 2022-09-09 07:58:41
业务实现之编写写入DWD层业务代码
DWD层数据主要存储干净的明细数据,这里针对ODS层“KAFKA-ODS-TOPIC”数据编写代码进行清洗写入对应的Kafka topic和Iceberg-DWD层中。代码功能中有以下几点重要方面:
- 针对Kafka ODS层中的数据进行清洗,写入Iceberg-DWD层中。
- 将数据除了写入Iceberg-DWD层中之外,还要写入Kafka中方便后续处理得到DWS层数据。
一、代码编写
编写处理Kafka ODS层数据写入Iceberg-DWD层数据时,由于在Kafka “KAFKA-ODS-TOPIC”topic中每条数据都已经有对应写入kafka的topic信息,所以这里我们只需要读取“KAFKA-ODS-TOPIC”topic中的数据写入到Iceberg-DWD层中,另外动态获取每条数据写入Kafka topic信息将每条数据写入到对应的topic即可。
具体代码参照“ProduceODSDataToDWD.scala”,大体代码逻辑如下:
case class DwdInfo (iceberg_ods_tbl_name:String,kafka_dwd_topic:String,browse_product_code:String,browse_product_tpcode:String,user_ip:String,obtain_points:String,user_id1:String,user_id2:String, front_product_url:String, log_time:String, browse_product_url:String ,id:String,ip:String, login_tm:String,logout_tm:String)
object ProduceODSDataToDWD {
private val kafkaBrokers: String = ConfigUtil.KAFKA_BROKERS
def main(args: Array[String]): Unit = {
//1.准备环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
env.enableCheckpointing(5000)
import org.apache.flink.streaming.api.scala._
/**
* 2.需要预先创建 Catalog
* 创建Catalog,创建表需要在Hive中提前创建好,不在代码中创建,因为在Flink中创建iceberg表不支持create table if not exists ...语法
*/
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
/**
* 2.创建 Kafka Connector,连接消费Kafka ods中数据
*/
tblEnv.executeSql(
"""
|create table kafka_ods_tbl(
| iceberg_ods_tbl_name string,
| kafka_dwd_topic string,
| data string
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-ODS-TOPIC',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='latest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
val odsTbl :Table = tblEnv.sqlQuery(
"""
| select iceberg_ods_tbl_name,data,kafka_dwd_topic from kafka_ods_tbl
""".stripMargin)
val odsDS: DataStream[Row] = tblEnv.toAppendStream[Row](odsTbl)
//3.设置Sink 到Kafka 数据输出到侧输出流标记
val kafkaDataTag = new OutputTag[JSONObject]("kafka_data")
/**
* 4.表准换成对应的DataStream数据处理,清洗ODS 中的数据,存入Iceberg
* {
* "iceberg_ods_tbl_name": "ODS_BROWSELOG",
* "data": "{\"browseProductCode\":\"yyRAteviDb\",\"browseProductTpCode\":\"120\",\"userIp\":\"117.233.5.190\",\"obtainPoints\":\"24\",
* \"userId\":\"uid464936\",\"frontProductUrl\":\"https://1P//2RQbHFS2\",\"logTime\":\"1647065858856\",\"browseProductUrl\":\"https://RXm/iOUxR/Tliu9TE0\"}",
* "kafka_dwd_topic": "KAFKA-DWD-BROWSE-LOG-TOPIC"
* }
*
* {
* "iceberg_ods_tbl_name": "ODS_USER_LOGIN",
* "data": "{\"database\":\"lakehousedb\",\"xid\":\"14942\",\"user_id\":\"uid283876\",\"ip\":\"215.148.233.254\",\"commit\":\"true\",
* \"id\":\"10052\",\"type\":\"insert\",\"logout_tm\":\"1647066506140\",\"table\":\"mc_user_login\",\"ts\":\"1647066504\",\"login_tm\":\"1647051931534\"}",
* "kafka_dwd_topic": "KAFKA-DWD-USER-LOGIN-TOPIC"
* }
*
* 这里将数据转换成DataStream后再转换成表写入Iceberg
*
*/
//对数据只是时间进行清洗,转换成DwdInfo 类型DataStream 返回,先过滤一些数据为null的
val dwdDS: DataStream[DwdInfo] = odsDS.filter(row=>{row.getField(0)!=null && row.getField(1)!=null &&row.getField(2)!=null })
.process(new ProcessFunction[Row,DwdInfo]() {
override def processElement(row: Row, context: ProcessFunction[Row, DwdInfo]#Context, collector: Collector[DwdInfo]): Unit = {
val iceberg_ods_tbl_name: String = row.getField(0).toString
val data: String = row.getField(1).toString
val kafka_dwd_topic: String = row.getField(2).toString
val jsonObj: JSONObject = JSON.parseObject(data)
//清洗日期数据
jsonObj.put("logTime",DateUtil.getDateYYYYMMDDHHMMSS(jsonObj.getString("logTime")))
jsonObj.put("login_tm",DateUtil.getDateYYYYMMDDHHMMSS(jsonObj.getString("login_tm")))
jsonObj.put("logout_tm",DateUtil.getDateYYYYMMDDHHMMSS(jsonObj.getString("logout_tm")))
//解析json 嵌套数据
val browse_product_code: String = jsonObj.getString("browseProductCode")
val browse_product_tpcode: String = jsonObj.getString("browseProductTpCode")
val user_ip: String = jsonObj.getString("userIp")
val obtain_points: String = jsonObj.getString("obtainPoints")
val user_id1: String = jsonObj.getString("user_id")
val user_id2: String = jsonObj.getString("userId")
val front_product_url: String = jsonObj.getString("frontProductUrl")
val log_time: String = jsonObj.getString("logTime")
val browse_product_url: String = jsonObj.getString("browseProductUrl")
val id: String = jsonObj.getString("id")
val ip: String = jsonObj.getString("ip")
val login_tm: String = jsonObj.getString("login_tm")
val logout_tm: String = jsonObj.getString("logout_tm")
//往各类数据 data json 对象中加入sink dwd topic 的信息
jsonObj.put("kafka_dwd_topic",kafka_dwd_topic)
context.output(kafkaDataTag,jsonObj)
collector.collect(DwdInfo(iceberg_ods_tbl_name, kafka_dwd_topic, browse_product_code, browse_product_tpcode, user_ip, obtain_points,
user_id1,user_id2, front_product_url, log_time, browse_product_url, id, ip, login_tm, logout_tm))
}
})
val props = new Properties()
props.setProperty("bootstrap.servers",kafkaBrokers)
/**
* 6.将以上数据写入到Kafka 各自DWD 层topic中,这里不再使用SQL方式,而是直接使用DataStream代码方式 Sink 到各自的DWD层代码中
*/
dwdDS.getSideOutput(kafkaDataTag).addSink(new FlinkKafkaProducer[JSONObject]("KAFKA-DWD-DEFAULT-TOPIC",new KafkaSerializationSchema[JSONObject] {
override def serialize(jsonObj: JSONObject, aLong: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
val sinkDwdTopic: String = jsonObj.getString("kafka_dwd_topic")
new ProducerRecord[Array[Byte], Array[Byte]](sinkDwdTopic,null,jsonObj.toString.getBytes())
}
},props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))
env.execute()
}
}二、创建Iceberg-DWD层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1、在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;2、创建Iceberg表
这里创建Iceberg-DWD表有“DWD_USER_LOGIN”,创建语句如下:
CREATE TABLE DWD_USER_LOGIN (
id string,
user_id string,
ip string,
login_tm string,
logout_tm string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWD_USER_LOGIN/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);三、代码测试
以上代码编写完成后,代码执行测试步骤如下:
1、在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-DWD-USER-LOGIN-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWD-USER-LOGIN-TOPIC --partitions 3 --replication-factor 3
#监控以上topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DWD-USER-LOGIN-TOPIC2、将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
3、执行代码,查看对应结果
以上代码执行后在,在对应的Kafka “KAFKA-DWD-USER-LOGIN-TOPIC” topic中都有对应的数据。在Iceberg-DWD层中对应的表中也有数据。
Kafka中结果如下:
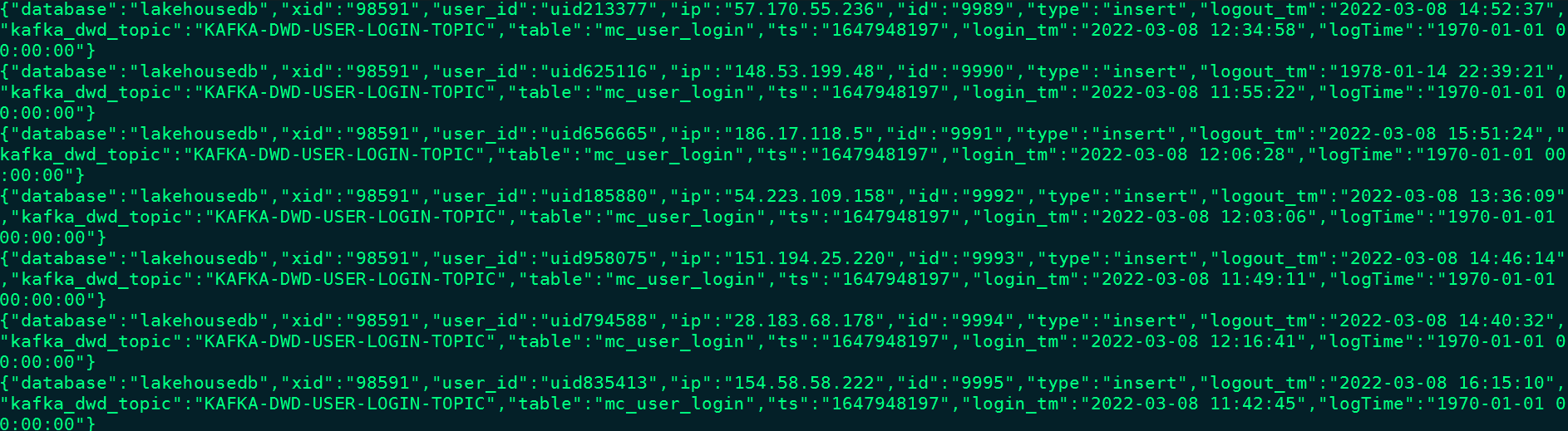
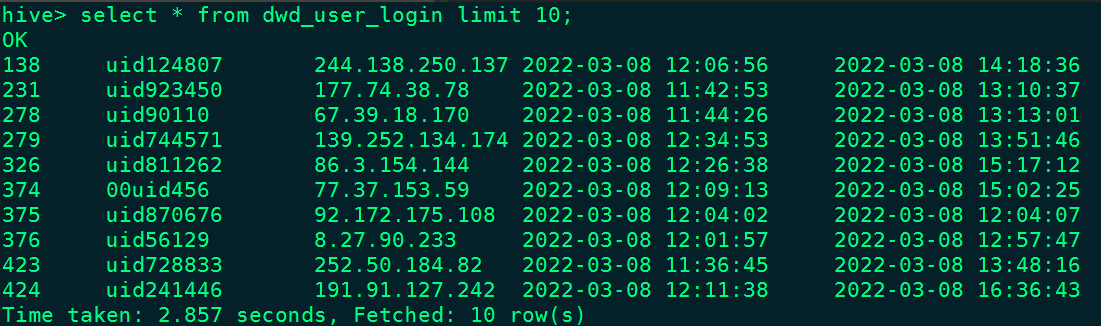
Iceberg-DWD层表”DWD_USER_LOGIN”中的数据如下:
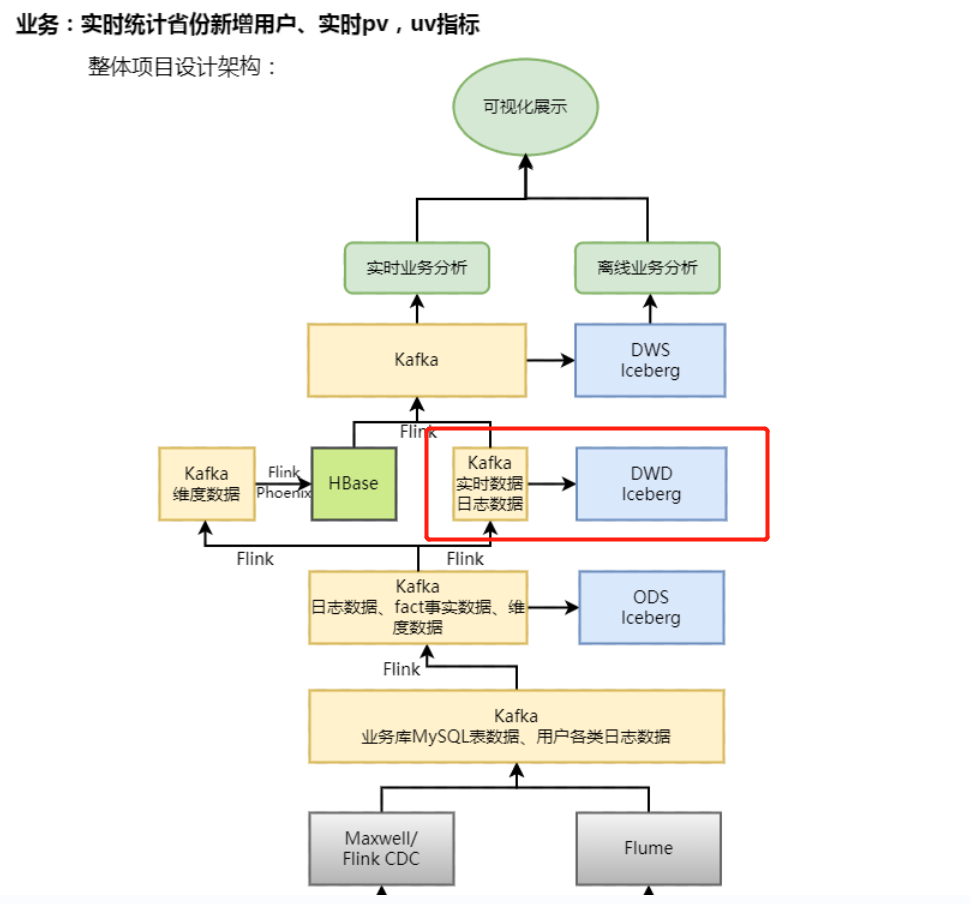
四、架构图
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号