前提条件
创建作业
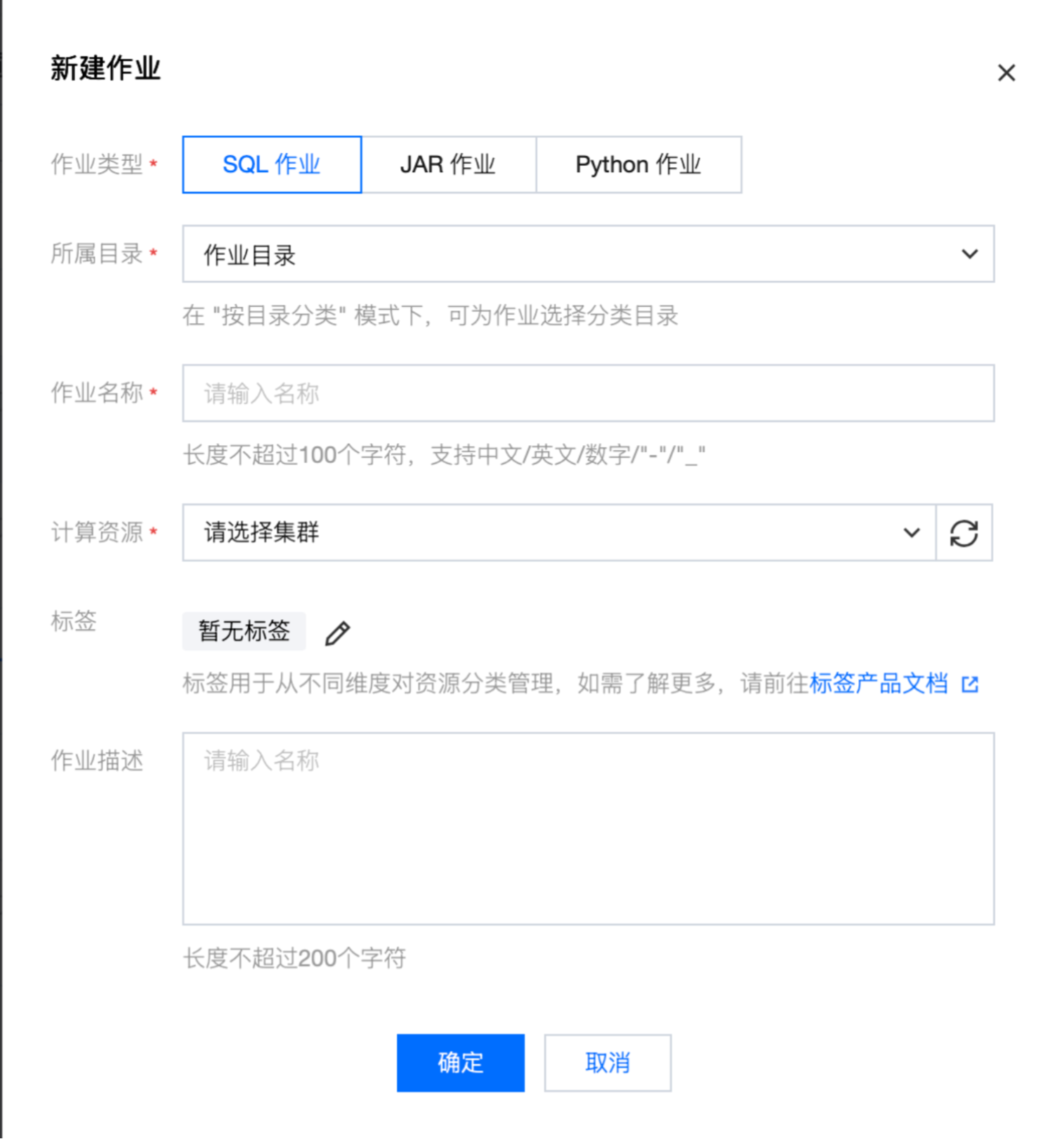
创建 SQL 作业后,在作业管理中单击要进行开发的作业名称,然后单击开发调试,即可在草稿状态下进行作业开发。版本管理(草稿)后的“(草稿)”,即表示当前正处于可编辑的草稿状态下。
编写和调试 SQL
开发 SQL 作业需在 SQL 编辑器中输入 SQL 分析语句。单击插入模板可以快速在编辑器中插入常用的 Ckafka 或 JDBC 等数据流的定义语句。单击库表引用可以便捷地引用表,以及查看、编辑 DDL 语句。SQL 语句编辑完成后,单击作业参数,在页面右侧弹出的参数界面中设置参数值,具体可参考 作业参数。然后单击保存,保存 SQL 语句和作业参数。
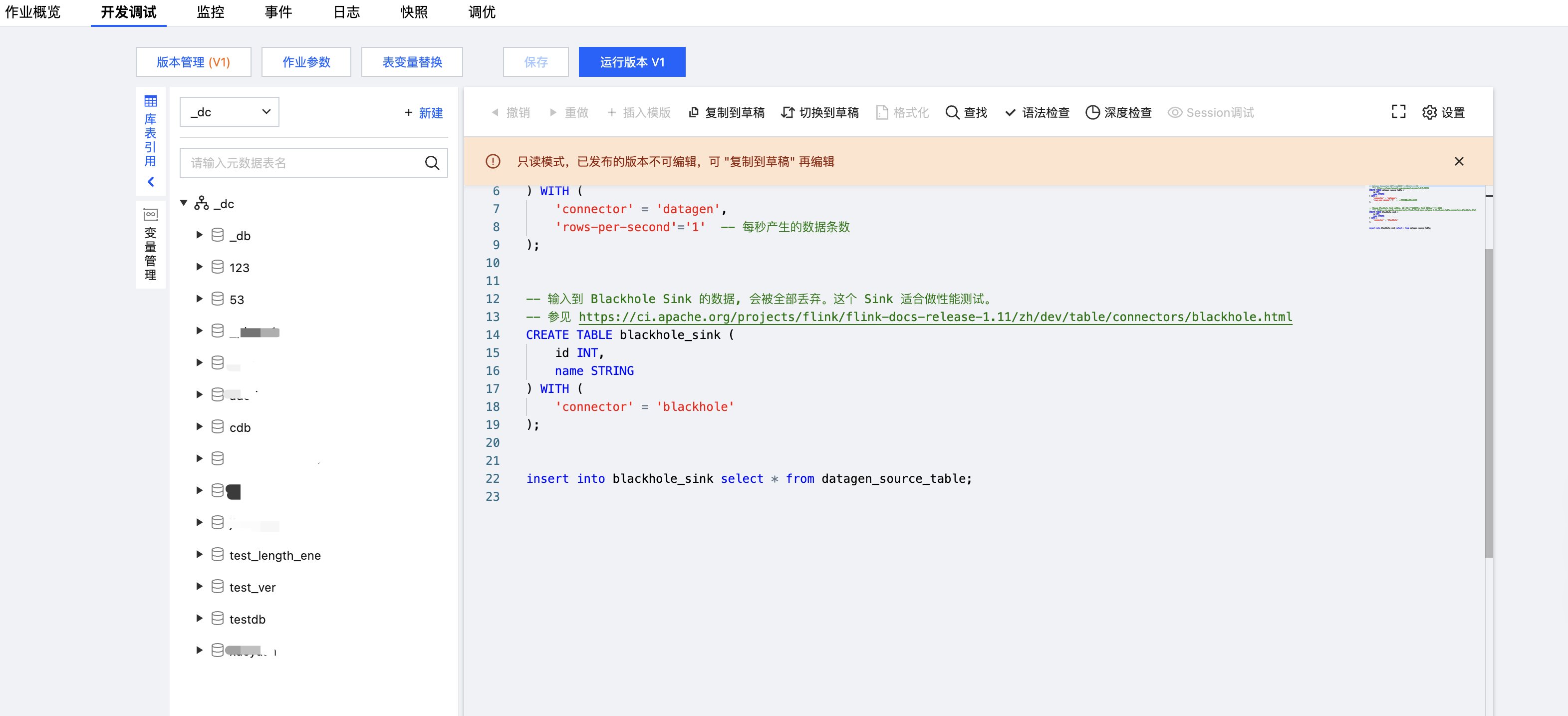
作业参数
作业参数可以在开发调试页面中单击作业参数并在侧边弹出的参数界面中设置参数值,然后单击确定保存作业参数信息。下文会有各参数的详细介绍说明,以帮助您更好地配置各作业参数。
引用程序包
若 SQL 开发指南 中提供的内置函数不满足需求,用户可以自行开发自定义函数,并以 JAR 包的形式在依赖管理中上传后,方可在此添加引用程序包,并选择版本。
程序包的上传和版本管理方式可参考 依赖管理。
Checkpoint
Checkpoint 即作业快照,开启 checkpoint 之后作业会按照设置的时间间隔自动保存作业快照,用于遇到故障时作业的恢复。可设置 checkpoint 的时间间隔,设置范围在30秒 - 3600秒。
运行日志采集
显示当前作业的运行日志采集配置,默认为采集到集群绑定的默认日志服务。作业的运行日志将自动采集到作业所在的集群绑定的日志集和日志主题,可在日志页面中查看。
高级参数
规格配置
算子默认并行度
当没有在 JAR 包中通过代码显式定义算子并行度时,作业将采用用户指定的算子默认并行度。并行度与 TaskManager 规格大小决定作业所占用的计算资源。1个并行度将占用1个 TaskManager 规格大小的 CU 计算资源(当 TaskManager 规格大小为1时,1个并行度将占用1 CU 计算资源。当 TaskManager 规格大小为0.5时,1个并行度将占用0.5 CU 计算资源)。
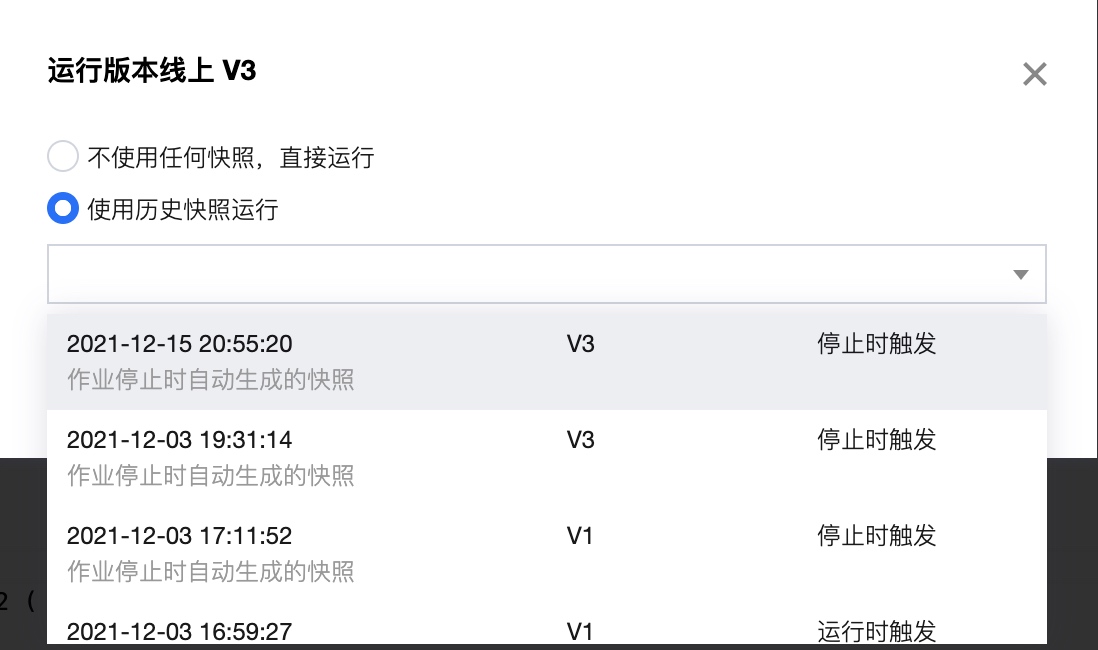
从快照恢复作业
作业运行时,支持从历史快照恢复。运行作业时,提示如下:
对于没有历史快照的作业,无法使用历史快照运行。
语法检查
编写并保存 SQL 语句后,可进行语法检查,以避免因语法错误而导致运行失败。单击 SQL 编辑器上方的语法检查,可对已保存 SQL 语句进行语法检查。若语法无误,将会在页面右上方提示“语法检查成功”;若有语法错误,将提示相应语法错误,请按照提示进行修改,直至语法检查通过。
深度检查
编写并保存 SQL 语句后,可进行深度检查,以避免因语法错误而导致运行失败。单击 SQL 编辑器上方的深度检查,可对已保存 SQL 语句进行深度语法检查。深度检查会检查语法以及检查依赖 connector 包。
Session 调试
目前这种模式的调试仅支持 Flink-1.13,Flink-1.16 版本且只有作业草稿版本可以调试。
单击 SQL 编辑器右上方的 Session 调试即可打开调试预览界面:

如果集群没有开启 Session 集群无法进行 Session 调试,需要去独享集群详情页开启 Session 集群:
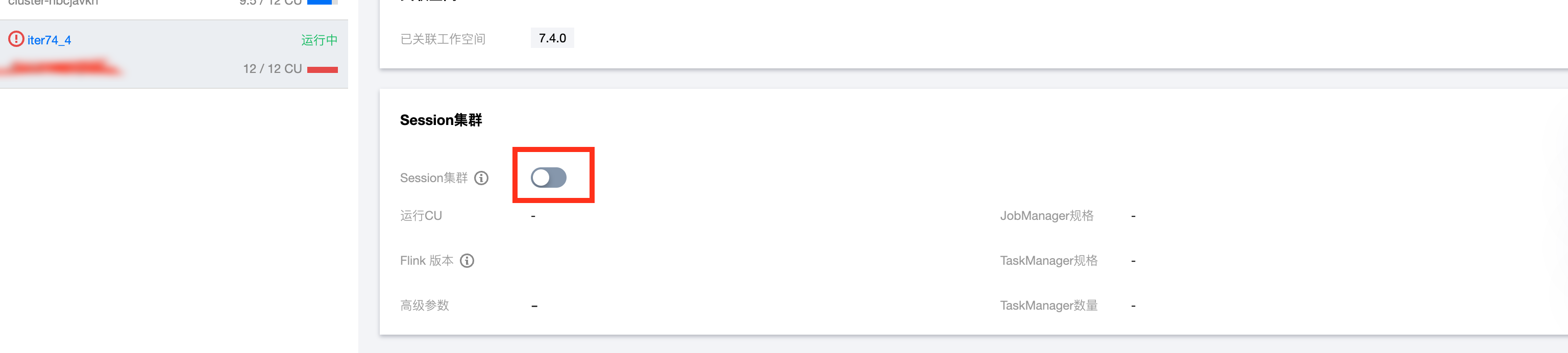
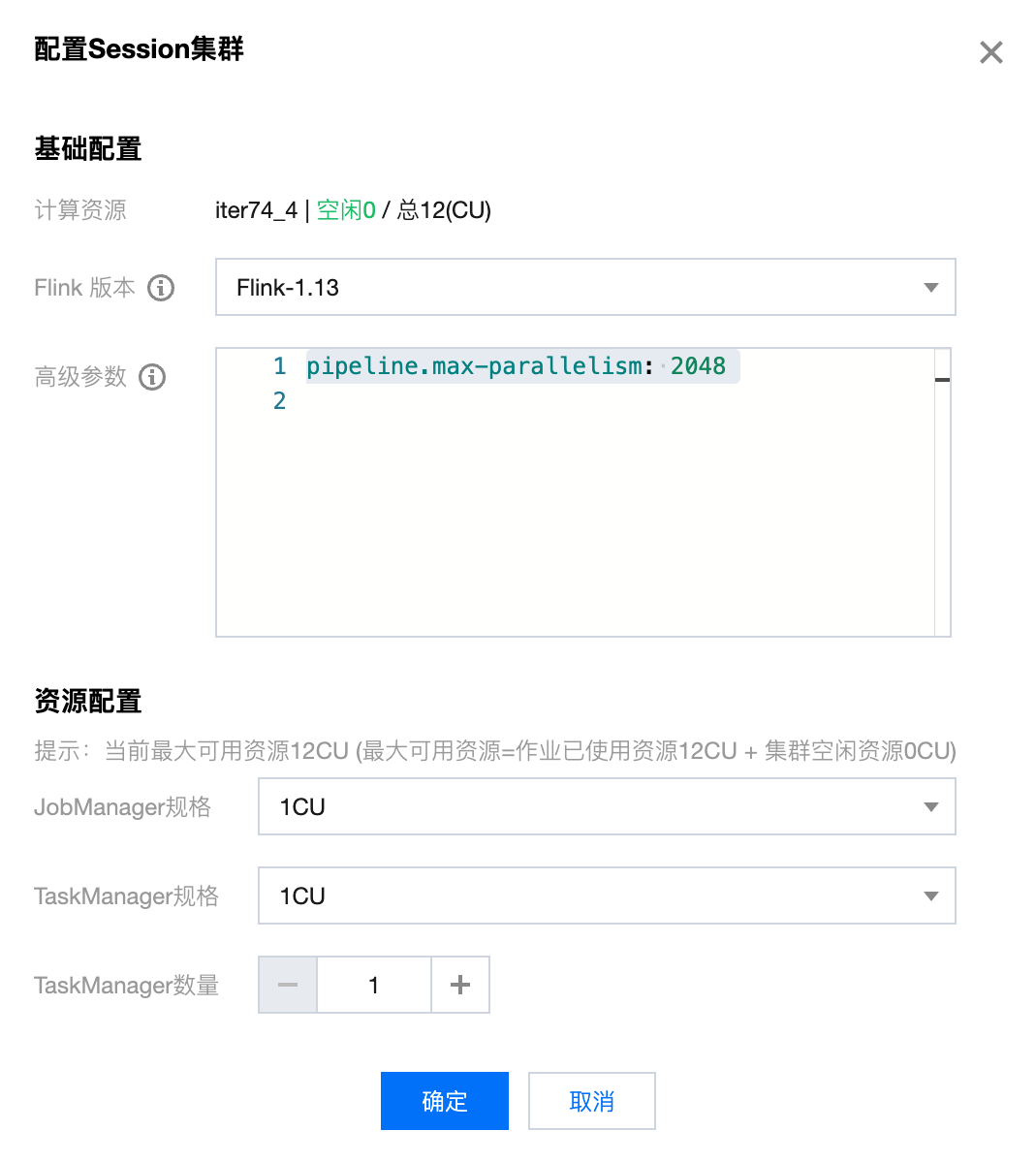
单击开启 Session 集群的按钮时可以设置 Session 集群启动时的高级参数、JobManager 的规格、TaskManager 的规格以及 TaskManager 启动的数量:
Session 集群启动相关信息也显示在集群详情页,可以单击 Flink UI 进入 Session 集群的 Flink UI 界面,Flink UI 密码与用户的独享集群相同:
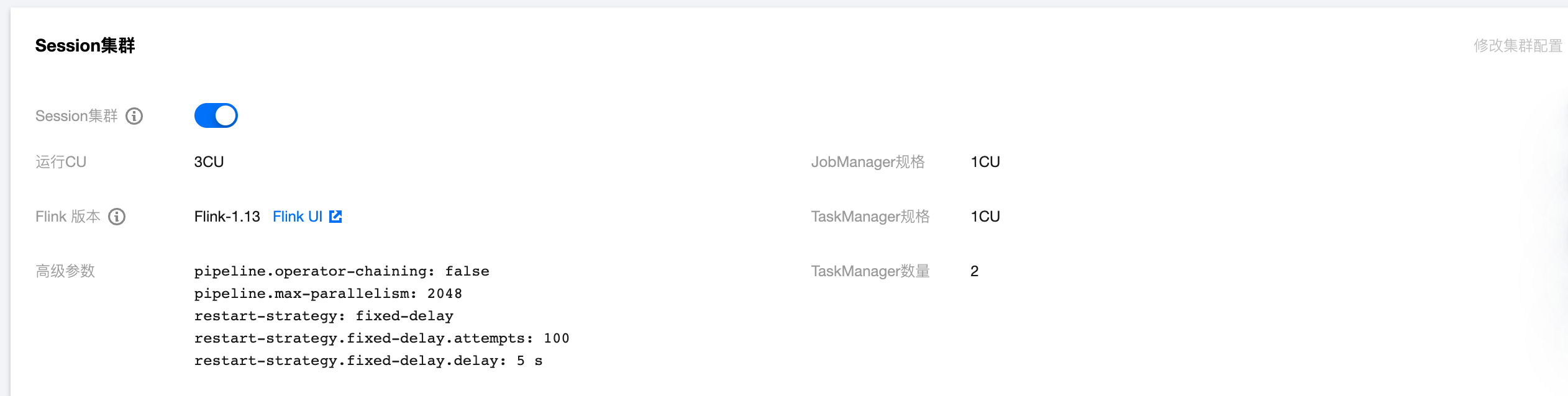
若需要修改 Session 集群参数则需要点击开关按钮停止 Session 集群后方可以单击右上角的修改集群配置按钮来修改参数,修改完成单击确定之后 Session 集群自动启动生效。
默认情况下直接单击 Session 调试功能则为调试整个 SQL 作业,生成的调试预览窗内容即为整个 SQL 作业:
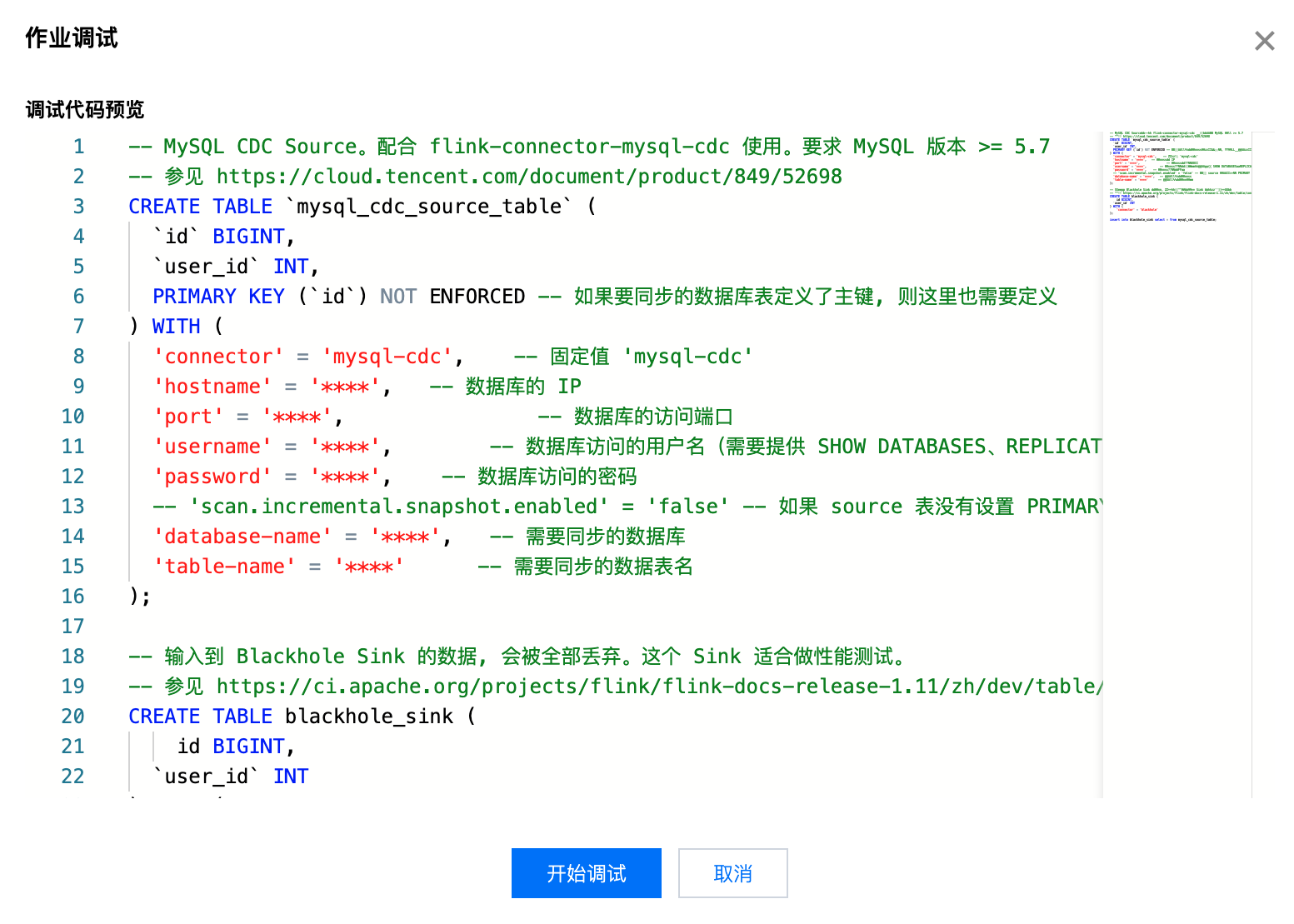
Session 调试功能也支持调试部分代码,您可以在点击 Session 调试之前先选中部分 SQL 代码之后再点 Session 调试,则预览窗口如下:
确认预览代码没有问题则单击开始调试即会出现调试界面,调试中的任务可以单击左边的红色停止按钮来停止调试任务,也可以单击波浪形按钮进入 Flink UI 界面,可以点击右上角的最小化最大化按钮来调整窗口:
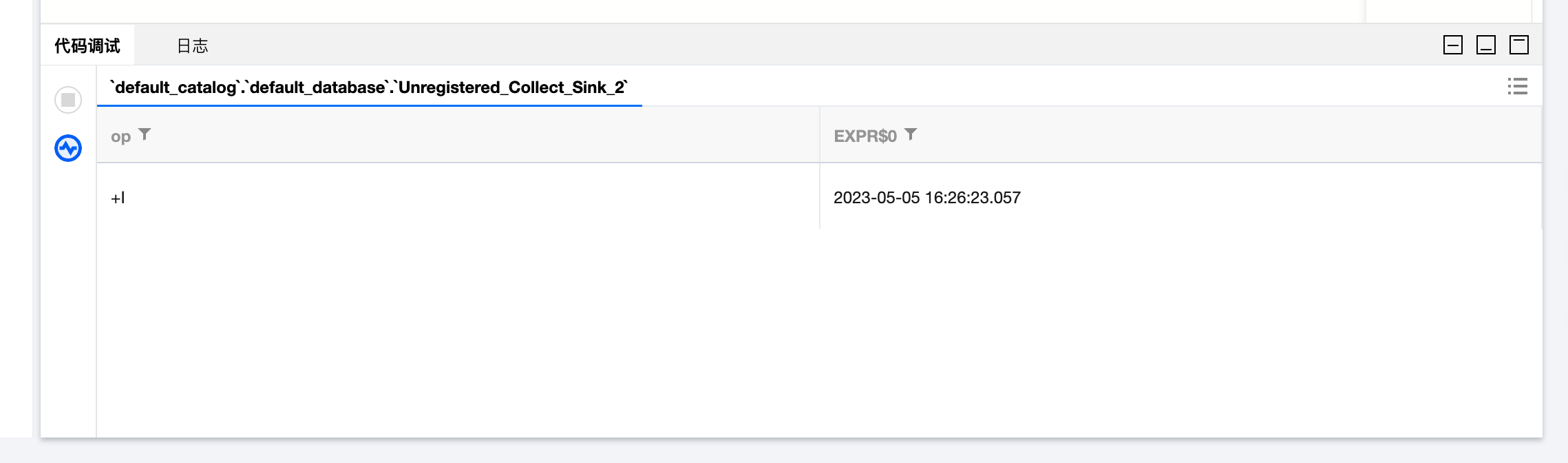
如果 SQL 没有语法上的问题则会获取到最终的结果:
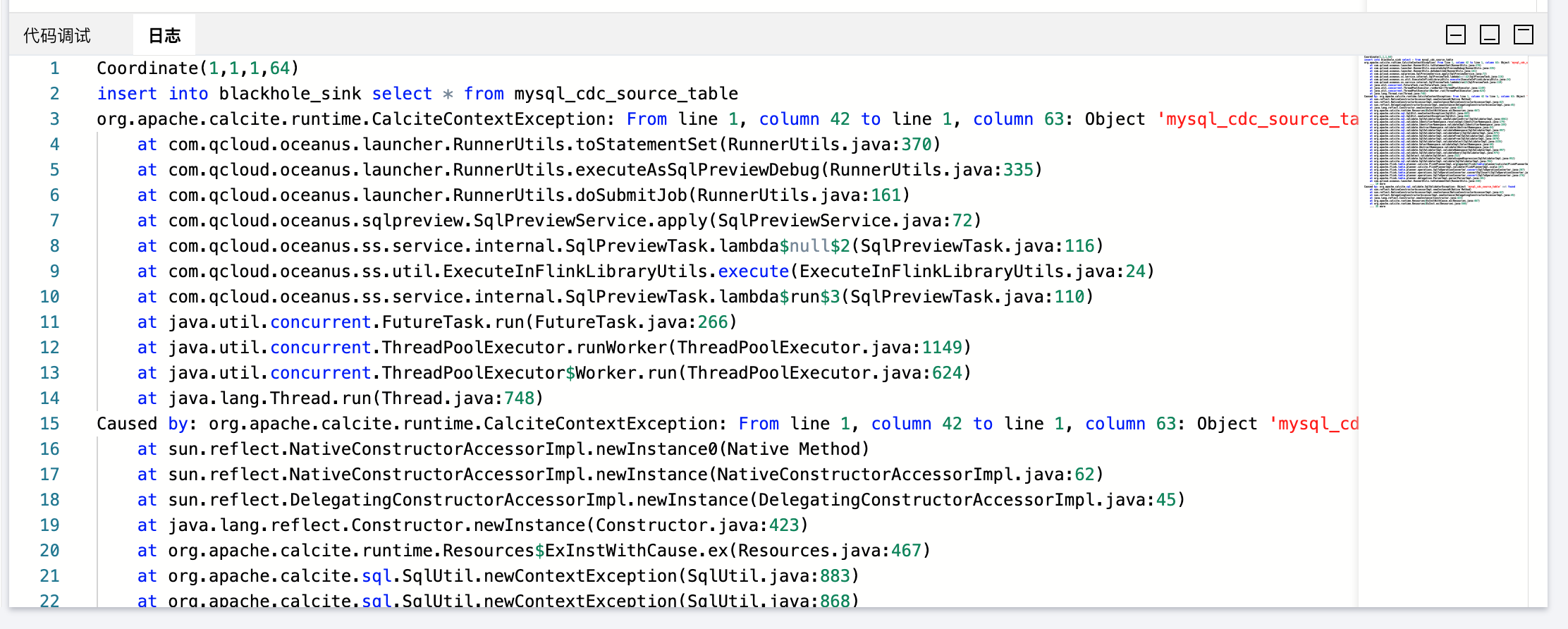
如果提交调试 SQL 代码或者调试 SQL 代码在执行过程中报错,则错误信息会显示到调试窗口中的日志 Tab 页面:
注意:
1. 只有超级管理员可以开启和停止 Session 集群。
2. 启动 Session 集群所需要的资源将从独享集群的可用 CU 数中扣除。
3. 调试结果最多展示100条,若调试任务有多个完整的 Pipeline (多 sink ),则任意一个 Sink 数据输出到100条会自动停止调试任务。若对其他 Sink 也有输出更多调试结果的需求可单独选中含有该 sink 的完整 Pipeline 的 SQL 代码进行调试。
4. 在调试任务运行期间切换到其他任意页面视为放弃本次调试。
5. 独享集群被隔离之后会停止 Session 集群,若用户续费独立集群后有 Session 调试的需求需要重新开启 Session 集群。
启动 Session 集群,禁止设置如下参数:
"jobmanager.rpc.address","blob.server.port","jobmanager.rpc.port","taskmanager.rpc.port","taskmanager.numberOfTaskSlots","parallelism.default","rest.bind-port","web.submit.enable","kubernetes.jobmanager.cpu","jobmanager.memory.process.size","kubernetes.jobmanager.labels","kubernetes.taskmanager.cpu","taskmanager.memory.process.size","kubernetes.taskmanager.labels","kubernetes.container.image","kubernetes.rest-service.annotations","kubernetes.container.image.pull-policy","kubernetes.jobmanager.service-account","state.checkpoints.dir","state.savepoints.dir","env.java.opts","kubernetes.namespace","kubernetes.rest-service.exposed.type","taskmanager.cpu.cores","jobmanager.heap.size","jobmanager.heap.mb","taskmanager.heap.size","taskmanager.heap.mb","classloader.resolve-order"
SQL 作业资源配置高级模式
SQL 作业资源配置高级模式支持对 SQL 生成的运行图做细粒度的配置,包括:算子并行度,设置算子细粒度资源(Fine-Grained Resource Management | Apache Flink)状态 ttl。
详细方式使用如下:
1. 单击 作业参数。

2. 资源配置模式选择高级模式(如果没有该选项,那可能是您作业所在集群的版本较低,请 联系我们 升级)然后单击立即配置。
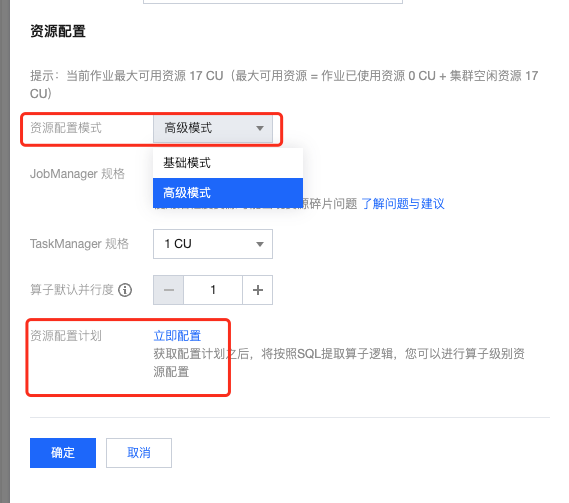
3. 选中对应的算子,设置 并行度 state ttl 等。
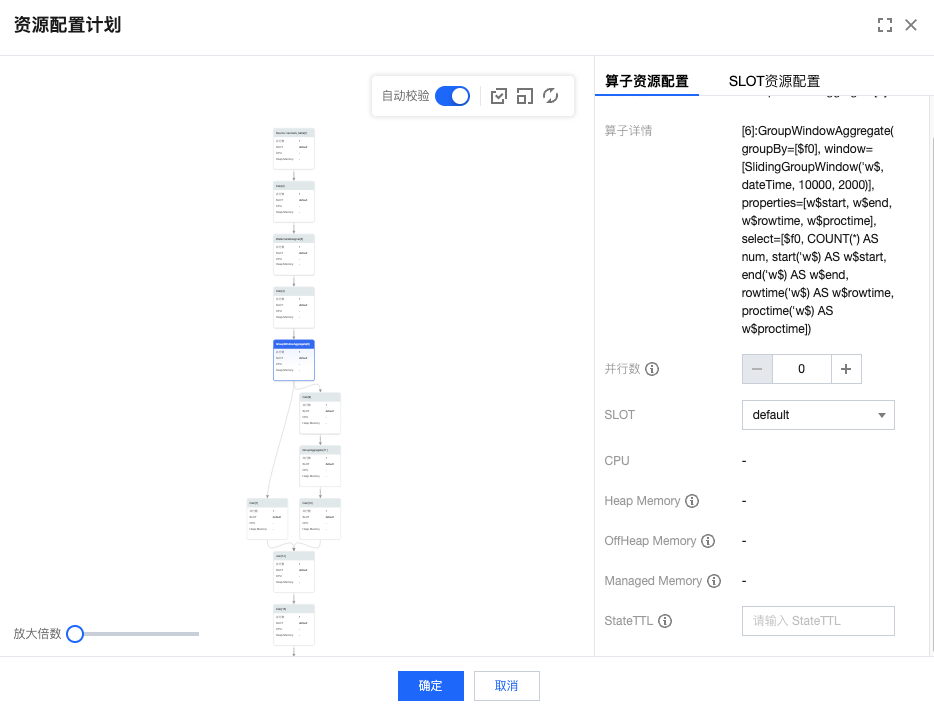
4. 如果需要配置 算子细粒度资源配置,单击 SLOT 资源配置,新增 SLOT。
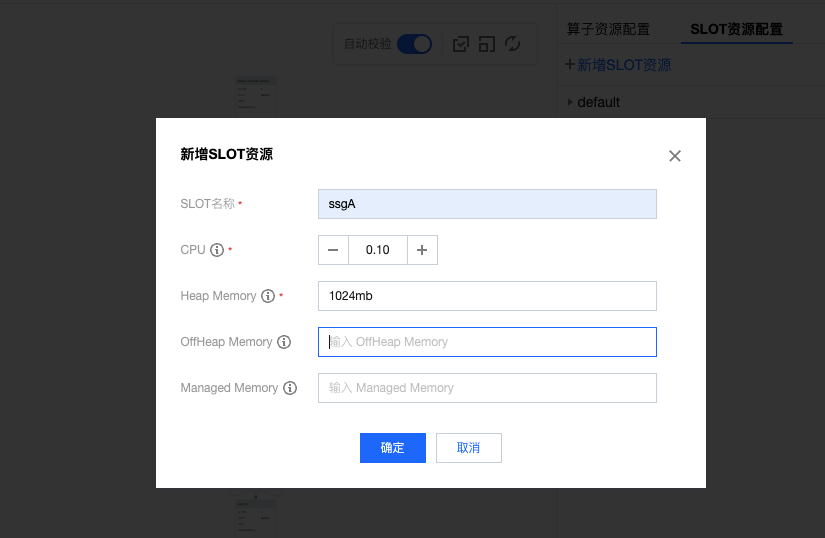
5. 配置算子到对应的 SLOT 。



