简介
腾讯 Kubernetes 引擎(TKE)是腾讯云提供的高性能、可扩展的容器管理服务,帮助用户轻松部署和管理容器化应用。在使用 TKE 的过程中,集群内的状况层出不穷,变化莫测,如节点状态异常、Pod 重启等。如果无法第一时间感知状况,可能会错过最佳的问题处理时间,待问题扩大,影响到业务时才发现往往已经为时已晚。为解决这一问题,CLS日志服务与 TKE 紧密集成,支持将集群事件日志实时采集至 CLS。同时借助 CLS 强大的日志分析和查询能力,用户可以实现对集群运行状况的全面监控,快速定位问题根源,提升故障排查的效率。例如:
当某个 Pod 频繁重启时,用户可以通过事件日志追踪其状态变化,快速识别问题原因。
如果节点出现异常,事件日志将提供详细的上下文信息,帮助用户判断是否需要进行节点的重启或替换。
用户可以设置告警规则,及时获取异常事件的通知,确保集群的稳定性和业务的连续性。
通过本篇实践,您将详细了解如下内容:
实践场景案例
您也可通过以下 Demo, 快速体验 CLS 与 TKE 的强大结合:
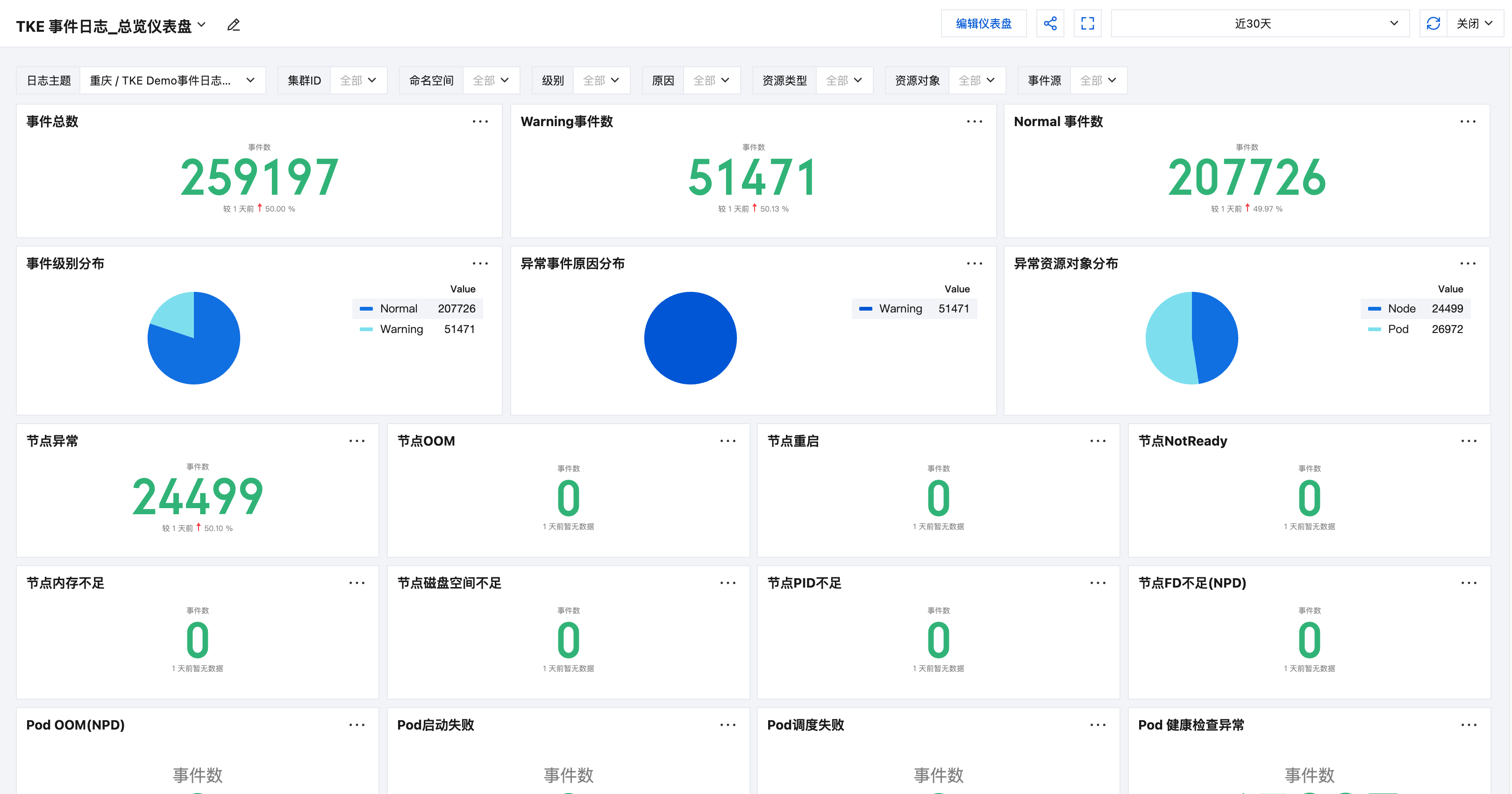
事件总览:可根据时间、命名空间、级别、原因、资源类型、资源对象等维度过滤事件,查看核心事件的汇总统计信息。
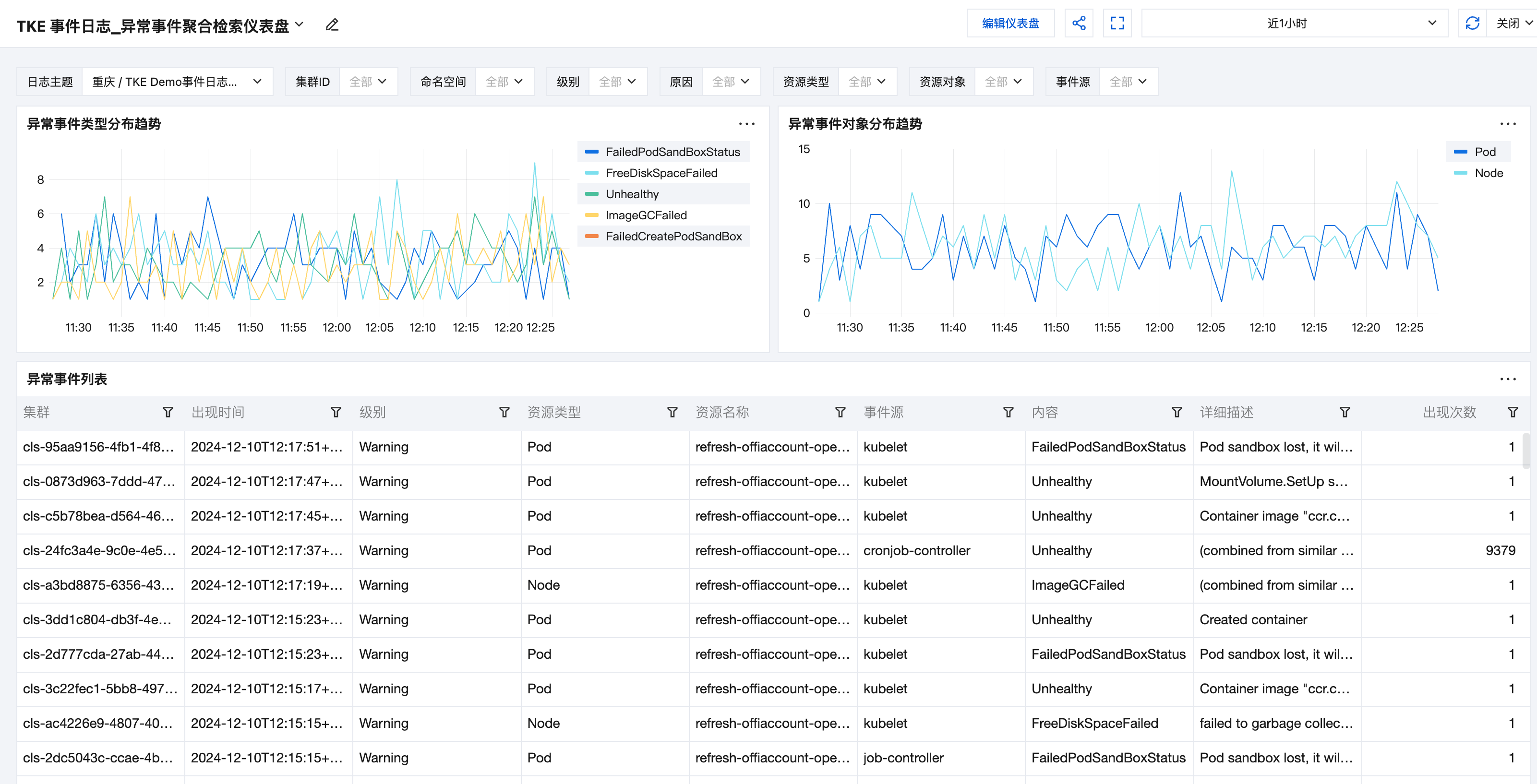
异常事件聚合检索:查看某个时间段内各类异常事件的 reason 和 object 分布趋势。
功能优势
CLS 为 TKE 事件日志分析场景提供了开箱即用的事件分析仪表盘,仪表中包含异常事件级别分布、异常事件原因分布、异常资源对象分布等分析看板。
采集 TKE 事件日志
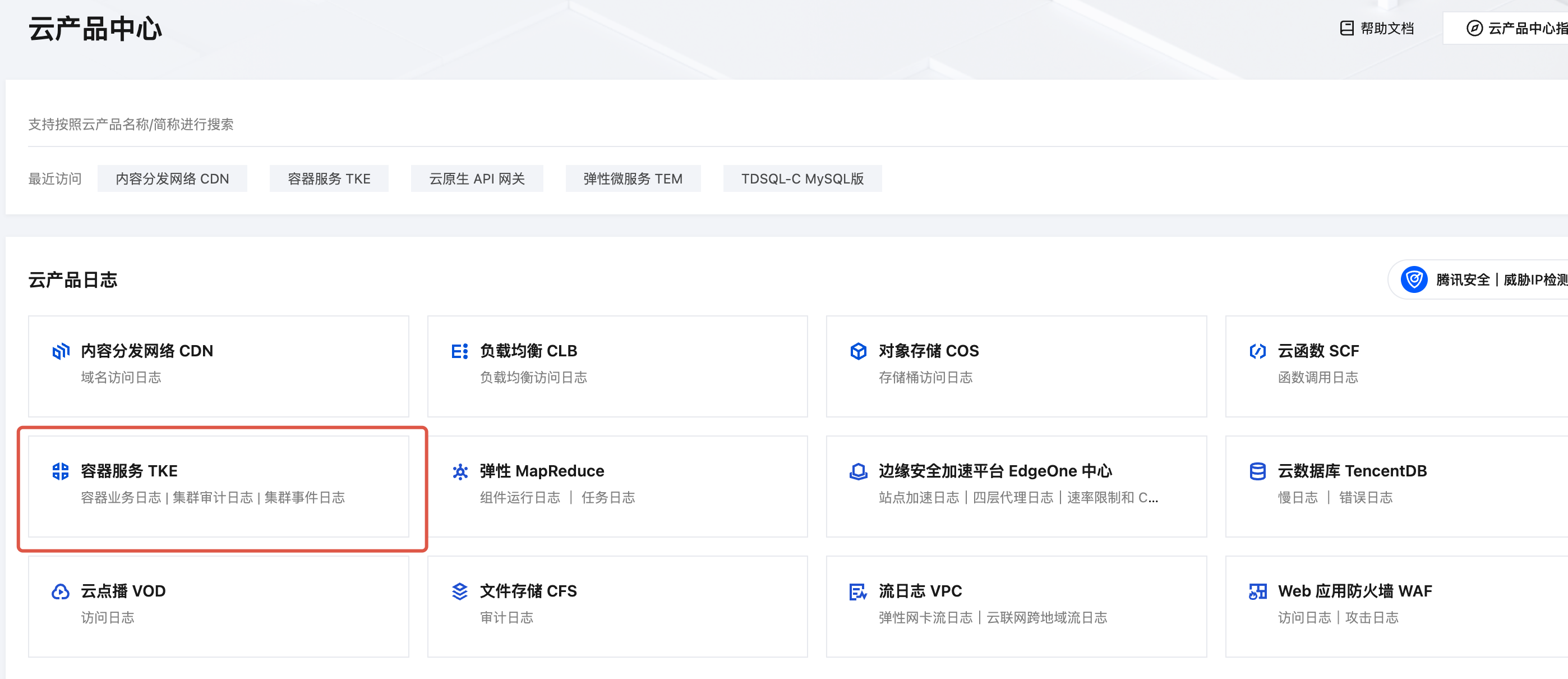
步骤1:进入 TKE 云产品中心
1. 登录 日志服务控制台,在左侧导航栏中,选择云产品中心,进入云产品中心页面。
2. 在云产品日志中,找到容器服务 TKE,并单击进入容器服务 TKE 云产品中心。
步骤2:开启 TKE 集群事件日志采集
1. 选择接入管理 > 实例接入页面。
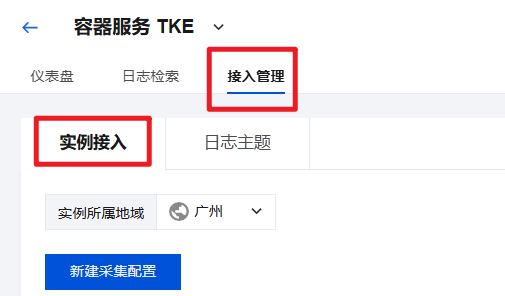
2. 在 TKE 云产品中心中,在集群列表中找到目标集群,若采集组件状态为未安装,单击安装,安装日志采集组件。

注意:
安装日志采集组件将在集群 kube-system 命名空间下,以 DaemonSet 的方式部署一个 tke-log-agent 的 pod 和一个 cls-provisioner 的 pod。 请为每个节点至少预留0.1核16Mib以上的可用资源。
3. 若采集组件状态为最新,单击集群名称,进入集群详情页,并在集群详情页的日志管理中找到集群事件日志。
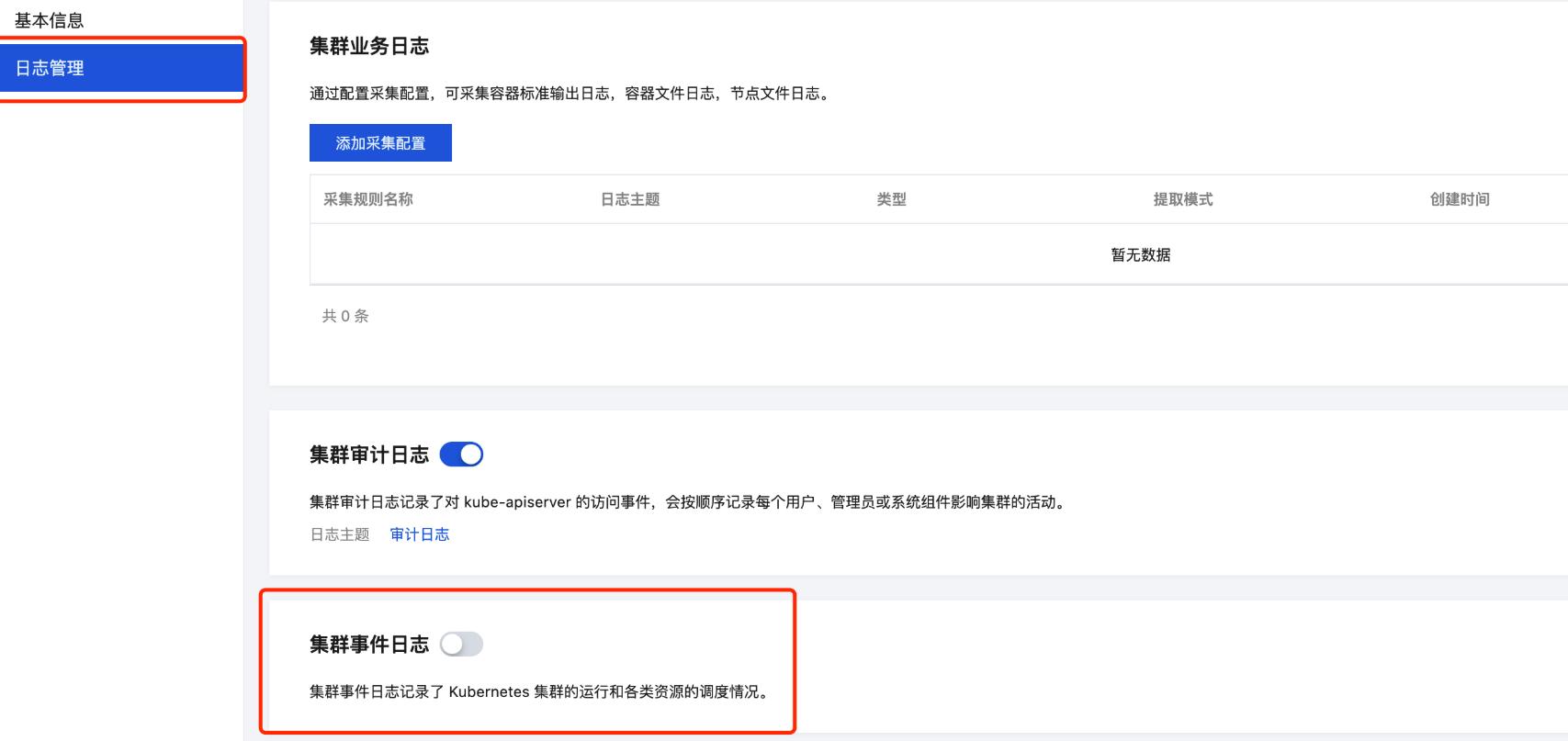
4. 单击开启集群事件日志,并进入集群事件日志配置流程。
5. 进入事件日志配置流程,在日志主题配置步骤中,您可选择已有或创建用于存储日志的日志主题。日志主题的相关信息请参见 日志主题。
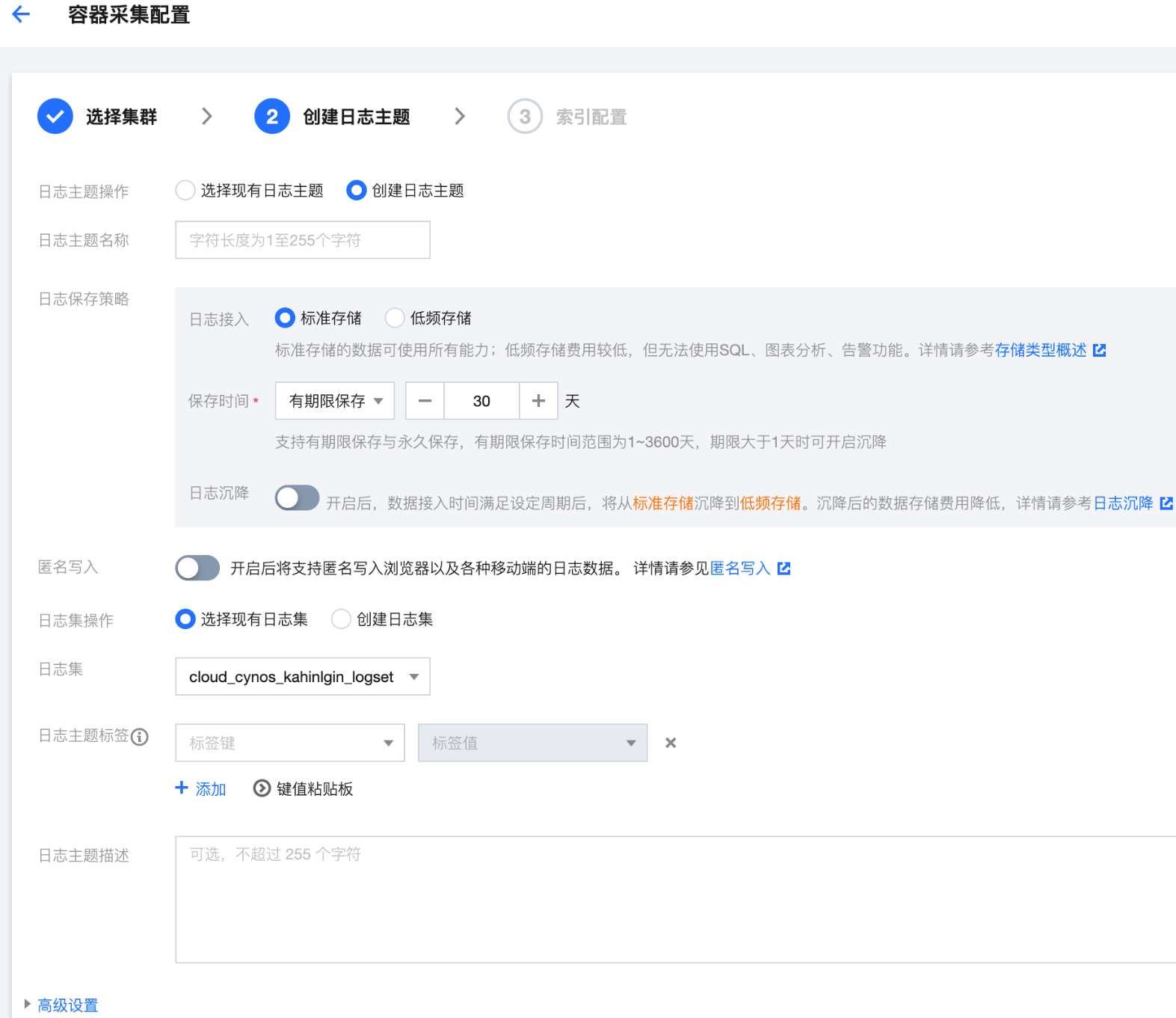
6. 完成日志主题配置后,单击下一步进入索引配置,索引的相关信息请参见 索引。
索引配置中的配置信息如下:
索引状态:确认是否开启索引, 以使用日志检索等分析功能。
全文索引:确认是否需要设置大小写敏感。全文分词符:默认为"@&()='",;:<>[]{}/ \\n\\t\\r",确认是否需要修改。
是否包含中文:确认是否开启。
键值索引:您可根据 key 名按需进行字段类型、分词符以及是否开启统计分析的配置。若您需要开启键值索引,可打开开关。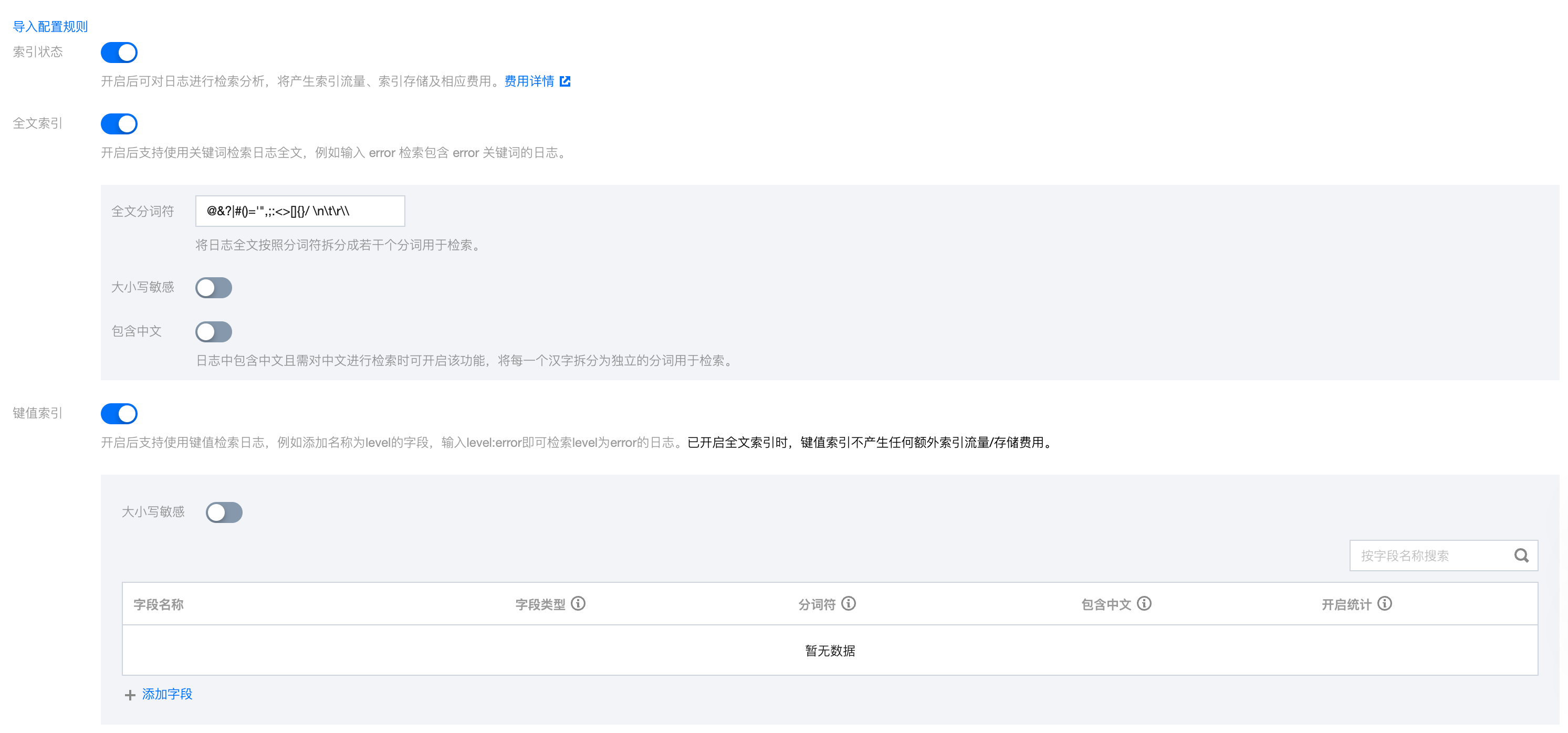
注意
检索必须开启索引配置,否则无法检索。
若需要基于日志字段检索日志,需配置键值索引。
若需要基于日志字段进行统计分析,需配置键值索引,并开启统计。
索引规则编辑后仅对新写入的日志生效,已有数据不会更新。
查看 TKE 事件分析仪表盘
事件总览:可根据时间、命名空间、级别、原因、资源类型、资源对象等维度过滤事件,查看核心事件的汇总统计信息。
异常事件聚合检索:查看某个时间段内各类异常事件的 reason 和 object 分布趋势。
您可通过以下操作查看以上 TKE 事件预置仪表盘:
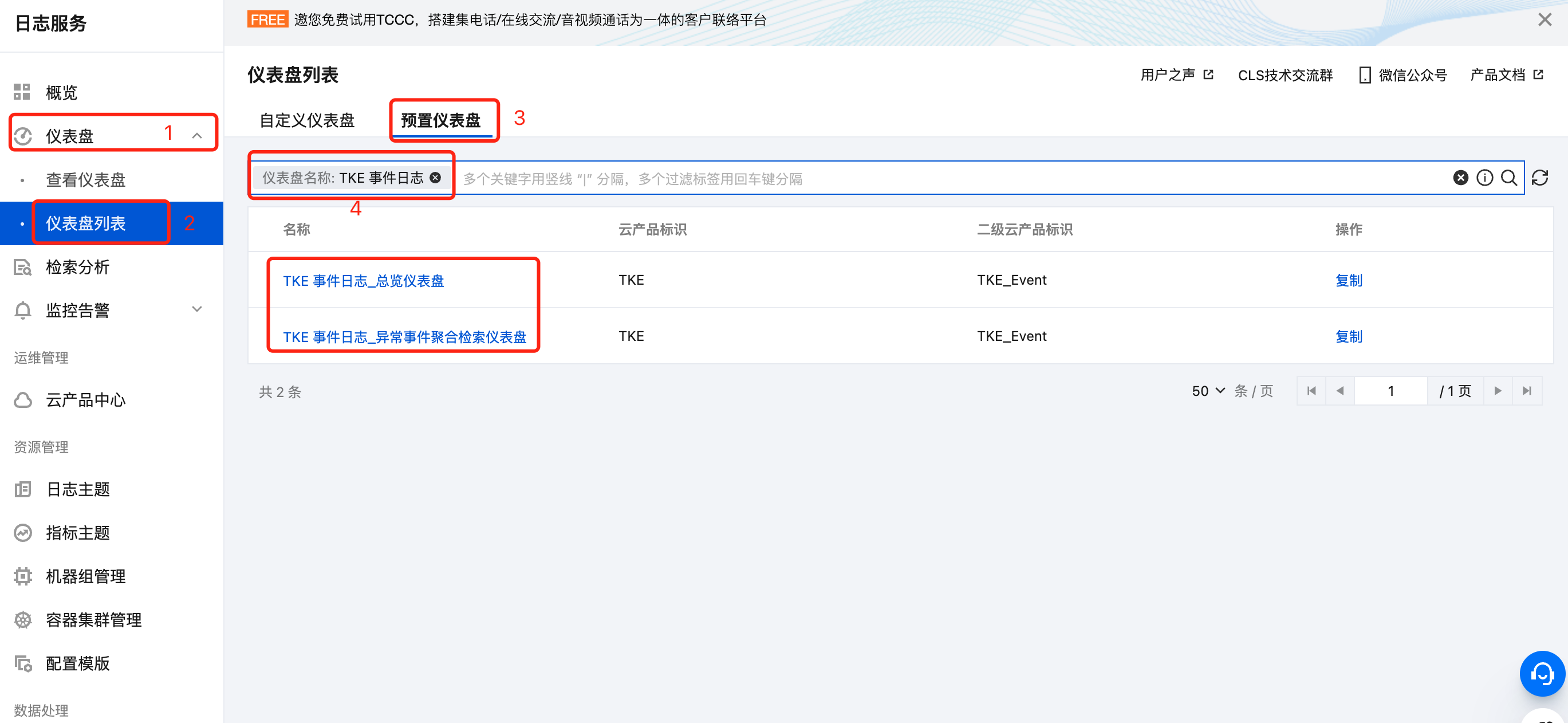
1. 登录 日志服务控制台。
2. 在左侧导航栏中,选择仪表盘 > 仪表盘列表 > 预置仪表盘,并搜索 “TKE 事件日志”
检索分析集群事件日志
1. 完成 开启 TKE 事件日志采集 后,在集群列表中,找到已开启集群事件日志的集群,单击集群名称进入集群详情页。
2. 在集群详情页中,选择日志管理,并找到集群事件日志模块。
3. 单击事件日志,跳转日志检索页,即可检索分析目标集群事件日志。日志字段说明请参见 日志字段说明。
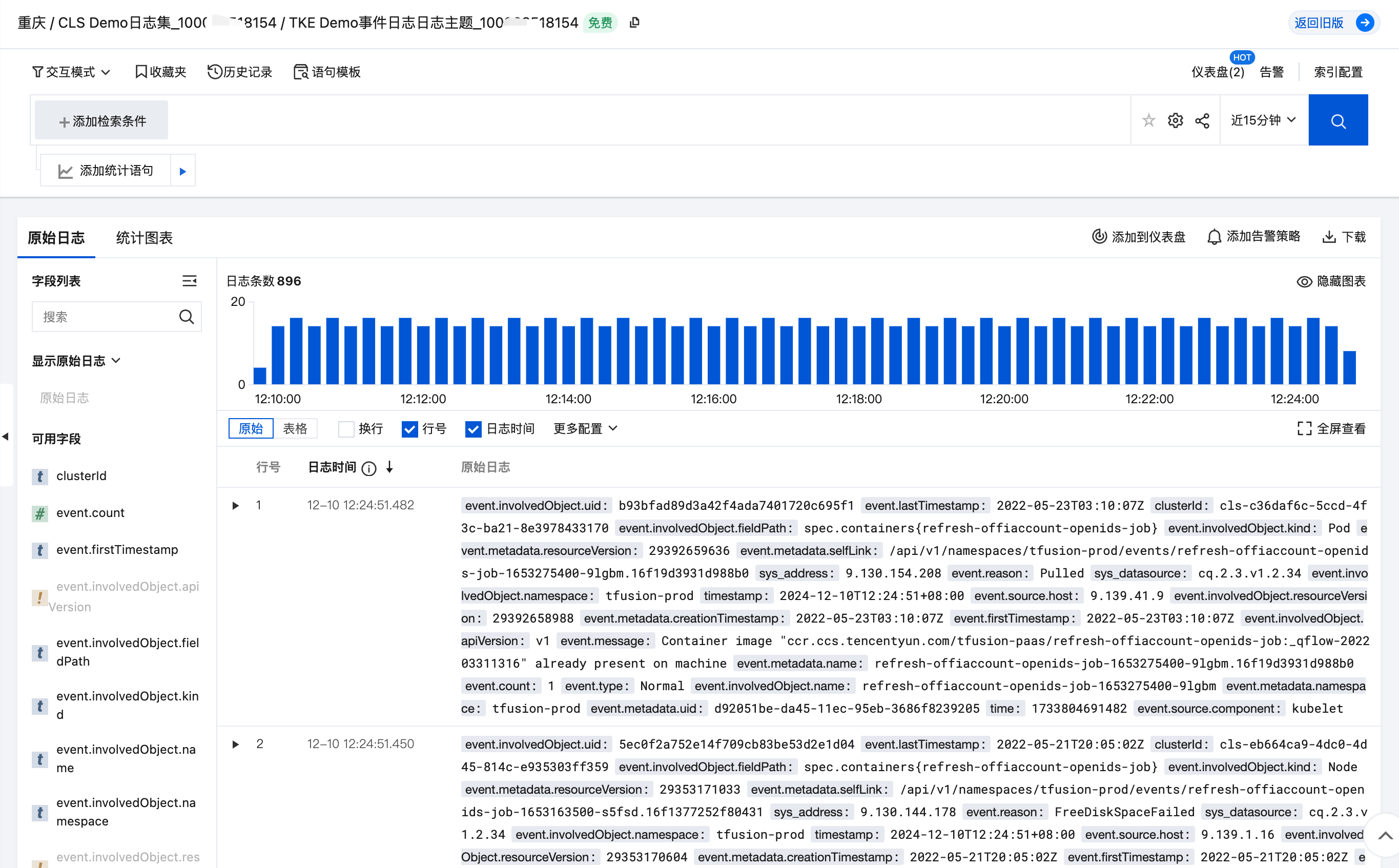
日志字段说明

级别(Type): 目前仅有 “Normal” 和 “Warning”,但是如果需要,可以使用自定义类型。
资源类型/对象(Involved Object):事件所涉及的对象,例如 Pod、Deployment、Node 等。
事件源(Source):报告此事件的组件;例如 Scheduler、Kubelet 等。
内容(Reason):当前发生事件的简短描述,一般为枚举值,主要在程序内部使用。
详细描述(Message):当前发生事件的详细描述信息。
出现次数(Count):事件发生的次数。
实践场景案例
场景1:一台 Node 节点出现异常,定位原因
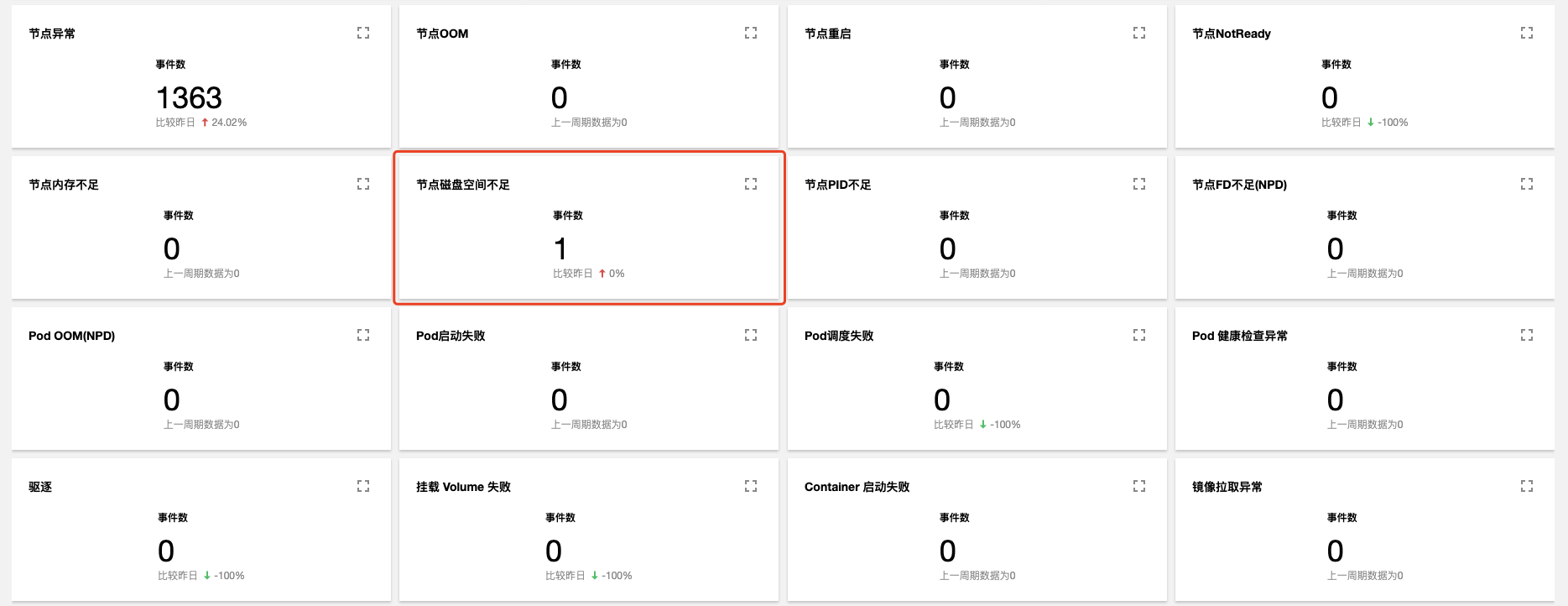
1. 参见 查看 TKE 事件分析仪表盘,打开事件总览仪表盘,在资源对象中输入异常节点名称。

2. 查询结果显示,有一条节点磁盘空间不足:
场景2:节点触发扩容了,用户需要对扩容过程进行回溯,以确定具体原因
开启 节点池「弹性伸缩」的集群,CA(cluster-autoscaler)组件会根据负载状况自动对集群中节点数量进行增减。如果集群中的节点发生了自动扩(缩)容,用户可通过事件检索对整个扩(缩)容过程进行回溯。
1. 参见 检索分析 TKE 事件日志,进入 TKE 事件日志检索页面。
2. 在事件检索页面,输入以下检索命令:
event.source.component : "cluster-autoscaler"
3. 结果如下图所示:
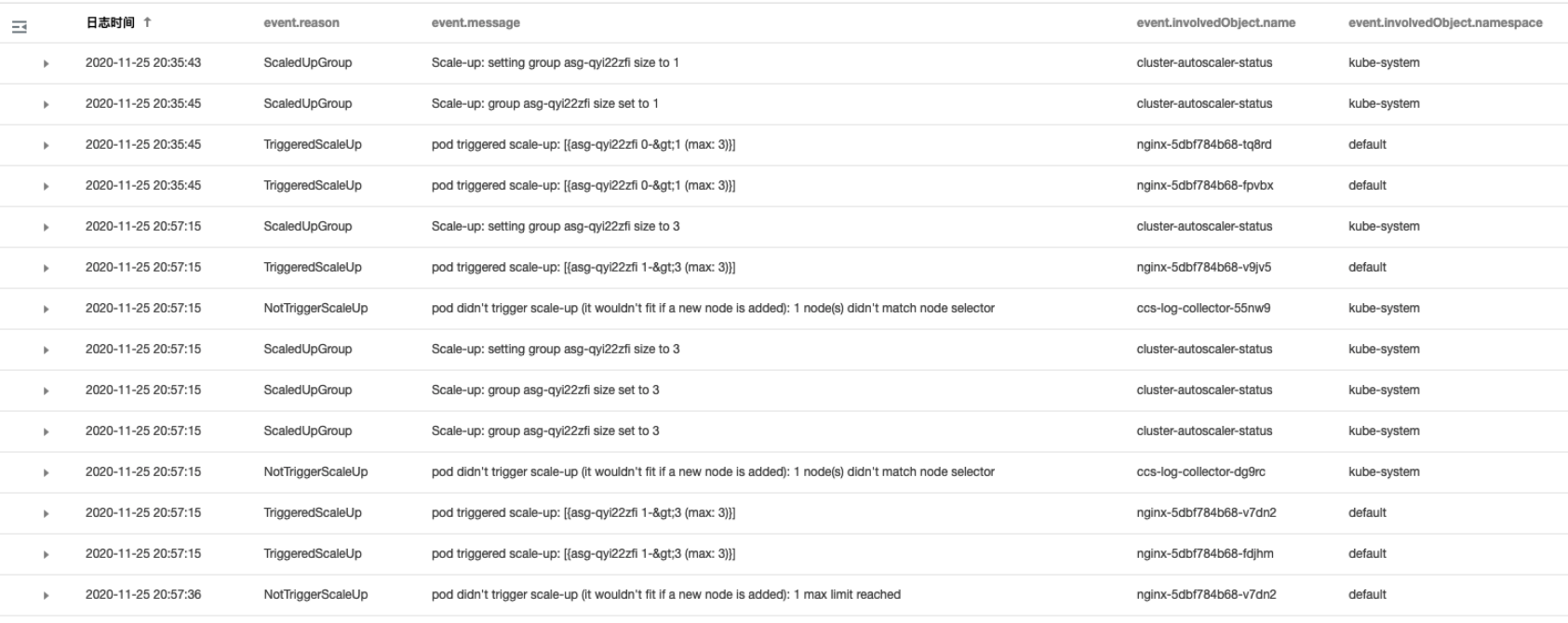
通过上图的事件流水,可以看到节点扩容操作在
2020-11-25 20:35:45左右,分别由三个 nginx Pod(nginx-5dbf784b68-tq8rd、nginx-5dbf784b68-fpvbx、nginx-5dbf784b68-v9jv5) 触发,最终扩增了3个节点,后续的扩容由于达到节点池的最大节点数没有再次触发。


