步骤1:导入 Python SDK 依赖库
import requestsimport jsonimport tcvectordbimport osfrom tcvectordb.model.enum import ReadConsistencyfrom tcvectordb.model.collection_view import Embedding
步骤2:创建客户端对象,连接数据库实例
vdbclient = tcvectordb.VectorDBClient(url='{your vdb url}', username='root', key='{your vdb key}')
步骤3:知识库初始化
声明 knowledgeInit() 函数,初始化知识库。
1. 为腾讯云向量数据库专有知识库创建一个 AI 类数据库 testdb。
2. 在已创建的 AI 类数据库中,创建集合视图 knowledge。
3. 上传 腾讯云向量数据库的产品文档 所有 md 文件于数据库集合视图中。
def knowledgeInit():#创建DBdb = vdbclient.create_ai_database(database_name='testdb')#创建CollectionViewcollView = db.create_collection_view(name='knowledge',embedding=Embedding(enable_words_embedding=True))#上传文件file_path = "{/yourLocalPath/files/}"for file_name in os.listdir(file_path):if file_name.endswith(".md"):print("\\n上传:"+file_name)collView.load_and_split_text(local_file_path=file_path+file_name)print('upload all file sucess')
步骤4:传入问题进行知识内容相似性检索
声明 searchKnowlege() 函数,传入用户 question,返回知识库中与用户 question 最相似的内容。
def searchKnowlege(question):db = vdbclient.database('testdb')collView = db.collection_view('knowledge')doc_list = collView.search(content=question,limit=3)knowledge = ''print("查询向量数据库:")for count,doc in enumerate(doc_list):print("知识条目:", count, "----------------")print(doc.data.text)knowledge += doc.data.textreturn knowledge
步骤5:将用户问题与知识库检索的相似性语料,送入百川大模型,生成问题答案
说明:
def generate_answer(msg):url = "https://api.baichuan-ai.com/v1/chat/completions"api_key = "baichuan_api_key"data = {"model": "Baichuan2-Turbo","messages": [{"role": "user","content": msg}]}json_data = json.dumps(data)headers = {"Content-Type": "application/json","Authorization": "Bearer " + api_key}response = requests.post(url, data=json_data, headers=headers,timeout=60)if response.status_code == 200:print("============================================")print("知识条目+大模型推理回答:\\n", json.loads(response.text)["choices"][0]["message"]["content"])else:print(response.text)print("请求失败,状态码:", response.status_code)
步骤6:构建 main() 函数
1. 调用 knowledgeInit() 初始化知识库。
2. 输入问题,调用 searchKnowledge() ,传入请求问题,在知识库检索与问题相似的知识。
3. 将检索结果的 Topk 条 knowledges 与输入的问题 question 进行内容组装。
4. 调用 generate_answer() ,传入组装后的内容,送入大模型,生成问题答案。
if __name__ == "__main__":knowledgeInit()question = input("请输入你的问题:\\n")print("问题:", question)print("============================================")knowledges = searchKnowlege(question)content = json.dumps({"请回答问题": question,"背景知识如下": knowledges},ensure_ascii=False)generate_answer(content)
问答效果体验
腾讯云向量数据库产品文档中的一些内容,通用的大语言模型(LLM)在预训练时若没有相关的数据,出现了幻觉问题,导致在回答时的效果较差。在使用腾讯云向量数据库 AI 套件搭建知识库对大语言模型(LLM)进行知识补充后,如下三个问题都能准确地回答,对比只使用大语言模型(LLM)的效果显著提升。
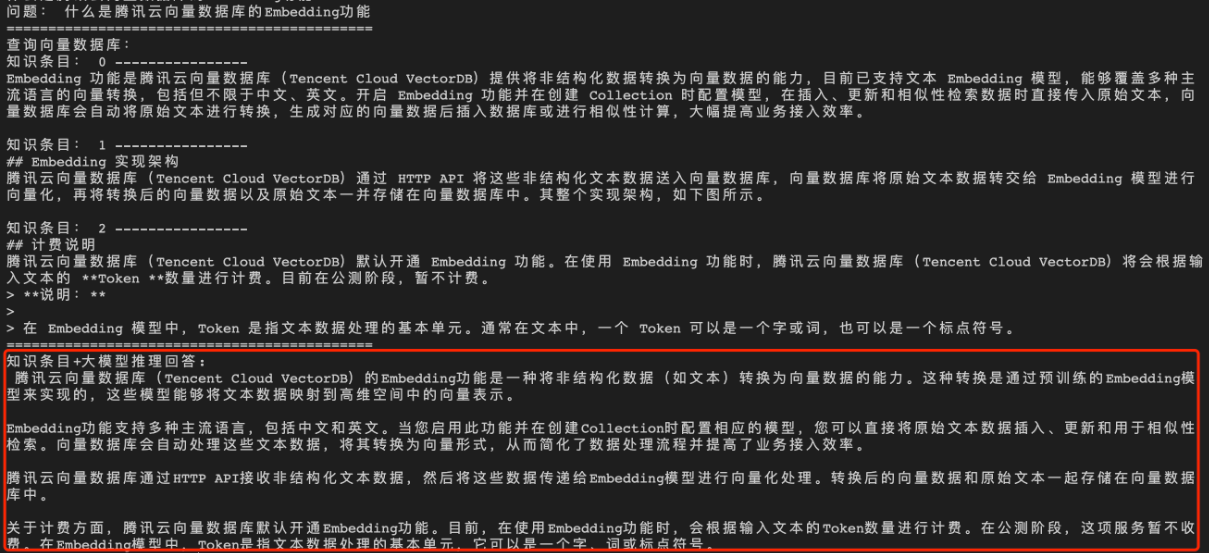
问题1:什么是腾讯云向量数据库的 Embedding 功能?
直接给大语言模型(LLM)输入问题,生成答案如下所示。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。
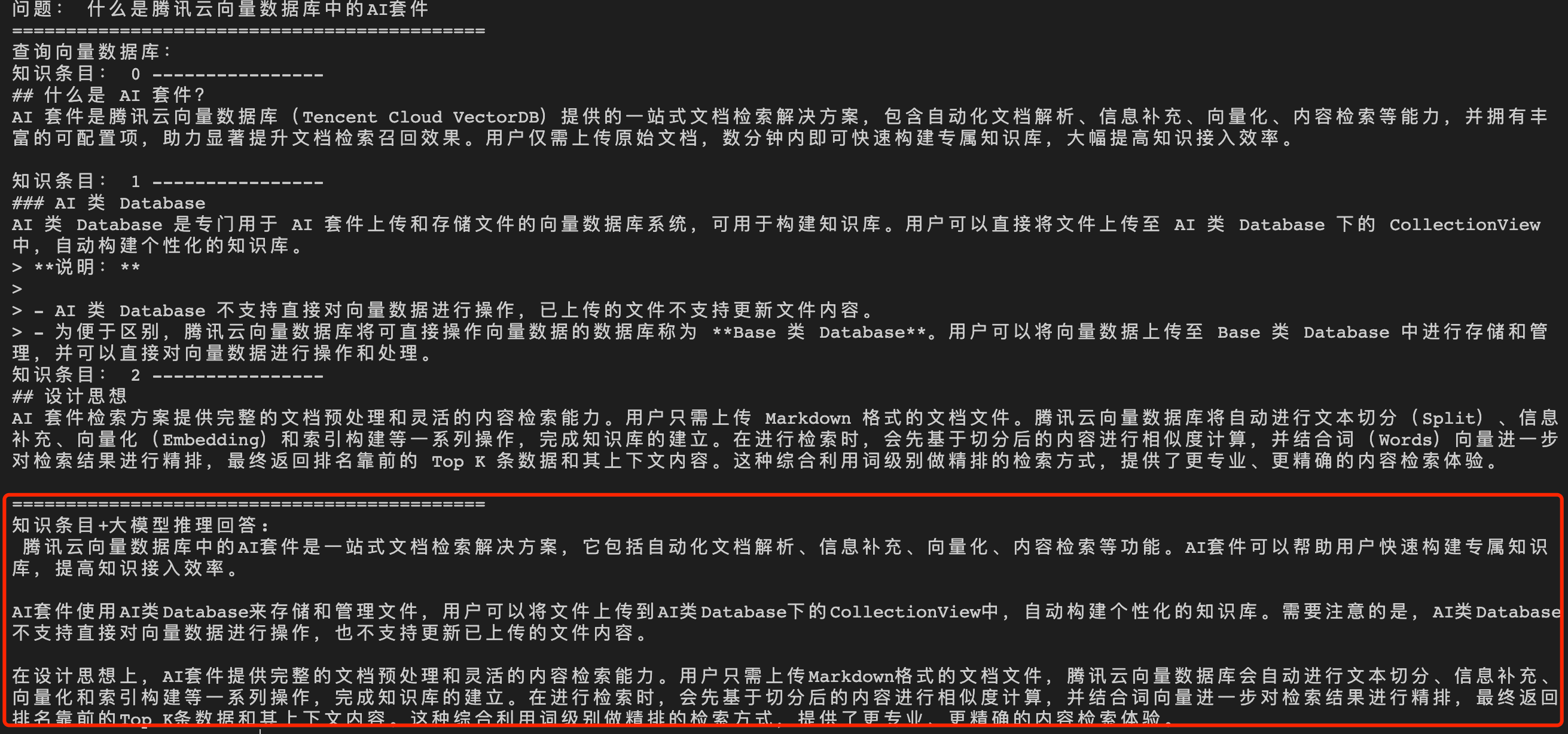
问题2:什么是腾讯云向量数据库中的 AI 套件?
直接给大语言模型(LLM)输入问题,生成答案如下所示。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。
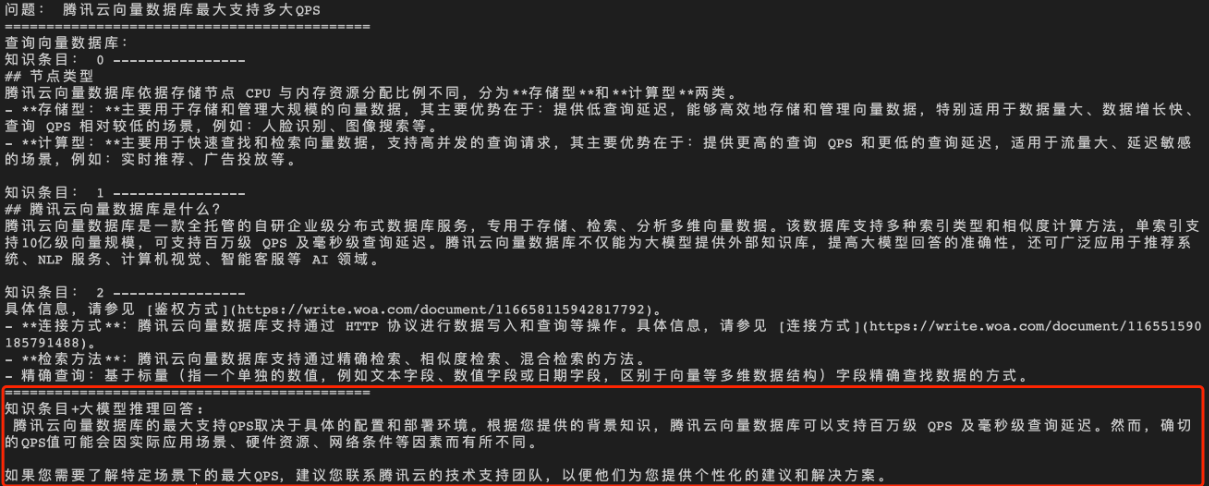
问题3:腾讯云向量数据库支持的最大 QPS
直接给大语言模型(LLM)输入问题,生成答案如下所示。

经过向量数据库的 AI 套件从知识库中检索出相似的 TopK 条语料,再送入大模型,生成答案如下所示。