前言
为了提升任务执行效率,您可以首先对现有任务或引擎进行洞察分析(仅 Spark)查看是否有可调优空间,其次 DLC 在计算过程中有许多优化措施,例如数据治理、Iceberg 索引、缓存等,您可以结合这些优化措施对任务做更全面的优化。正确使用不仅可以减少不必要的扫描费用,甚至可以提升几倍甚至几十倍的效率。
下面提供一些不同层面的优化思路。
Spark
任务洞察
可以解决常见的 SQL 问题,包括:
资源抢占
数据倾斜
磁盘不足或内存 OOM
慢 Task
小文件过多
Shuffle 不合理
执行计划分析
当任务洞察仍然无法满足性能调优时,根据Spark UI提供的当前任务详细的执行计划,可以进一步分析 SQL 的瓶颈。
Spark UI 可以从 SQL DataFrame 页面查看执行计划。
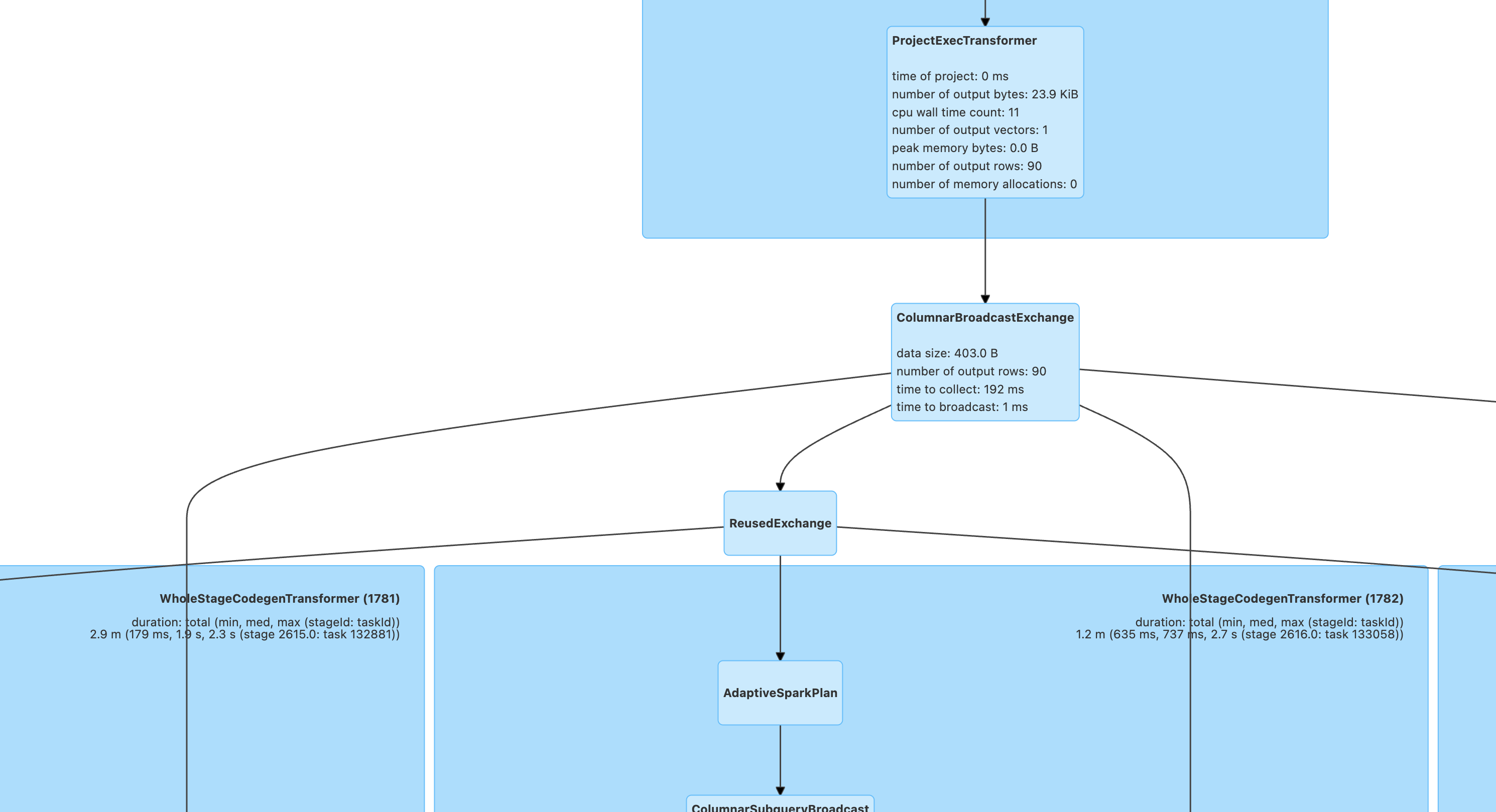
执行计划的查看和分析可以结合 Stages 页面的 Stage 耗时,按照以下步骤及优化思路。优化前,建议提前对输入、Join、输出的数据量级有初步的判断。
第一步:分析 Scan 算子
Scan 算子是负责读取所有库表的操作,Stages 页面包含有 Input 数据的 Stage 一般对应 Scan 算子,当这种 Stage 耗时长时需要重点查看 Scan 算子的指标。
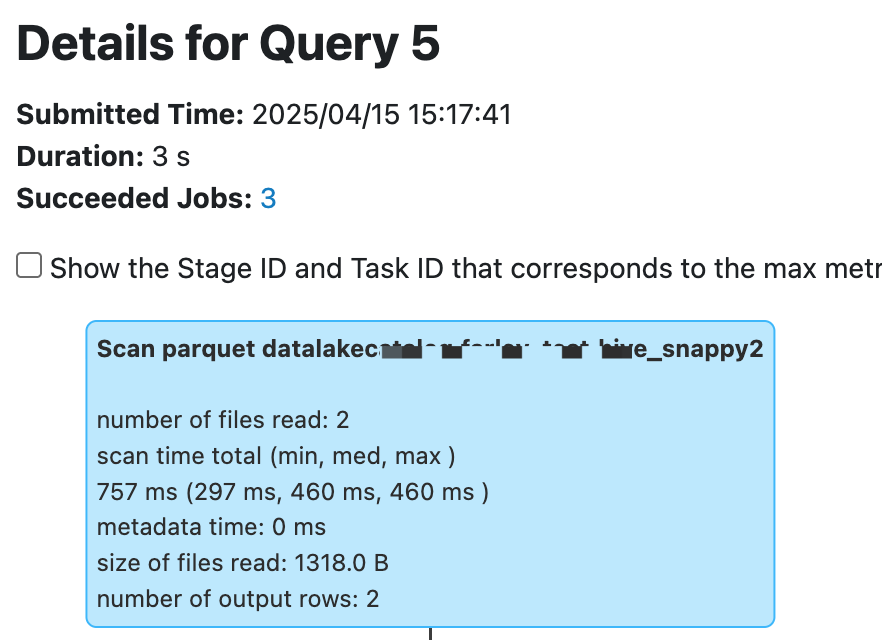
以下 Metrics 信息在 Hive/Iceberg 表上名称有所不同,但是指标内容及含义基本相同。
number of files read: 如果读取的文件数太多,而 size of files read/number of output rows 太小,可以认为小文件太多,需要合并小文件,或者使用 数据优化来配置自动合并。
scan time total (min, med, max ):分布式读取时的时间分布,如果存在部分任务读取太慢,可能是因为存储的 COS 桶限流或限频,建议查看 COS 桶监控,可以提工单给 COS 调整带宽。
size of files read: 辅助判断读取的数据量是否合理。如果发现读取的文件太大,需要判断是否存储的文件格式不对,或有脏数据存在。
number of output rows: 辅助判断读取的数据量是否合理。如果发现读取的数据量太大,需要结合 Scan 的 Filter 条件判断是否过滤条件有误导致扫描了全表。Spark引擎可以自动下推过滤条件到 Scan 算子,但如果某些特殊情况没有自动下推过滤条件,可以提前将 SQL 中的 where 下推。
第二步:寻找计算瓶颈
建议先从 Stages 页面查看耗时最长的 StageId,再根据 StageID 到执行计划(页面上需要勾选 Show the Stage ID and Task ID)页面分析。
在任务洞察中可以识别常见的性能瓶颈点,而在执行计划中分析,往往需要结合瓶颈算子的上下文来分析。
Project 算子
Project 算子往往需要关注是否有大量重复的 Expression 定义,这种建议 SQL 中改写来避免大量的重复计算。
Filter 算子
过滤算子的过滤条件一般重点检查是否正确过滤数据,重点关注 Filter 前后数据量是否有正常的减少。
Join 算子
Join 是较为常见出现性能瓶颈的算子。常见的优化思路如下。
SortMergeJoin 出现 skewJoin,尽管 Spark 会默认对倾斜的 Join 做优化,但是当数据膨胀系数不大(spark.sql.adaptive.skewJoin.skewedPartitionFactor=5.0,超过平均值5倍认为是倾斜),或者当倾斜并不是特别突出(spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes=256MB,大于256MB才会认为倾斜)时一旦导致 spill 性能会急剧下降,仍然有一定的调优空间。
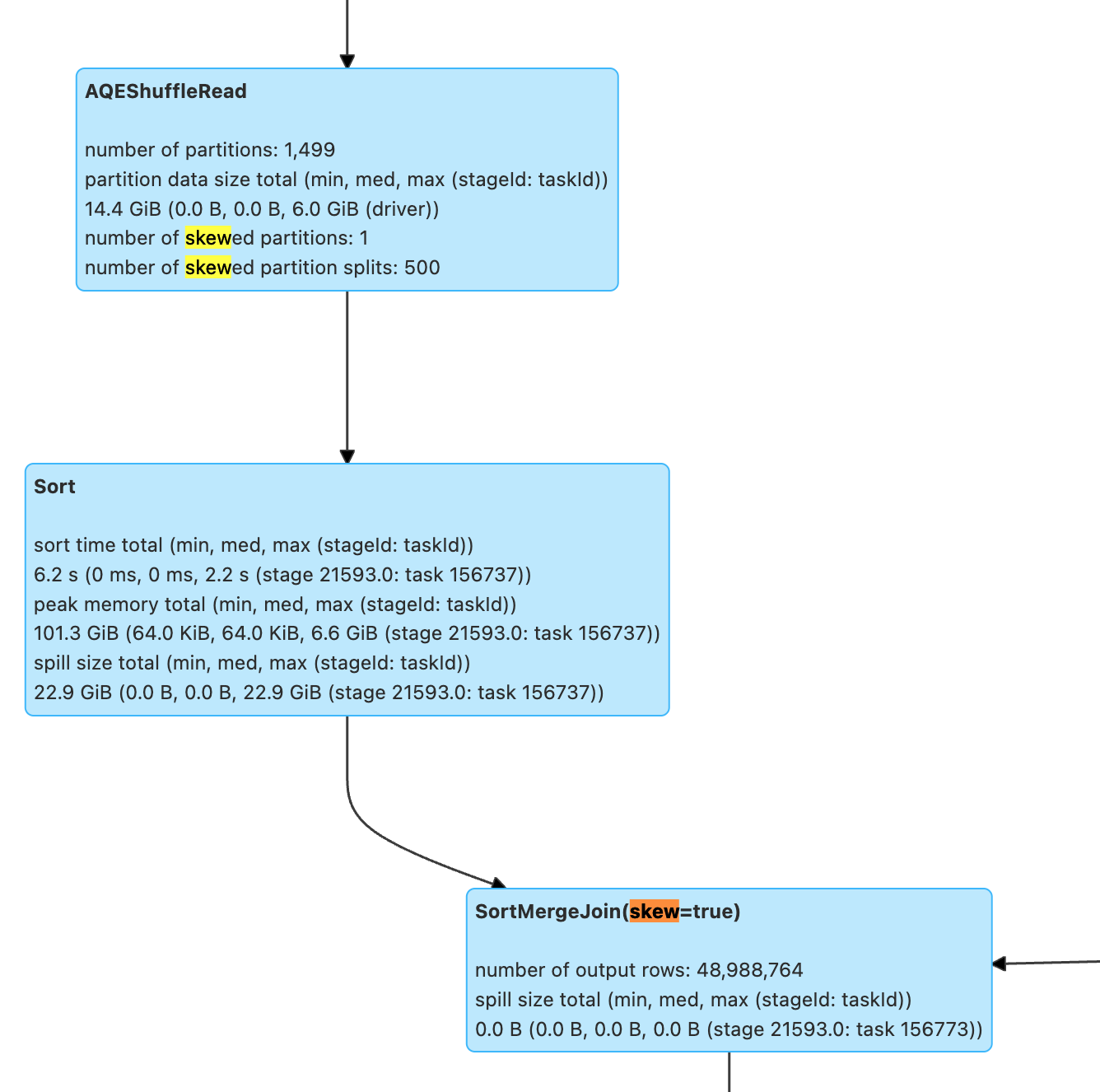
SortMergeJoin 数据量太大,可以结合 SQL 和执行计划分析:
1. 是否出现了笛卡尔积,join on 的条件字段存在重复,导致 left join 或 inner join 数据膨胀。
2. 是否有些过滤条件没有下推,例如 Aggregate 操作可能会隔绝过滤条件的下推,设置 spark.sql.optimizer.AggregatePushdownThroughJoins.enabled=true 可以查看是否可以下推 Aggregate 后的算子。
SortMergeJoin 出现大表 Join 小表,是否可以考虑替换为 BroadcastHashJoin。通过 Spark hints 或调大 spark.sql.autoBroadcastJoinThreshold=10MB 来让小的表可以广播。
Aggregate 算子
Aggregate 比较常见的是倾斜的问题,当 aggregate key 明显过多时,会导致慢 task 的产生。如果调整分区数无法解决倾斜,一般只能通过重新调整 key 来打散过多的 Key,来重新做业务 SQL 设计。此外,如果 Aggregate 的函数存在重复计算,也可以考虑从 SQL 层面做精简。
Exchange + AQEShuffleRead 算子
AQE 是 Spark 提供的在 shuffle 时自动合并过小的分区、打散过大的分区的特性。上面的 Join/Aggregate 往往也会需要查看 Exchange+AQEShuffleRead 的算子。AQE 是根据 spark.sql.adaptive.advisoryPartitionSizeInBytes=64MB 来判断 ShuffleRead 时的分区大小的。所以当业务的出现数据膨胀非常多,例如小数据量 Join 产生非常大的数据量,可以考虑调小 advisory的partition size;或者在 Shuffle 经过处理数据量缩小得非常多,可以考虑调大 advisory 的 partition size 来避免产生过多的小文件。
第三步:查看 Insert/Write 算子
Stages 页面包含 Output 的 Stage,一般可以对应到写入的算子。
一般任务结尾都为写入的算子,例如 Insertxxx/Overwritexxx/AppendData 等,常常需要关注是否有写入过多的小文件,以及 commit 的时间。

常见的指标含义:
number of output row:写入的数据量是否符合预期,尤其在性能变动大时需要关注。
task/job commit time:数据写入后,需要 commit 确认整张表的数据写入正确,如果 commit 时间过长,一般是普通桶 rename 的时间过长,可以考虑换元数据加速桶,可以工单咨询 COS 桶。
number of dynamic part:默认动态分区写入,如果只写入了一个分区,需要查看写入算子前是否有 Exchange 算子只对某个只有一个值的字段做了分区,这会导致分布式写变成单线程写。如果是 Hive 表写入可以通过 Spark hints 调整写入时的分区策略;如果是 Iceberg 表则需要调整 `spark.sql.iceberg.distribution-mode`=none。
Presto
优化 SQL 语句
场景:SQL 语句本身不合理,导致执行效率不高。
优化 JOIN 语句
当查询涉及 JOIN 多个表时, Presto 引擎会优先完成查询右侧的表的 JOIN 操作,通常来说,先完成小表的 JOIN,再用结果集和大表进行 JOIN,执行效率会更高,因此 JOIN 的顺序会直接影响查询的性能,DLC presto 会自动收集内表的统计数据, 利用 CBO 对查询中的表进行重排序。
对于外表,通常用户可以通过analyze语句完成统计数据的收集,或者手动指定 JOIN 的顺序。如需手动指定请按表的大小顺序,将小表放在右侧,大表放在左侧, 如表A > B > C, 例如:select * from A Join B Join C。需要注意的是,这不能保证所有场景下都能提升效率,实际上这取决于 JOIN 后的数据量大小。
优化 GROUP BY 语句
合理安排 GROUP BY 语句中字段顺序对性能有一定提升,请根据聚合字段的基数从高到低进行排序,例如:
//高效的写法SELECT id,gender,COUNT(*) FROM table_name GROUP BY id, gender;//低效的写法SELECT id,gender,COUNT(*) FROM table_name GROUP BY gender, id;
另一种优化方式是,尽可能地使用数字代替具体分组字段。这些数字是 SELECT 关键字后的列名的位置,例如上面的 SQL 可以用以下方式代替:
SELECT id,gender,COUNT(*) FROM table_name GROUP BY 1, 2;
使用近似聚合函数
对于允许有少量误差的查询场景,使用这一些近似聚合函数对查询性能有大幅提升。
例如,Presto 可以使用 APPROX_DISTINCT()函数代替 COUNT(distinct x),Spark 中对应函数为APPROX_COUNT_DISTINCT。该方案缺点是近似聚合函数有大概2.3%的误差。
使用 REGEXP_LIKE 代替多个 LIKE
当 SQL 中有多个 LIKE 语句时,通常可以使用正则表达式来代替多个 LIKE,这样可以大幅提升执行效率。例如:
SELECT COUNT(*) FROM table_name WHERE field_name LIKE '%guangzhou%' OR LIKE '%beijing%' OR LIKE '%chengdu%' OR LIKE '%shanghai%'
可以优化成:
SELECT COUNT(*) FROM table_name WHERE regexp_like(field_name, 'guangzhou|beijing|chengdu|shanghai')
数据治理
数据治理适用场景
场景:实时写入。Flink CDC 实时写入通常采用 upsert 的方式写入,该流程在写入过程中会产生大量的小文件,当小文件堆积到一定程度后会导致数据查询变慢,甚至超时无法查询。
可以通过以下方式查看表文件数量和快照信息。
SELECT COUNT(*) FROM [catalog_name.][db_name.]table_name$files;SELECT COUNT(*) FROM [catalog_name.][db_name.]table_name$snapshots;
例如:
SELECT COUNT(*) FROM `DataLakeCatalog`.`db1`.`tb1$files`;SELECT COUNT(*) FROM `DataLakeCatalog`.`db1`.`tb1$snapshots`;
数据治理效果
开启数据治理后,查询效率得到显著提升,例如下表对比了合并文件前后的查询耗时,该实验采用16CU presto,数据量为14M,文件数量2921,平均每个文件0.6KB。
执行语句 | 是否合并文件 | 文件数量 | 记录条数 | 查询耗时 | 效果 |
SELECT count(*) FROM tb | 否 | 2921个 | 7895条 | 32s | 速度快93% |
| SELECT count(*) FROM tb | 是 | 1个 | 7895条 | 2s |
分区
分区能够根据时间、地域等具有不同特征的列值将相关数据分类存储,这有助于大幅减少扫描量,提升查询效率。关于 DLC 外表分区更多详情信息,请参考一分钟入门分区表。下表展示了在数据量为66.6GB,数据记录为14亿条,数据格式为 orc 的单表中,分区和不分区时查询耗时和扫描量的效果对比。其中`dt`是含有1837个分区的分区字段。
查询语句 | 未分区 | 分区 | 耗时对比 | 扫描量对比 | ||
| | | 耗时 | 扫描量 | 耗时 | 扫描量 |
SELECT count(*) FROM tb WHERE dt='2001-01-08' | 2.6s | 235.9MB | 480ms | 16.5 KB | 快81% | 少99.9% |
SELECT count(*) FROM tb WHERE dt<'2022-01-08' AND dt>'2001-07-08' | 3.8s | 401.6MB | 2.2s | 2.8MB | 快42% | 少99.3% |
从上表中可以看出,分区可以有效地降低查询延时和扫描量,但过度分区可能适得其反。如下表所示。
查询语句 | 未分区 | 分区 | 耗时对比 | 扫描量对比 | ||
| | | 耗时 | 扫描量 | 耗时 | 扫描量 |
SELECT count(*) FROM tb | 4s | 24MB | 15s | 34.5MB | 慢73% | 多30% |
建议您在 SQL 语句中通过 WHERE 关键字来过滤分区。
缓存
在如今分布式计算和存算分离的趋势下,通过网络访问元数据以及海量数据将会受到网络 IO 的限制。DLC 默认开启以下缓存技术大幅降低响应延时,无需您介入管理。
Alluxio :是一种数据编排技术 。它提供缓存,将数据从存储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。Alluxio 内存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。
RaptorX:是Presto的一个连接器。它像 Presto 一样运行在存储之上,提供亚秒级延迟。 目标是为 OLAP 和交互式用例提供统一、廉价、快速且可扩展的解决方案。
结果缓存:Result Cache,对于重复的同一查询进行缓存,极大提高速度和效率。
DLC Presto 引擎默认支持 RaptorX 和 Alluxio 分级缓存,在短时间内相同任务场景中可以有效地降低延时。Spark、Presto引擎均支持结果缓存。
下表是在总数据量 为1TB的 Parquet 文件中的 TPCH 测试数据,本次测试选用16CU Presto。因为测试的是缓存功能,所以主要从 TPCH 中选择 IO 占用比较大的 SQL ,涉及的表主要有 lineitem、orders、customer 等表,涉及的 SQL 为 Q1、Q4、Q6、Q12、Q14、Q15、Q17、Q19 以及 Q20。其中横坐标表示SQL语句,纵坐标表示运行时间(单位秒)。
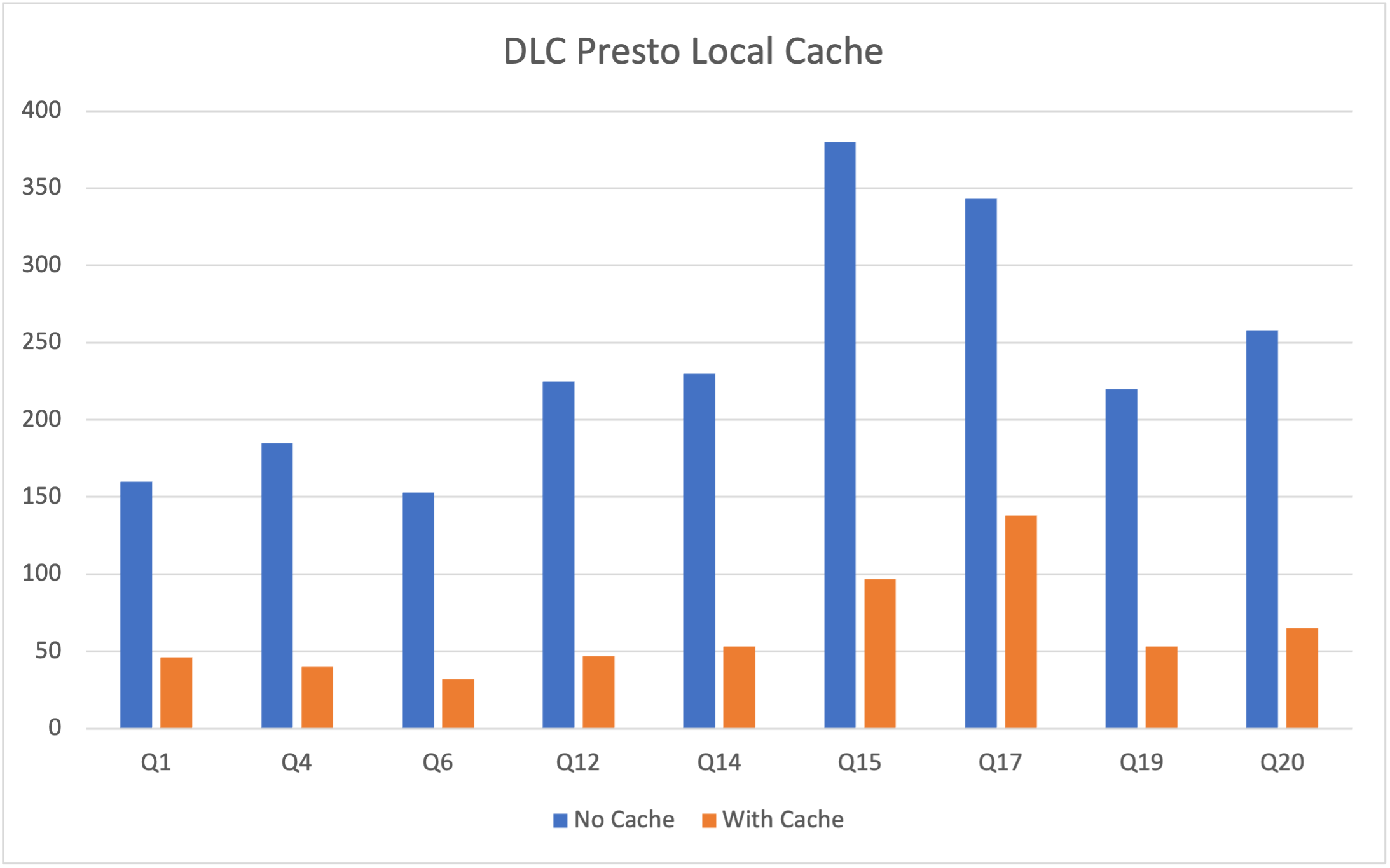
需要注意的是,DLC Presto 引擎会根据数据访问频率动态加载缓存,所以引擎启动后首次执行任务无法命中缓存,这导致首次执行仍受网络 IO 限制,但随着执行次数增加,该限制明显得到缓解。如下表展示了 presto 16cu 集群三次查询的性能比较。
查询语句 | 查询 | 耗时 | 数据扫描量 |
SELECT * FROM table_namewhere udid='xxx'; | 第一次查询 | 3.2s | 40.66MB |
| 第二次查询 | 2.5s | 40.66MB |
| 第三次查询 | 1.6s | 40.66MB |
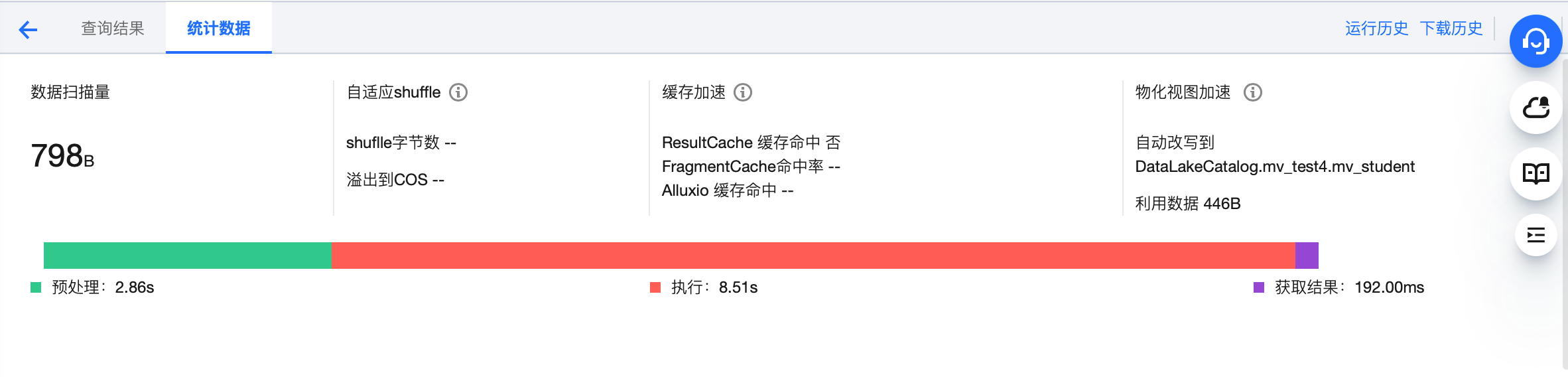
您可以在DLC控制台 数据探索 功能中查看执行的SQL任务的缓存命中情况。
索引
创建表后根据业务使用频率在 insert 前建立索引,WRITE ORDERED BY 后的索引字段。
alter table `DataLakeCatalog`.`dbname`.`tablename` WRITE ORDERED BY udid;
下表展示了 presto 16cu 集群在外表和内表(加索引)上查询性能比较
表类型 | 查询 | 耗时 | 数据扫描量 |
外表 | 第一次查询 | 16.5s | 2.42GB |
| 第二次查询 | 15.3s | 2.42GB |
| 第三次查询 | 14.3s | 2.42GB |
内表(索引) | 第一次查询 | 3.2s | 40.66MB |
| 第二次查询 | 2.5s | 40.66MB |
| 第三次查询 | 1.6s | 40.66MB |
从表中可以看出,内表+索引的建表方式相对于外表,在时间和扫描量上均会大幅减小,并且由于缓存加速,执行时间也会随着执行次数的增加而减少。
同步查询和异步查询
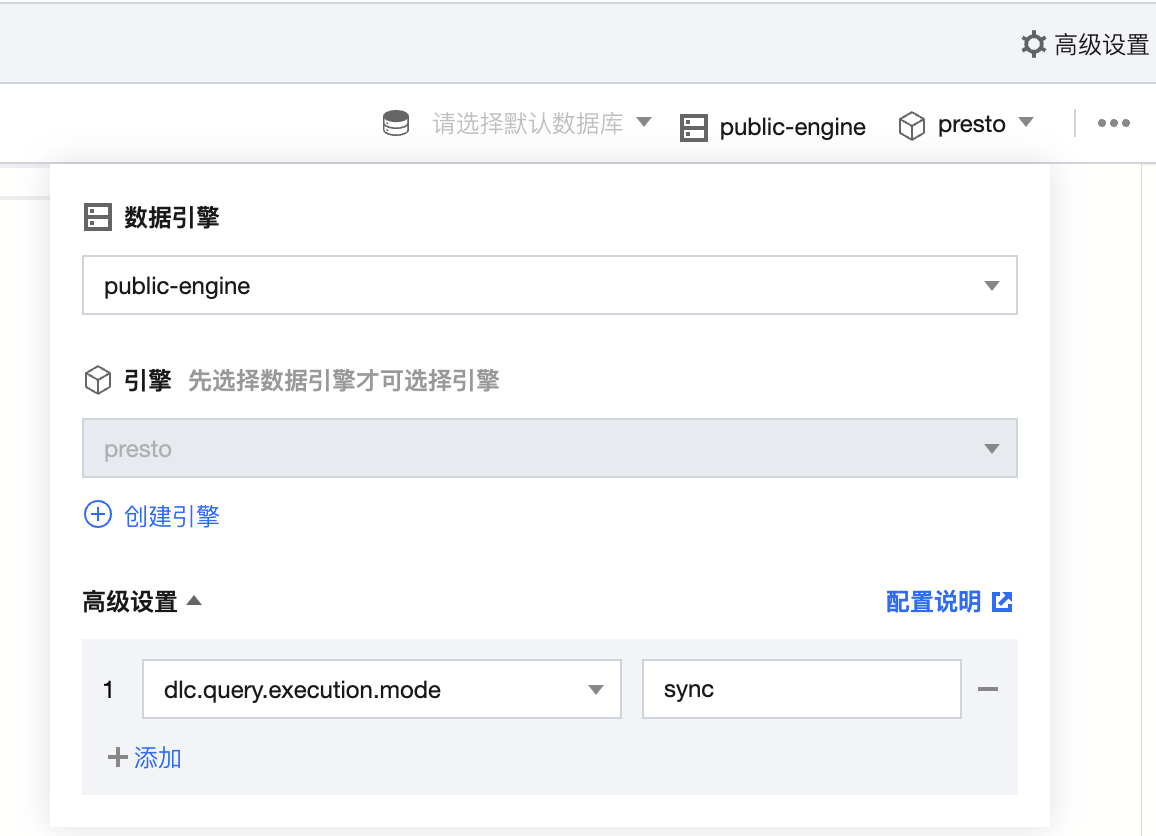
DLC 针对于 BI 场景进行了特别的优化,可以通过配置引擎参数dlc.query.execution.mode来开启同步模式或者异步模式(只支持 presto 引擎)。取值介绍如下。
async(默认):该模式任务会完成全量查询计算,并将结果保存到 COS,再返回给用户,允许用户在查询完成后下载查询结果。
sync:该模式下,查询不一定会执行全量计算,部分结果可用后,会直接由引擎返回给用户,不再保存到 COS。因此用户可获得更低查询延迟和耗时, 但结果只在系统中保存30s。推荐不需要从 COS 下载完整查询结果,但期望更低查询延迟和耗时时使用该模式,例如查询探索阶段、BI 结果展示。
配置方式:支持对数据引擎进行参数配置,选择数据引擎后,在高级设置单击添加即可进行配置。
资源瓶颈
1. 打开左侧数据引擎标签页。
2. 单击相应引擎的右侧监控按钮。
3. 跳转到腾讯云可观测平台,可以查看到所有监控指标,如下图所示。详细操作以及监控指标请参考数据引擎监控。同时您也可以针对每个指标进行告警配置,详细介绍请参考 监控告警配置。
其他因素
自适应 shuffle
DLC 默认关闭自适应 shuffle。当您任务出现 No space left 等磁盘空间不足的问题时,可以开启自适应 shuffle,这是一套即能支持有限本地磁盘的常规 shuffle,又能保证在大 shuffle 和数据倾斜等场景下的稳定性。自适应 shuffle 带来的优势:
1. 降低存储成本:集群节点的磁盘挂载量进一步降低,一般规模集群每节点只要50G、大规模集群也不超200G。
2. 稳定性:对于 shuffle 数据量剧增或数据倾斜场景任务执行的稳定性不会再因本地磁盘限制而失败。
尽管自适应 shuffle 带来存储成本的降低和稳定性提升,但在某些场景下,如资源不足时,会带来约15%的延时。
【开启方式】
集群配置中新增以下配置开启:spark.shuffle.manager=org.apache.spark.shuffle.enhance.EnhancedShuffleManager
可选配置:
如果您希望提前写入数据到远端,确保磁盘有足够空间,避免影响其他任务,可以考虑以下配置:
spark.shuffle.enhanced.usage.waterLevel1=磁盘比例,shuffle 结果写到远端时磁盘已使用的比例,默认0.7。
spark.shuffle.enhanced.usage.waterLevel2=磁盘比例,shuffle spill 数据写到远端时磁盘已使用的比例,默认0.9。
集群冷启动
DLC 支持自动或者手动挂起集群,挂起后不再产生费用,所以在集群启动后,首次执行任务可能存在“正在排队”的提示,这是因为集群冷启动中正在拉起资源。如果您频繁提交任务,建议购买包年包月集群,该类型集群不存在冷启动,能在任何时间快速执行任务。
Iceberg
分区扫描与谓词下推
Spark+Iceberg的场景,经常会遇到读分区表时,实际扫描的分区过大(常见的是直接扫描了全表)导致性能变差。原因是SQL中的where条件指定的分区字段的扫描条件,不能正常被下推到Scan的算子中,导致Iceberg Scan时需要先扫描全表,再在Spark中做过滤。
这种场景的表现在于读表性能极差,Spark UI中有Input的Stage input数据量远超过预期。
导致这种过滤条件的谓词不能正常下推到算子中的常见问题有:
分区字段类型和SQL中指定的常量值类型不一致。
SQL中指定的过滤条件是对分区字段做函数计算,而Iceberg不支持这种函数计算下推。
# ICEBERG TABLE partition_table PARTITIONED BY (dt STRING)## 谓词正常下推,只会扫描dt='20260109'的分区文件select * from partition_table where dt = '20260109';## 场景1:因为类型不对,导致谓词不能下推,扫描所有分区。## Spark实际解析为select * from partition_table where cast(dt as int) = 20260109, 而cast操作Iceberg不支持select * from partition_table where dt = 20260109;## 场景2:因为对分区字段做函数计算,导致谓词不能下推,扫描所有分区。select * from partition_table where date_diff(dt, '2026-01-08') > 7
ICEBERG 支持的分区字段的函数下推仅限于以下几种函数。

如果您的引擎在2025-12-19前购买的版本,上面两种场景都会导致谓词无法下推,Iceberg扫描全表的性能比较差。这时只能通过修改SQL来规避这个问题。
如果您的引擎是2025-12-19后购买的版本,则场景1中常量值类型和分区字段类型不匹配的问题会自动优化;而场景2中带函数计算的场景目前有任务级参数可控制。这两个功能支持的场景细节如下。
场景1
分区字段和常量值的场景,SQL形如where partition_filed OP Literal
针对OP为<=>, =, <=, >=, >, <的场景,当常量值类型和分区字段类型不一致时,会自动将常量值类型转成和分区字段一致的类型,形式如dt = cast (Literal as Type_Of_dt)。
可以通过参数spark.sql.optimizer.enableNormalizePartitionFilterCasts=true来控制,默认为true。
# ICEBERG TABLE partition_table PARTITIONED BY (dt STRING)## 谓词正常下推,只会扫描dt='20260109'的分区文件select * from partition_table where dt = '20260109';## 谓词可正常下推select * from partition_table where dt = 20260109;select * from partition_table where dt > 20260109;select * from partition_table where dt between 20260107 and 20260109;
场景2
分区字段带函数计算的场景,SQL形如 where function(partition_field) 或 where function(partition_field) = Literal
可以通过参数spark.sql.optimizer.foldingPartitionFiltersInDatasourceV2=true来控制,默认为false。
该场景生效有以下限制:
1. partition_field类型限制:ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType, StringType, DateType, TimestampType, TimestampNTZType
2. partition_field 无转换:不能带transformer,例如partitioned by year(dt), partitioned by bucket(6, dt)
3. function必须是确定性函数,且是Build-in函数。
4. 函数实际可匹配到的分区值个数总数小于等于366。当有多级分区时,这里的总数包括最底层的分区,例如year=2026&month=01, year=2026&month=02计算两次。可以通过参数spark.sql.optimizer.foldingPartitionFiltersMaxSize对个数限制做调整。
5. 如果匹配到分区值为null,我们会明确用isNull(partition_field)来替换。其他null值的场景不被支持。
6. 函数可以支持输入一个分区字段作为参数,也可以支持一级分区、二级分区两个参数。其他场景不被支持。
此外,我们对一些常见函数,包括date_diff,contains,concat,date_add,len,ends_with, unix_timestamp,date_format,coalesce及加减乘除做了验证,其他函数在不断验证中,如果您有其他函数不支持可以反馈给我们。
# ICEBERG TABLE partition_table PARTITIONED BY (dt STRING)## 谓词正常下推,只会扫描dt='20260109'的分区文件select * from partition_table where dt = '20260109';## 谓词可正常下推select * from partition_table where date_diff(id, '2025-12-14') < 7;select * from partition_table where date_format(ds, 'yyyy-MM-dd') is null;select * from partition_table where unix_timestamp(ds, 'yyyy-MM-dd') >= unix_timestamp('2025-12-21', 'yyyy-MM-dd');# ICEBERG TABLE partition_table PARTITIONED BY (dt STRING, hour STRING)## 谓词正常下推select * from partition_table where unix_timestamp(concat(dt, ' ', hour), 'yyyy-MM-dd HH') >= 176000000;



