UDF 说明
用户可通过编写 UDF 函数,打包为 JAR 文件后,在数据湖计算定义为函数在查询分析中使用。目前数据湖计算 DLC 的 UDF 为 HIVE 格式,继承 org.apache.hadoop.hive.ql.exec.UDF,实现 evaluate 方法。
示例:简单数组 UDF 函数。
public class MyDiff extends UDF {public ArrayList<Integer> evaluate(ArrayList<Integer> input) {ArrayList<Integer> result = new ArrayList<Integer>();result.add(0, 0);for (int i = 1; i < input.size(); i++) {result.add(i, input.get(i) - input.get(i - 1));}return result;}}
pom 文件参考:
<dependencies><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.16</version><scope>test</scope></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>1.2.1</version></dependency></dependencies>
UDF Jar 包的最佳实践
UDF 的 Jar 包是在函数注册或者使用时才会被加载到引擎中。在使用 UDF 时,建议您关注以下特性:
1. Jar 包的热更新。
Spark 默认不支持 Jar 包的热更新,DLC 中可以通过
spark.jars.update.enabled=true(引擎静态级参数,需要重启引擎,标准引擎20250630后的版本支持)打开,生产环境不建议打开,避免您误更新 COS 上的 Jar 包导致生产环境受到影响。2. Jar 包的版本和同名类。
由于 Java 的 ClassLoader 会优先从已经加载过的 Jar 包中搜寻类信息,所以您需要注意使用过程中避免多个版本/多个不同名称的 Jar 包中包含多个同名类的场景,否则会出现JVM加载到了旧的类导致计算结果错误。
3. Jar 包的安全性检查。
DLC 的 Spark 引擎在通过 UDF 加载 Jar 包时,您可以选择对 Jar 包做一层检查,您可以通过以下两个参数(任务级参数,无需重启引擎)调整:
spark.sql.udf.check.jar:默认值 false,打开 Jar 包的检查。spark.sql.udf.check.timeout.milliseconds:默认值30000,同步检查的时间,如果检查时间超过了该值,会放弃检查。检查的内容主要是避免 Jar 包存在问题而污染引擎的执行环境,包括:
检查指定 UDF 的类是否存在。
检查指定 UDF 的类是否可以正常初始化,例如 static 静态代码段是否正常。
检查指定的 Jar 包是否引入新的 Class-Path,例如 META-INF 里定义了 Class-Path: .这会导致循环加载。
检查指定的 Jar 包签名是否有问题,例如 signature 不合法会导致 Jar 包无法加载。
当检查不通过时,会提示 Resource/Class cannot be loaded safely, the source jar should be ignored,从而避免将有问题的 Jar 包安装到引擎导致集群不可用。
创建函数
方式一:SQL 命令创建
-- 创建临时函数(临时函数会实时加载Jar包到引擎,仅当前session有效)create temp function DB.TEMP_FUNCTION as 'JAR_CLASS_NAME' using jar 'cosn://bucket/path/to/jar';-- 创建常驻函数(注册到元数据中心,调用时加载Jar包到引擎)create function DB.FUNCTION as 'JAR_CLASS_NAME' using jar 'cosn://bucket/path/to/jar';
方式二:控制台创建
注意:
如您创建的是 udaf/udtf 函数,需要在函数名相应加上 _udaf/_udtf 后缀。
1. 登录 数据湖计算控制台 ,选择服务地域。
2. 通过左侧导航菜单进入数据管理,选择需要创建的函数的数据库,如果需要创建新的数据库,可参见 数据库管理。
3. 单击函数进入函数管理页面。
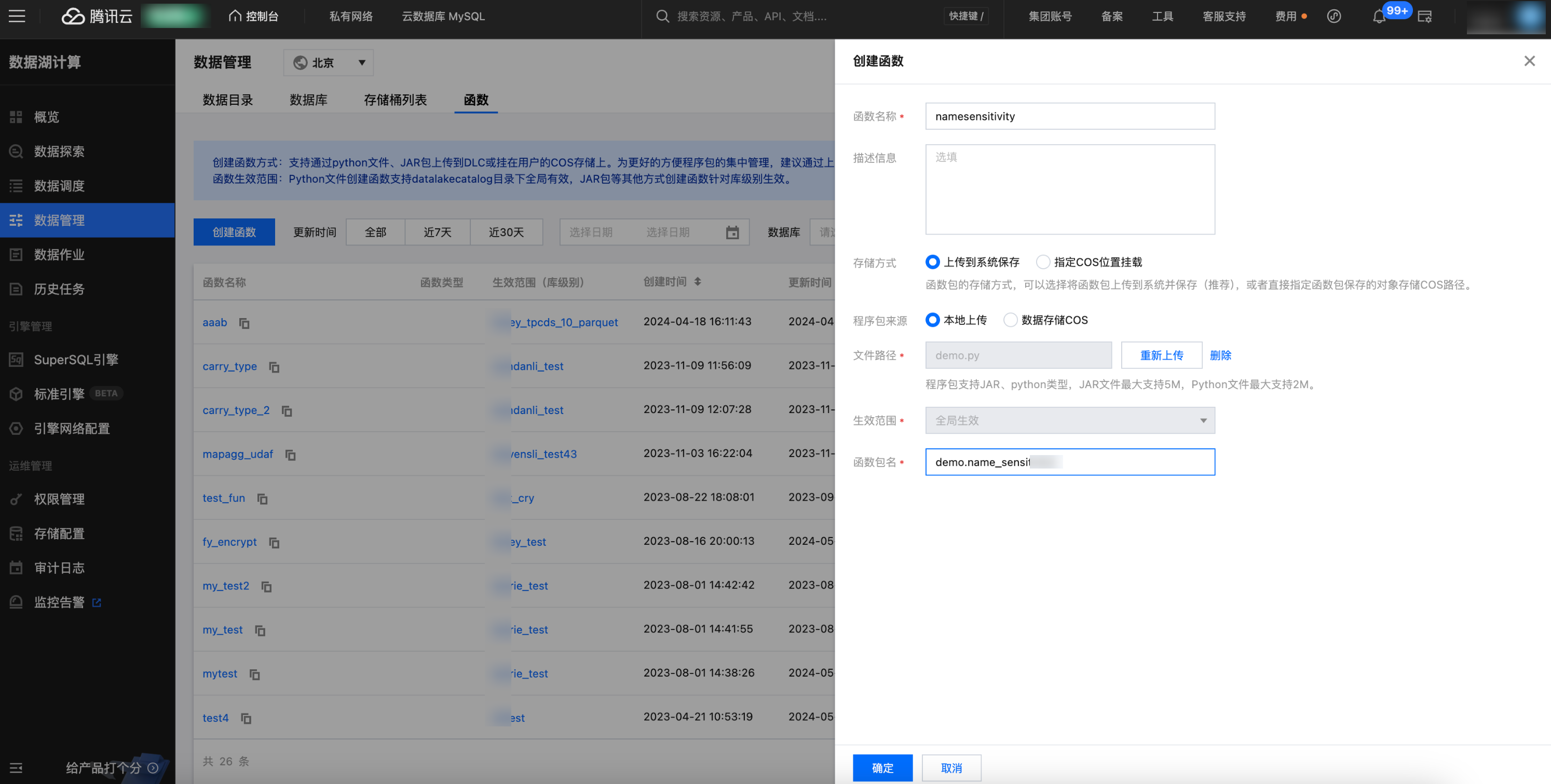
4. 单击创建函数进行创建。
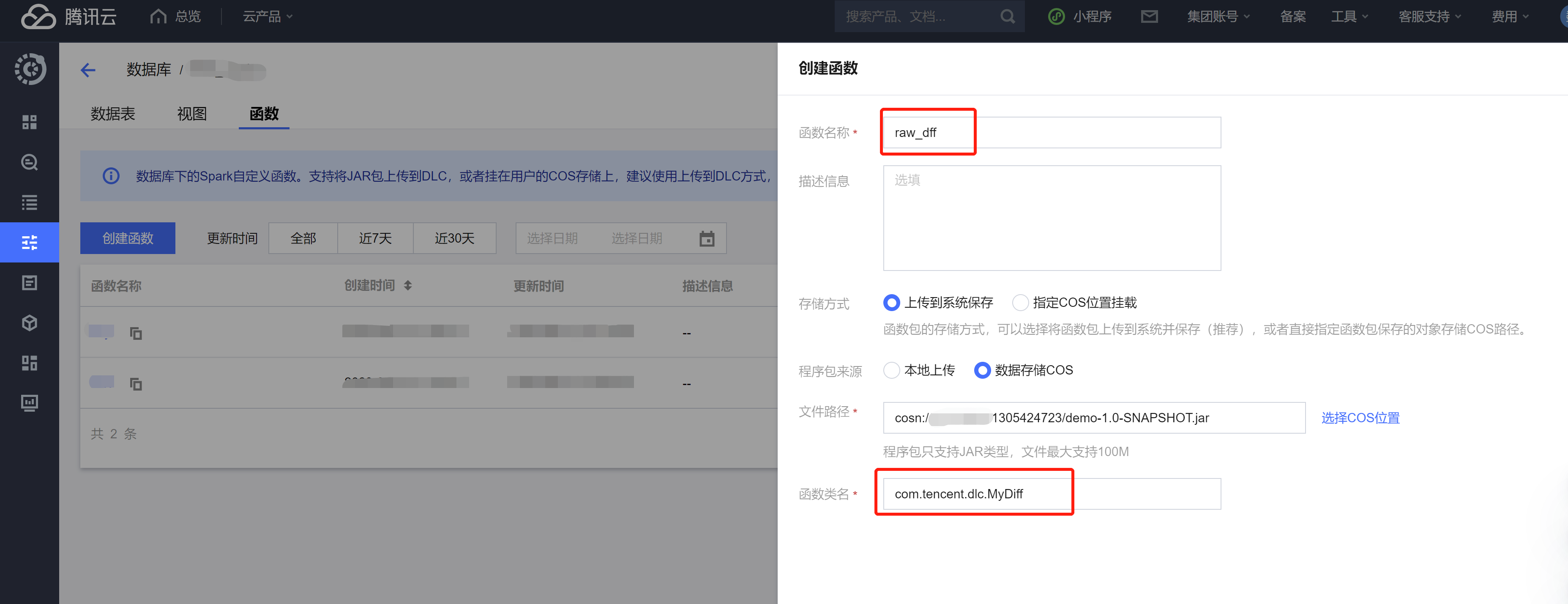
UDF 的程序包支持本地上传或选择 COS 路径(需具备 COS 相关权限),示例为选择 COS 路径创建。
函数类名包含“包信息”及“函数的执行类名”。
函数使用
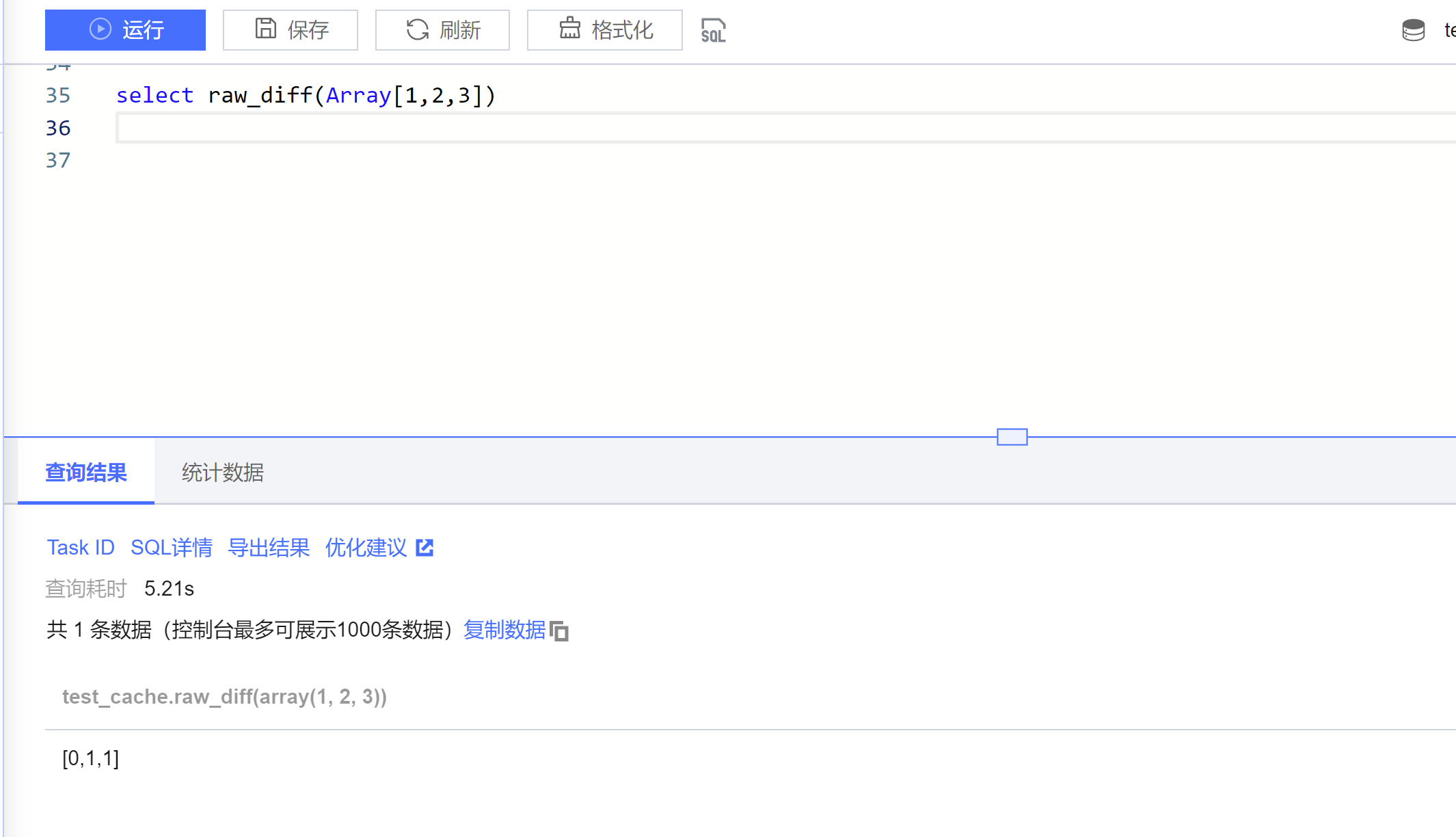
1. 登录 数据湖计算控制台,选择服务地域。
2. 通过左侧导航菜单进入数据探索,选择计算引擎后即可使用 SQL 调用函数(注意:请选择独享引擎,共享引擎暂不支持自定义 udf 函数使用)。
Python UDF 开发
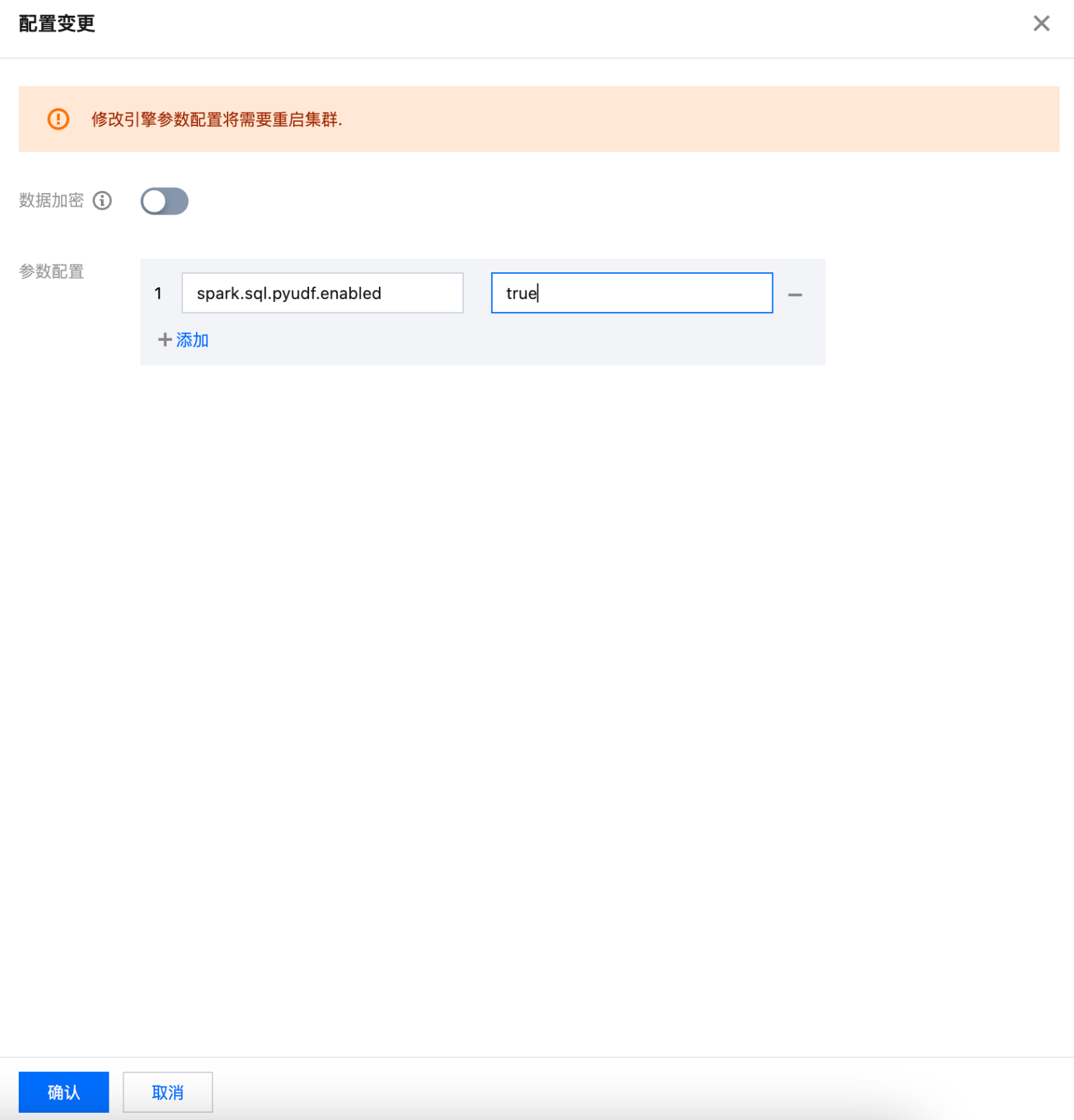
1. 开启集群 Python UDF 功能。
默认情况下,Python UDF 功能未开,请在引擎页面,选择需要开启的引擎,单击参数配置,加入配置。输入
spark.sql.pyudf.enabled = true 后,单击确认,进行保存。标准引擎资源组 或者 SparkSQL 集群待集群重启后生效,SparkBatch 集群下一个任务生效。
2. 注册 Python UDF 函数。
DLC 支持完全社区兼容的 UDF 函数。
示例,请编辑如下文件
demo.py :def name_sensitivity(name):if len(name) > 2:return name[0] + '*' * (len(name) - 2) + name[-1]elif len(name) == 2:return '*' + name[-1]else:return name
目前支持单 Python 文件。
只支持 import 系统自带模块。
请注意函数输入、输出类型。
请注意处理函数异常。
3. 在数据探索界面,使用开启了支持 Python UDF 的集群,并设置 Session 参数
eos.sql.processType=DIRECT如果您不能编辑该参数,请 提交工单 联系我们。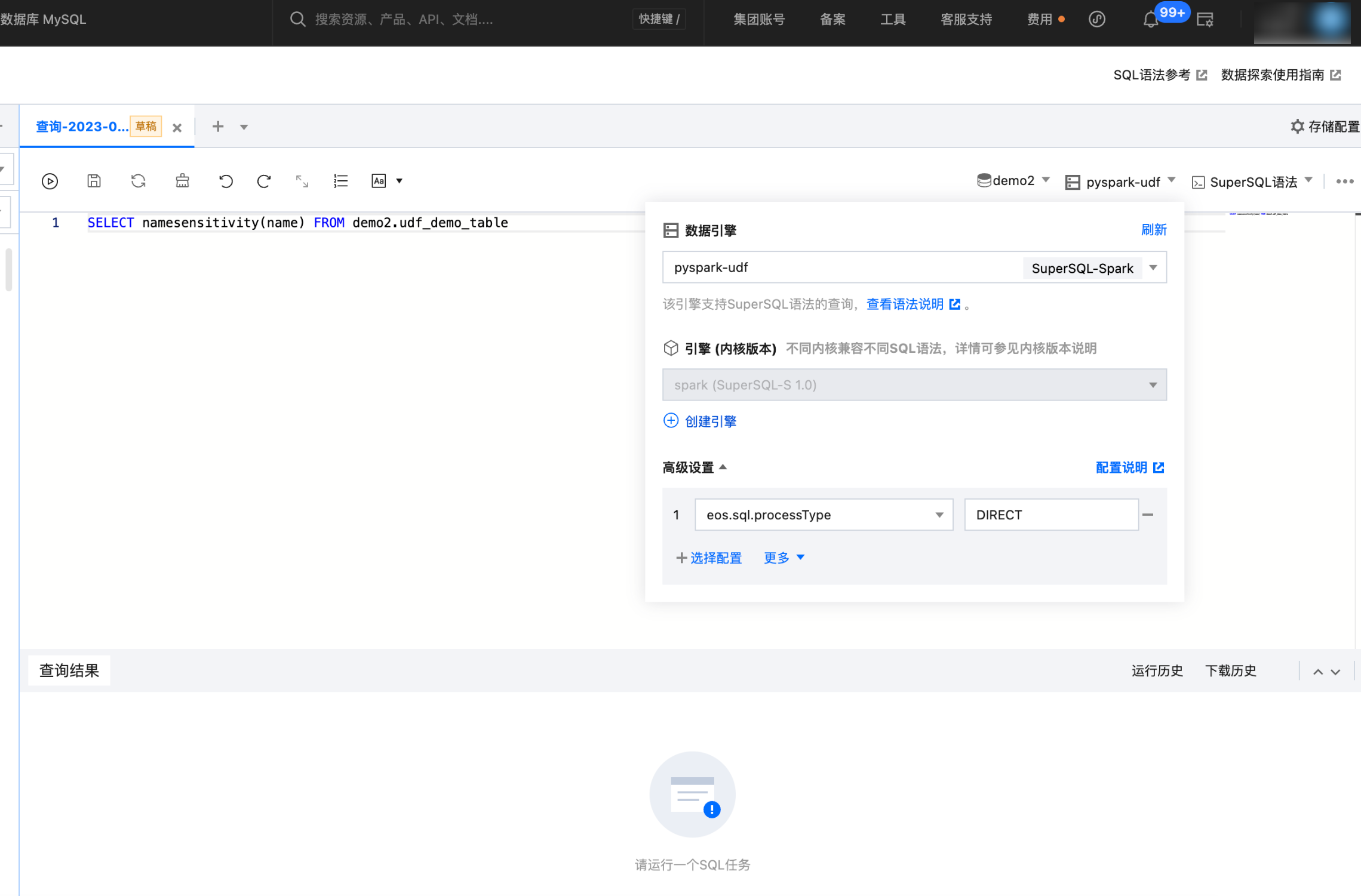
如果您需要编辑变更 Python UDF 函数,SparkSQL 集群加载机制约有30s延迟,SparkBatch 集群下一个任务立即生效。
如果您需要删除当前 Python UDF 函数,SparkSQL 集群需要重启集群,SparkBatch 集群下一个任务立即生效。
Python 函数编辑权限配置
说明:
当通过 Python 创建函数时,允许创建者及管理员对函数进行编辑权限配置。流程如下:
入口一:创建函数时进行编辑权限配置
1. 登录数据湖 DLC 控制台,选择服务地域。
2. 左侧菜单栏进入元数据管理,选择函数页面,单击函数栏左上方蓝色按钮创建函数,进入页面。
3. 单击函数编辑权限右侧展开,创建者可选择用户或工作组(可组合选择)进行对函数“编辑”和“删除”的授权,创建者和管理员默认拥有全部权限。
4. 设置完成后,单击确定,即可完成函数编辑权限配置。
入口二:对已有函数进行编辑权限配置
1. 登录数据湖 DLC 控制台,选择服务地域。
2. 左侧菜单栏进入元数据管理,选择函数页面,选择需要编辑的函数右侧操作栏的编辑按钮,即可进入编辑页面。
3. 进入编辑函数页面后,单击函数编辑权限右侧展开,可以进行权限的修改与删除。



