应用场景
CDC(Change Data Capture)是变更数据捕获的缩写,可以将源数据库中的增量变更近似实时同步到其他数据库或应用程序。DLC 支持通过 CDC 技术将源数据库的增量变更同步到 DLC 原生表,完成源数据入湖。
前置条件
正确开通 DLC,已完成用户权限配置,开通托管存储。
正确创建 DLC 数据库。
正确配置 DLC 数据库数据优化,详细配置请参考开启数据优化。
InLong 数据入湖
Oceanus 流计算数据入湖
自建 Flink 数据入湖
通过 Flink 可将源数据同步到 DLC。本示例展示将源 Kafka 的数据同步到 DLC,完成数据入湖。
环境准备
依赖集群:Kafka 2.4.x,Flink 1.15.x, Hadoop3.x。
整体操作过程
详细操作流程可参考如下图:

步骤1:上传依赖 Jar
1. 下载依赖 Jar
相关依赖 Jar 建议上传与Flink对应版本的Jar,例如 Flink 为 Flink1.15.x,则建议下载 flink-sql-connect-kafka-1.15.x.jar。相关文件参考附件。
2. 登录 Flink 集群,将准备好的 Jar 上传到 flink/ib 目录下。
步骤2:创建 Kafka Topic
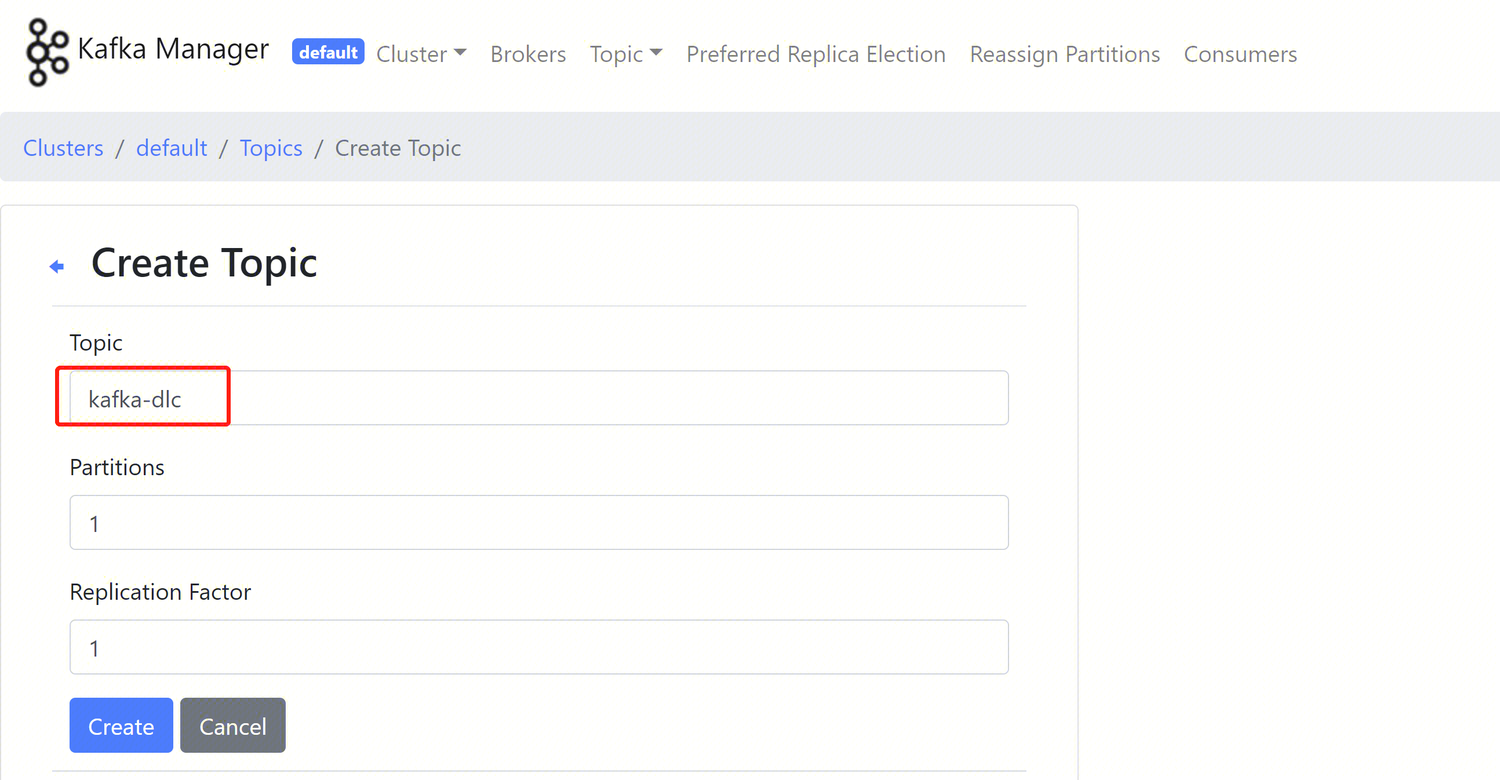
登录 Kafka Manager,单击 default 集群,单击 Topic > Create。
Topic 名称:本示例输入为 kafka_dlc
分区数:1
副本数:1
或者登录 Kafka 集群实例,在 kafka/bin 目录下使用如下命令创建 Topic。
./kafka-topics.sh --bootstrap-server ip:port --create --topic kafka-dlc
步骤3:DLC 新建目标表
步骤4:提交任务
Flink 同步数据的方式有2种,Flink SQL写入模式 和 Flink Stream API,以下会介绍2种同步方式。
提交任务前,需要新建保存 checkpoint 数据的目录,通过如下命令新建数据目录。
新建 hdfs /flink/checkpoints 目录:
hadoop fs -mkdir /flinkhadoop fs -mkdir /flink/checkpoints
Flink SQL 同步模式
1. 通过 IntelliJ IDEA 新建一个名称为“flink-demo”的 Maven 项目。
2. 在 pom 中添加相关依赖,依赖详情请参考 完整样例代码参考 > 示例1。
3. Java 同步代码:核心代码如下步骤展示,详细代码请参考 完整样例代码参考 > 示例2。
创建执行环境和配置 checkpoint:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(60000);env.getCheckpointConfig().setCheckpointStorage("hdfs:///flink/checkpoints");env.getCheckpointConfig().setCheckpointTimeout(60000);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
执行 Source SQL:
tEnv.executeSql(sourceSql);
执行 同步 SQL:
tEnv.executeSql(sql)
4. 通过 IntelliJ IDEA 对 flink-demo 项目编译打包,在项目 target 文件夹下生成 JAR 包 flink-demo-1.0-SNAPSHOT.jar。
5. 登录 Flink 集群其中的一个实例,上传 flink-demo-1.0-SNAPSHOT.jar 到 /data/jars/ 目录(没有目录则新建)。
6. 登录 Flink 集群其中的一个实例,在 flink/bin 目录下执行如下命提交同步任务。
./flink run --class com.tencent.dlc.iceberg.flink.AppendIceberg /data/jars/flink-demo-1.0-SNAPSHOT.jar
Flink Stream API 同步模式
1. 通过 IntelliJ IDEA 新建一个名称为“flink-demo”的 Maven 项目。
2. 在 pom 中添加相关依赖:完整样例代码参考 > 示例3。
3. Java 核心代码如下步骤展示,详细代码请参考 完整样例代码参考 > 示例4。
创建执行环境 StreamTableEnvironment,配置 checkpoint:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(60000);env.getCheckpointConfig().setCheckpointStorage("hdfs:///data/checkpoints");env.getCheckpointConfig().setCheckpointTimeout(60000);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
获取 Kafka 输入流:
KafkaToDLC dlcSink = new KafkaToDLC();DataStream<RowData> dataStreamSource = dlcSink.buildInputStream(env);
配置 Sink:
FlinkSink.forRowData(dataStreamSource).table(table).tableLoader(tableLoader).equalityFieldColumns(equalityColumns).metric(params.get(INLONG_METRIC.key()), params.get(INLONG_AUDIT.key())).action(actionsProvider).tableOptions(Configuration.fromMap(options))//默认为false,追加数据。如果设置为true 就是覆盖数据.overwrite(false).append();
执行同步 SQL:
env.execute("DataStream Api Write Data To Iceberg");
4. 通过 IntelliJ IDEA 对 flink-demo 项目编译打包,在项目 target 文件夹下生成 JAR 包 flink-demo-1.0-SNAPSHOT.jar。
5. 登录 Flink 集群其中的一个实例,上传 flink-demo-1.0-SNAPSHOT.jar 到 /data/jars/ 目录(没有目录则新建)。
6. 登录 Flink 集群其中的一个实例,在 flink/bin 目录下执行如下命令提交任务。
./flink run --class com.tencent.dlc.iceberg.flink.AppendIceberg /data/jars/flink-demo-1.0-SNAPSHOT.jar
步骤5:发送消息数据和查询同步结果
1. 登录 Kafka 集群实例,在 kafka/bin 目录 用如下命令,发送消息数据。
./kafka-console-producer.sh --broker-list 122.152.227.141:9092 --topic kafka-dlc
数据信息如下:
{"id":1,"name":"Zhangsan","age":18}{"id":2,"name":"Lisi","age":19}{"id":3,"name":"Wangwu","age":20}{"id":4,"name":"Lily","age":21}{"id":5,"name":"Lucy","age":22}{"id":6,"name":"Huahua","age":23}{"id":7,"name":"Wawa","age":24}{"id":8,"name":"Mei","age":25}{"id":9,"name":"Joi","age":26}{"id":10,"name":"Qi","age":27}{"id":11,"name":"Ky","age":28}{"id":12,"name":"Mark","age":29}
2. 查询同步结果
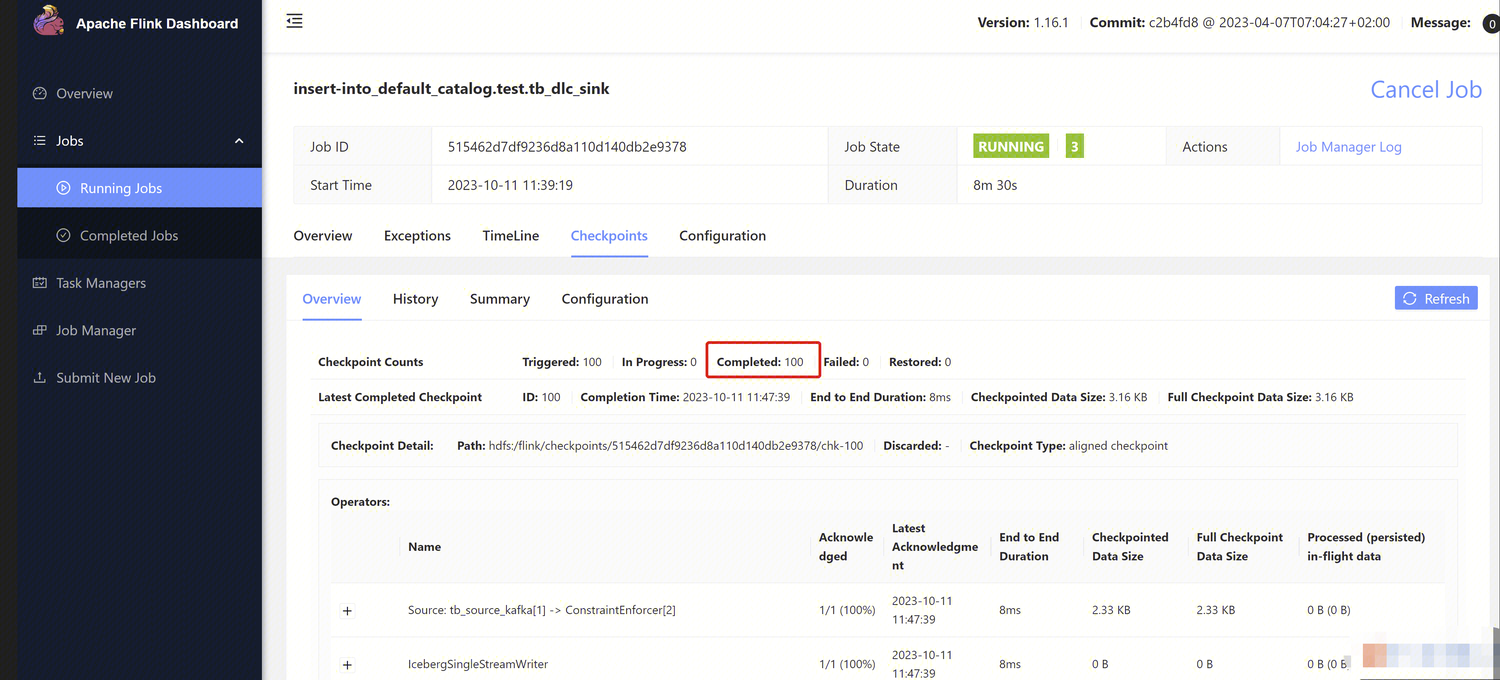
打开 Flink Dashboard,单击 Running Job > 运行Job > Checkpoint > Overview,查看 Job 同步结果。
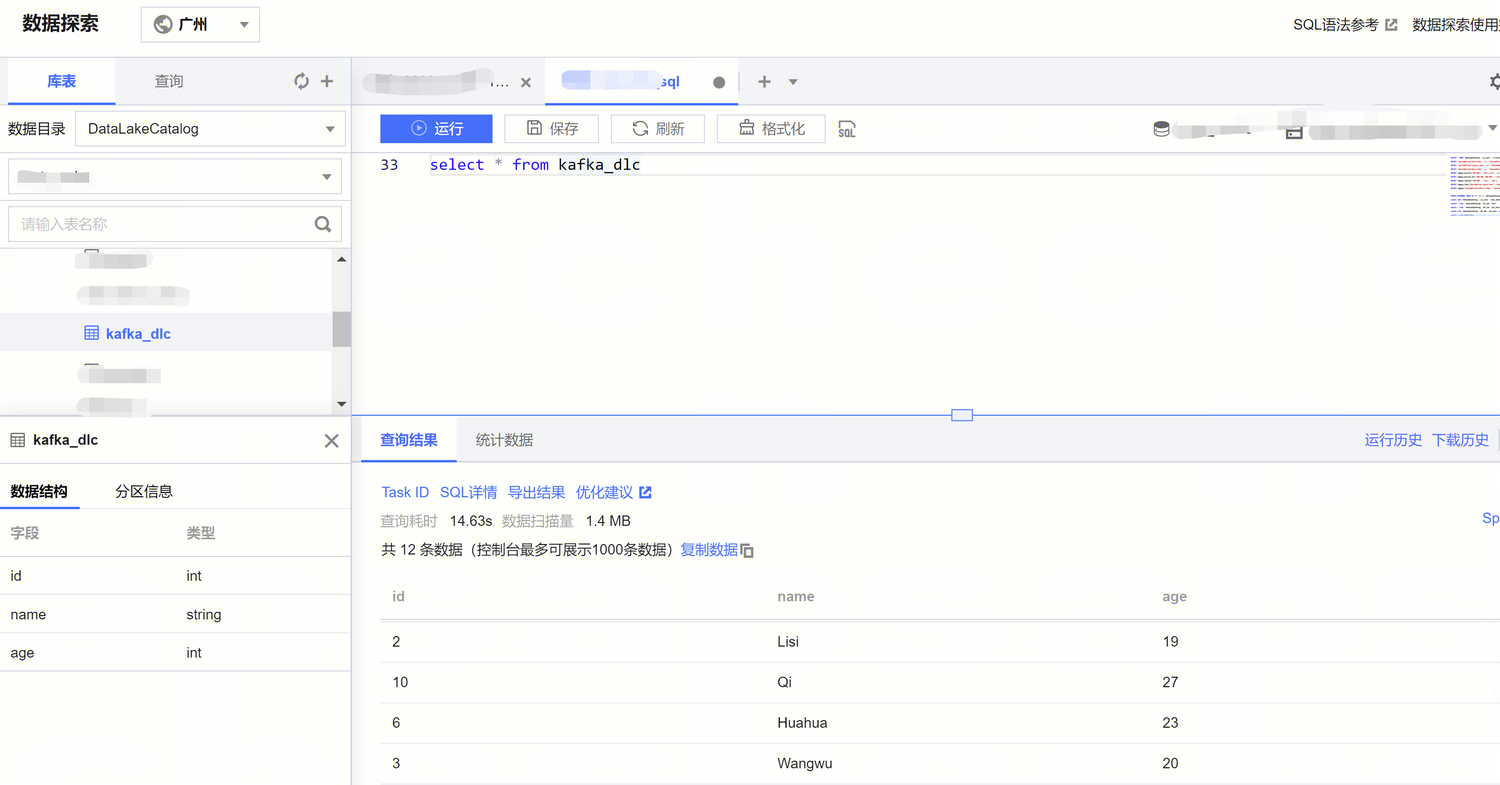
3. 登录 DLC 控制台,单击数据探索,查询目标表数据。
完整样例代码参考示例
说明:
示例1
<properties><flink.version>1.15.4</flink.version><cos.lakefs.plugin.version>1.0</cos.lakefs.plugin.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>com.qcloud.cos</groupId><artifactId>lakefs-cloud-plugin</artifactId><version>${cos.lakefs.plugin.version}</version><exclusions><exclusion><groupId>com.tencentcloudapi</groupId><artifactId>tencentcloud-sdk-java</artifactId></exclusion></exclusions></dependency></dependencies>
示例2
public class AppendIceberg {public static void main(String[] args) {// 创建执行环境 和 配置checkpointStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(60000);env.getCheckpointConfig().setCheckpointStorage("hdfs:///flink/checkpoints");env.getCheckpointConfig().setCheckpointTimeout(60000);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);// 创建输入表String sourceSql = "CREATE TABLE tb_kafka_sr ( \\n"+ " id INT, \\n"+ " name STRING, \\n"+ " age INT \\n"+ ") WITH ( \\n"+ " 'connector' = 'kafka', \\n"+ " 'topic' = 'kafka_dlc', \\n"+ " 'properties.bootstrap.servers' = '10.0.126.***:9092', \\n" // kafka 连接 ip 和 port+ " 'properties.group.id' = 'test-group', \\n"+ " 'scan.startup.mode' = 'earliest-offset', \\n" // 从可能的最早偏移量开始+ " 'format' = 'json' \\n"+ ");";tEnv.executeSql(sourceSql);// 创建输出表String sinkSql = "CREATE TABLE tb_dlc_sk ( \\n"+ " id INT PRIMARY KEY NOT ENFORCED, \\n"+ " name STRING,\\n"+ " age INT\\n"+ ") WITH (\\n"+ " 'qcloud.dlc.managed.account.uid' = '1000***79117',\\n" //用户Uid+ " 'qcloud.dlc.secret-id' = '***',\\n" // 用户SecretId+ " 'qcloud.dlc.region' = 'ap-***',\\n" // 数据库表地域信息+ " 'qcloud.dlc.user.appid' = '130***1723',\\n" // 用户appId+ " 'qcloud.dlc.secret-key' = '***',\\n" // 用户 SecretKey+ " 'connector' = 'iceberg-inlong', \\n"+ " 'catalog-database' = 'test_***', \\n" // 目标数据库+ " 'catalog-table' = 'kafka_dlc', \\n" // 目标数据表+ " 'default-database' = 'test_***', \\n" //默认数据库+ " 'catalog-name' = 'HYBRIS', \\n"+ " 'catalog-impl' = 'org.apache.inlong.sort.iceberg.catalog.hybris.DlcWrappedHybrisCatalog', \\n"+ " 'uri' = 'dlc.tencentcloudapi.com', \\n"+ " 'fs.cosn.credentials.provider' = 'org.apache.hadoop.fs.auth.DlcCloudCredentialsProvider', \\n"+ " 'qcloud.dlc.endpoint' = 'dlc.tencentcloudapi.com', \\n"+ " 'fs.lakefs.impl' = 'org.apache.hadoop.fs.CosFileSystem', \\n"+ " 'fs.cosn.impl' = 'org.apache.hadoop.fs.CosFileSystem', \\n"+ " 'fs.cosn.userinfo.region' = 'ap-***', \\n" // 使用到的COS的地域信息+ " 'fs.cosn.userinfo.secretId' = '***', \\n" // 用户SecretId+ " 'fs.cosn.userinfo.secretKey' = '***', \\n" // 用户 SecretKey+ " 'service.endpoint' = 'dlc.tencentcloudapi.com', \\n"+ " 'service.secret.id' = '***', \\n" // 用户SecretId+ " 'service.secret.key' = '***', \\n" // 用户 SecretKey+ " 'service.region' = 'ap-***', \\n" // 数据库表地域信息+ " 'user.appid' = '1305424723', \\n"+ " 'request.identity.token' = '1000***79117', \\n"+ " 'qcloud.dlc.jdbc.url'='jdbc:dlc:dlc.internal.tencentcloudapi.com?task_type=SparkSQLTask&database_name=test_***&datasource_connection_name=DataLakeCatalog®ion=ap-***&data_engine_name=flink-***' \\n"+ ");";tEnv.executeSql(sinkSql);// 执行计算并输出String sql = "insert into tb_dlc_sk select * from tb_kafka_sr";tEnv.executeSql(sql);}}
示例3
<properties><flink.version>1.15.4</flink.version></properties><dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.22</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.inlong</groupId><artifactId>sort-connector-iceberg-dlc</artifactId><version>1.6.0</version><scope>system</scope><systemPath>${project.basedir}/lib/sort-connector-iceberg-dlc-1.6.0.jar</systemPath></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka-version}</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.25</version></dependency></dependencies>
示例4
public class KafkaToDLC {public static void main(String[] args) throws Exception {final MultipleParameterTool params = MultipleParameterTool.fromArgs(args);final Map<String, String> options = setOptions();//1.执行环境 StreamTableEnvironment,配置checkpointStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(60000);env.getCheckpointConfig().setCheckpointStorage("hdfs:///data/checkpoints");env.getCheckpointConfig().setCheckpointTimeout(60000);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);env.getConfig().setGlobalJobParameters(params);//2.获取输入流KafkaToDLC dlcSink = new KafkaToDLC();DataStream<RowData> dataStreamSource = dlcSink.buildInputStream(env);//3.创建Hadoop配置、Catalog配置CatalogLoader catalogLoader = FlinkDynamicTableFactory.createCatalogLoader(options);TableLoader tableLoader = TableLoader.fromCatalog(catalogLoader,TableIdentifier.of(params.get(CATALOG_DATABASE.key()), params.get(CATALOG_TABLE.key())));tableLoader.open();Table table = tableLoader.loadTable();ActionsProvider actionsProvider = FlinkDynamicTableFactory.createActionLoader(Thread.currentThread().getContextClassLoader(), options);//4.创建SchemaSchema schema = Schema.newBuilder().column("id", DataTypeUtils.toInternalDataType(new IntType(false))).column("name", DataTypeUtils.toInternalDataType(new VarCharType())).column("age", DataTypeUtils.toInternalDataType(new DateType(false))).primaryKey("id").build();List<String> equalityColumns = schema.getPrimaryKey().get().getColumnNames();//5.配置SlinkFlinkSink.forRowData(dataStreamSource)//这个 .table 也可以不写,指定tableLoader 对应的路径就可以。.table(table).tableLoader(tableLoader).equalityFieldColumns(equalityColumns).metric(params.get(INLONG_METRIC.key()), params.get(INLONG_AUDIT.key())).action(actionsProvider).tableOptions(Configuration.fromMap(options))//默认为false,追加数据。如果设置为true 就是覆盖数据.overwrite(false).append();//6.执行同步env.execute("DataStream Api Write Data To Iceberg");}private static Map<String, String> setOptions() {Map<String, String> options = new HashMap<>();options.put("qcloud.dlc.managed.account.uid", "1000***79117"); //用户Uidoptions.put("qcloud.dlc.secret-id", "***"); // 用户SecretIdoptions.put("qcloud.dlc.region", "ap-***"); // 数据库表地域信息options.put("qcloud.dlc.user.appid = '130***1723'" ); // 用户appIdoptions.put("qcloud.dlc.secret-key", "***"); // 用户 SecretKeyoptions.put("connector", "iceberg-inlong");options.put("catalog-database", "test_***"); // 目标数据库options.put("catalog-table", "kafka_dlc"); // 目标数据表options.put("default-database", "test_***"); //默认数据库options.put("catalog-name", "HYBRIS");options.put("catalog-impl", "org.apache.inlong.sort.iceberg.catalog.hybris.DlcWrappedHybrisCatalog");options.put("uri", "dlc.tencentcloudapi.com");options.put("fs.cosn.credentials.provider", "org.apache.hadoop.fs.auth.DlcCloudCredentialsProvider");options.put("qcloud.dlc.endpoint", "dlc.tencentcloudapi.com");options.put("fs.lakefs.impl", "org.apache.hadoop.fs.CosFileSystem");options.put("fs.cosn.impl", "org.apache.hadoop.fs.CosFileSystem");options.put("fs.cosn.userinfo.region", "ap-***"); // 使用到的COS的地域信息options.put("fs.cosn.userinfo.secretId", "***"); // 用户SecretIdoptions.put("fs.cosn.userinfo.secretKey", "***"); // 用户 SecretKeyoptions.put("service.endpoint", "dlc.tencentcloudapi.com");options.put("service.secret.id", "***"); // 用户SecretIdoptions.put("service.secret.key", "***"); // 用户 SecretKeyoptions.put("service.region", "ap-***"); // 数据库表地域信息options.put("user.appid", "1305***23");options.put("request.identity.token", "1000***79117");options.put("qcloud.dlc.jdbc.url","jdbc:dlc:dlc.internal.tencentcloudapi.com?task_type,SparkSQLTask&database_name,test_***&datasource_connection_name,DataLakeCatalog®ion,ap-***&data_engine_name,flink-***");return options;}/*** 创建输入流** @param env* @return*/private DataStream<RowData> buildInputStream(StreamExecutionEnvironment env) {//1.配置执行环境EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();StreamTableEnvironment sTableEnv = StreamTableEnvironment.create(env, settings);org.apache.flink.table.api.Table table = null;//2.执行SQL,获取数据输入流try {sTableEnv.executeSql(createTableSql()).print();table = sTableEnv.sqlQuery(transformSql());DataStream<Row> rowStream = sTableEnv.toChangelogStream(table);DataStream<RowData> rowDataDataStream = rowStream.map(new MapFunction<Row, RowData>() {@Overridepublic RowData map(Row rows) throws Exception {GenericRowData rowData = new GenericRowData(3);rowData.setField(0, rows.getField(0));rowData.setField(1, (String) rows.getField(1));rowData.setField(2, rows.getField(2));return rowData;}});return rowDataDataStream;} catch (Exception e) {throw new RuntimeException("kafka to dlc transform sql execute error.", e);}}private String createTableSql() {String tableSql = "CREATE TABLE tb_kafka_sr ( \\n"+ " id INT, \\n"+ " name STRING, \\n"+ " age INT \\n"+ ") WITH ( \\n"+ " 'connector' = 'kafka', \\n"+ " 'topic' = 'kafka_dlc', \\n"+ " 'properties.bootstrap.servers' = '10.0.***:9092', \\n"+ " 'properties.group.id' = 'test-group-10001', \\n"+ " 'scan.startup.mode' = 'earliest-offset', \\n"+ " 'format' = 'json' \\n"+ ");";return tableSql;}private String transformSql() {String transformSQL = "select * from tb_kafka_sr";return transformSQL;}}



