Redis 实例 CPU 使用率升高会影响整个实例集群的吞吐量,甚至可能会导致应用阻塞,超时中断。当平均 CPU 使用率高于60%或者 CPU 平均峰值使用率高于90%且持续时间超过5分钟时,您需要及时排查具体原因,针对性快速解决问题,以保障业务稳定性和可用性。
现象描述
现象1:收到 CPU 使用率过高的消息提醒:
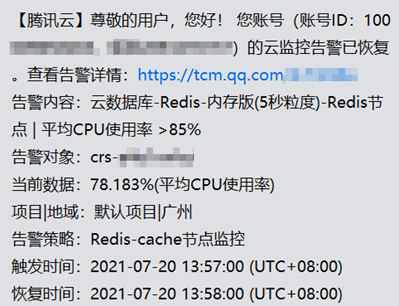
现象2:CPU 使用率的监控指标高。
现象3:整体吞吐量变小、响应速度变慢。
可能原因、排查及解决方法
可能原因 | 原因分析 | 排查方法 | 解决方法 |
频繁建立短连接 | 实例大量资源消耗在处理频繁短连接上,引起 CPU 使用率较高,连接数较高,但 QPS(集群每秒访问次数)未达到预期。 | | 应急处理:Kill 会话。 推荐解决方法:将短连接调整为长连接,例如使用 JedisPool 连接池连接。具体代码示例,请参见 Jedis 客户端。 |
存在高时间复杂度的命令。例如:sort、sunion、zunionstore 等。 | Redis 是单线程执行命令,执行复杂度高的命令,很可能阻塞其他命令。命令的时间复杂度越高,在执行时会消耗较多的资源,同时产生慢日志,会引起 CPU 使用率上升。 | | 使用复杂度较高命令,每次不要获取太多的数据,尽量操作少量的数据,让 Redis 可以及时处理返回。 |
存在对热点 Key 的大量访问 | 热 Key 指的是那些在一段时间内访问频率特别高的键值。具体到业务场景,包括热点新闻、热门直播、秒杀活动等。大量访问流量集中到一个实例中,达到单个实例的处理上限,引起 CPU 使用率上升。 | 拆分复杂数据结构,将热点 Key 拆分为若干个新的 Key 分布到不同 Redis 节点上,从而减轻压力。以哈希类型为例,该热 Key 的类型是一个二级数据结构,该哈希元素个数可能较多,可以考虑将当前 hash 进行拆分。 | |
存在大 Key | 大 Key 指某个 Key 对应的 value 很大,占用的 Redis 空间很大。执行大 Key 相关读取或者删除操作时,会严重占用带宽和CPU。 | 若是 value 过大,您可以将对象拆分成多个 key-value,将操作压力平摊到多个 Redis 实例;若是 Key 过多,您可以参考 hash 结构存储,将多个 Key 存储在一个 hash 结构中。 | |
读写负载过高 | 读负载过高,达到资源上限 写负载过高,内存规格不足 | 写负载过高:通过 增加分片数量 的方式来分摊写负载。若实例为标准架构,请优先升级标准架构为集群架构,提升 CPU 处理能力。具体操作,请参见 升级实例架构。升级集群架构之前需要检测兼容性,请参见 标准架构迁移集群架构检查。 | |
频繁切换 DB,即频繁执行 select 命令进行 DB 切换。 | 频繁切换 DB,带来资源的过度开销。 | 使用诊断优化 > 延迟分析 > 命令字分析功能,对命令字分析中 select 命令的监控数据进行确认,确认是否存在 select 请求比较多的现象。具体排查方法请参见 排查频繁执行的 select 命令。 | 若存储不同业务,针对频繁切换 DB 的业务,建议分开存储。 若存储相同业务,评估 Key 名不冲突的前提下,考虑将数据存储在相同的 DB,减少 select 请求操作次数。 |
排查并优化短连接
排查步骤
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化。
2. 在页面上方选择数据库类型 Redis 和实例 ID,选择实时会话页签。
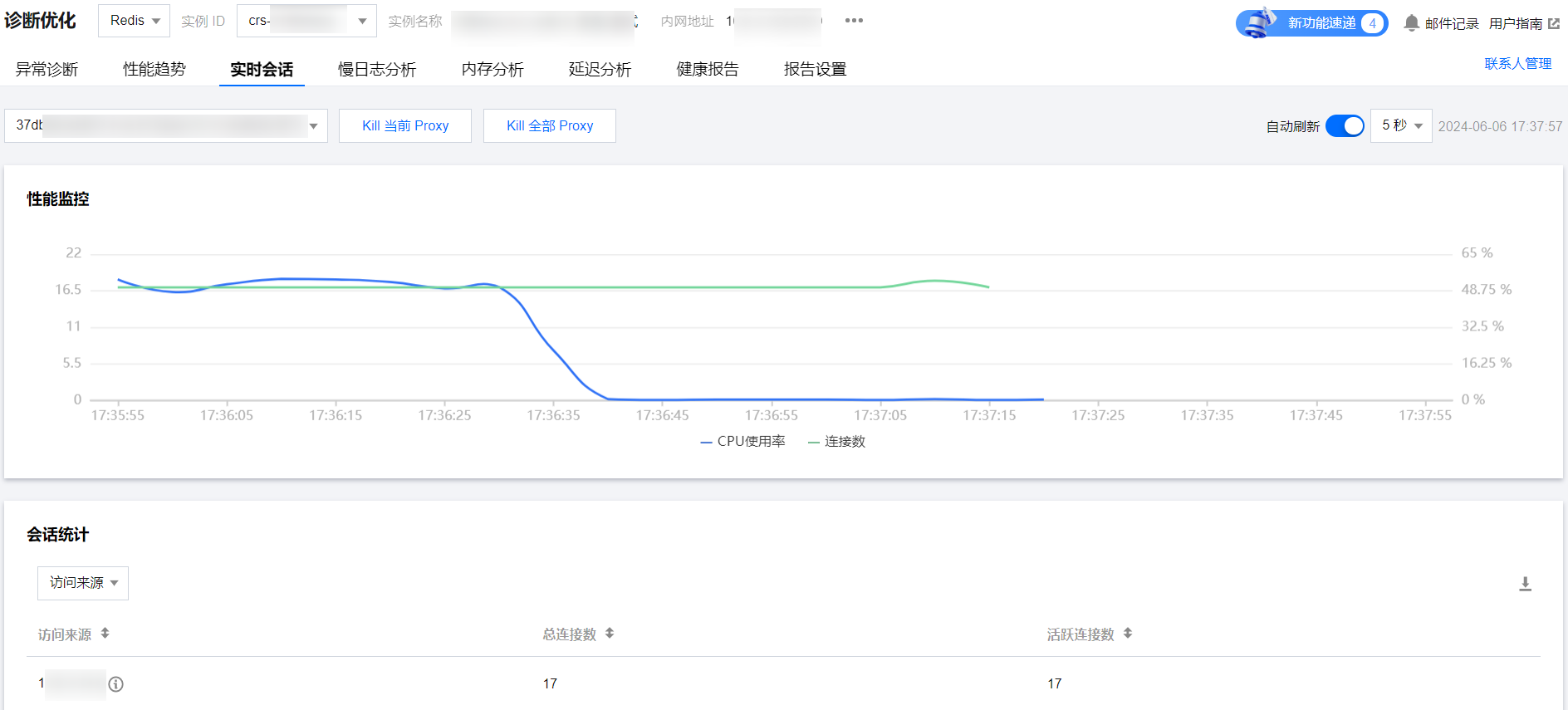
3. 在性能监控趋势图左上方的下拉列表中,选择待分析的 Proxy ID。
4. 在性能监控趋势图中,查看是否存在 CPU 使用率较高,连接数较高。
解决方法
应急处理
Kill 会话。DBbrain 支持 Kill 所选 Redis 实例当前 Proxy 或全部 Proxy 的客户端连接。
说明:
Kill 会话会中断正在进行的操作并可能导致数据丢失,请谨慎使用。在使用之前,请先备份数据并评估风险。
在页面上方单击 Kill 当前 Proxy,在弹出的对话框中,单击确定。

在页面上方单击 Kill 全部 Proxy,在弹出的对话框中,单击确定。

推荐解决方法
排查复杂度较高命令
排查步骤
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化。
2. 在页面上方选择数据库类型 Redis 和实例 ID,选择慢日志分析页签。
3. 选择查看实例级别或 Proxy 节点慢日志。
单击实例,查看实例维度的慢日志统计趋势图。
单击 Proxy 节点,在其后面的下拉列表中选择需分析的 Proxy ID,可根据 CPU 使用率的趋势图或慢查询数量变化的趋势图选择需分析的 Proxy ID。
4. 在页面上方选择时间范围查看慢 SQL。支持选择当天、近5分钟、近10分钟、近1小时、近3小时、近24小时、近3天和自定义时间段。
若此实例在该时间段中有慢 SQL,SQL 统计会以柱形图的方式展示慢 SQL 产生的时间点和个数。单击柱形图,下方的慢日志列表会显示对应的所有慢 SQL 信息(模板聚合之后的 SQL),右方会显示该时间段内 SQL 的耗时分布。
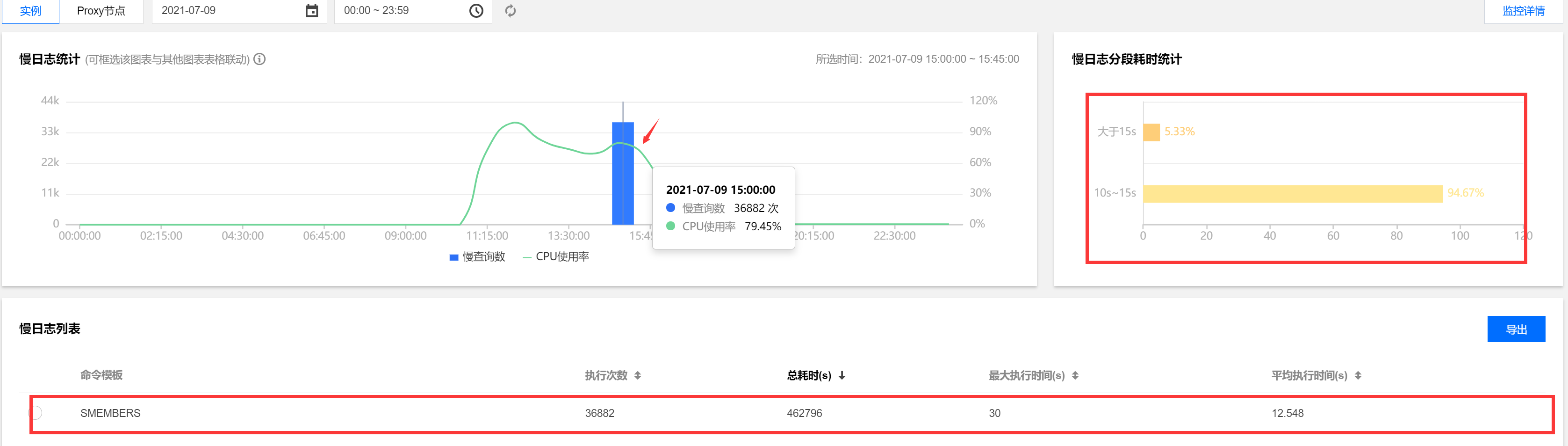
5. 在慢日志列表中可找到类似 sort、sunion、zunionstore 等复杂度较高的命令。
解决方法
使用复杂度较高命令,每次不要获取太多的数据,尽量操作少量的数据,让 Redis 可以及时处理返回。
排查访问频次高的热 Key
排查步骤
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化。
2. 在页面上方选择数据库类型 Redis 和实例 ID,选择延迟分析 > 热 Key 分析。

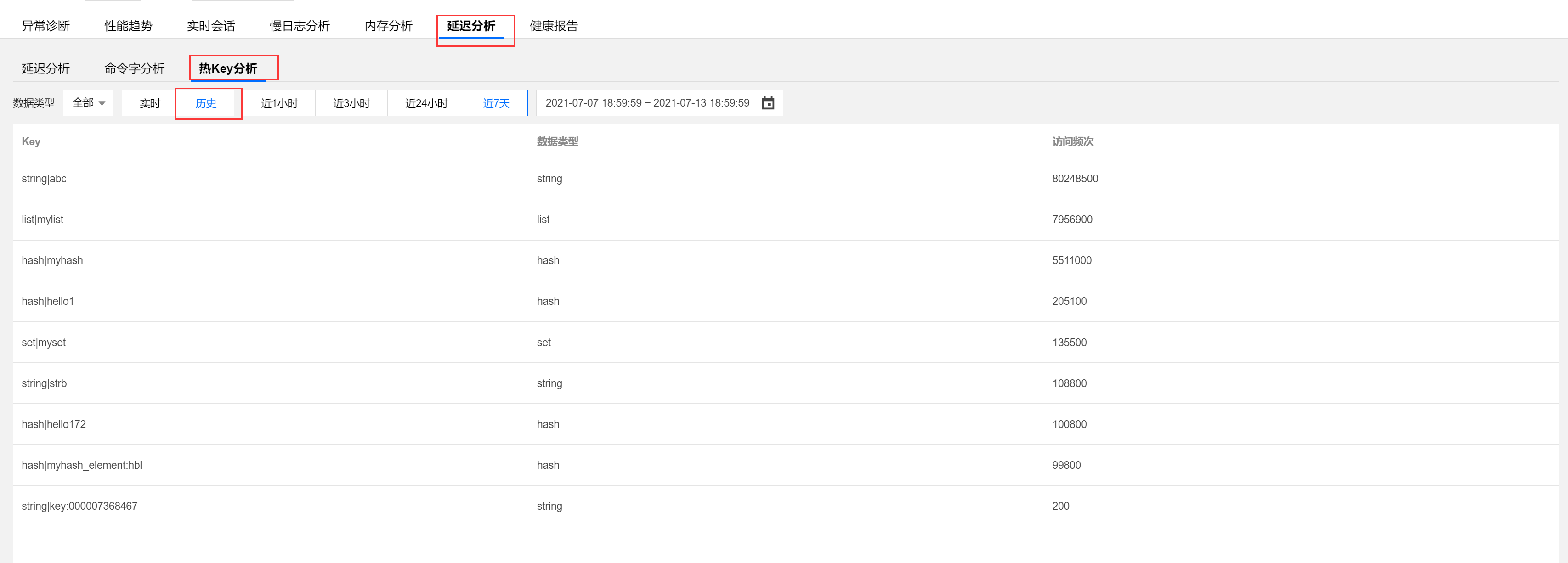
3. 在热 Key 分析页面,数据库类型选择全部,若明确 Redis 节点请选择具体节点,若不明确 Redis 节点请选择所有节点。

4. 选择实时或历史视图,选择待查看的时间段,查看访问频率高的热 Key。
解决方法
拆分复杂数据结构,将热点 Key 拆分为若干个新的 Key 分布到不同 Redis 节点上,从而减轻压力。以哈希类型为例,该热 Key 的类型是一个二级数据结构,该哈希元素个数可能较多,可以考虑将当前 hash 进行拆分。
排查大 Key
排查步骤
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化。
2. 在页面上方选择数据库类型 Redis 和实例 ID,选择内存分析 > 即时大 Key 分析。

3. 单击创建任务,在弹出的对话框中选择分隔符、选择分片编号,单击确认。
注意:
标准架构实例:仅需要选择分隔符,任务启动后,创建一个 Redis 备份任务,基于备份数据进行大 Key 分析,默认保存30天分析结果。如果数据量过大,可能会导致分析任务失败。
集群架构实例:需要选择分隔符和分片,任务启动后,会根据您选择的分片创建一个 Redis 备份任务,基于备份数据进行大 Key 分析,默认保存30天分析结果。如果数据量过大,可能会导致分析任务失败。
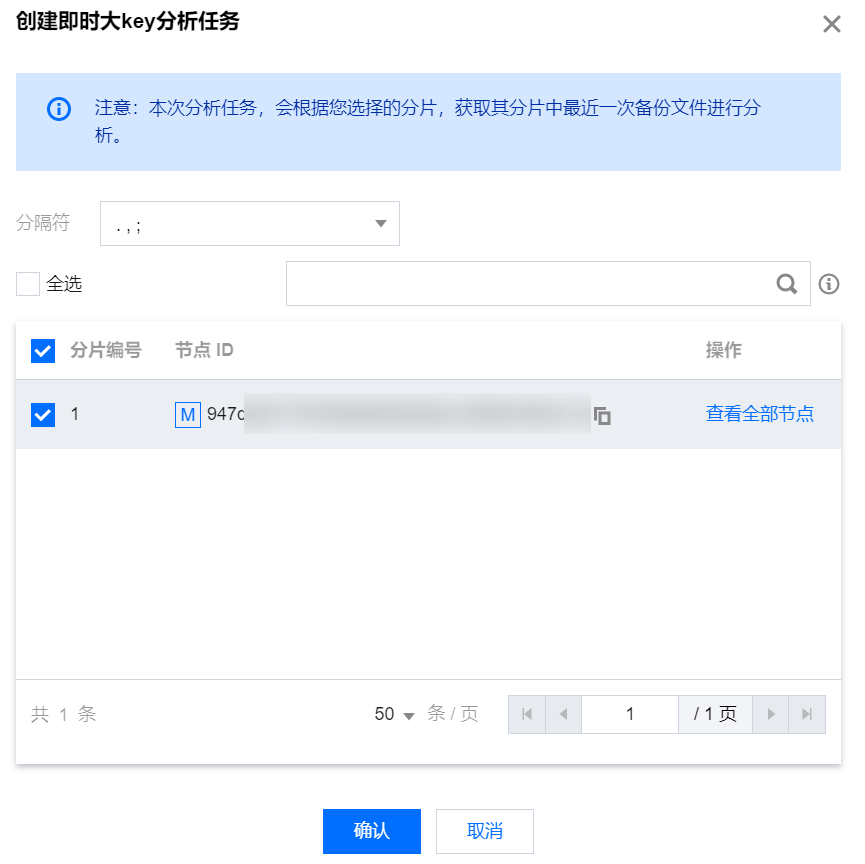
可在操作列单击查看全部节点,查看所有节点 ID。
DBbrain 会在您创建即时大 Key 分析任务后,立即自动生成一次备份,进行自动化分析。
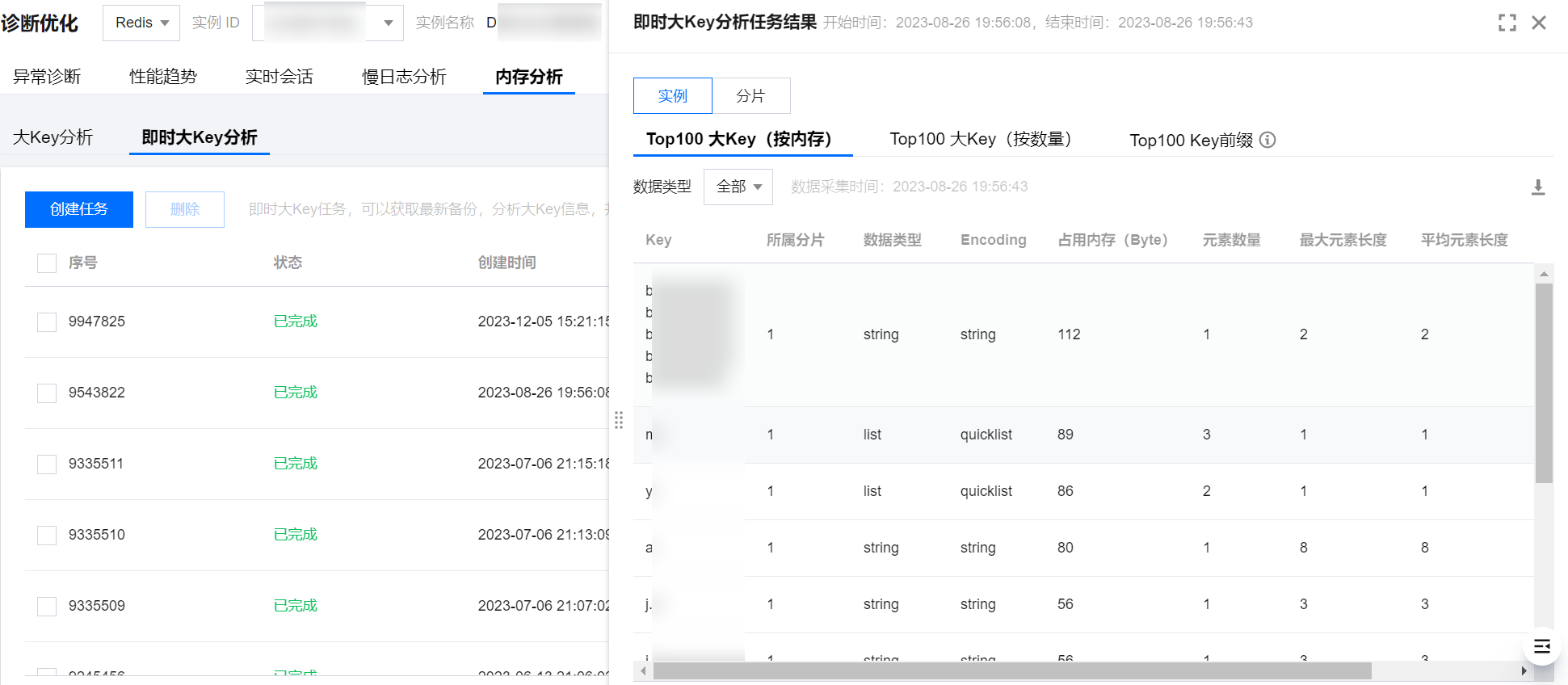
4. 在任务列表中,当任务进度为100%时,在操作列,单击查看,在右侧弹窗查看任务分析结果。
任务分析结果从 Top100 大 Key(按内存)、Top100 大 Key(按数量)、Top100 Key 前缀三个维度展示大 Key 分析结果,并支持从实例和分片两个维度查看大 Key 分析结果。
解决方法
若是 value 过大,您可以将对象拆分成多个 key-value,将操作压力平摊到多个 Redis 实例;若是 Key 过多,您可以参考 hash 结构存储,将多个 Key 存储在一个 hash 结构中。
排查读写负载过高
排查步骤
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化。
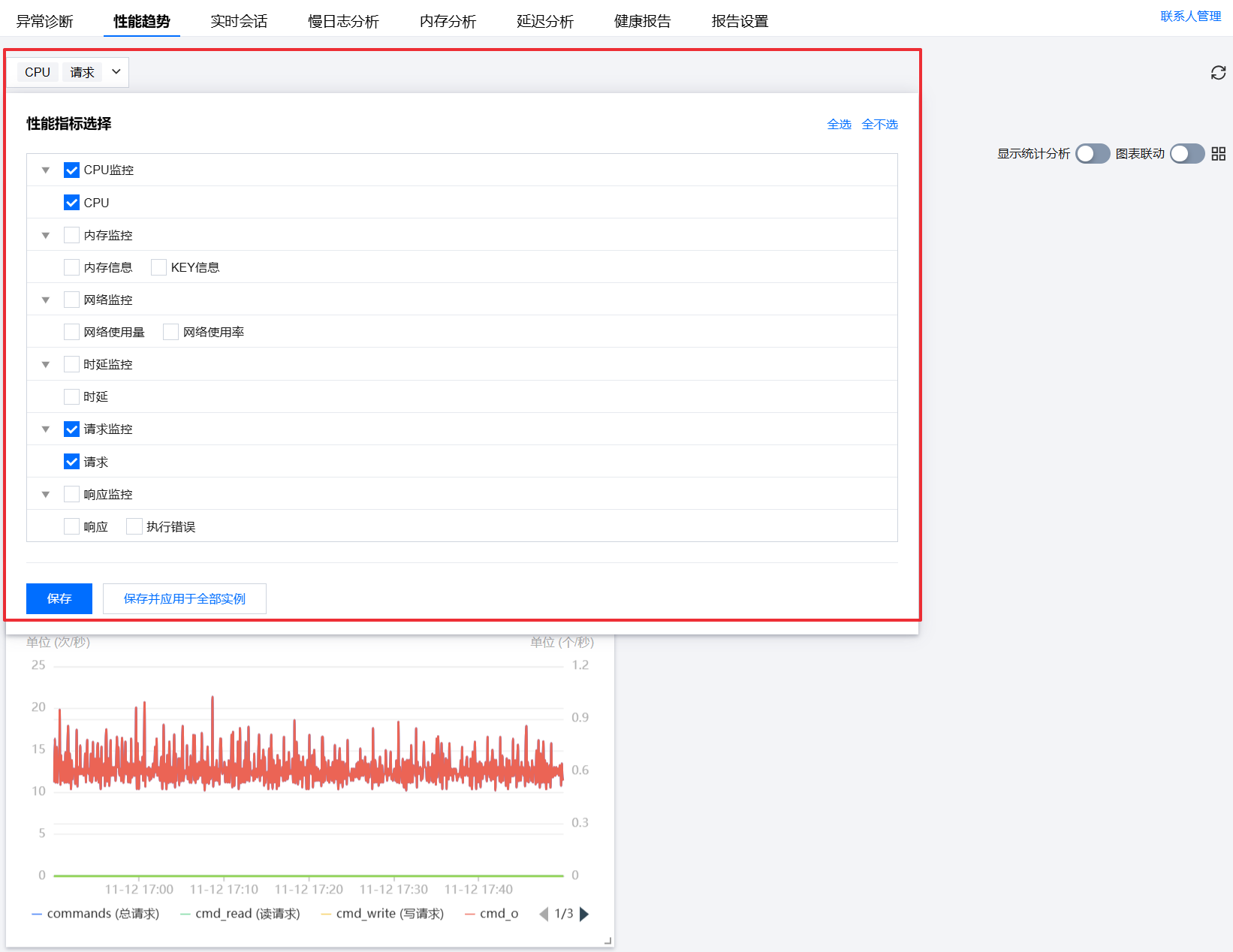
2. 在页面上方选择数据库类型 Redis 和实例 ID,选择性能趋势。
3. 选择待查看的实例、 Redis 节点或 Proxy 节点。

4. 单击性能指标下拉框,选择 CPU 监控和请求监控性能指标。
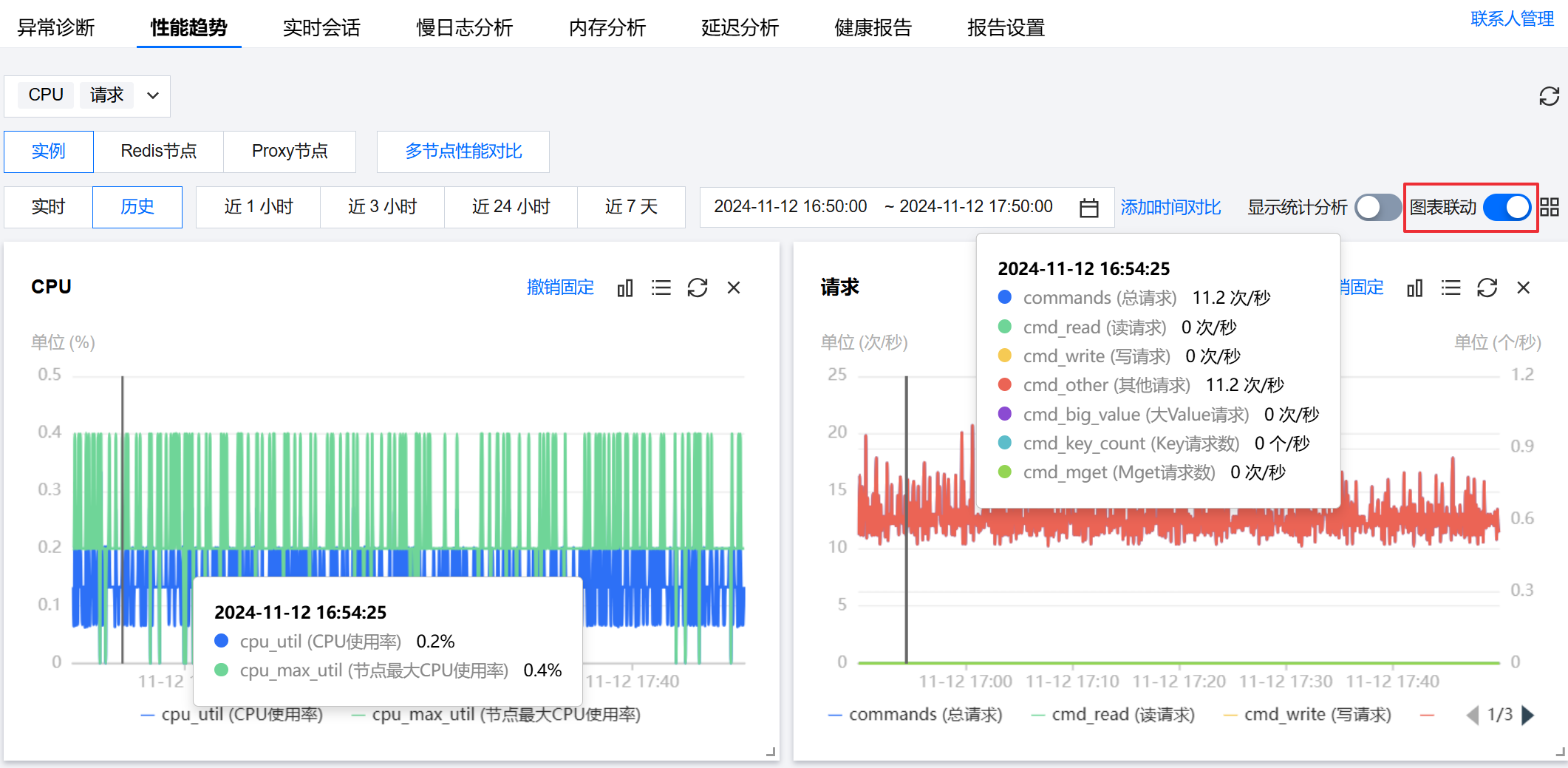
5. 在页面右上方开启图表联动,联动查看性能趋势图中,CPU 使用率高的时候是否读写请求同时高。
解决方法
写负载过高:通过 增加分片数量 的方式来分摊写负载。若实例为标准架构,请优先升级标准架构为集群架构,提升 CPU 处理能力。具体操作,请参见 升级实例架构。升级集群架构之前需要检测兼容性,请参见 标准架构迁移集群架构检查。
排查频繁执行的 select 命令
排查步骤
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化。
2. 在页面上方选择数据库类型 Redis 和实例 ID,选择延迟分析 > 命令字分析。

3. 在命令字分析页,选择实时或历史数据。
4. 选择 select 命令类型,单击确定。
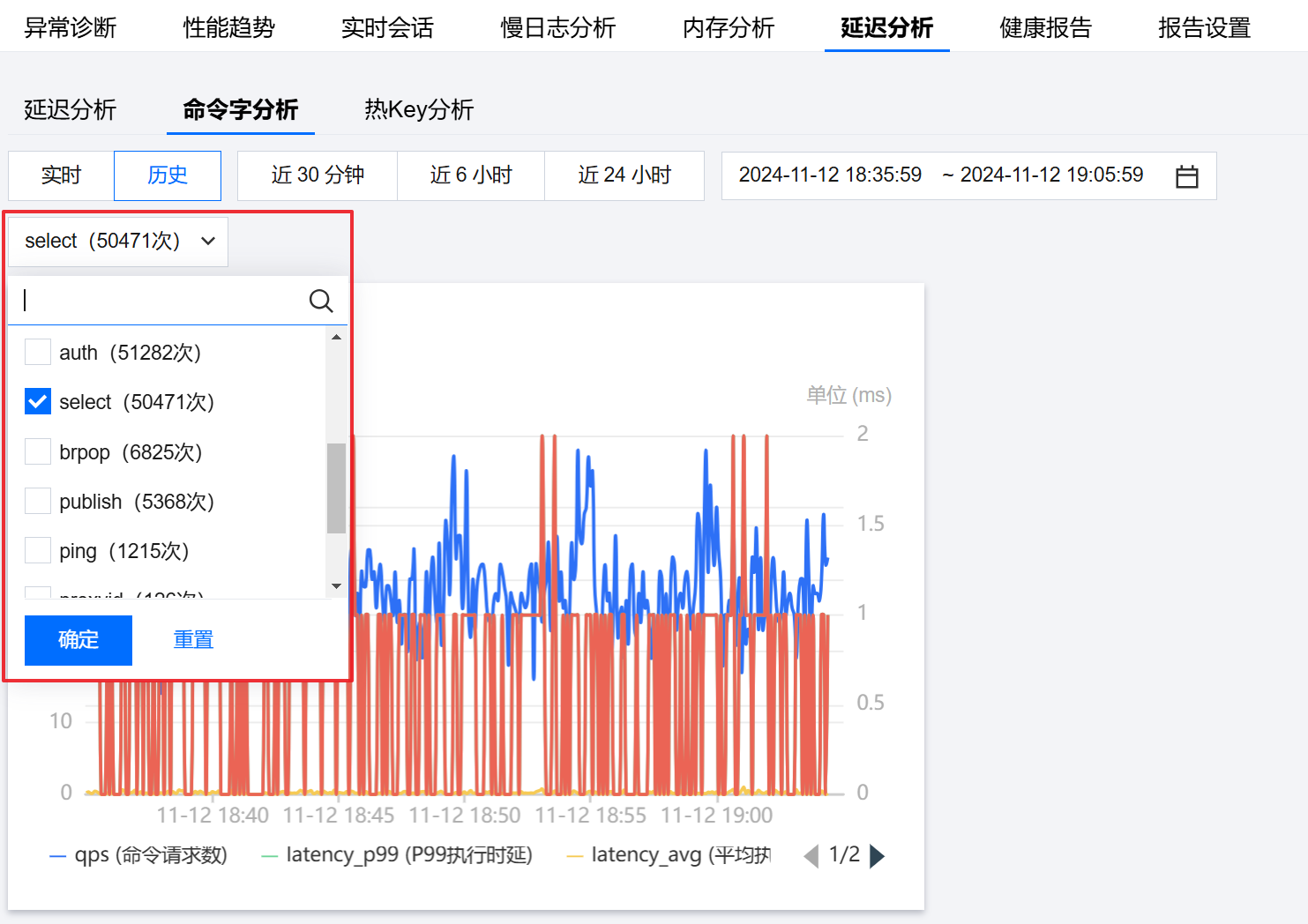
5. 查看是否存在 select 请求比较多的现象。
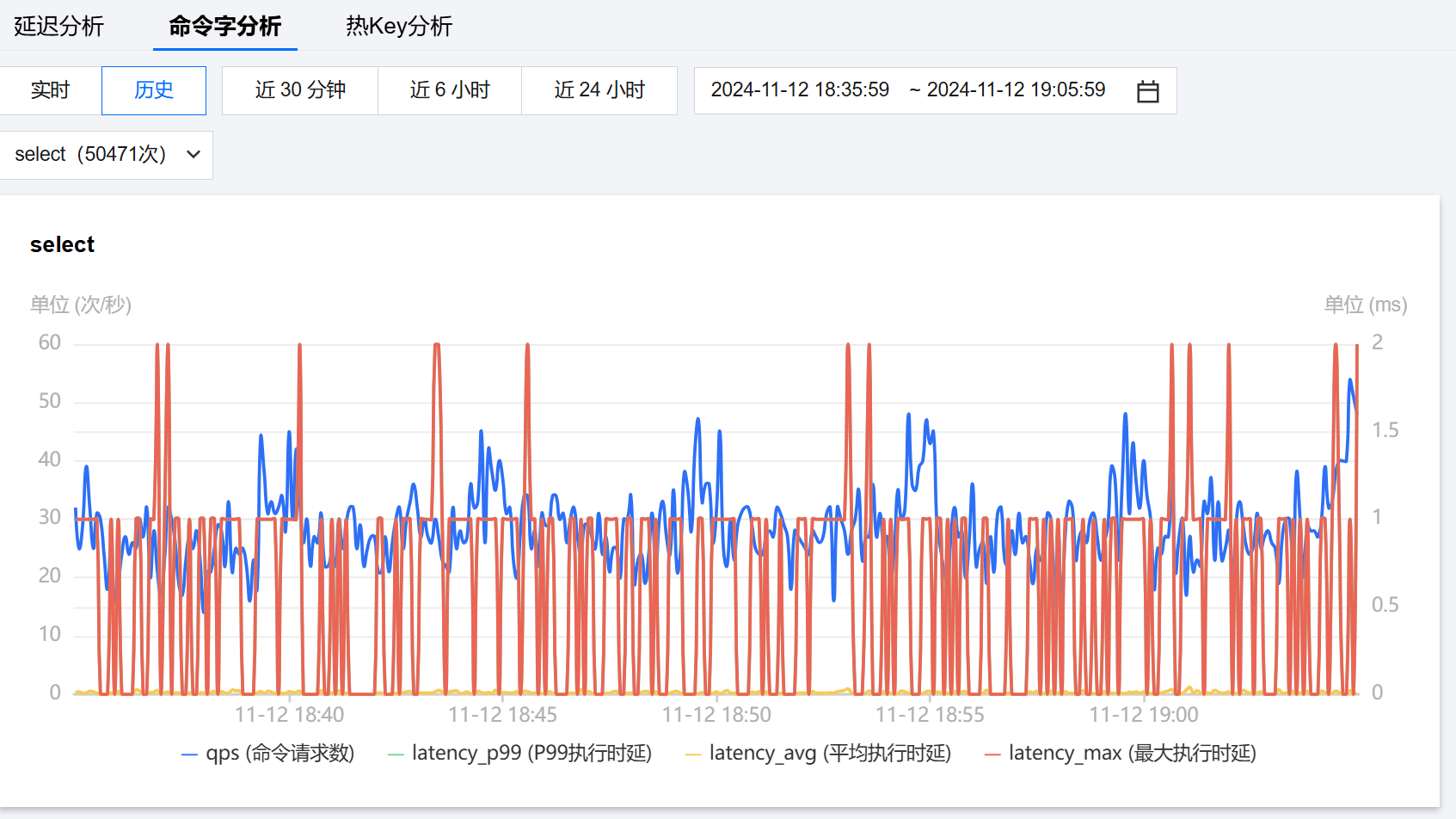
解决方法
若存储不同业务,针对频繁切换 DB 的业务,建议分开存储。
若存储相同业务,评估 Key 名不冲突的前提下,考虑将数据存储在相同的 DB,减少 select 请求操作次数。



