本文介绍超级节点特有的 Annotation 与示例,该 Annotation 针对 TKE 标准集群和 TKE Serverless 集群内超级节点上运行的 Pod 生效。
Annotation 使用方法
控制台操作步骤如下:
1. 登录 容器服务控制台,选择左侧导航栏中的集群。
2. 在集群列表页中,单击集群 ID,进入该集群详情页。
3. 选择左侧导航中的工作负载,在右侧操作 > 更多中选择编辑 Annotation/编辑 yaml。如下图所示:
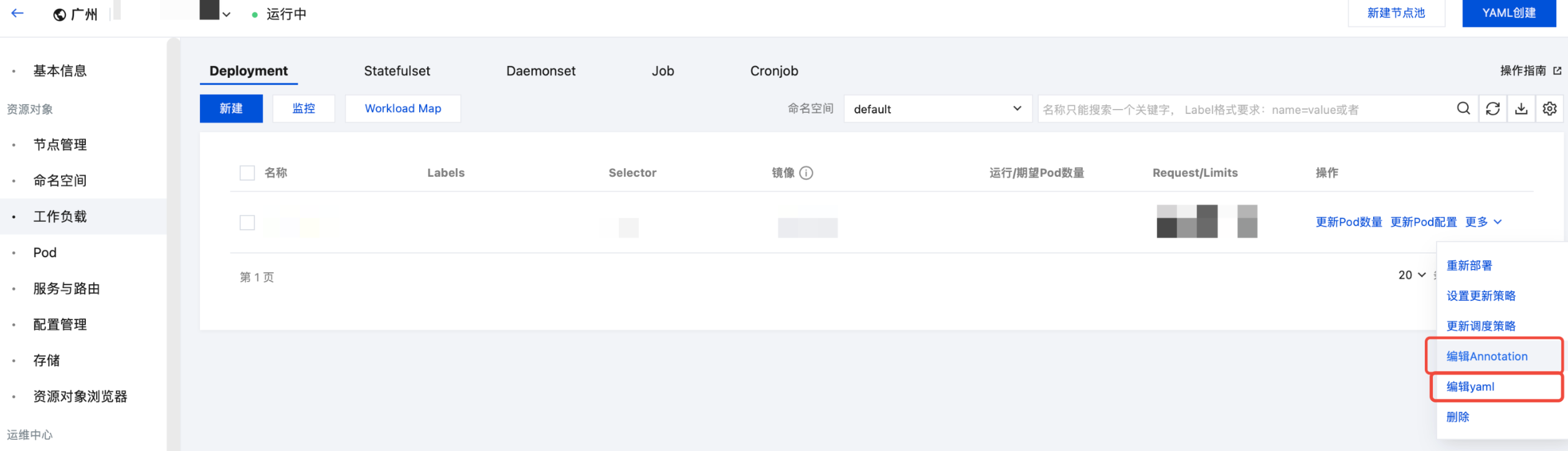
工作负载里添加 Pod 注解
本文所说明的注解均为在 Pod 级别添加注解,通常用户使用的是工作负载而不是裸 Pod。本文以在 Deployment 上添加 Pod 注解为例,需注意,工作负载里添加 Pod 注解是在
.spec.template.metadata.annotations 字段。apiVersion: apps/v1kind: Deploymentmetadata:name: nginxspec:replicas: 1selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxannotations:eks.tke.cloud.tencent.com/retain-ip: 'true' # 工作负载里添加 Pod 注解是在 .spec.template.metadata.annotations 字段spec:containers:- name: nginximage: nginx
全局配置
如果用户希望注解默认对集群里所有 Pod 生效,可以通过修改全局配置实现。需注意,全局配置在 kube-system 命名空间下名为 eks-config 的 configmap,如没有该资源则需要自行新建。
apiVersion: v1kind: ConfigMapmetadata:name: eks-confignamespace: kube-systemdata:pod.annotations: |eks.tke.cloud.tencent.com/resolv-conf: |nameserver 183.60.83.19eks.tke.cloud.tencent.com/host-sysctls: '[{"name": "net.core.rmem_max","value": "26214400"}]'
说明:
添加在 Pod 上的注解优先级高于全局配置。
资源与规格
指定 CPU 与内存
超级节点上运行的 Pod 默认会根据 request 与 limit 自动计算出底层资源的规格,用户可以参考官方文档 指定资源规格,也可以通过给 Pod 添加注解去指定 Pod 需要的计算资源规格。示例如下:
eks.tke.cloud.tencent.com/cpu: '8'eks.tke.cloud.tencent.com/mem: '16Gi' # 内存一定要以 Gi 为单位,以 G 为单位则会报参数错误
指定系统盘大小及类型
超级节点上运行的 Pod 默认免费提供 20GiB 高性能系统盘(不额外申明 Annotation 时的默认配置),系统盘生命周期与 Pod 的生命周期一致,可满足通用场景的系统盘资源诉求,若特殊场景下用户需要额外扩容系统盘大小或额外指定磁盘类型,支持通过 Annotation 来声明所需系统盘的大小及类型。注意,此时超过 20GiB 的部分将按照指定磁盘类型的按量计费的刊例价进行计费,计费详情请参见 云硬盘定价说明。系统盘大小及类型注解示例如下,可单独使用:
eks.tke.cloud.tencent.com/root-cbs-size: '50' # 指定系统盘大小,超过20GiB额外按高性能云盘计费,最大1000GiBeks.tke.cloud.tencent.com/root-cbs-type: 'CLOUD_SSD' # 指定系统盘类型为SSD,不额外指定时默认为高性能磁盘,超过20GiB额外按照SSD磁盘按量计费的刊例价进行计费。
规格自动升配
超级节点上运行的 Pod 会按照 request 与 limit 自动计算出匹配的底层资源规格。如果对应的规格底层无相应资源,则会创建失败并在事件中提示资源不足 (insufficient resource)。如果用户接受使用更高规格的资源来创建 Pod,则可在 Pod 添加如下注解,开启自动升配,计费将按照升配后的规格计算。
eks.tke.cloud.tencent.com/spec-auto-upgrade: 'true' # 遇到资源不足时,开启自动升配,只按 CPU 规格向上升配一次
指定 GPU
如需指定 GPU,可在 Pod 上添加如下注解:
eks.tke.cloud.tencent.com/gpu-type: 'T4,V100' # 指定 GPU 型号,支持优先级顺序写法,若使用1/4卡的 T4 vGPU 则指定 GPU 型号为1/4*T4。
说明:
TKE Serverless 支持通过 Annotation 指定和通过 Request 及 Limit 计算两种声明方式指定资源规格。
如通过 Request 及 Limit 计算,声明 gpu-type 后我们将为您自动计算出合适的规格。
eks.tke.cloud.tencent.com/gpu-type: 'V100'eks.tke.cloud.tencent.com/gpu-count: '1'eks.tke.cloud.tencent.com/cpu: '8'eks.tke.cloud.tencent.com/mem: '40'
建议您直接声明 gpu-type,通过 Request 及 Limit 计算指定资源。
指定 CPU 类型
如需指定 CPU 类型,可在 Pod 上添加如下注解:
eks.tke.cloud.tencent.com/cpu-type: 'amd,intel' # 表示优先创建 amd 资源 Pod,如果所选地域可用区 amd 资源不足,则会创建 intel 资源 Pod
开启竞价模式
eks.tke.cloud.tencent.com/spot-pod: 'true'
IP 保留与 EIP
StatefulSet 固定 IP
使用固定 IP 的前提是工作负载为 StatefulSet,或者直接使用裸 Pod(需注意 Pod 名称不能改变),用户可在 Pod 级别添加注解启用固定 IP:
eks.tke.cloud.tencent.com/retain-ip: 'true' # 置为 true 启用固定 IP。eks.tke.cloud.tencent.com/retain-ip-hours: '48' # 保留 IP 的最大时长(小时),Pod 销毁之后超过这个时长没有创建回来,IP 将被释放。
说明:
TKE 集群超级节点场景下的固定 IP,用法保持跟 TKE 一致,无需添加上述注解。
固定 IP 的 Pod 迁移可用区执行步骤
前置说明
适用于使用 TKE/TKE Serverless 固定 IP(ENI)机制的 Pod。
操作过程中 Pod 会被删除并重建,请确认业务可中断。
如 Pod 使用 PVC,请确认是否允许数据被删除。
操作步骤
1. 配置如下两个 annotation:
eks.tke.cloud.tencent.com/delete-pvc-on-pod-delete: "true" #删除Pod时,删除对应的PVCeks.tke.cloud.tencent.com/delete-ip-on-pod-delete: "true" #删除Pod时,释放对应的固定IP,解除kubesystem的configmap的子网和podname的绑定关系
注意:
删除 Pod 时将同时释放固定 IP,并清理子网绑定关系。
delete-pvc-on-pod-delete 会在 Pod 删除时同时删除 PVC 和数据,请确认业务允许数据被销毁,如不希望删除数据,请勿开启 delete-pvc-on-pod-delete。
2. 销毁重建Pod,释放固定 IP
此步骤会解除 Pod 与原可用区子网的绑定关系。
注意:
此操作可能会导致服务中断,请确认业务可中断。
3. (可选)指定目标可用区子网
如需将 Pod 调度到指定可用区,可通过以下方式之一指定子网:
修改固定 IP 控制器使用的子网配置。
或通过标签 / 调度策略指定目标可用区节点。
直接手动修改 kube-system 下的系统 ConfigMap。
4. 重新创建 Pod
Pod 将根据新的子网配置,被调度到目标可用区。
绑定 EIP
如需绑定 EIP,可在 Pod 上添加如下注解:
eks.tke.cloud.tencent.com/eip-attributes: '{"InternetMaxBandwidthOut":50, "InternetChargeType":"TRAFFIC_POSTPAID_BY_HOUR"}' # 值可以为空串,表示启用 EIP 并使用默认配置;也可以用创建 EIP 接口的 json 参数,详细参数列表参考 https://cloud.tencent.com/document/api/215/16699#2.-.E8.BE.93.E5.85.A5.E5.8F.82.E6.95.B0,本例中的参数表示 EIP 是按量付费,且带宽上限为 50M。
注意:
StatefulSet 固定 EIP
如需在 StatefulSet 固定 EIP,可在 Pod 级别添加如下注解:
eks.tke.cloud.tencent.com/eip-attributes: '{}' # 启用 EIP 并使用默认配置。eks.tke.cloud.tencent.com/eip-claim-delete-policy: 'Never' # Pod 删除后,EIP 是否自动回收,默认回收。使用 "Never" 不回收,即下次同名 Pod 创建出来仍然会绑定此 EIP,实现固定 EIP。
注意:
Deployment 类型的工作负载使用
Never 不回收策略时,Pod 删除后 EIP 不会回收,滚动更新后的 Pod 也不会使用原本的 EIP。StatefulSet 使用已有 EIP
如需将已有的 EIP 绑定到 Pod 而不是自动创建,可以给 Pod 指定要绑定的 EIP 实例 ID。注解如下:
eks.tke.cloud.tencent.com/eip-id-list: 'eip-xx1,eip-xx2' # 这里指定已有的 EIP 实例列表,确保 StatefulSet 的 Pod 副本数小于等于这里的 EIP 实例数。
注意:
指定 EIP 场景下,请勿配置 eip-attributes 注解。
镜像与仓库
忽略证书校验
如果自建镜像仓库的证书是自签的,拉取镜像会失败 (ErrImagePull),可以给 Pod 添加以下注解指定拉取此镜像仓库的镜像时不校验证书:
eks.tke.cloud.tencent.com/registry-insecure-skip-verify: 'harbor.example.com' # 也可以写多个,逗号隔开
使用 HTTP 协议
如果自建镜像仓库使用的 HTTP 而不是 HTTPS,拉取镜像会失败 (ErrImagePull),可以给 Pod 添加以下注解指定拉取此镜像仓库的镜像时使用 HTTP 协议:
eks.tke.cloud.tencent.com/registry-http-endpoint: 'harbor.example.com' # 也可以写多个,逗号隔开
镜像复用
超级节点上默认会复用系统盘以加快启动速度,复用的是同一工作负载下相同可用区 Pod 且在缓存时间内(销毁后2小时内)的系统盘。如需复用不同工作负载的 Pod 的镜像,可以在不同工作负载的 Pod 上打上相同的
cbs-reuse-key 的注解:eks.tke.cloud.tencent.com/cbs-reuse-key: 'image-name'
镜像缓存
超级节点上提供 镜像缓存能力,即提前创建好镜像缓存实例,自动将需要的镜像下载下来并创建云盘快照,后续创建 Pod 开启镜像缓存,这样就会根据镜像名自动匹配镜像缓存实例的快照,直接使用快照里面的镜像内容,避免重复下载,加快 Pod 启动速度。
启用镜像缓存的注解:
eks.tke.cloud.tencent.com/use-image-cache: 'auto'
指定镜像缓存创建出来的盘类型:
eks.tke.cloud.tencent.com/image-cache-disk-type: 'CLOUD_SSD' # 指定镜像缓存创建出来的盘类型,可取值如下:CLOUD_BASIC为普通云硬盘,CLOUD_PREMIUM为高性能云硬盘(默认),CLOUD_SSD为SSD云硬盘,CLOUD_HSSD为增强型SSD云硬盘,CLOUD_TSSD为极速型SSD云硬盘
指定镜像缓存创建出来的盘的大小:
eks.tke.cloud.tencent.com/image-cache-disk-size: '50' # 指定镜像缓存创建出来的盘的大小,默认是镜像缓存创建时设置的大小,可以调大,不能调小,最大支持1000GiB
用户也可以手动指定镜像缓存实例,不使用自动匹配:
eks.tke.cloud.tencent.com/use-image-cache: 'imc-xxx'
镜像缓存创建出来的数据盘,在 Pod 删除后会立即销毁。如果需额外保留镜像缓存创建的数据盘,可以通过注解指定保留时间。开启数据盘保留后,再次创建 Pod 的时候会直接复用保留中的盘,可节省数据再重新从快照回滚至新云硬盘的时间:
eks.tke.cloud.tencent.com/image-cache-disk-retain-minute: '10' # 设定镜像缓存创建的数据盘,在销毁 Pod 后保留 10 分钟
绑定安全组
超级节点默认会为 Pod 绑定同地域默认项目下的
default 安全组,也可以通过给 Pod 加注解绑定指定安全组:eks.tke.cloud.tencent.com/security-group-id: 'sg-id1,sg-id2' # 填本地域存在的安全组 id,多个用逗号隔开,网络策略按安全组顺序生效,安全组默认最多只能绑定 2000 个 Pod,如需更多请提工单提升配额。
绑定角色
超级节点上默认会为 Pod 关联
TKE_QCSLinkedRoleInEKSLog 角色,授予 Pod 里日志采集组件上报日志的权限。用户也可通过注解为 Pod 关联其他 CAM 角色,方便从 Pod 内获取操作云上资源的权限。eks.tke.cloud.tencent.com/role-name: 'TKE_QCSLinkedRoleInEKSLog'
设置宿主机内核参数
有些内核参数以网络命名空间隔离,无法在容器内查看或设置,超级节点内 Pod 虽然是独占虚拟机,但不代表就能在容器内直接设置宿主机上的内核参数。
可以通过给 Pod 加注解来实现设置 Pod 宿主机内核参数:
eks.tke.cloud.tencent.com/host-sysctls: '[{"name": "net.core.rmem_max","value": "26214400"},{"name": "net.core.wmem_max","value": "26214400"},{"name": "net.core.rmem_default","value": "26214400"},{"name": "net.core.wmem_default","value": "26214400"}]'
加载内核模块
eks.tke.cloud.tencent.com/host-modprobe: 'toa'
自动重建自愈
超级节点所在集群虚拟机内的 agent 会上报心跳给控制面,如果上报超时(默认 5min),一般说明 Pod 内进程已经无法正常工作了,故障原因通常是高负载,这时集群默认会自动迁移虚拟机(对当前虚拟机关机并自动创建新虚拟机,让 Pod 迁移到新虚拟机里去运行),从而实现自愈。
如果用户不希望自动重建(如用于保留现场),可以在 Pod 上添加如下注解:
eks.tke.cloud.tencent.com/recreate-node-lost-pod: "false"
如果用户认为默认的 5min 上报超时时间过长,希望及时摘除异常 Pod 的流量,可以在 Pod 上添加如下注解来自定义心跳超时时间:
eks.tke.cloud.tencent.com/heartbeat-lost-period: 1m
磁盘清理
当超级节点内 Pod 磁盘空间紧张的时候,会自动触发清理流程以释放空间,通过
df -h 可以确认磁盘使用情况。常见磁盘空间不足的原因有:
业务有大量临时输出。您可以通过 du 命令确认。
业务持有已删除的文件描述符,导致磁盘空间未释放。您可以通过 lsof 命令确认。
清理容器镜像
默认情况下,磁盘空间达 80% 以上会自动清理容器镜像来释放空间,如果已经没有容器镜像可以释放,则会报告如下事件:
failed to garbage collect required amount of images. Wanted to free 7980402688 bytes, but freed 0 bytes
如需自定义清理的阈值,可以在 Pod 上添加如下注解:
eks.tke.cloud.tencent.com/image-gc-high-threshold: '80' # 表示磁盘使用空间达 80% 触发清理容器镜像eks.tke.cloud.tencent.com/image-gc-low-threshold: '75' # 触发清理容器镜像后,默认释放 5% (high-threshold - low-threshold) 的磁盘空间,便停止清理eks.tke.cloud.tencent.com/image-gc-period: '3m' # 磁盘空间检查的间隔,默认 3 分钟
清理已退出的容器
如果业务原地升级过,或者容器异常退出过,已退出的容器仍会保留,直到磁盘空间达到 85% 时才会清理已退出的容器。清理阈值可以使用如下 Annotation 调整:
eks.tke.cloud.tencent.com/container-gc-threshold: "85"
如果已退出的容器不想被自动清理(例如需要退出的信息进一步排障),可以通过如下 Annotation 关闭容器的自动清理,但副作用是磁盘空间无法自动释放:
eks.tke.cloud.tencent.com/must-keep-last-container: "true"
重启磁盘用量高的 Pod
业务需要在容器的系统盘用量超过某个百分比后直接重启 Pod,可以通过 Annotation 配置:
eks.tke.cloud.tencent.com/pod-eviction-threshold: "85" # 此功能只在设置后开启,默认不开启
只重启 Pod,不会重建子机,退出和启动都会进行正常的 gracestop、prestop、健康检查。
注意:
此特性上线时间为 2022-04-27,故在此时间前创建的 Pod,需要重建 Pod 来开启特性。
监控指标
9100 端口问题
超级节点上 的 pod 默认会通过 9100 端口对外暴露监控数据,用户可以执行以下命令访问 9100/metrics 获取数据:
获取全部指标:
curl -g "http://<pod-ip>:9100/metrics"
大集群建议去掉 ipvs 指标:
curl -g "http://<pod-ip>:9100/metrics?collect[]=ipvs"
如果业务本身直接监听了 9100 端口,将会有如下报错,提醒用户 9100 端口已经被使用:
listen() to 0.0.0.0:9100, backlog 511 failed (1: Operation not permitted)
您可以自定义暴露监控数据的端口号,避免与业务冲突。配置方式如下:
eks.tke.cloud.tencent.com/metrics-port: "9110"
说明:
如果 Pod 带有公网 EIP,则需要设置安全组,注意 9100 端口问题,并放通需要的端口。
监控数据上报频率
超级节点上暴露的 cAdvisor 监控数据,默认 30 秒刷新一次,可以通过如下注解调整刷新频率:
eks.tke.cloud.tencent.com/cri-stats-interval: '30s'
自定义监控指标路径
监控数据默认通过
/metrics 路径暴露监控数据,无需改动。如有自定义的需求,可以用下面的注解:eks.tke.cloud.tencent.com/custom-metrics-url: '/metrics'
设置 Pod 网卡名称
Pod 默认使用
eth0 网卡,如果需更改网卡名称,需要添加如下注解:internal.eks.tke.cloud.tencent.com/pod-eth-idx: '1' # 设置网卡名为 eth1
自定义 DNS
Pod 所在宿主机默认使用 VPC 内的 DNS:183.60.83.19,183.60.82.98。如果需要更改宿主机上的 DNS,可以配置如下 annotation:
eks.tke.cloud.tencent.com/resolv-conf: |nameserver 4.4.4.4nameserver 8.8.8.8
注意:
1. 配置了自定义 DNS 后,则宿主机上的 DNS 以配置的为准。
2. 只对新增 Pod 有效。如果在 configmap kube-system/coredns 中配置了 forward . /etc/resolv.conf,则需重建 coredns Pod 才能生效此注解指定的 DNS为上游(重建 coredns Pod 可能影响业务,建议低峰期操作)。
日志采集到 kafka
超级节点支持通过开源的日志采集组件将日志采集到 kafka。如果采集的是容器内文件,或者采集时进行了多行合并,则需合理配置单行大小。默认设置的单行大小是 2M,超过 2M 则会丢弃该行日志。日志的单行大小可通过如下注解调整:
internal.eks.tke.cloud.tencent.com/tail-buffer-max-size: '2M' # 默认支持最大 2M 的单行日志
采集到 kafka 时,日志内容的字段为
log,如需将字段名配置为 message,则可通过如下注解调整:eks.tke.cloud.tencent.com/log-key-as-message: 'true'
日志上报时会额外携带 Pod 的 metadata 信息,信息以
string 的格式放在 kubernetes 字段,如果需要将 kubernetes 字段设置成 json 格式,需配置如下注解:eks.tke.cloud.tencent.com/filebeat-metadata-format: 'true'
延迟销毁
超级节点上运行的 Job 任务结束后,底层资源就会被销毁;相应的,运行时产生的临时输出,也会被销毁,此时执行
kubectl logs <pod> 会提示 can not found connection to pod。如果需要保留底层资源定位问题,可以设置延迟销毁底层资源:eks.tke.cloud.tencent.com/reserve-sandbox-duration: '1m' # 开启延迟 1 分钟销毁的功能,Failed 状态的 Pod 最后一个容器退出后,额外保留底层资源 1 分钟eks.tke.cloud.tencent.com/reserve-succeeded-sandbox: 'false' # 延迟销毁默认只对 Failed 状态的 Pod 生效,变更此字段可将延迟销毁也应用于 Succeeded 状态的 Podeks.tke.cloud.tencent.com/reserve-task-shorter-than: '5s' # 如果只关心运行时间较短的 Job,可以配置此参数,只有 Pod 内有任何一个容器的运行时间低于指定值,才会触发延迟销毁。默认不开启。
注意:
开启延迟销毁后,会将子机销毁的时间作为 pod 的结束时间对 pod 进行计费。
Service 规则同步
关闭 Service 规则同步
超级节点所在集群通过 IPVS 生成 K8s service 规则。 如果无需生成 service 规则,可通过如下注解关闭:
eks.tke.cloud.tencent.com/cluster-ip-switch: 'disable'
注意:
关闭 service 规则后,则集群内的服务发现都会失效。Pod 将无法使用
ClusterFirst 的 dnsPolicy,需改成其他类型,例如 Default。等待 Service 规则同步
集群在 Pod 启动的同时同步 service 规则,如果需要在 Pod 启动前先等待 service 规则同步完成,则可以配置:
eks.tke.cloud.tencent.com/duration-to-wait-service-rules: '30s' # 启动 Pod 前先等待 service 规则同步完成,此处设置最多等待的时间为 30s
设置 IPVS 参数
IPVS 规则可通过如下注解控制:
eks.tke.cloud.tencent.com/ipvs-scheduler: 'sh' # 调度算法,sh 是 source hash,按源地址 hash 进行转发,更利于分布式全局的负载均衡。默认为 rr (轮询 round robin)eks.tke.cloud.tencent.com/ipvs-sh-port: "true" # 按端口进行 source hash,仅在 ipvs-scheduler 为 sh 有效。eks.tke.cloud.tencent.com/ipvs-sync-period: '30s' # 规则刷新的最大间隔,默认 30s 刷新一次。eks.tke.cloud.tencent.com/ipvs-min-sync-period: '2s' # 规则刷新的最小间隔,默认 service 一有变更就刷新。调整此参数可避免刷新过于频繁。
设置集群内访问 CLB 的 VIP 时流量不走 IPVS:
适用于希望集群内访问不走 IPVS 而走 CLB 的场景,通过给 Service 配置该 annotation 后,不会再生成对应的 IPVS 规则,此操作会影响存量的长连接:
service.cloud.tencent.com/discard-loadbalancer-ip: 'true' # 该 annotation 配置在 Service 上,无需重建 Pod 即可即时生效,但会影响存量的长连接
注意:
该 annotation 对已有 Service 动态配置时,会导致存量使用了对应 CLB VIP 的长连接出现网络不通直至超时。短连接则不受影响。该配置与 Kubernetes 社区的 service.kubernetes.io/service-proxy-name Label 有同样的风险。建议在 Service 创建时就配置该 annotation。如果必须对已有 Service 配置,请确保业务客户端使用了短连接。若客户端使用了长连接,则需具备自动重连机制,并在业务低峰期操作。
自定义 Pod 底层的子机时区
超级节点上的 Pod 所在的子机默认为 UTC 时间,若需要调整子机时区为东8区,可添加如下 Annotation:
eks.tke.cloud.tencent.com/host-timezone: 'Asia/Shanghai' # 该 annotation 用于设置 Pod 时区为东8区
超级节点 Pod 支持云标签
超级节点上的 Pod 会默认继承集群、超级节点池、超级节点的云标签,也支持通过 Annotation 为 Pod 额外打上云标签,方便用户以更细的粒度对资源进行分账管理,对应 Annotation 如下:
eks.tke.cloud.tencent.com/resource-tag: '{"key0":"val0","key1":"val1"}' # 该 annotation 用于设置 Pod 云标签为 key0=val0,key1=val1
注意:
若集群维度、超级节点维度和 Pod 维度均有标签,则 Pod 维度会对所有标签进行合并,当出现相同 key 值不同 value 值时,Pod 维度云标签的生效顺序为 Pod > 超级节点 > 集群, 即当集群维度、超级节点维度和 Pod 维度的标签键值冲突的时候,以 Pod 维度的 value 值为准。
超级节点 Pod 支持获取 eks-id
超级节点中的 Pod 以 eks-id 作为资源的唯一 id,eks-id 应用于按量计费的 Pod 账单中,若用户需要使用 Pod 信息与账单中的 eks-id 进行对账,可通过如下 annotation 将 eks-id 写入 Pod 的 yaml 后进行获取。
eks.tke.cloud.tencent.com/eks-id: "true" # 该 annotation 用于设置 pod yaml 中是否展示 eks-id



