智能拆条功能整合了大模型视频理解、语音识别、文字提取以及人物物体识别等技术,能够对长视频进行精准拆条和打点标记。系统可输出拆解后的视频片段,包括每个片段的封面图、起止时间、标题和内容摘要等信息。例如,将完整的新闻联播素材拆分为多个独立新闻事件视频,可显著提升新闻和体育类视频的拆条质量,有效促进二次创作,同时大幅降低人力和硬件成本。

拆条场景及计费说明
处理类型 | 智能拆条版本分类 | 描述 | 支持视频场景 | 计费说明 |
支持处理离线文件、直播流 | 智能拆条-高级版 | 基于语音、文本内容理解进行拆条,可自定义 Prompt 调整理解方向和拆条要求。 | 教育网课视频等,支持传入 Prompt 自定义场景。 镜头拆条:画面镜头或场景有明显变化时进行拆条。 目标拆条:指定物体、人物等目标,识别视频中该目标出现的关键帧。 | 收取“视频拆条-高级版”费用。 |
| 智能拆条-基础版 | 专用模型,仅支持部分视频场景。 | 新闻拆条:新闻长视频,识别其中每条新闻资讯的时间点。 | 收取“视频拆条”费用。 |
拆条场景及扩展参数示例
发起智能拆条任务,需要传入以下核心参数:
模板 ID(
AiAnalysisTask.Definition):使用 27 号预设智能拆条模板。扩展参数(
ExtendedParameter):JSON 字符串,用于指定拆条版本、调整拆条参数,从而更适配视频场景。以下分拆条版本、视频场景,提供了扩展参数示例:
智能拆条-高级版
智能拆条-高级版:通过识别视频语音、画面文字内容后提取出文本,基于大模型对视频进行拆条。支持镜头拆条、目标拆条、教育网课、自定义视频场景。
场景描述
自定义 Prompt 调整理解方向和拆条要求,适用于教育网课等视频场景。
扩展参数示例
{"des": {"split": {"method": "llm","model": "deepseek-v3","max_split_time_sec": 100,"extend_prompt": "本视频为经济金融相关网课教学场景视频,按照讲解知识点对视频进行分段"},"need_ocr": true,"text_requirement": "摘要在40字以内","dstlang": "zh"},"strip": {"type": "content"}}
输出内容
拆出的视频片段、每个片段的封面图、起止时间、标题、摘要等。
效果示例
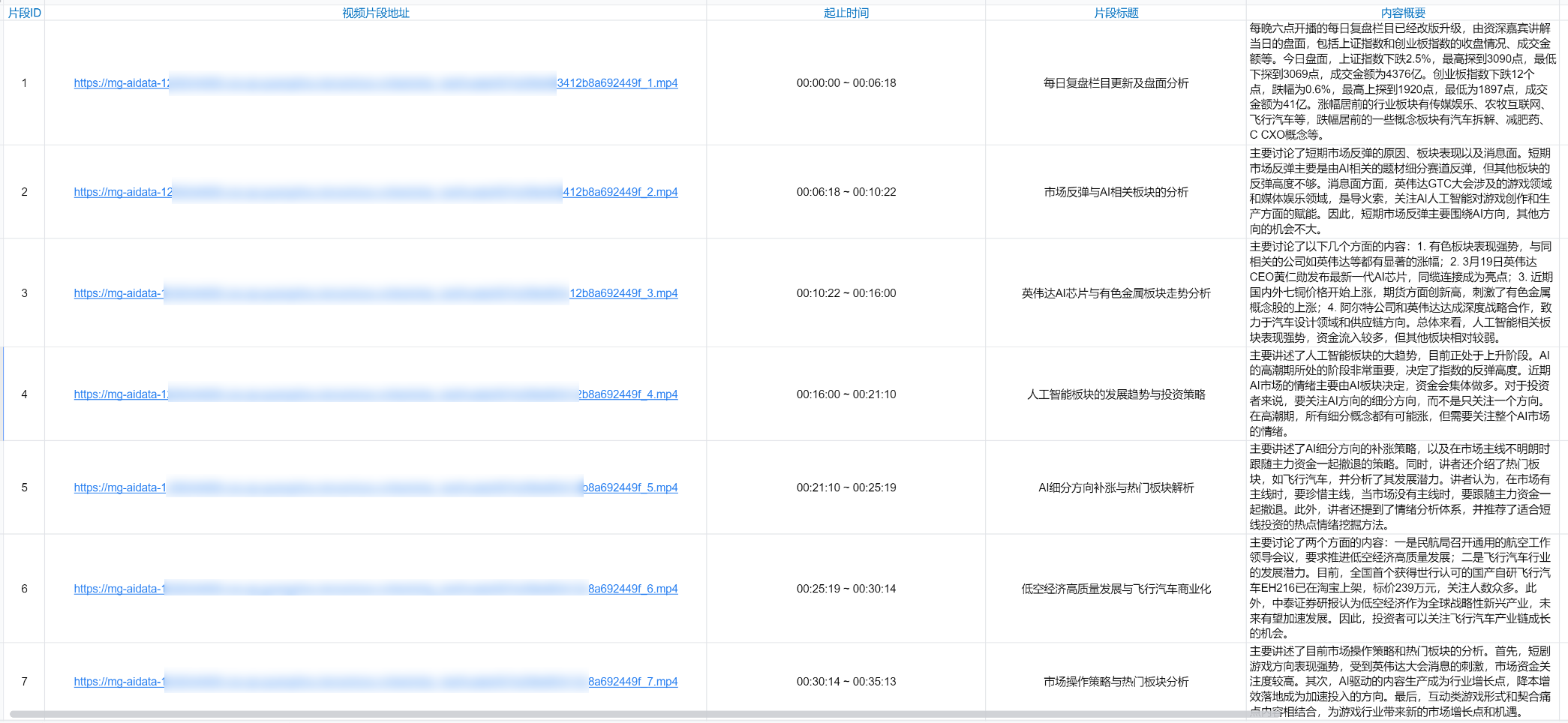
场景描述
根据画面镜头/场景的变化进行拆条。
扩展参数示例
{"strip":{"type":"screen_strip"}}
输出内容
拆出的视频片段、每个片段的封面图、起止时间。
效果示例
场景描述
支持指定物体、人物等目标,识别视频中该目标出现的关键帧,将相应片段拆出来。例如,针对监控视频,只拆分出有人出现的画面片段。
扩展参数示例
{"strip":{"type":"object","objects":["人"], "object_set":[91020415]}}
输出内容
拆出的视频片段、每个片段的封面图、起止时间。
效果示例

智能拆条-基础版
智能拆条-基础版:专用模型,仅支持部分视频场景。
场景描述
对新闻视频中的导播台,以及“快讯”等特征进行定位识别, 从而达到新闻拆条的效果。
扩展参数示例
{"strip":{"type":"news"}}
输出内容
拆出的视频片段、每个片段的封面图、起止时间。
效果示例
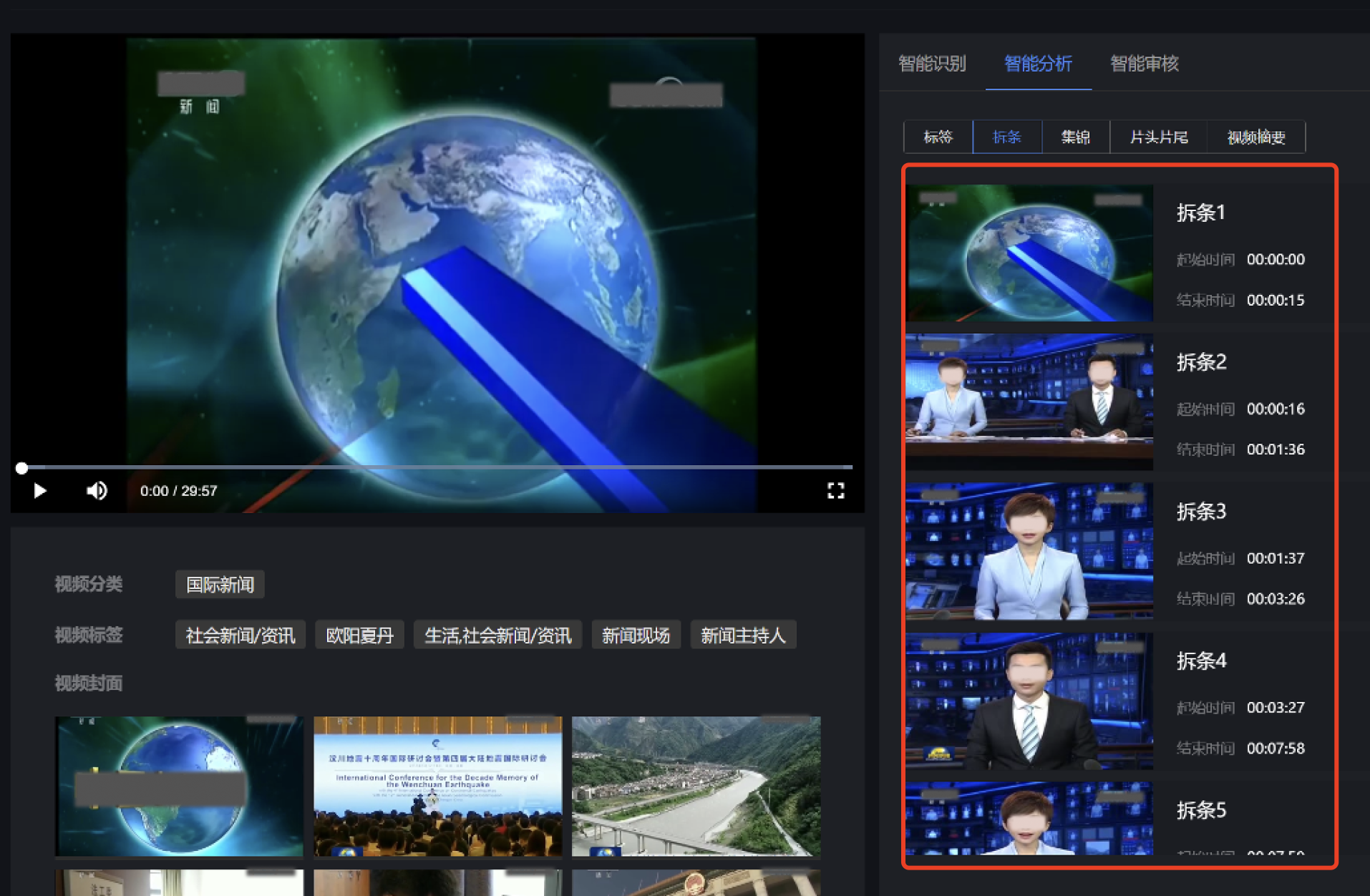
处理离线视频
发起任务方式1:控制台发起
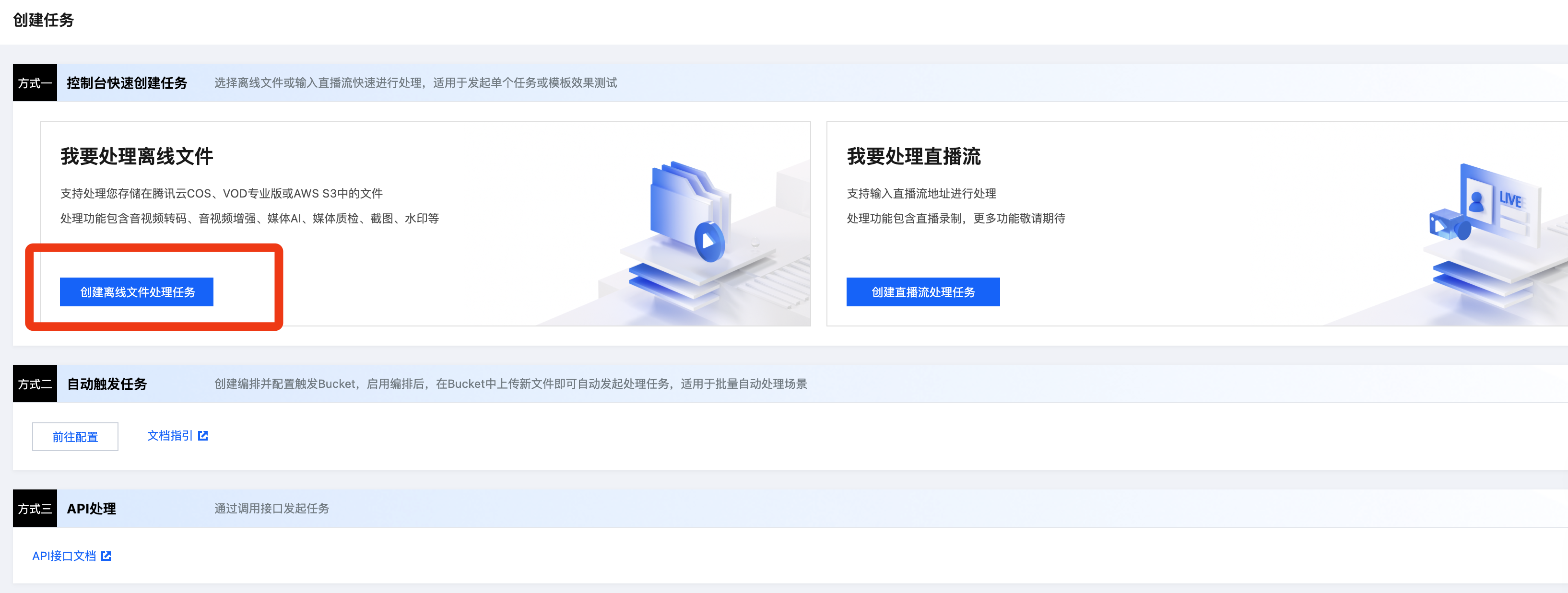
1. 进入 媒体处理控制台,依次点击创建任务 > 创建离线文件处理任务。
2. 依次选择输入文件路径、配置编排处理流程、输出路径。在编排配置中,选择媒体 AI - 智能分析节点。
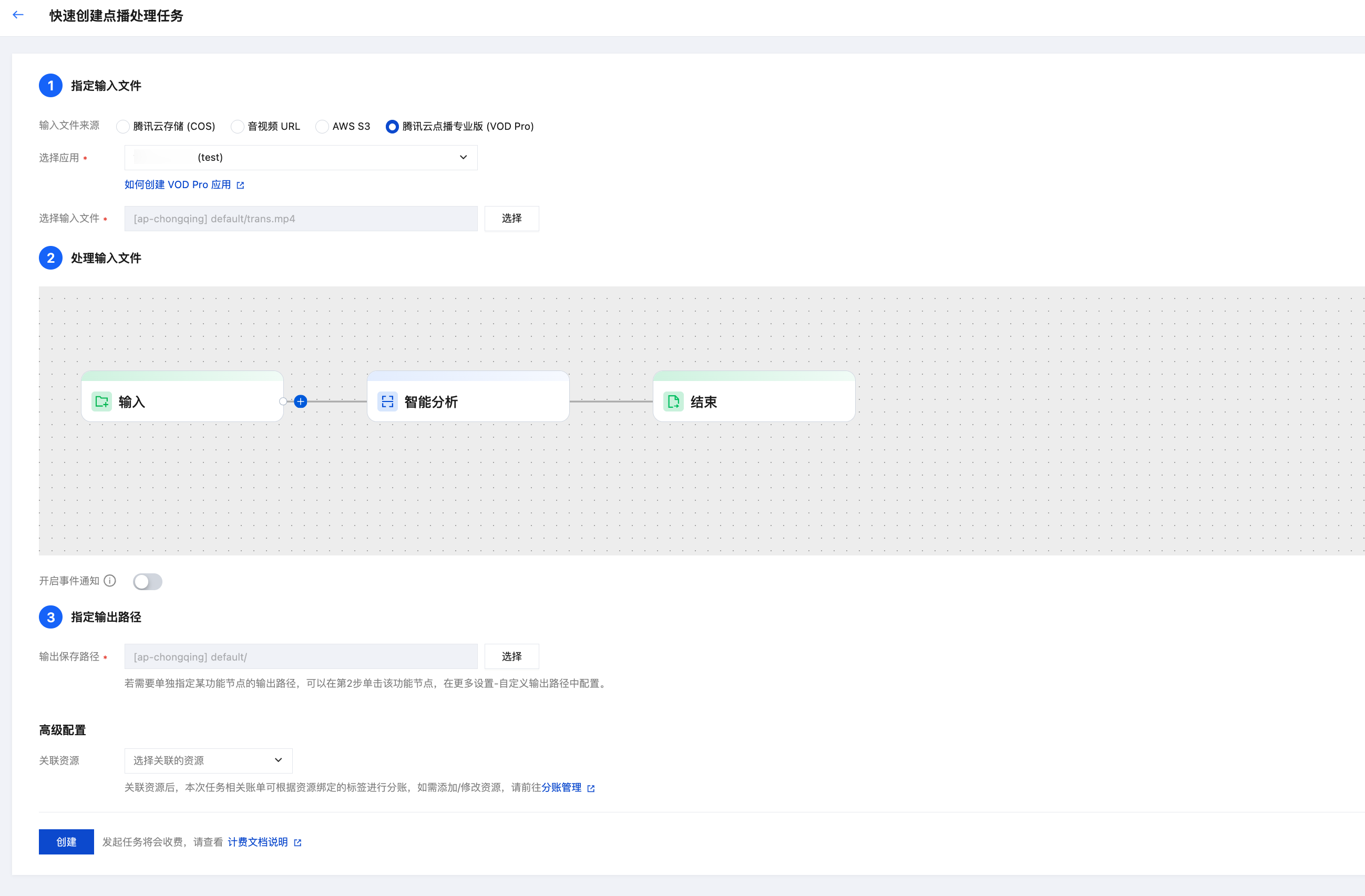
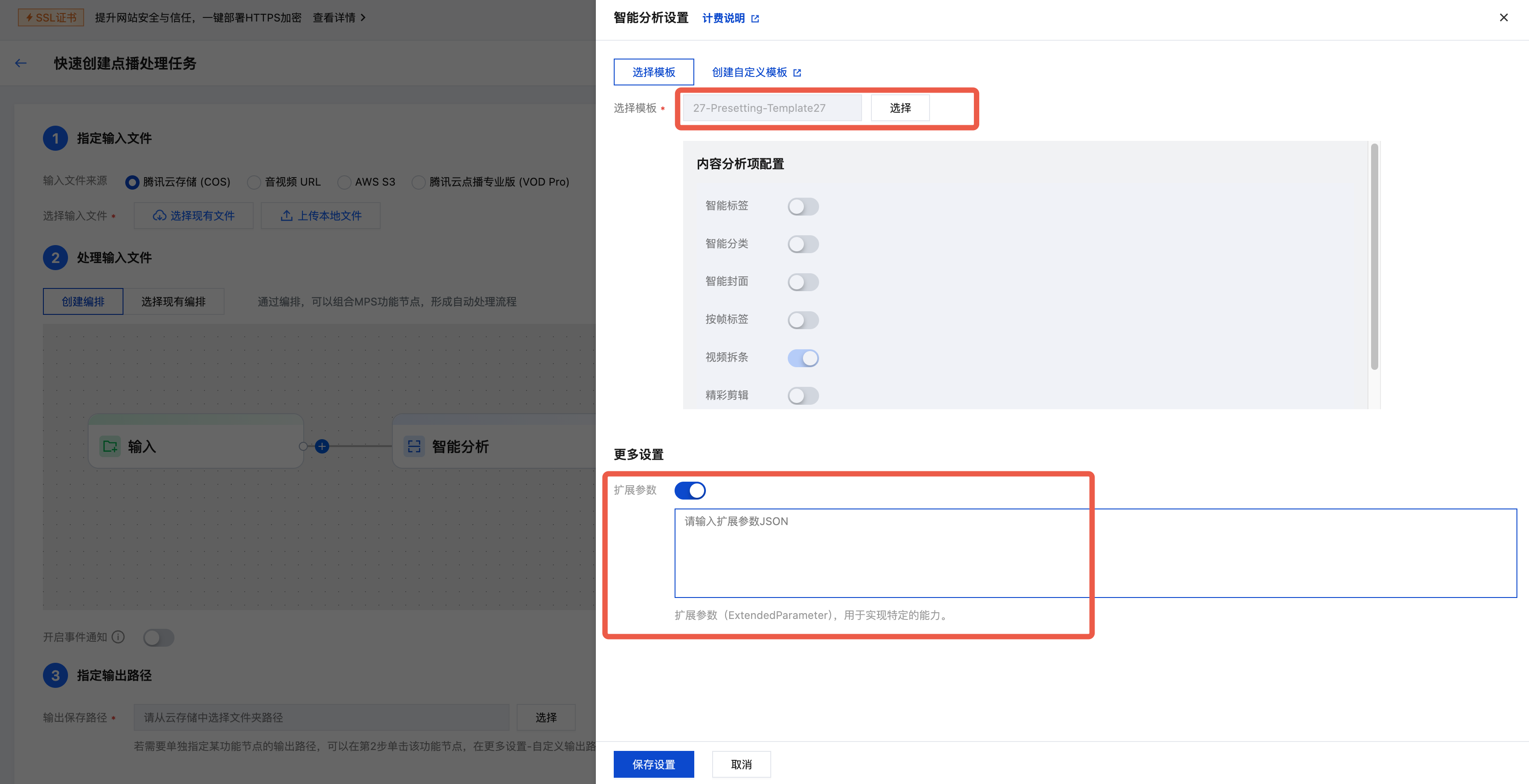
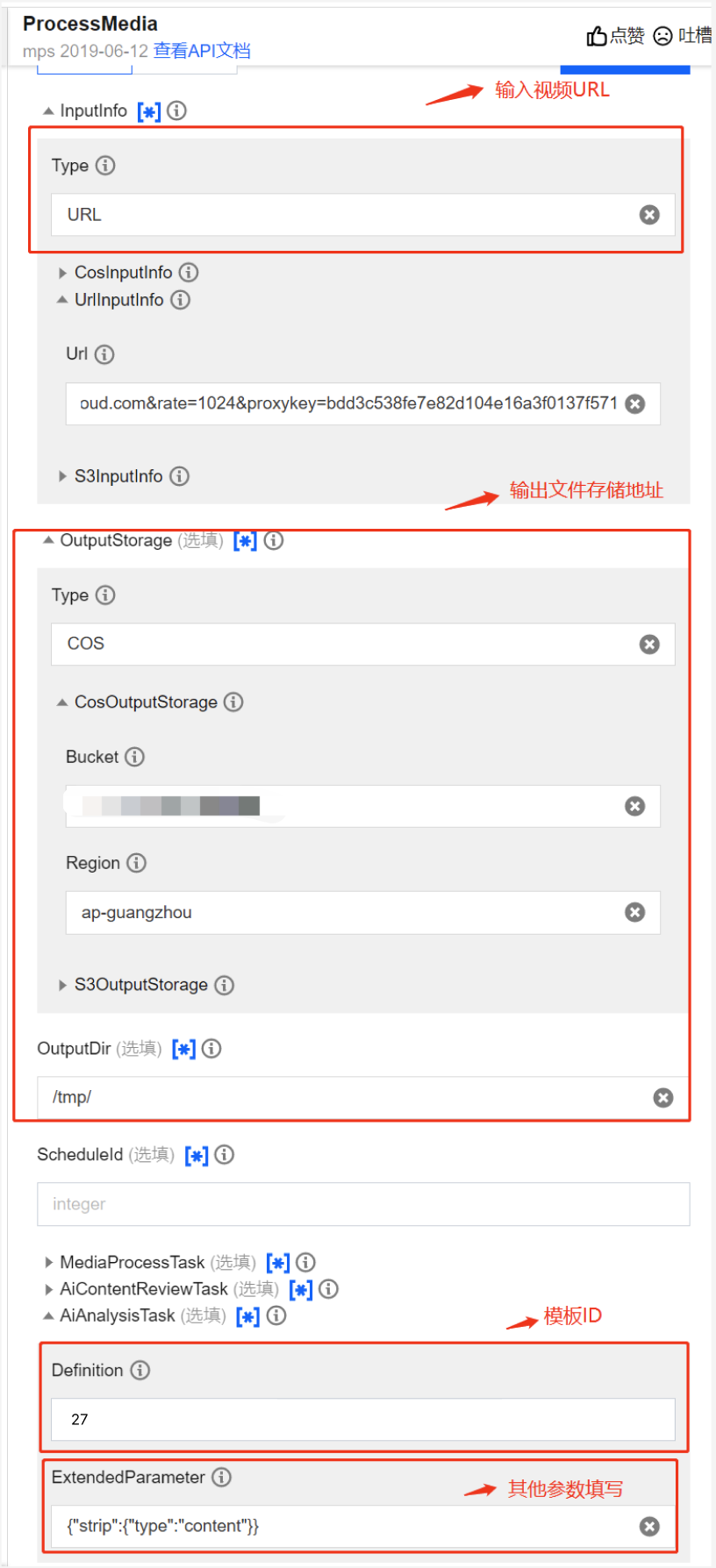
3. 在右侧弹出的智能分析设置页面中,选择预设智能拆条模板(模板 ID:27)。您可以开启更多设置下的扩展参数,参考 拆条场景及扩展参数示例 传入扩展参数来指定拆条场景、实现更好的拆条效果。为保证处理效果,建议您 联系我们,线下对接确认具体配置。
说明:
MPS 控制台会自动转义,请直接传入 JSON 数据,不要传入转义后的字符串,否则任务会失败。
若未填入扩展参数,默认为新闻拆条场景。
4. 最后,单击创建发起任务。
发起任务方式2:自动触发
若您希望实现:在 COS 桶中上传了视频文件,自动按照预设参数进行智能拆条处理。您可以在创建任务时单击保存此编排,在弹出的窗口中配置触发 Bucket、触发目录等参数。
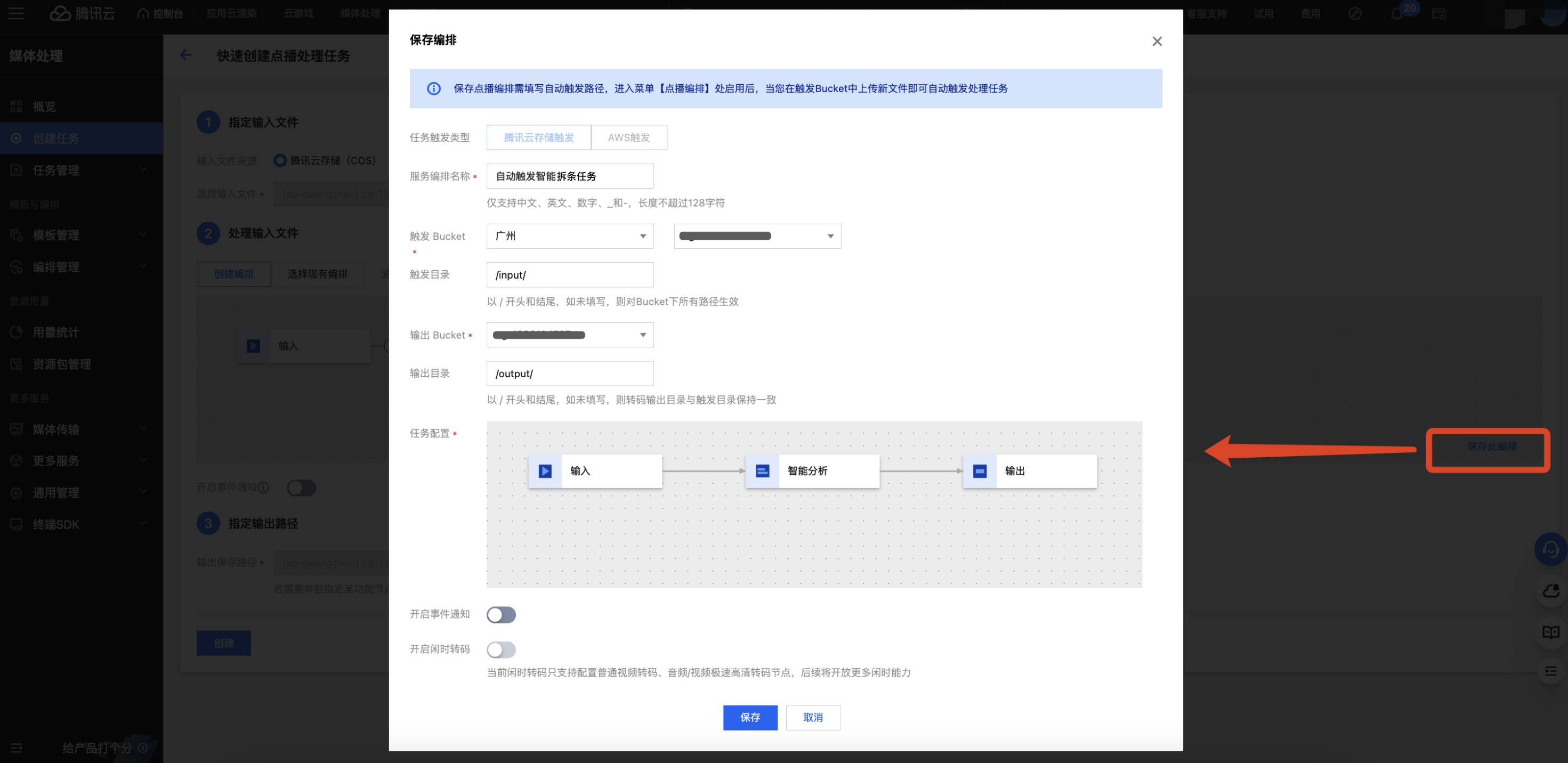
然后进入离线编排列表,找到刚创建好的编排,在启用处开启按钮即可。后续在触发目录下新增的视频文件,将自动按照该编排预设的流程和参数发起任务,并将处理后的视频文件保存到编排配置的输出路径中。
注意:
启用编排成功后,需要3~5分钟才会生效。
发起任务方式3:调用 API
如期望调用 API 发起任务,您可以调用 ProcessMedia 接口 ,选择 AiAnalysisTask 任务,将 Definition 设置为 27(预设智能拆条模板),ExtendedParameter 填额外的扩展参数,用于指定拆条场景、实现更好的拆条效果,取值详情见 拆条场景及扩展参数示例。ProcessMedia 接口传参 JSON 示例如下:
{"InputInfo":{ //输入视频路径,请替换为您的原始视频"Type":"URL","UrlInputInfo":{"Url":"https://test-1234567.cos.ap-nanjing.myqcloud.com/mps_test/myvideo.mp4"}},"OutputStorage":{ //输出COS存储桶,请替换"Type":"COS","CosOutputStorage":{"Bucket":"test","Region":"ap-nanjing"}},"OutputDir":"/mps_test/output/",//输出文件夹路径,请替换"AiAnalysisTask":{"Definition":27, //智能拆条预设模板ID,填 27 即可"ExtendedParameter":"{\\"des\\":{\\"split\\":{\\"method\\":\\"llm\\",\\"model\\":\\"deepseek-v3\\",\\"max_split_time_sec\\":100,\\"extend_prompt\\":\\"本视频为在线教育场景视频,按照老师讲解知识点对视频进行分段\\"},\\"need_ocr\\":true,\\"text_requirement\\":\\"摘要在40字以内\\",\\"dstlang\\":\\"zh\\"},\\"strip\\":{\\"type\\":\\"content\\"}}" //扩展参数,选择不同拆条场景需要替换这部分参数,取值参考接入教程文档说明},"TaskNotifyConfig":{ //事件回调通知配置,可选"NotifyType":"URL","NotifyUrl":"http://www.qq.com/callback"}}
建议您通过 API Explorer 实现快速验证。您可以将上述 JSON 复制到 API Explorer 的 JSON 模式中,切换至“表单”模式可以自动解析,调整输入输出路径等必要参数后,再单击发起调用即可。
在 API Explorer 表单和 JSON 两种输入模式下,ExtendedParameter 的位置示意如下:
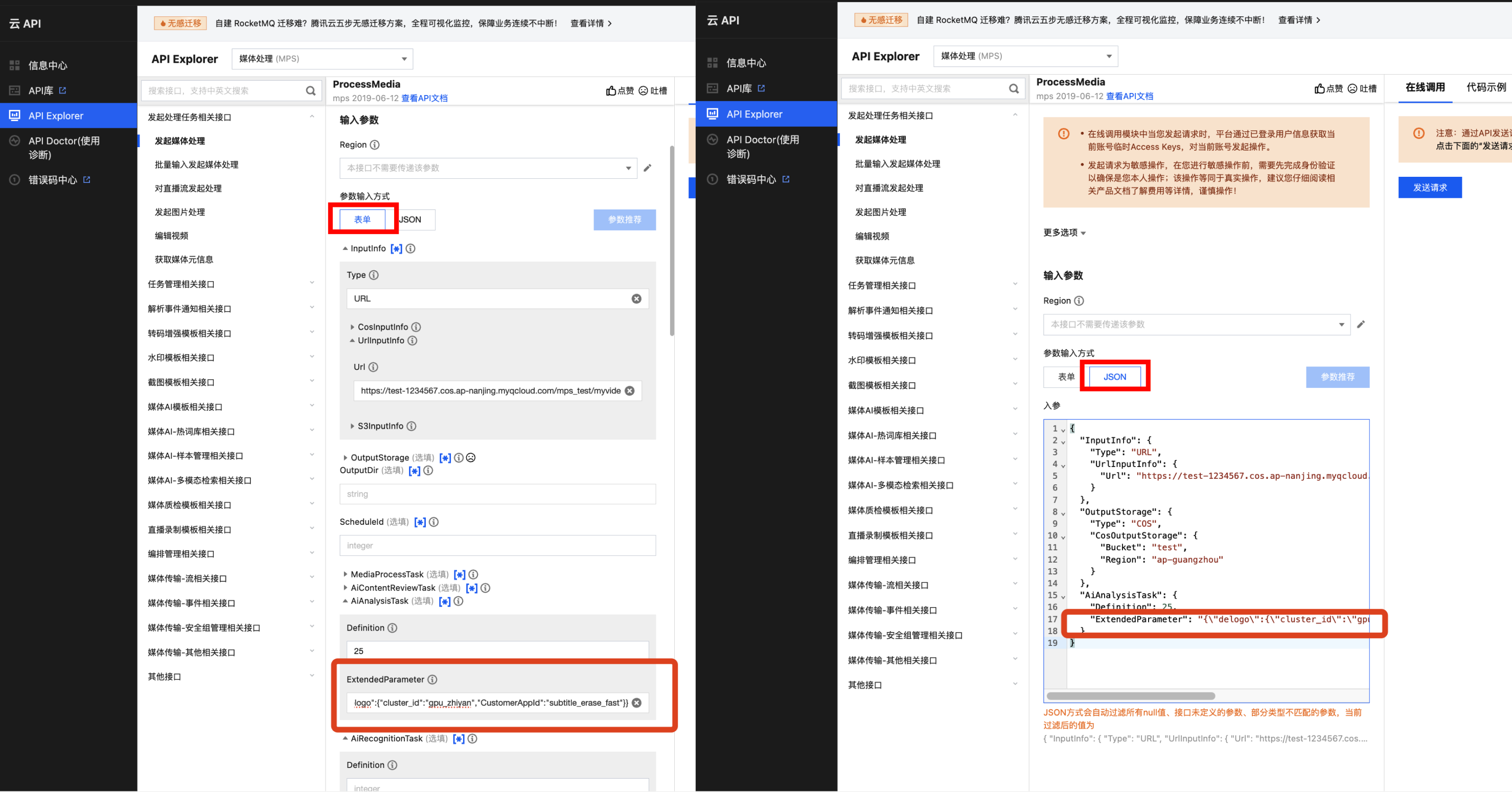
注意:
使用 API Explorer 的表单模式填写 ExtendedParameter 时,需要直接传入 JSON,不用转换成字符串。但使用 API Explorer 的 JSON 模式或直接使用 API 接口,则必须传入转义后的字符串。
API Explorer 表单模式,ExtendedParameter 传入 JSON 即可,示例:
{"des":{"split":{"method":"llm","model":"deepseek-v3","max_split_time_sec":100,"extend_prompt":"本视频为在线教育场景视频,按照老师讲解知识点对视频进行分段"},"need_ocr":true,"text_requirement":"摘要在40字以内","dstlang":"zh"},"strip":{"type":"content"}}
API Explorer JSON 模式,ExtendedParameter 则需要传入转义后的字符串,示例:
{\\"des\\":{\\"split\\":{\\"method\\":\\"llm\\",\\"model\\":\\"deepseek-v3\\",\\"max_split_time_sec\\":100,\\"extend_prompt\\":\\"本视频为在线教育场景视频,按照老师讲解知识点对视频进行分段\\"},\\"need_ocr\\":true,\\"text_requirement\\":\\"摘要在40字以内\\",\\"dstlang\\":\\"zh\\"},\\"strip\\":{\\"type\\":\\"content\\"}}
查询任务结果
智能拆条任务会输出处理后的分段视频文件、封面图等信息,保存在任务配置的输出路径下。
控制台查询结果
1. 您可以在控制台 任务管理 页面查看任务状态,当子任务状态为“成功”时:
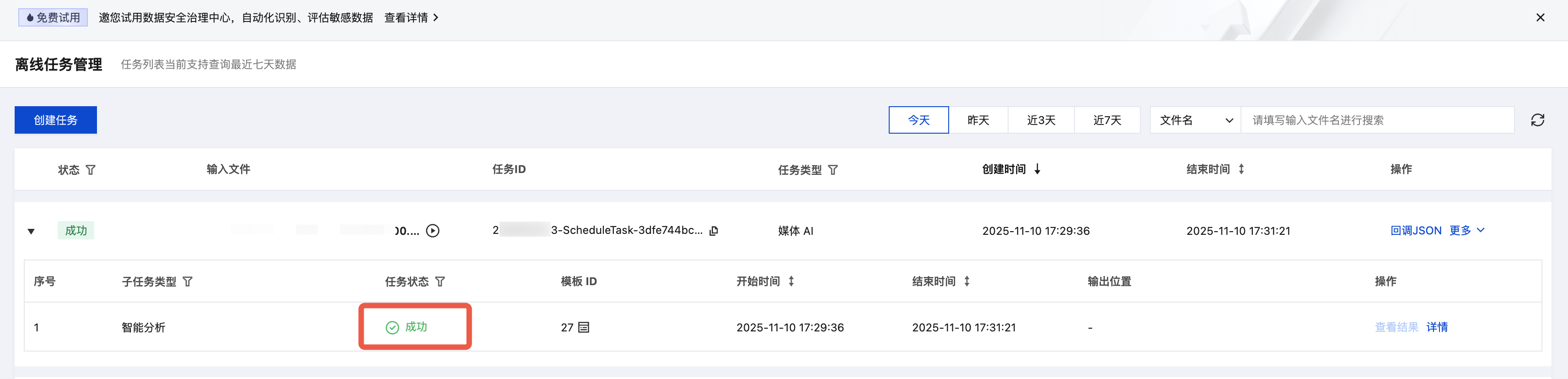
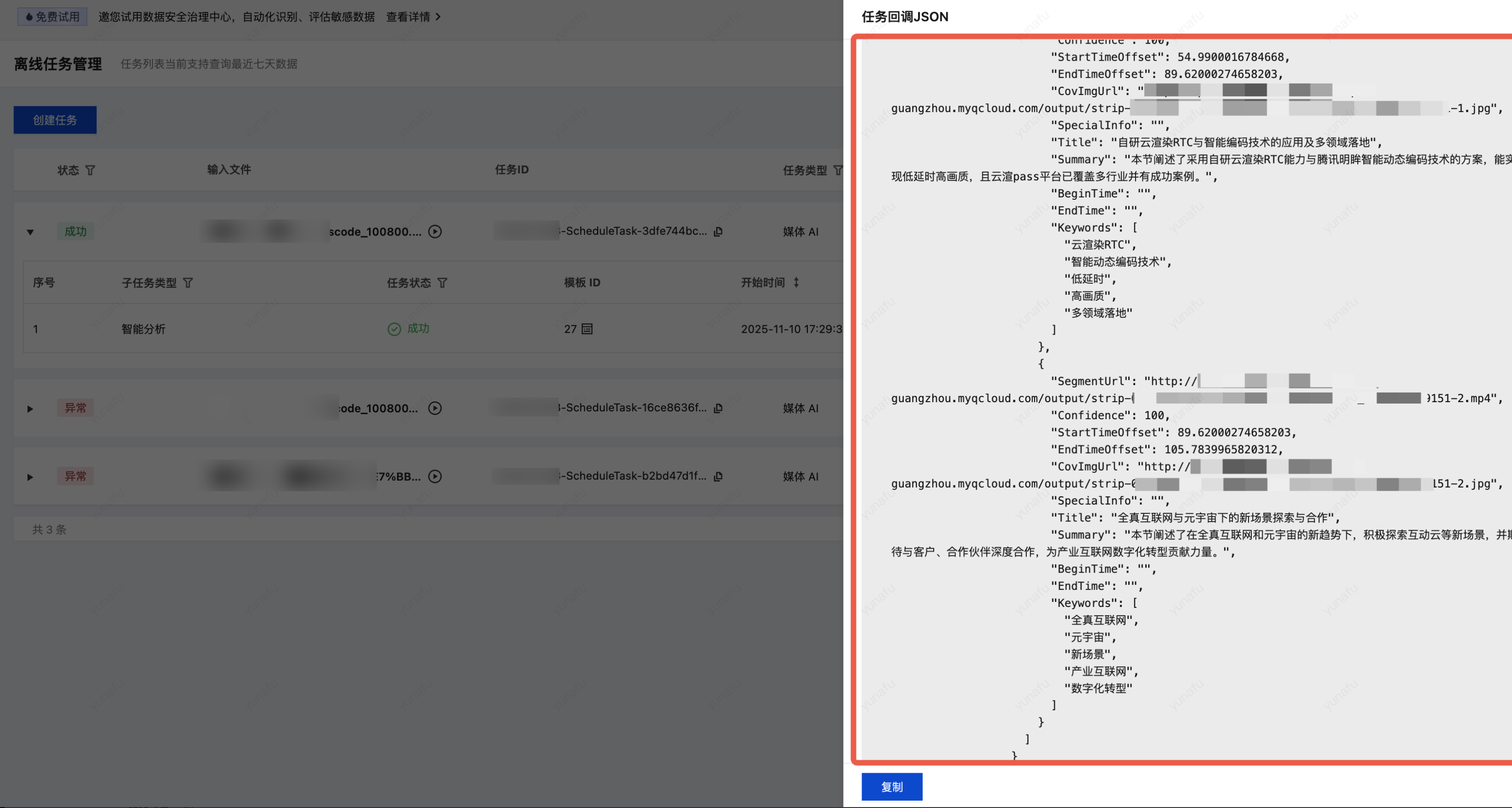
2. 单击回调JSON,可以在输出信息中找到输出结果和输出文件路径:
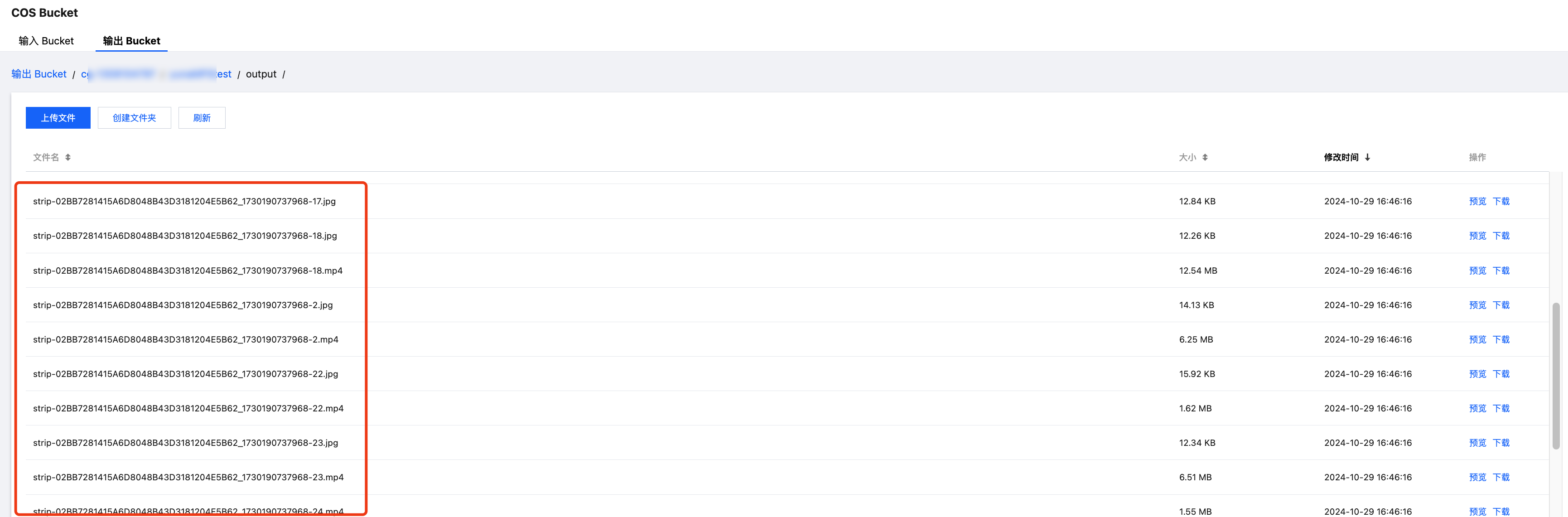
3. 如果使用 COS 作为输出路径,您可以在 MPS 控制台的 COS Bucket > 输出 Bucket 页面中找到您的输出目录,在目录下
strip-开头的文件即为智能拆条的输出文件(分段视频以及封面图)。说明:
标题、摘要等文本内容不会输出至 Bucket 中,必须通过事件回调或接口查询。
事件通知回调
在使用 ProcessMedia 发起媒体处理任务时,您可以通过
TaskNotifyConfig 参数配置事件回调。当任务处理完成后,会通过配置的回调信息回调任务结果,您可以通过 ParseNotification 解析事件通知结果。调用接口查询任务结果
在使用 ProcessMedia 发起媒体处理任务后,会返回任务 ID(
TaskId),例如:24000022-WorkflowTask-b20a8exxxxxxx1tt110253、24000022-ScheduleTask-774f101xxxxxxx1tt110253。调用 DescribeTaskDetail 接口,输入任务 ID 即可获取任务结果,您需要解析 WorkflowTask ->AiAnalysisResultSet 字段获取任务结果。处理直播流
发起任务方式:API 发起任务
智能拆条任务暂仅支持通过 API 发起直播流处理任务。
调用 对直播流发起处理(ProcessLiveStream)接口 ,选择 AiAnalysisTask 任务,将 AiAnalysisTaskInput - Definition 设置为 27(预设智能拆条模板)。
说明:
直播流目前支持新闻拆条、NLP 拆条场景,暂不支持目标拆条场景。
{"Url": "http://www.abc.com/abc.m3u8","TaskNotifyConfig": {"NotifyType": "URL","NotifyUrl": "http://www.qq.com/callback"},"OutputStorage": {"Type": "COS","CosOutputStorage": {"Bucket": "mybucket","Region": "ap-guangzhou"}},"OutputDir": "/path/to/output/","AiAnalysisTask": {"Definition": 27,"ExtendedParameter": "{\\"des\\":{\\"split\\":{\\"method\\":\\"llm\\",\\"model\\":\\"deepseek-v3\\",\\"max_split_time_sec\\":100,\\"extend_prompt\\":\\"本视频为在线教育场景视频,按照老师讲解知识点对视频进行分段\\"},\\"need_ocr\\":true,\\"text_requirement\\":\\"摘要在40字以内\\",\\"dstlang\\":\\"zh\\"},\\"strip\\":{\\"type\\":\\"content\\"}}"}}
API Explorer 快速验证
说明:
Explorer 会自动转换,ExtendedParameter 填写对应 json 即可,不用转换成字符串。
查询直播拆条任务结果
接收任务回调:在使用 ProcessLiveStream 发起媒体处理任务时,通过
TaskNotifyConfig 参数设置回调信息。处理直播流过程中,会通过配置的回调信息实时回调任务结果。您可以参考 解析直播流处理结果 文档解析 AiAnalysisResultInfo 字段获取任务结果。附:扩展参数说明
参数 | 是否必填 | 类型 | 说明 |
split.method | 否 | string | 视频分段方法,llm 表示大模型分段,nlp 表示传统 nlp 分段,默认为 llm。 |
split.model | 否 | string | 分段大模型,可选 hunyuan,deepseek-v3,deepseek-r1,默认为 deepseek-v3。 |
split.max_split_time_sec | 否 | int | 强制指定最大分段时间,单位秒。建议必要情况下再使用,可能影响分段效果。默认3600。 |
split.extend_prompt | 否 | string | 补充大模型分段任务提示词,如“本视频为教学视频,按照相关知识点对视频进行分段”。建议先不填进行测试,效果不达预期时再补充。 |
need_ocr | 否 | bool | 是否使用 ocr 辅助分段,true 表示开启,默认为 false。 不开启,系统仅识别视频语音内容辅助视频分段;开启,还会识别视频画面上的文字内容辅助视频分段。 |
text_requirement | 否 | string | 补充大模型摘要任务提示词。例如限制字数"摘要在40字以内"。 |
dstlang | 否 | string | 视频语言,用于视频语音识别与摘要相关结果语言指定,默认为"zh"。 "zh":中文 "en":英文 |



