概述
故障诊断与恢复功能旨在及时发现算力资源异常,快速定位问题类型及原因,并通过自动或手动的方式恢复算力资源,以保障业务连续性与稳定性。
本文将详细介绍 TI-ONE 平台提供的故障诊断机制,并列举典型异常场景及其处理方案。同时,本文还将介绍如何配置告警规则,以便及时预警,最大程度降低业务风险。
故障诊断机制
平台提供自动与手动两种诊断方式,全面覆盖各类运维场景:
1. 自动诊断
CVM 自动诊断:云服务器支持自动探测CVM实例异常,并主动下发维修任务。
TI-ONE 自动检测:TI-ONE 平台支持在后台定时检测节点是否处于可用状态,预防潜在故障。
2. 手动诊断
TI-ONE 健康检测:TI-ONE 平台资源组内提供手动创建健康检测任务的功能,支持主动排查节点网络连通性及环境一致性等。
CVM 自动诊断
CVM 自动诊断是由 云服务器 提供的标准化故障处理服务,当云服务器检测到实例突发异常时(例如底层宿主机突发异常宕机,或主动预测底层宿主机的软硬件故障隐患以提前规避宕机风险),云服务器将自动创建相应的维修任务并发送通知。您可在 CVM控制台 的维修任务列表中,查看并关注实例恢复情况。触发维修任务的异常类型、具体含义以及处理策略详见 维修任务类型与处理策略。
说明:
若您添加至 TI-ONE 平台 资源组 的 CVM 机器上存在云服务器下发的维修任务,平台会将节点状态变更为“待维修”,引导您前往 CVM 控制台完成授权操作。处理方式详见 节点上存在CVM维修任务 。
TI-ONE 自动诊断
TI-ONE 自动诊断是由 TI-ONE资源组 提供的故障诊断能力,支持在添加/管理/释放节点的过程中,持续检测节点状态及关联组件是否正常可用。当检测到 GPU 掉卡、XID 异常、VPC 网络不通等问题时,能够通过诊断工具定位具体原因,并按下图中的逻辑自动分为三类处理方式。
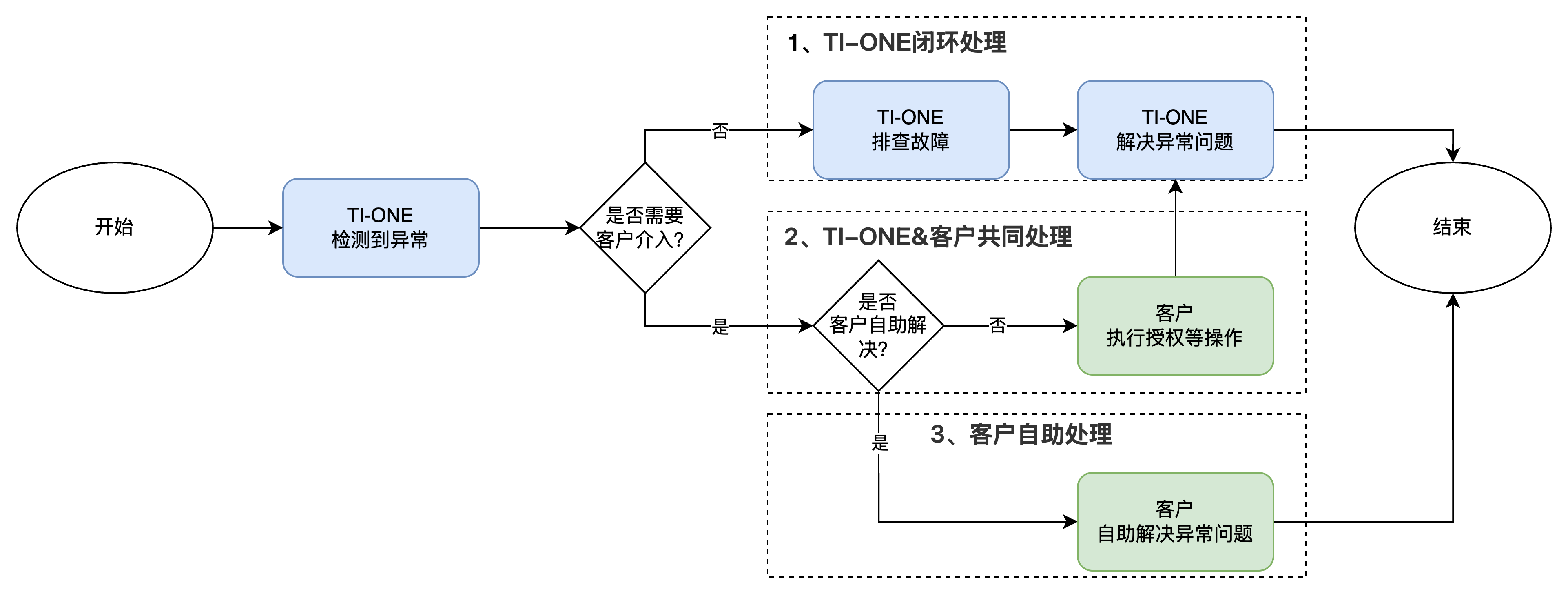
处理方式 | 说明 | 举例 |
TI-ONE 闭环处理 | 表示由 TI-ONE 平台完成“诊断-排查-恢复”的全流程,控制台仅作必要展示(包括异常原因及异常信息等)。 | 将 CVM 节点添加至资源组时,由于创建TKE集群失败导致添加失败。 |
TI-ONE & 用户共同处理 | 表示 TI-ONE 平台检测到异常后,通知用户介入,并指引用户完成某些操作后(如授权等),由TI-ONE排障解决。 | 已添加至资源组的节点由于CVM侧下发了维修任务,需要用户主动授权后,由 TI-ONE & CVM 恢复节点。 |
用户自助处理 | 表示 TI-ONE 平台将检测的异常信息反馈给用户,并指引用户自助完成排障操作。 | CVM 算力费用或节点的软件订阅费用即将到期,需要用户自助操作续费。 |
TI-ONE 健康检测
通过预先检测节点可用性,可有效规避因节点故障导致的各类运行问题,举例如下:
避免 GPU 资源浪费:当任务或服务因节点故障(如驱动异常)而陷入持续重试循环时,即便已完成模型加载等耗时初始化操作,也无法正常执行。这不仅占用宝贵的GPU资源,还需投入额外时间进行故障排查与任务重新提交。健康检测可在此类任务启动前识别并排除故障节点,从而保障资源高效利用。
防止任务/服务性能受损:在任务或服务运行过程中,可能因节点网络通信缓慢等问题,导致训练效率低下或在线服务响应延迟。由于此类性能瓶颈在任务启动前难以预知,往往在造成实质性影响后才被发现。健康检测能够提前暴露此类潜在性能缺陷,防止任务在非健康节点上启动,从源头保障业务性能。
下面将详细介绍如何在资源组内创建一个健康检测任务。
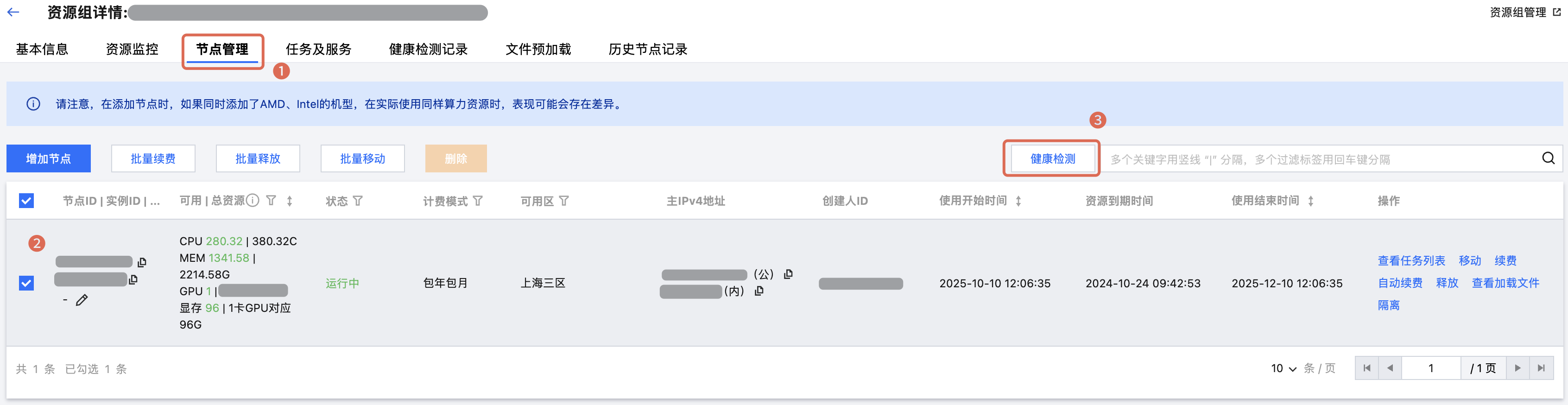
1. 创建健康检测任务
进入资源组详情页的“节点管理” tab 中,选择需要检测的节点范围,并单击右上角 健康检测 按钮。在弹窗内选择检测项后,即可完成创建。
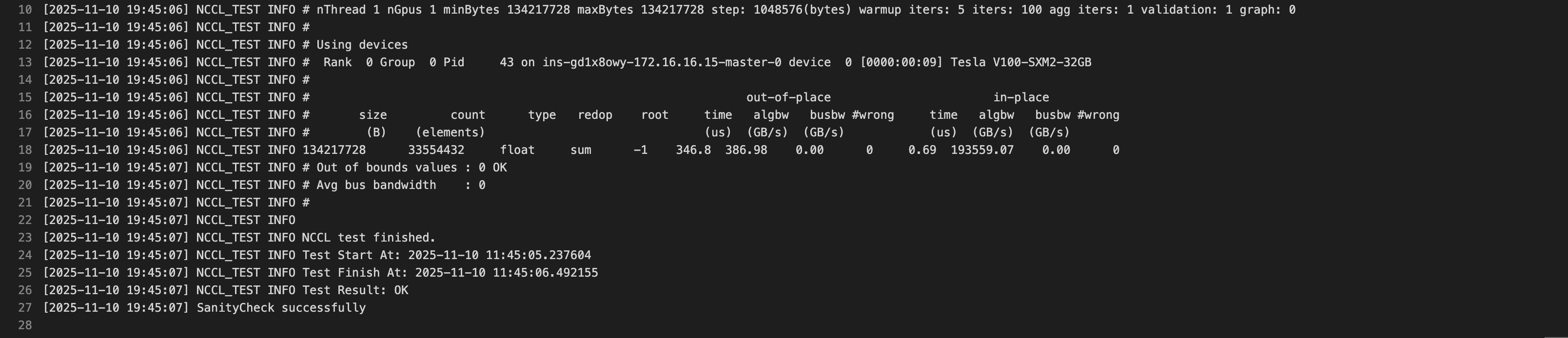
2. 查看任务记录及结果
切换至“健康检测记录” tab,可查看任务运行历史,以及检测结果日志。

典型场景及处理方案
由 TI-ONE 闭环处理
下表中列举了由 TI-ONE 自动完成诊断与修复的十余种异常场景。当平台检测到此类异常时,将自动触发处理流程并协调相关资源进行修复,期间无需您手动介入,请您耐心等待。若持续未解决,可 提交工单 联系我们获取进一步支持。
触发阶段 | 节点状态 | 异常原因 | 异常场景 |
添加节点时 | 部署失败 | TKE 集群创建失败 | 由于 TKE 版本限制,导致调用 TKE 接口创建集群失败 由于 TKE API 存在变更没有同步,导致添加 agent 节点到集群失败 由于 TKE 的注册节点能力未开启或者存在bug,导致 TKE 集群注册节点失败 |
| | 无法将节点添加至 TKE 集群 | 由于注册脚本存在bug,或未适配新版本操作系统,导致注册脚本执行失败 由于 CVM 操作系统变更,原有操作系统镜像不支持使用,导致调用 CVM 接口安装操作系统失败 由于 CVM 节点硬盘为只读权限,导致注册脚本执行失败 |
| | TKE 集群初始化失败 | 由于 CVM 节点的 GPU / RDMA 存在故障,导致TKE集群的系统组件处于 pending 状态 由于 CVM 节点的网络存在异常,无法访问系统服务,导致TKE集群的系统组件处于 crash状态 由于 TKE 未适配 CVM 节点对应的 GPU 机型,导致 qgpu/rdma/eni 等资源为0 Turbocfs 组件状态异常。由于 turbocfs 未适配最新操作系统,导致 CVM 节点的存储组件不可用 |
使用节点时 | 异常 | 节点未处于“Running”状态 | 由于 CVM 节点启动失败/被操作停机,导致 ping 不通或无法 ssh 由于 CVM 节点启动后,关键服务组件初始化失败,导致节点资源异常(qgpu/rdma/eni等资源为0) |
| | NPD 检测节点存在异常 | 由于 GPU/RDMA/CPU/内存/本地磁盘/操作系统/K8S组件 等对象异常,导致 CVM 节点不可用 |
| | TKE 集群的系统组件存在异常 | 由于 RDMA 网卡宕机,导致 CVM 节点的 RDMA/GPU 组件处于 crash 状态 由于操作系统存在内存泄露,导致 CVM 节点不可用 |
| | qGPU 组件状态异常 | 由于 qGPU 未适配对应 GPU 卡型,或驱动版本>550,导致 CVM 节点的 qGPU 组件不可用 |
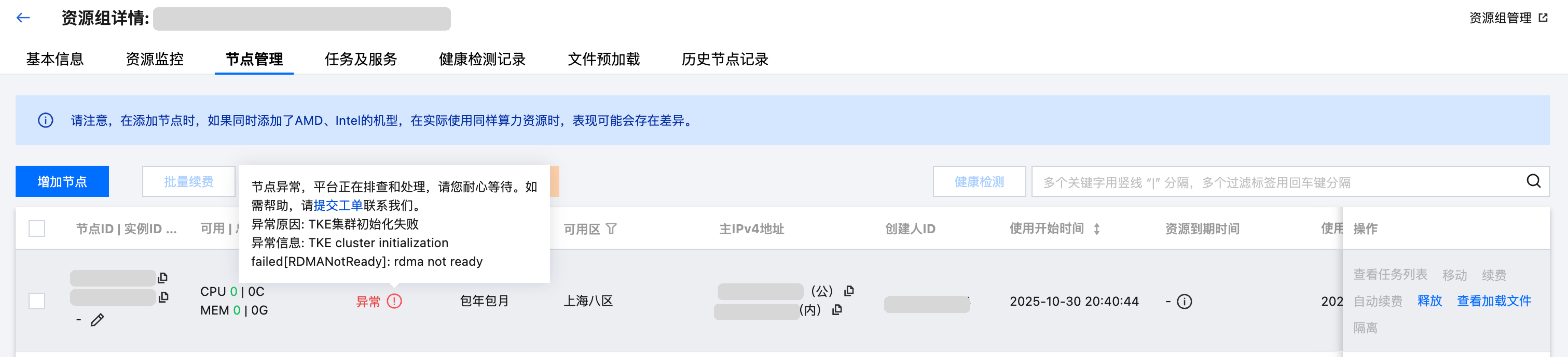
对于上述场景,TI-ONE 控制台将显示必要的提示信息,包括失败原因及具体的异常信息。举例如下:

由 TI-ONE & 用户共同处理
下表中列举了由 TI-ONE 与用户共同处理的4种异常场景。当检测到此类异常时,平台将明确提示异常原因,并引导您前往指定界面完成必要的故障排查或修复操作。
触发阶段 | 节点状态 | 异常原因 | 异常场景 |
添加节点时 | 部署失败 | 无法将节点添加至 TKE 集群 | 由于用户的 VPC 存在网络限制,导致无法连接节点 |
| | | 由于 CVM 节点上存在历史残留的lvm卷,导致注册脚本执行失败 |
使用节点时 | 待维修 | 节点上存在 CVM 侧下发的维修任务 | 由于 CVM 侧主动发现节点异常,并下发了维修任务(如:CPU/硬盘/主板/网卡等硬件故障,或 GPU/网卡 等运行异常)。详见 CVM自动诊断 |
| 异常 | 网络连接异常 | 由于用户的 VPC 安全组/路由配置异常,导致无法连接到节点 |
各种异常的处理方案——
控制台提示信息如下图所示:

处理方案:
1. 单击提示信息中的 云联网 按钮,前往 云联网 控制台。
2. 创建实例:单击 新建 按钮,创建云联网实例。详见文档 新建云联网实例。
3. 关联VPC:进入云联网实例详情页,在 “关联实例” tab 中,单击列表左上方 新增实例 按钮,在弹窗内选择需要关联的网络实例类型、所属地域和具体 VPC 实例。详见文档 关联网络实例。(备注:需要添加的 VPC 实例分别为控制台显示的“平台VPC”与“节点VPC”)
4. 检查路由表:在路由表tab页内查看云联网关联的 VPC 下各子网的路由策略是否生效。若所关联的网络实例网段有冲突,则会产生失效路由。
处理方案:
1. 单击提示信息中的 授权 按钮,前往 CVM 控制台的 维修任务 列表,找出对应 CVM 实例上的任务信息。
2. 单击列表右侧 授权/预约 按钮,在弹窗内选择具体的授权维护方式及预约维护时间。单击 确定 即可完成授权操作。
由用户自助处理
下表中列举了支持用户完全自助处理的4种常见场景。平台在检测到这些异常后,将提供清晰的异常说明与处理指引,您可参照提示在指定页面内独立完成修复操作,快速恢复业务运行。
触发阶段 | 节点状态 | 异常原因 | 异常场景 |
使用节点时 | 异常 | 节点未处于“Running”状态 | 由于用户主动在 CVM 控制台操作节点重启/关机,或节点已到期,导致节点不可用 |
| 运行中 | 节点即将到期 | CVM 实例的算力费用即将到期,需要用户自助操作续费 TI-ONE 资源组节点的软件订阅费即将到期,需要用户自助操作续费 |
| 运行中 | 磁盘空间不足 | CVM 实例挂载的是系统盘或数据盘写满,导致 POD 无法启动,需要用户自助操作扩容 |
各种异常的处理方案——
控制台提示信息如下图所示:

处理方案:
1. 单击提示信息中的 CVM控制台 按钮,前往 CVM控制台,在实例列表中找出对应机器。
2. 确认该实例状态是否处于“重启中/已关机/待回收”。
2.1 若处于上述状态且确认不再使用该机器,可前往 实例回收站 直接单击 释放 按钮。
2.2 若仍需继续使用,可单击 续费 或 恢复 按钮确保实例正常可用。


告警配置
在资源组的运维过程中,平台已将对节点状态变化的监控接入 腾讯云可观测平台 的告警规则。当节点进入“异常”、“维修中”、“已隔离”等关键生命周期状态时,系统会主动向您推送告警,协助您及时掌握资源动态,保障运维效率。
目前已覆盖的告警触发状态包括:异常、购买状态、维修中、待维修、运行中、已销毁、已隔离等。
配置告警规则的步骤如下:
1. 进入 可观测平台 > 告警管理 > 告警配置 ,单击 新建策略 并选择 自定义告警策略。
2. 在 新建告警策略 页面填写策略名称及描述,按以下参数配置告警规则:
2.1 监控类型:选择“云产品监控”;
2.2 策略类型:选择“腾讯云大模型训推平台 TI-ONE / 资源 / 资源状态”;
2.3 告警对象:按需选择“指定实例”(资源组节点),或“全部对象”;
2.4 触发条件:手动配置,在“指标”字段中选择需要告警的节点状态,如“实例异常”。
3. 单击 下一步:配置告警通知 ,选择通知模板后单击 完成 。



