解决方案描述
概述
本方案结合本地自建 Kafka 集群、腾讯云流计算 Oceanus(Flink)、云数据库 Redis 对博客、购物等网站 UV、PV 指标进行实时可视化分析。分析指标包含网站的独立访客数量(UV )、产品的点击量(PV)、转化率(转化率 = 成交次数 / 点击量)等。
UV(Unique Visitor):独立访客数量。访问您网站的一台客户端为一个访客,如用户对同一页面访问了5次,那么该页面的 UV 只加1,因为 UV 统计的是去重后的用户数而不是访问次数。
PV(Page View):点击量或页面浏览量。 如用户对同一页面访问了5次,那么该页面的 PV 会加5。
方案架构及优势
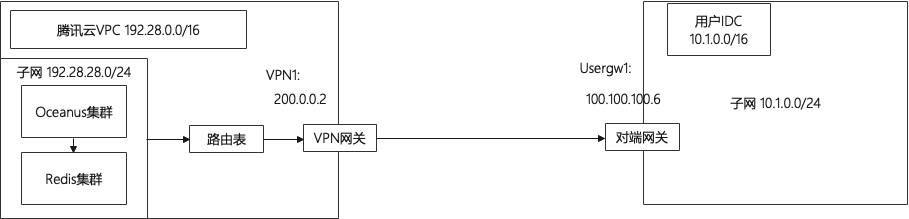
根据以上实时指标统计场景,设计了如下架构图:

涉及产品列表:
本地数据中心(IDC)的自建 Kafka 集群
私有网络 VPC
专线接入/云联网/VPN 连接/对等连接
流计算 Oceanus (Flink)
云数据库 Redis
前置准备
购买所需的腾讯云资源,并打通网络。自建的 Kafka 集群需根据集群所在区域需采用 VPN 连接、专线连接或对等连接的方式来实现网络互通互联。
创建私有网络 VPC
私有网络(VPC)是一块在腾讯云上自定义的逻辑隔离网络空间,在构建 Oceanus 集群、Redis 组件等服务时选择的网络建议选择同一个 VPC,网络才能互通。否则需要使用对等连接、NAT 网关、VPN 等方式打通网络。私有网络创建步骤可参考 创建私有网络。
创建 Oceanus 集群
流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发、无缝连接、亚秒延时、低廉成本、安全稳定等特点的企业级实时大数据分析平台。流计算 Oceanus 以实现企业数据价值最大化为目标,加速企业实时化数字化的建设进程。
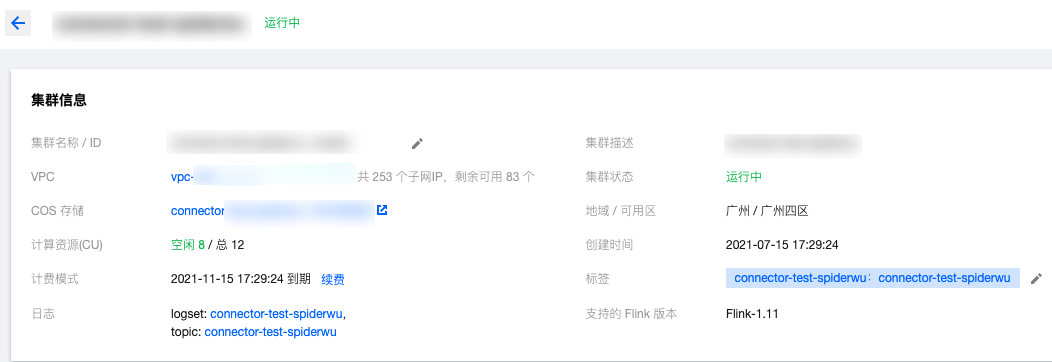
在流计算 Oceanus 控制台的集群管理 > 新建集群中创建集群,选择地域、可用区、VPC、日志、存储,设置初始密码等。VPC 及子网使用刚创建好的网络。创建完后 Flink 的集群如下:
创建 Redis 集群

配置自建 Kafka 集群
修改自建 Kafka 集群配置
自建 Kafka 集群连接时
bootstrap-servers 参数常使用 hostname 而不是 IP 来连接。但用自建 Kafka 集群连接腾讯云上的 Oceanus 集群为全托管集群, Oceanus 集群的节点上无法解析自建集群的 hostname 与 IP 的映射关系,所以需要改监听器地址由 hostname 为 IP 地址连接的形式。将
config/server.properties 配置文件中 advertised.listeners 参数配置为 IP 地址。# 0.10.X及以后版本advertised.listeners=PLAINTEXT://10.1.0.10:9092# 0.10.X之前版本advertised.host.name=PLAINTEXT://10.1.0.10:9092
修改后重启 Kafka 集群。
注意
若在云上使用到自建的 zookeeper 地址,也需要将 zk 配置中的 hostname 修改 IP 地址形式。
模拟发送数据到 topic
本案例使用 topic 为
uvpv-demo。Kafka 客户端
进入自建 Kafka 集群节点,启动 Kafka 客户端,模拟发送数据。
./bin/kafka-console-producer.sh --broker-list 10.1.0.10:9092 --topic uvpv-demo>{"record_type":0, "user_id": 2, "client_ip": "100.0.0.2", "product_id": 101, "create_time": "2021-09-08 16:20:00"}>{"record_type":0, "user_id": 3, "client_ip": "100.0.0.3", "product_id": 101, "create_time": "2021-09-08 16:20:00"}>{"record_type":1, "user_id": 2, "client_ip": "100.0.0.1", "product_id": 101, "create_time": "2021-09-08 16:20:00"}
使用脚本发送
脚本一:Java 代码可参考 使用 SDK 收发消息(推荐)。
脚本二:Python 脚本。参考之前案例中 Python 脚本进行适当修改即可,详情可参考 视频直播解决方案之实时 BI 分析。
打通自建 IDC 集群到腾讯云网络通信
自建 Kafka 集群联通腾讯云网络,可通过以下前3种方式打通自建 IDC 到腾讯云的网络通信。
专线接入:适用于本地数据中心 IDC 与腾讯云网络打通。
云联网:适用于本地数据中心 IDC 与腾讯云网络打通,也可用于云上不同地域间私有网络 VPC 打通。
VPN 连接:适用于本地数据中心 IDC 与腾讯云网络打通。
方案实现
业务目标
利用流计算 Oceanus 实现网站 UV、PV、转化率指标的实时统计,这里只列取以下3种统计指标:
网站的独立访客数量 UV。Oceanus 处理后在 Redis 中通过 set 类型存储独立访客数量,同时也达到了对同一访客的数据去重的目的。
网站商品页面的点击量 PV。Oceanus 处理后在 Redis 中使用 list 类型存储页面点击量。
转化率(转化率 = 成交次数 / 点击量)。Oceanus 处理后在 Redis 中用 String 存储即可。
源数据格式
Kafka topic:uvpv-demo(浏览记录)
字段 | 类型 | 含义 |
record_type | int | 记录类型 |
user_id | varchar | 用户 ID |
client_ip | varchar | 客户端 IP |
product_id | Int | 产品 ID |
create_time | timestamp | 创建时间 |
Kafka 内部采用 json 格式存储,数据格式如下:
# 浏览记录{"record_type":0, # 0 表示浏览记录"user_id": 6,"client_ip": "100.0.0.6","product_id": 101,"create_time": "2021-09-06 16:00:00"}# 购买记录{"record_type":1, # 1 表示购买记录"user_id": 6,"client_ip": "100.0.0.8","product_id": 101,"create_time": "2021-09-08 18:00:00"}
编写 Flink SQL 作业
示例中实现了 UV、PV 和转化率3个指标的获取逻辑,并写入 Sink 端。
定义 Source
CREATE TABLE `input_web_record` (`record_type` INT,`user_id` INT,`client_ip` VARCHAR,`product_id` INT,`create_time` TIMESTAMP,`times` AS create_time,WATERMARK FOR times AS times - INTERVAL '10' MINUTE) WITH ('connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector'topic' = 'uvpv-demo','scan.startup.mode' = 'earliest-offset','properties.bootstrap.servers' = '10.1.0.10:9092','properties.group.id' = 'WebRecordGroup', -- 必选参数, 一定要指定 Group ID'format' = 'json','json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
定义 Sink
-- UV sinkCREATE TABLE `output_uv` (`userids` STRING,`user_id` STRING) WITH ('connector' = 'redis','command' = 'sadd', -- 使用集合保存uv(支持命令:set、lpush、sadd、hset、zadd)'nodes' = '192.28.28.217:6379', -- redis连接地址,集群模式多个节点使用'',''分隔。'password' = 'yourpassword');-- PV sinkCREATE TABLE `output_pv` (`pagevisits` STRING,`product_id` STRING,`hour_count` BIGINT) WITH ('connector' = 'redis','command' = 'lpush', -- 使用列表保存pv(支持命令:set、lpush、sadd、hset、zadd)'nodes' = '192.28.28.217:6379', -- redis连接地址,集群模式多个节点使用'',''分隔。'password' = 'yourpassword');-- 转化率 sinkCREATE TABLE `output_conversion_rate` (`conversion_rate` STRING,`rate` STRING) WITH ('connector' = 'redis','command' = 'set', -- 使用列表保存pv(支持命令:set、lpush、sadd、hset、zadd)'nodes' = '192.28.28.217:6379', -- redis连接地址,集群模式多个节点使用'',''分隔。'password' = 'yourpassword');
业务逻辑
-- 加工得到 UV 指标,统计所有时间内的 UVINSERT INTO output_uvSELECT'userids' AS `userids`,CAST(user_id AS string) AS user_idFROM input_web_record ;-- 加工并得到 PV 指标,统计每 10 分钟内的 PVINSERT INTO output_pvSELECT'pagevisits' AS `pagevisits`,CAST(product_id AS string) AS product_id,SUM(product_id) AS hour_countFROM input_web_record WHERE record_type = 0GROUP BYHOP(times, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE),product_id,user_id;-- 加工并得到转化率指标,统计每 10 分钟内的转化率INSERT INTO output_conversion_rateSELECT'conversion_rate' AS `conversion_rate`,CAST( (((SELECT COUNT(1) FROM input_web_record WHERE record_type=0)*1.0)/SUM(a.product_id)) as string)FROM (SELECT * FROM input_web_record where record_type = 1) AS aGROUP BYHOP(times, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE),product_id;
结果验证
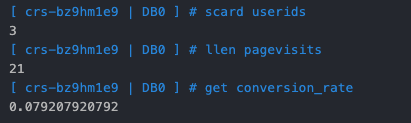
userids:存储 UVpagevisits:存储 PVconversion_rate:存储转化率,即购买商品次数/总页面点击量总结
通过自建 Kafka 集群采集数据,在流计算 Oceanus(Flink)中实时进行字段累加、窗口聚合等操作,将加工后的数据存储在云数据库Redis,统计到实时刷新的 UV、PV 等指标。这个方案在 Kafka json 格式设计时做了简化处理,将浏览记录和产品购买记录都放在了同一个 topic 中,重点通过打通自建 IDC 和腾讯云产品间的网络来展现整个方案。
针对超大规模的 UV 去重,采用了 Redis hyperloglog 方式来实现 UV 统计,相比直接使用 set 类型方式有占用极小的内存空间的优点,详情可参考 Oceanus 在腾讯微视数据的实践-统计某时间段内的 uv、pv。



