前言
Elasticsearch(ES)是一款基于 Lucene 的分布式搜索引擎,可以快速地存储、搜索和分析大量的数据。ES 以其高性能、可扩展性和丰富的功能使得它广泛应用于各种领域,例如企业搜索、日志分析、安全分析、商业智能、向量检索等。腾讯云大数据 Elasticsearch Service 是云端全托管 Elastic Stack 服务,集成 X-Pack 特性,并独有腾讯自研优化的内核特性。近期首发上线的 ES 8.16.1 版本,集成了 HNSW 算法来提高向量检索的计算速度,经过我们调优后,支持高达十亿级向量检索。本文旨在介绍如何使用集文本搜索、向量检索和 AI 能力于一身的 ES 8.16.1,为您带来搜索与分析全新的前沿体验。
总体架构
ES 8.16.1 提供的是一个从自然语言处理,到向量化,再到向量搜索,并能与大模型集成的端到端的搜索与分析平台。与 ES 7 相比,ES 8.16.1 引入了 HNSW 算法来给向量建立图索引,并且集成到 Lucene 的工作方式(倒排索引,BKD 树,缓存等)来优化检索性能。所以,ES 8.16.1 的向量搜索可以跟任何 ES 支持的任意查询相结合,并与聚合、文档级安全性、字段级安全性、索引排序等兼容,并同时兼具良好的性能体验。

总体流程简介如下:
向量化数据:用户可以上传提前训练好的自定义大数据模型,例如词嵌入模型(Word Embeddings)或深度学习模型(如 BERT),让 ES 做实时的读写 Embedding。业务也可以直接将向量数据上报到 ES。
索引向量数据:将向量化的数据存储到 ES 中。在索引过程中,将向量数据分布式地存储在多个节点上,以提高数据的可靠性和可扩展性。
发起向量检索请求:通过使用 ES 的搜索 API,发起向量检索请求。在请求中,需要指定待检索的向量以及其他相关参数,例如调用模型、相似度算法、返回结果数量等。
执行向量检索:ES 使用倒排索引来加速向量检索,快速定位包含特定向量的文档。在向量检索过程中, ES 会根据查询向量的特征,通过倒排索引匹配相似的向量。一旦匹配到倒排索引中的文档, ES 会计算查询向量与匹配文档向量之间的相似度。常用的相似度计算方法包括余弦相似度、欧几里得距离等。
返回检索结果:根据相似度计算的结果, ES 会返回与查询向量最相似的文档或结果。可以根据需求设置返回结果的数量和排序方式。同时,在召回后,可选择将 TOP 结果传入 LLM 大语言模型(例如混元、GPT)等,对信息进行对话式结果整合,最终返回给用户,实现对话式搜索。
操作实践
1. 在腾讯云 Elasticsearch Service 上申请 ES 8.16.1 集群。
2. 在 ES 中上传部署自定义 NLP 模型(可选)。
如果您需要提前将原始数据转化成向量,可以通过一些大数据模型执行推理任务,切割提取文本中的信息,将其转为向量。腾讯云 ES 8.16.1 最大的区别在
于,支持用户无需重启集群即可本地上传提前训练好的自定义大数据模型,例如,从 HuggingFace 上下载的 transformer 模型,并在 Kibana 界面上管理和测试模型。最后通过在管道中集成不同的 Processor,灵活的处理数据。详情可参见 如何将本地 transformer 模型部署到 Elasticsearch。
3. 在 ES 中创建向量索引结构。
命令范例以及一些参数介绍如下:
PUT my_vector_index{"mappings": {"properties": {"my_vector_field": {"type": "dense_vector","dims": 768, // 最高支持2048维度"element_type": "float", // 支持 float, byte"index": true,"similarity": "cosine", // 支持 cosine, dot_product, l2_norm"index_options": { // hnsw 高级参数配置"type": "int8_hnsw","m": 16,"ef_construction": 100}}}}}
4. 导入向量数据。
如果您的数据已经完成向量化数据,可以通过以下 ES Bulk/Index API 直接写入ES。
POST my_vector_index/_doc{ "my_vector_field": [54, 10, -2], "ip": "1.1.1.1", "name": "john" }
如果您的数据需要做向量化,通过指定 ES Ingest Pipeline 配置之前上传的 NLP 模型,可以在实时写入过程中执行推理任务,可以随时添加、删除或更新新向量。
5. 进行向量检索
ES 8.16.1 提供的向量检索功能既可以进行单独向量检索,也可以支持跟任意的查询组合,实现高效预过滤、高效混合搜索。并且跟与聚合、文档级安全性、字段级安全性、索引排序等兼容,在执行向量搜索之后还能再进行 ES 聚合操作。
POST my_vector_index/_search{"query": { // 可选,混合多路评分检索"match": {"name": "john"}},"knn": {"field": "my_vector_field","query_vector": [54, 10, -2],"k": 10,"num_candidates": 100,"query_vector_builder": { // 可选,调用模型进行Embedding"text_embedding": {"model_id": "sentence-transformers__msmarco-minilm-l-12-v3","model_text": "How is the weather in Jamaica?"}},"filter": { // 可选,前置过滤"term": {"file-type": "png"}}}"size": 100}
ES 的数据是以分片的形式散落在多台机器节点上的。向量搜索的流程如下:
1. 先在每个分片上查找 num_candidates 个近似最近邻候选者向量。
2. 计算这些候选向量与查询向量的相似度,从每个分片中选择 k 个最相似的结果。
3. 协调节点会归并每个分片的结果,以返回全局前 size 最终结果返回给用户。
所以,用户可以增加 num_candidates 以提升查询结果的准度,相应的,查询耗时也会增加,时间换取准度。如果您的查询还未做向量化,也可以在查询语句中指定已经上传好的大模型进行向量化再做查询。
优化实践
我们在支持客户的大型在线搜索业务的接入过程中,业务持续导入了超过亿条向量,并做了最终性能压测,ES 8.16.1 轻松扛住了最高十亿级向量,并且可以做到查询结果平均响应时延在毫秒级。下面我们会具体介绍该业务接入的优化实践。
1. 使用段合并大幅提升向量检索性能。
ES 的写入模型采用的是类似 LSM-Tree 的存储结构。ES 实时写入的数据都先放在 Lucene 内存 buffer 中,同时依赖写入 translog 保证数据的可靠性。当积攒到一定程度后,将他们批量写入一个新的段(Segment)。ES 对向量也是采用相同的处理方式,所以可以做到向量实时的插入跟检索。但这种方式,也会产生较多的小段,不同段之间的向量无法连接起来,导致查询效率低下。ES 会在集群运行过程中缓慢地持续进行底层段的 Merge,同时我们也建议业务在低峰期可以定期调度一些段合并(forcemerge)任务以减少底层段数量,实测至少可以提升向量检索性能3 - 5倍以上。
其压测采用的配置为:6台高 IO 型 SSD 节点,16核64G,亿级向量,96维。最终压测结果如下:
是否做段合并优化 | 优化前(30个段) | 优化后(2个段) |
查询 qps | 622 | 3112 |
查询平均延迟 | 307 ms | 81 ms |
需要注意的是 forcemerge 需要全量重新构建图索引,对资源占用比较高,建议可以在业务低峰期进行。ES 集群支持横向无限拓展,业务如果性能不满足还可以通过横向增加节点跟分片数提升 qps。
2. 使用 ES 8.16.1 同时调大 Merge 线程池,以提升 forcemerge 效率。
ES 8.16.1 相对于之前的版本,Lucene 对合并 HNSW 图进行了重大改进,会尽可能复用现有最大的 HNSW 图。因此,Lucene 不再像以前那样从一个空图开始,而是利用之前完成的所有工作来构建现有最大的段。合并较大的段时,这个改进带来的提升是巨大的。在基准测试中,段合并时间减少了40%。腾讯云 ES 自研内核新增合并策略,集群闲时自动 Merge 清理超过阈值的段,不影响集群整体性能的同时降低存储成本、提升查询性能。如果用户需要做forcemerge 的话,可以根据机器核数配置,调大 forcemerge 线程池配置来加速 forcemerge 过程。
thread_pool.force_merge.size: 8 // 初始默认值为2,比较小
云 ES 控制台上也支持用户设置定时任务做 forcemerge。
3. 尽量分配足够的 RAM 和高 IO 的硬盘。
ES 将向量数据存储在磁盘上,同时使用倒排索引来加速向量查询跟匹配,所以ES 将允许数据集大于本地主机上可用的 RAM 总量,但是随着页面缓存中可容纳的 HNSW 数据比例的降低,性能将会下降。注重性能的用户需要根据数据集的大小来调整 RAM 大小,同时选用高 IO 的硬盘,例如 SSD,以维持良好的查询性能。
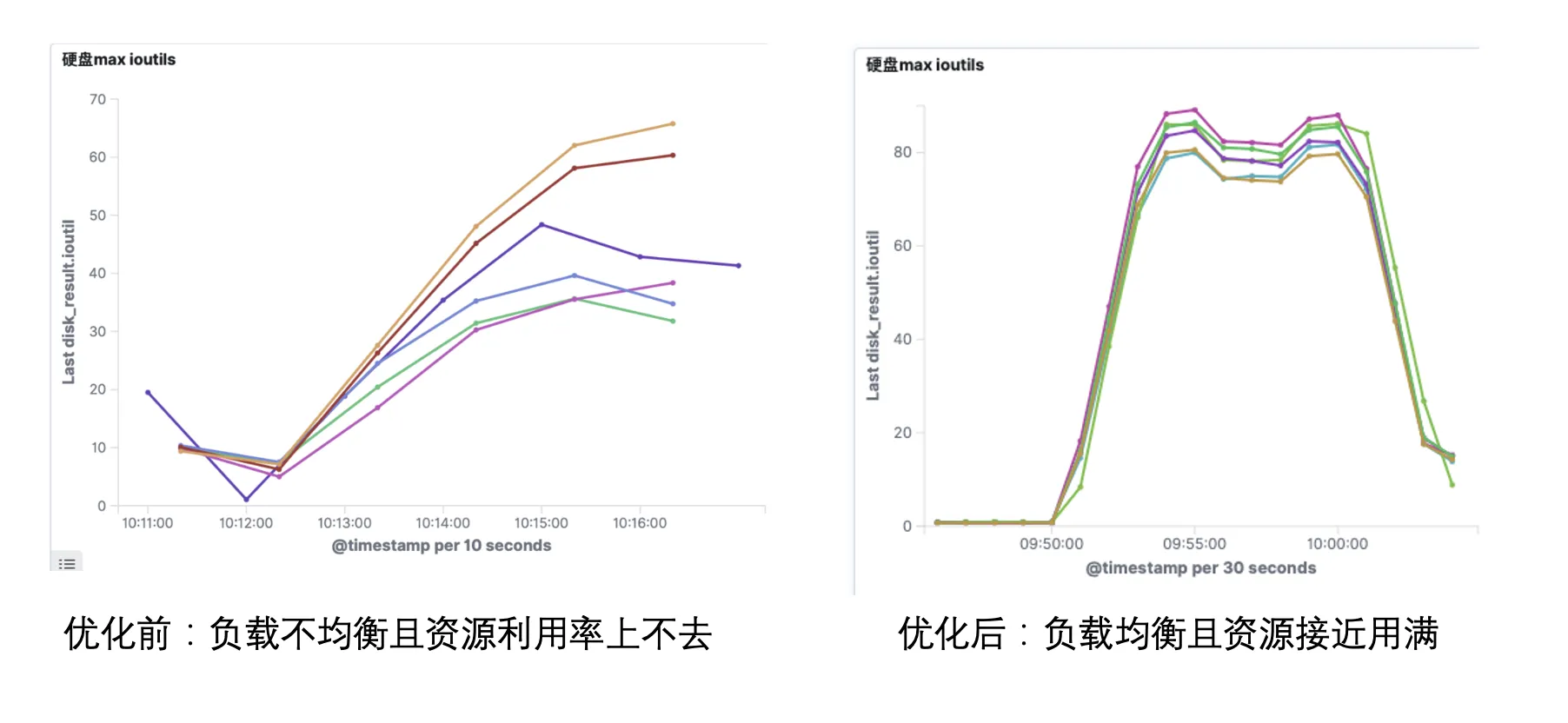
4. 分片数、ES 查询参数调优。
用户在性能压测过程中,遇到了压测负载上不去,负载不均等问题,我们通过对分片数、分发等 ES 查询参数进行调优,解决了这些问题。
5. 召回率测试。
我们基于不同 ef_construction 参数,跟暴力计算相对比来计算召回率,结果如下。
efConstruction | 100 | 200 | 500 |
top100 召回率 | >=96% | =100% | =100% |
top200 召回率 | >=94.5% | >99.9% | =100% |
top500 召回率 | >=90% | >=99.2% | >99% |
总结
腾讯云大数据 Elasticsearch Service 近期首发上线的 ES 8.16.1 版本,提供了强大的云端 AI 增强与向量检索能力,支持在端到端搜索与分析平台中实现自然语言处理、向量搜索以及与大模型的集成,10亿级向量检索平均响应延迟控制在毫秒级,助力客户实现由 AI 驱动的高级搜索能力,为搜索与分析带来全新的前沿体验。



