对于需要采集并分析腾讯云 TKE 容器日志的场景,可以使用 Filebeat 采集数据,并将采集的数据传输到腾讯云 Elasticsearch 集群中进行存储,如果需要加工与处理,也可以先将数据发送到腾讯云 Logstash 中进行过滤与预处理,最终可以在 Kibana 中查询并分析日志。本文介绍如何配置 Filebeat 采集部署在腾讯云的 TKE 容器日志。
应用场景
Filebeat 是一个轻量型的日志采集器,可以轻松地采集云上的 TKE 容器日志,从而使得查询或者分析业务服务端的日志变得简单。
Filebeat 能够逐行读取并发送日志,支持在出现中断的情况下,记录中断时读取到的文件位置信息,后续恢复正常后可以从中断前停止的位置继续开始。
Filebeat 非常适合采集 nginx、apache 以及容器服务的日志,并且提供可以直接引用的配置模板,极大的简化了这类服务的日志采集过程。
操作须知
腾讯云 TKE 实例、腾讯云 ES 集群和 Logstash 实例,必须在同一 VPC 下,且腾讯云 ES 集群和 Logstash 实例的大版本相同。
TKE集群需要是运行中状态且为标准集群。
操作步骤
Filebeat 采集器配置
1. 登录 Elasticsearch Service 控制台 Beats 管理界面,授权服务相关角色,在 Filebeat 采集器选择 TKE 日志采集。
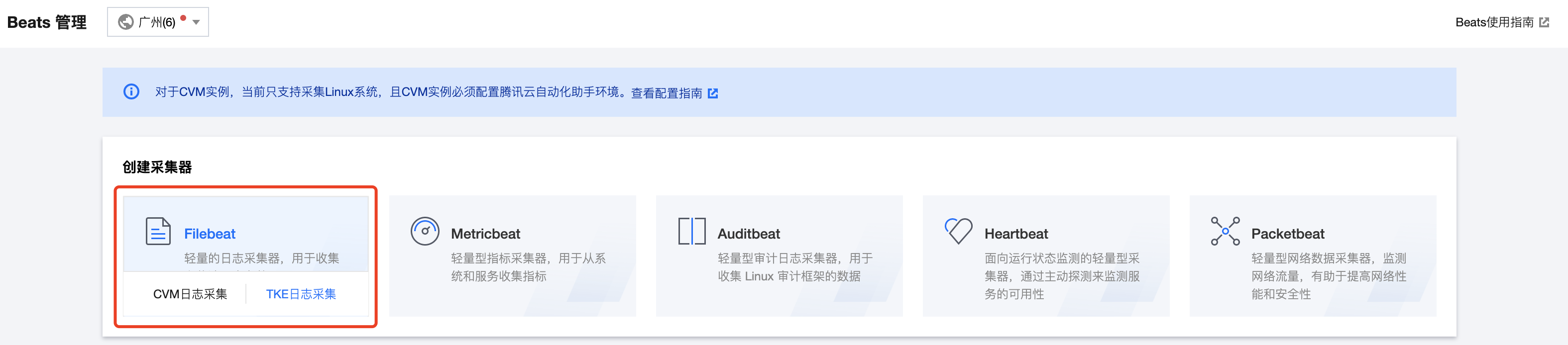
2. 在创建 Filebeat 采集器中,设置采集器相关信息。
2.1 第一步,选择输出目的:
采集器名称:必填。自定义采集器的名称。
安装版本:必选。支持6.8.21、7.10.2、7.14.0、7.17.1,安装版本需要和采集器输出的大版本相同。
采集器输出:必选。采集的数据支持传送到腾讯云 Elasticsearch 集群与 Logstash 实例,请选择与需采集数据的 TKE 在同一 VPC 下的 ES 集群和 Logstash 实例。不支持输出至开源版 ES 集群。
用户名密码:必填。若选择输出采集数据到开启用户登录认证的 ES 集群,需要填写用户名和密码,使得 Filebeat 有权限向 ES 集群中写入数据。用户名默认为 elastic,密码为集群创建时设置。
启用 Monitoring:可选。勾选后生成监控 Filebeat 的相关指标。当采集器输出为 ES 集群时,Monitoring 默认使用和采集器输出相同的 ES 集群;当采集器输出为 Logstash 实例时,则需要在配置文件中额外添加用于存储监控数据的 ES 集群地址。
启用 Kibana Dashboard:可选。勾选后生成默认的 Kibana Dashboard。
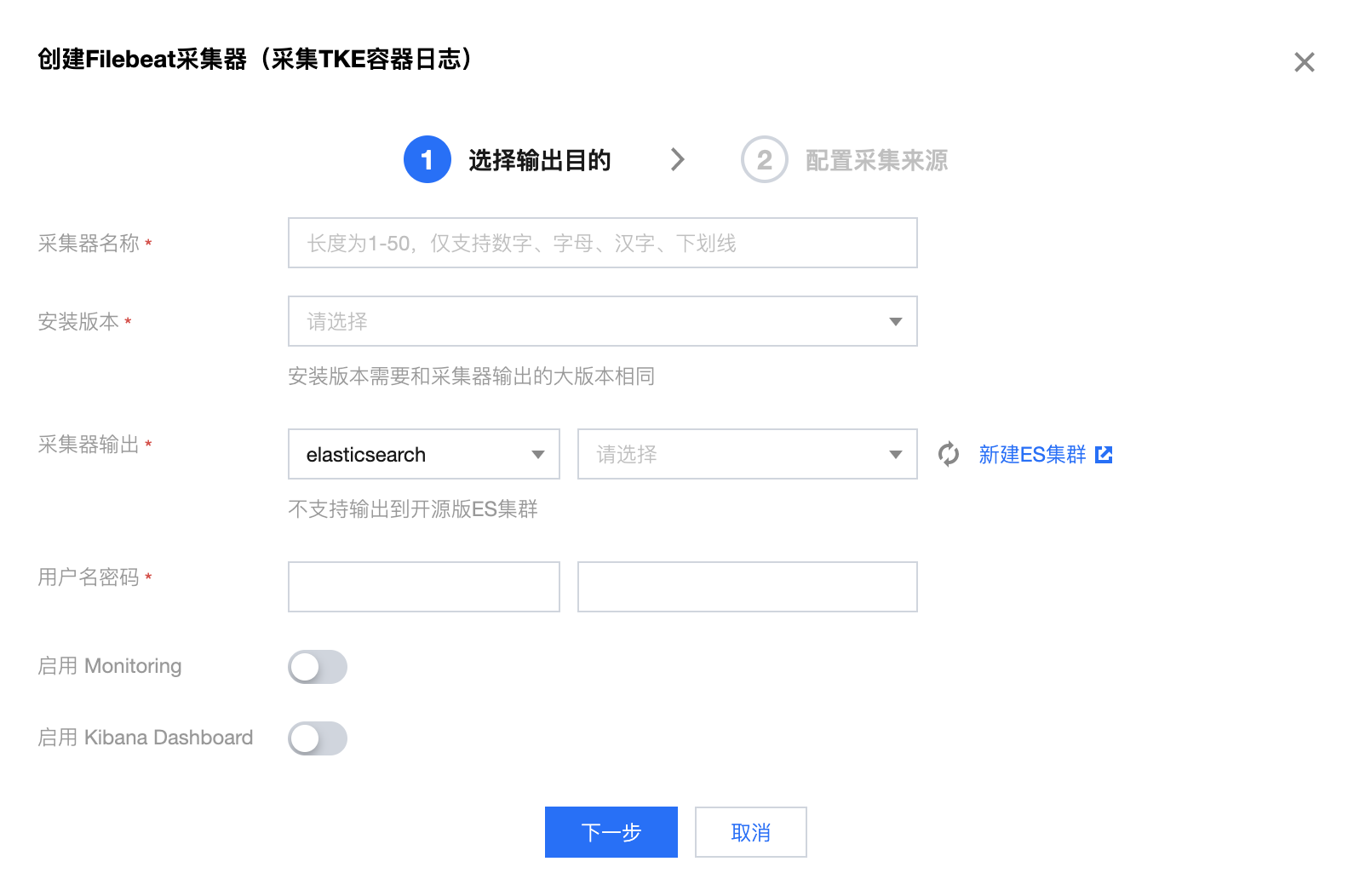
2.2 第二步,配置采集来源:
所在私有网络 VPC:默认使用上一步采集器输出选择的实例的 VPC,且不可更改。
待采集 TKE 集群 ID:必选。需采集的 TKE 集群的 ID,TKE 集群需要是运行中状态且为标准集群。
采集配置:可通过单击添加来横向增加更多采集配置,上限10个。
采集配置名称:必填。
命名空间:必选。第一个下拉可选择 包含/不包含。第二个下拉可选择命名空间,支持多选,不支持选择不包含全部命名空间。
Pod 标签:选填。支持创建多个 Pod 标签,标签之间是逻辑与关系。
容器名称:选填。填写的容器名称必须在采集目标集群及命名空间之下,为空时,Filebeat 会采集命名空间下符合 Pod 标签的全部容器。
写入的索引名称前缀:选填。写入的索引名称前缀将作为 ES 索引名称的一部分,例如替代 filebeat-%{[index]}-%{+yyyy.MM.dd}中的 index 。
日志内容过滤:选填。根据关键字过滤日志,可填多个关键字,以逗号分隔。
高级采集配置:选填。个性化设置解析方式、过滤等,一般采用默认配置,详情请参见 配置文件填写参考。
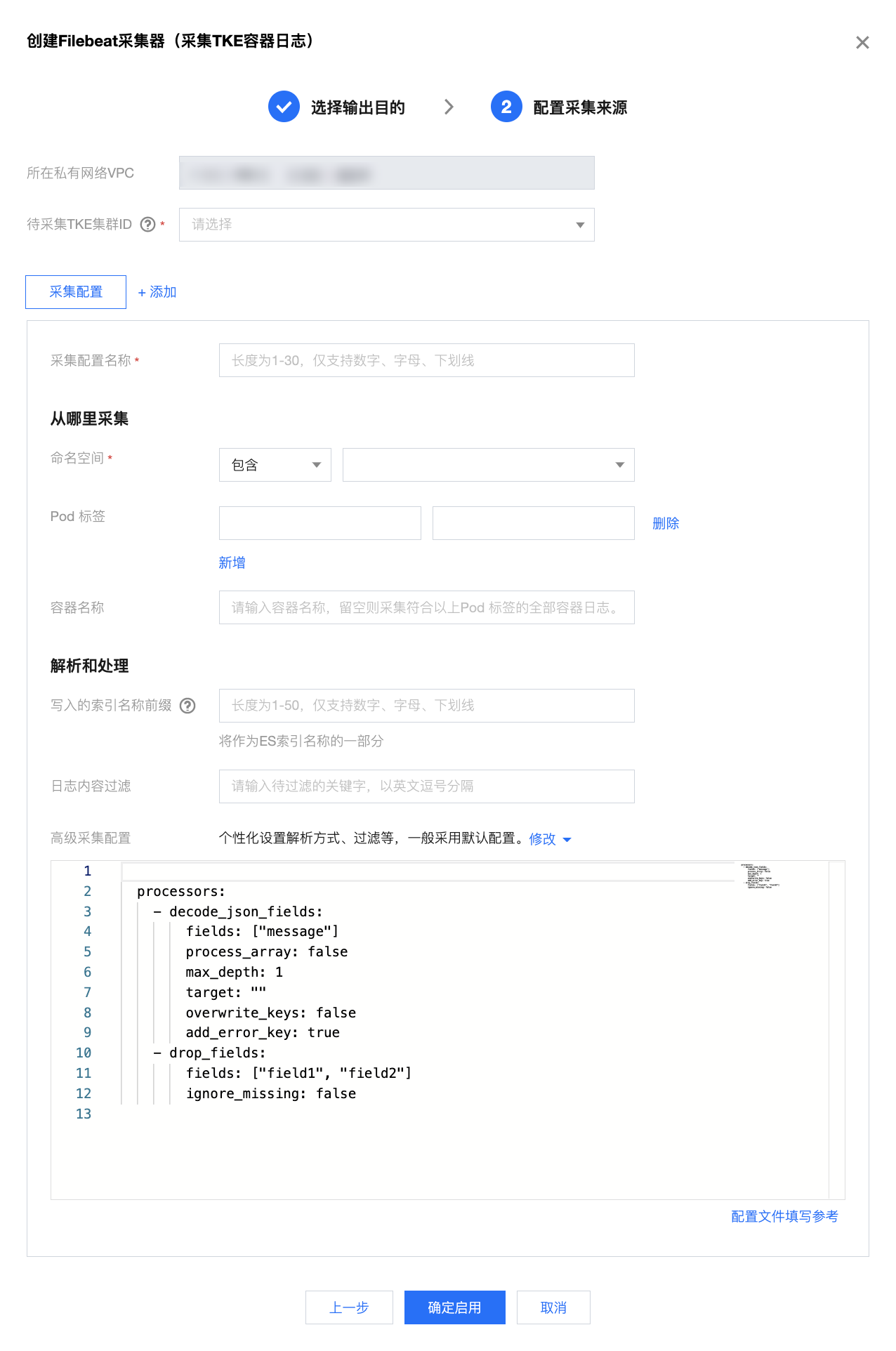
3. 单击确定启用后,跳转到 Beats 采集器管理界面,可以查看 Filebeat 采集器运行状态,显示“正常”则表示采集器安装成功。
Logstash 管道配置
Kibana 查看结果
1. 登录腾讯云 Elasticsearch Service 的 Kibana 控制台。
2. 左侧导航栏单击 Dev Tool,执行下述语句,查看采集成功的数据。
GET filebeat-7.10.2/_search



