ES 提供了多种灵活的方式将向量数据写入系统,无论您已有预计算的向量还是需要在写入中实时生成向量。本文将详细介绍各种写入方式。
方式1:直接写入已计算好的向量
如果您已经有预计算的向量(如通过外部 Python 脚本或模型服务生成),可以直接写入这些向量。
//单条文档写入PUT /book-index/_doc/1{"id": "1001","category":"小说","price":10,"title_text": "百年孤独","title_vector": [0.1, 0.2, 0.3 ...],"content_text": "马孔多小镇和布恩地亚家族的兴衰变化与传奇故事","content_vector": [0.5, 0.6, 0.7, ... ]}//批量写入POST /_bulk{ "index": { "_index": "book-index", "_id": "2" } }{ "id": "1002","category":"历史","price":20,"title_text": "人类简史", "title_vector": [0.1, 0.2, 0.3 ...], "content_text": "人类从认知革命到科技革命的发展史", "content_vector": [0.1, 0.2, 0.3, ...]}{ "index": { "_index": "book-index", "_id": "3" } }{ "id": "1003","category":"科幻","price":30,"title_text": "三体", "title_vector": [0.8, 0.7, 0.6 ...], "content_text": "人类文明和宇宙社会学法则", "content_vector": [0.1, 0.2, 0.3, ...]}
方式2:通过 Ingest Pipeline 自动生成向量
1. 创建 ingest pipeline
依据前面创建的文本嵌入模型推理服务,可以创建一个 Ingest Pipeline,用于写入过程的 embedding处理:
PUT /_ingest/pipeline/text-embedding{"description": "Text embedding pipeline","processors": [{"inference": {"model_id": "bge-base-zh","ignore_missing": true, // 忽略缺失的输入字段"input_output": [{"input_field": "title_text","output_field": "title_vector"},{"input_field": "content_text","output_field": "content_vector"}]}}]}
说明:
ingest pipeline中的model_id的取值,如果是通过机器学习节点部署的,直接取机器学习节点的model_id参数的值,如果是通过_inference端点,可以取_inference端点名称。两者同时建立了的话则都可以使用,其背后对应的是同一个模型的推理,只是前者直接访问模型推理,后者通过_inference端点推理。
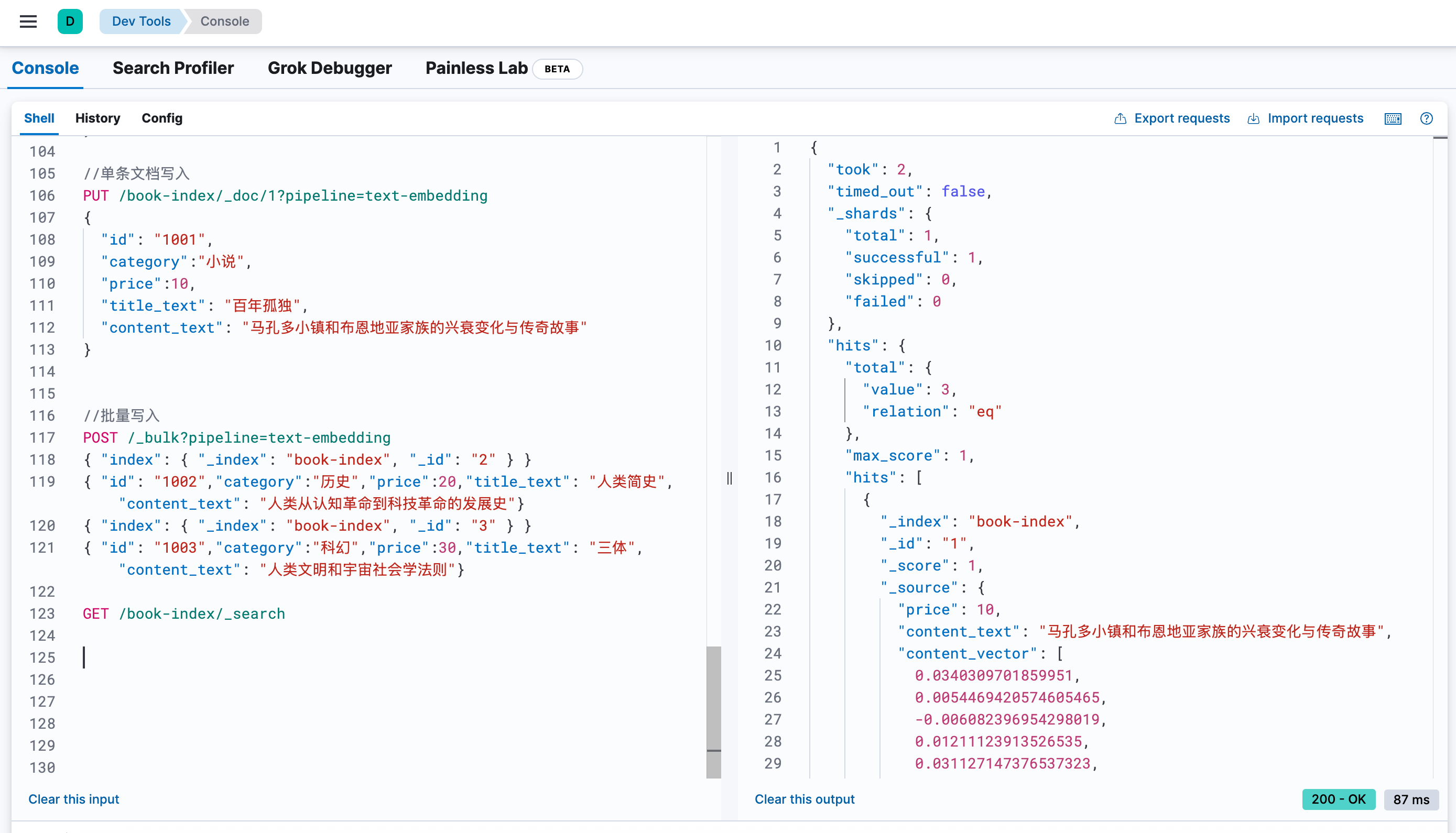
2. 写入数据
写入数据时只需要写入标量数据,ingest pipeline中的模型推理服务将自动生成向量数据。
//单条文档写入PUT /book-index/_doc/1?pipeline=text-embedding{"id": "1001","category":"小说","price":10,"title_text": "百年孤独","content_text": "马孔多小镇和布恩地亚家族的兴衰变化与传奇故事"}//批量写入POST /_bulk?pipeline=text-embedding{ "index": { "_index": "book-index", "_id": "2" } }{ "id": "1002","category":"历史","price":20,"title_text": "人类简史","content_text": "人类从认知革命到科技革命的发展史"}{ "index": { "_index": "book-index", "_id": "3" } }{ "id": "1003","category":"科幻","price":30,"title_text": "三体", "content_text": "人类文明和宇宙社会学法则"}
通过 GET /book-index/_search查看写入结果,向量已经自动生成了: