通过机器学习节点运行推理服务,您可以获得高性能、低延迟的模型推理能力,同时享受 Elasticsearch 生态的完整集成优势。
核心优势
GPU加速:腾讯ES自研了英伟达和国产GPU(例如GPU 加速的支持),推理效率可提升30倍。
生态集成:与Elasticsearch的数据采集、向量检索生态无缝集成。
模型支持:ES 机器学习节点目前支持文本嵌入, 重排, 命名实体识别、分类等多种模型。详情参见
创建步骤
1. 创建机器学习节点
如果您尚未创建ES集群,可以在创建集群时开启“机器学习节点”,如果您已经创建了ES集群,可以通过“调整配置”开启“机器学习节点”。

注意,针对不同的模型,您需要预留足够的内存空间,例如:
.multilingual-e5-small 需至少8GB内存
bge-base-zh-v1.5 需要至少16GB内存
bge-m3 需要至少32GB内存
选择 GPU 可以支持更高的推理效率,同时拥有更低的推理成本。
2. 部署模型推理服务
进入集群详情页,切换到“模型管理”:
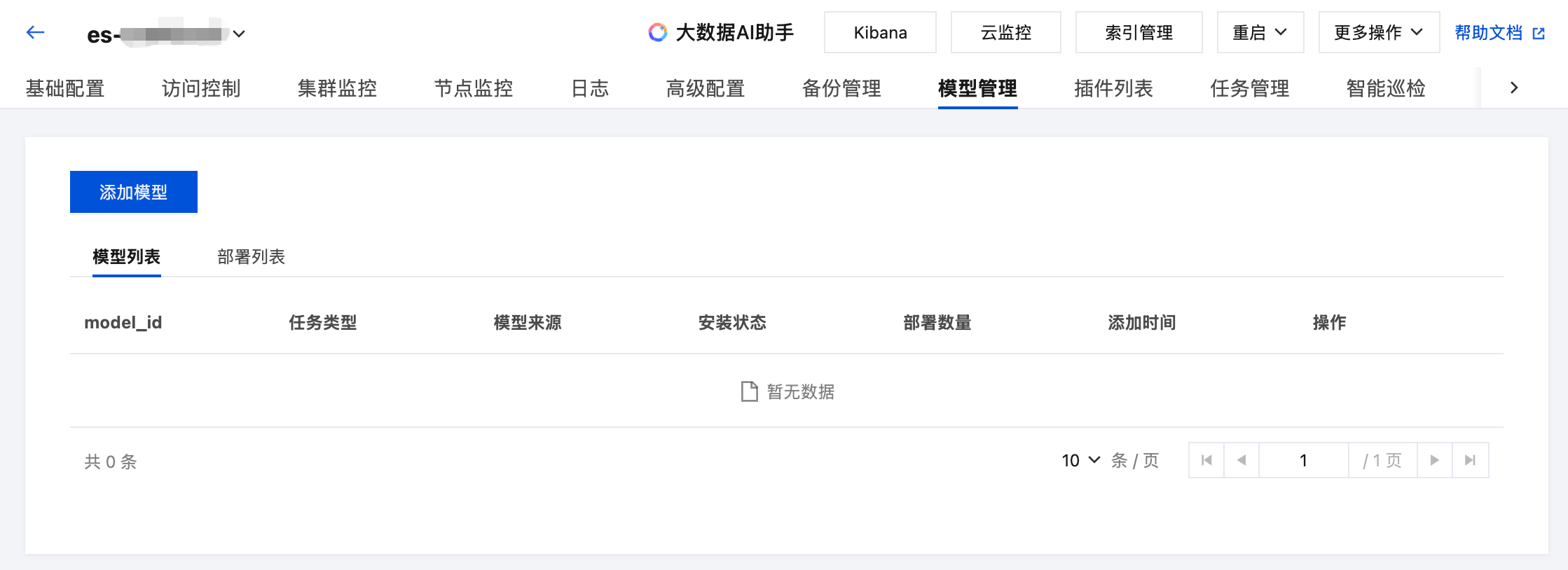
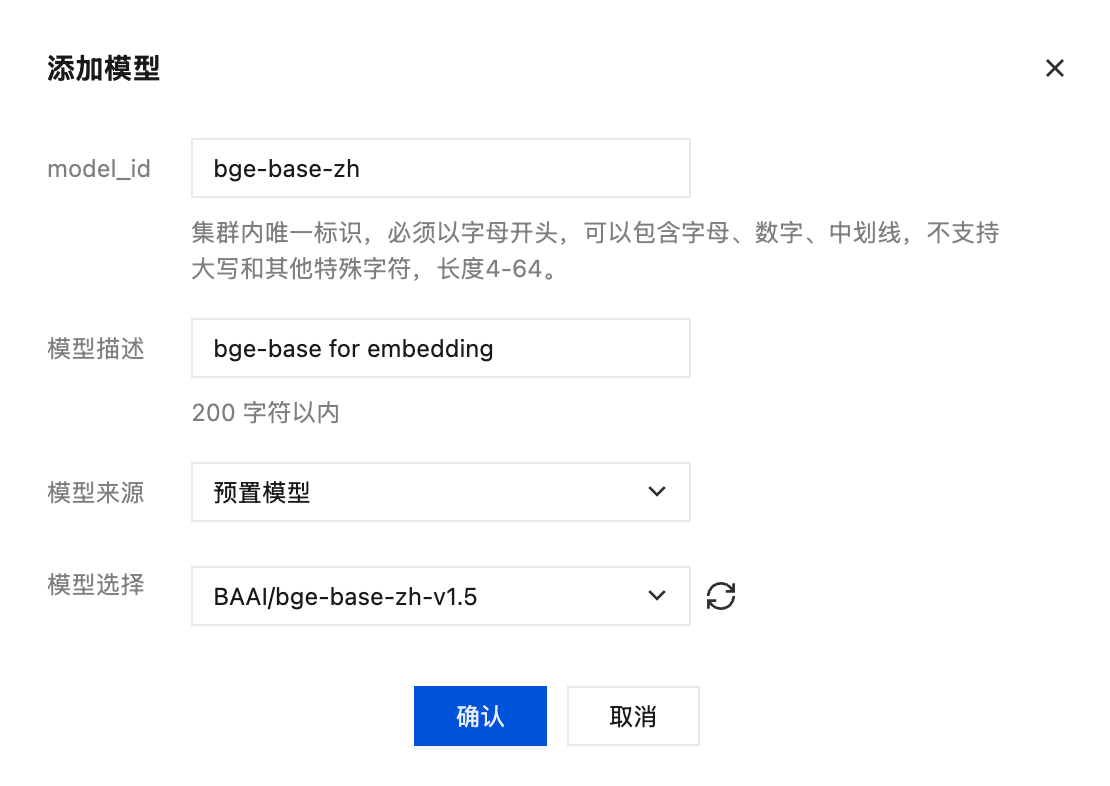
单击添加模型,可以从预置模型中选择:
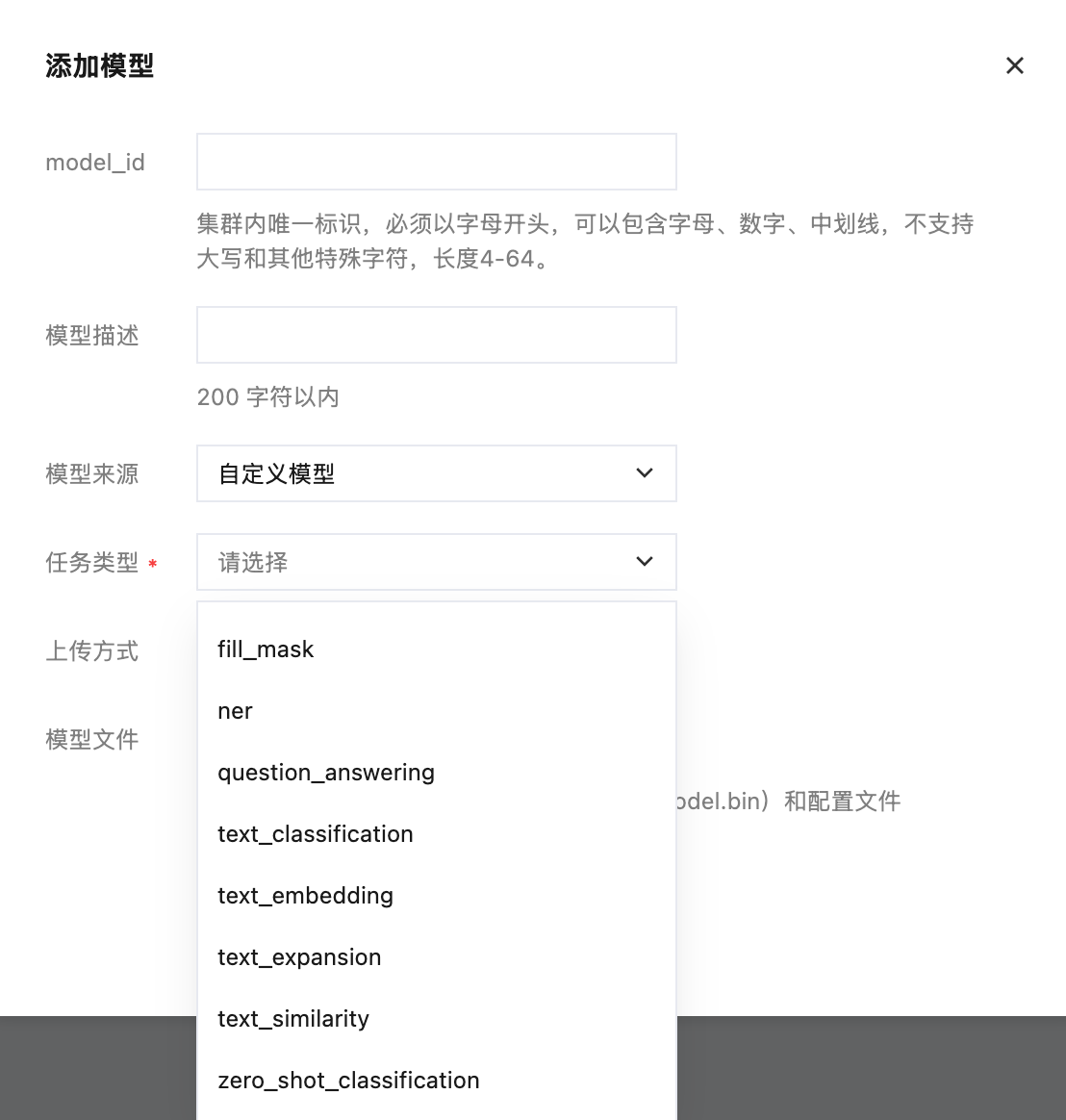
也可以上传自定义模型:
安装完成状态如下:
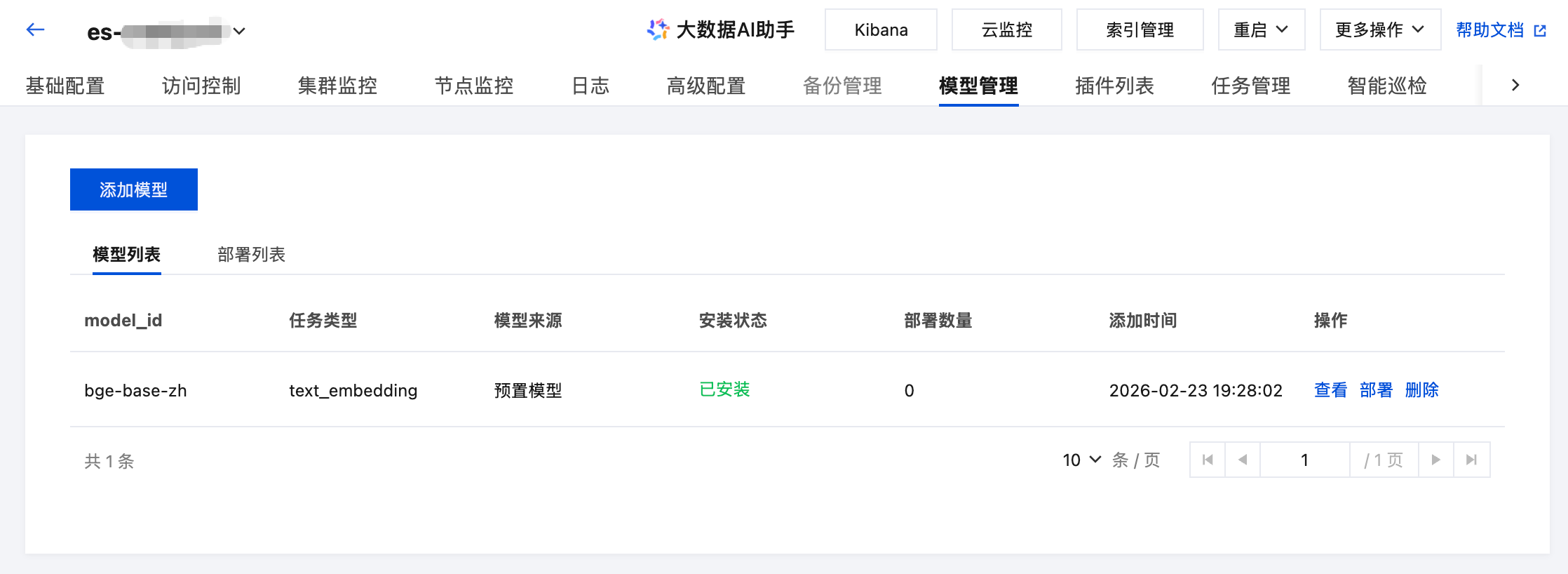
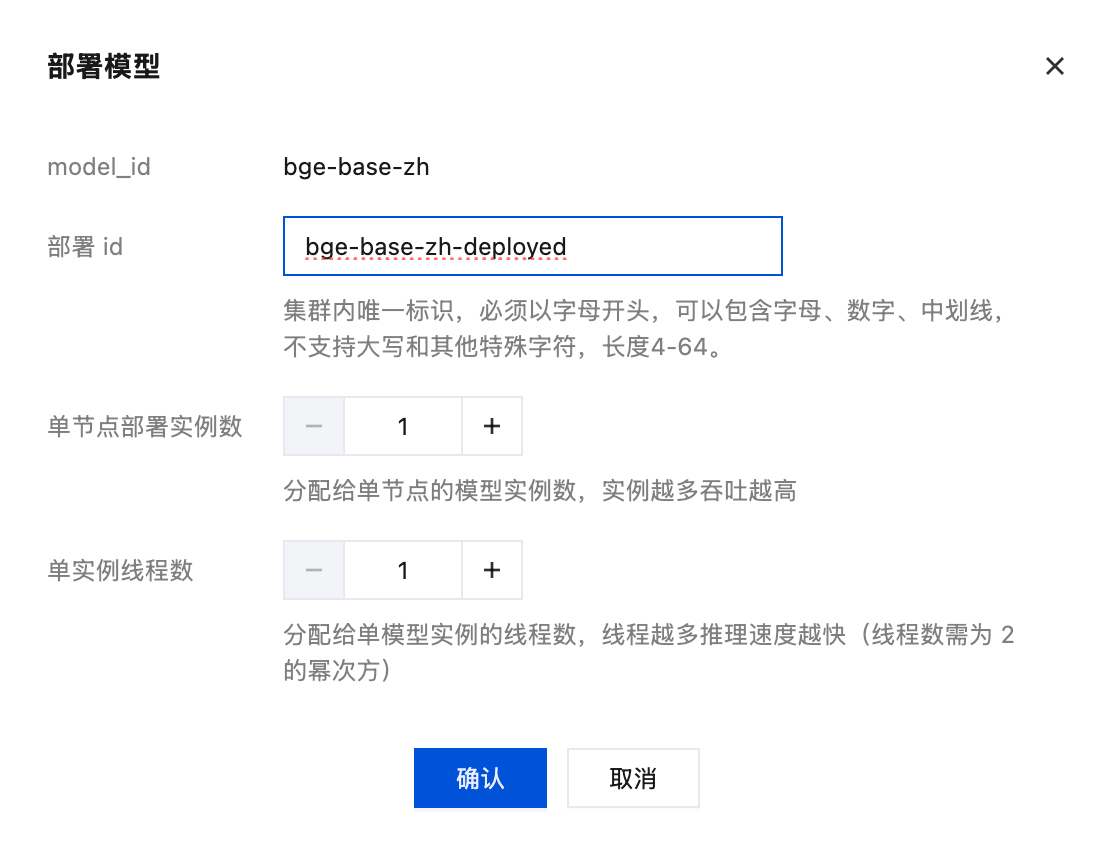
模型安装完成后,单击部署进行模型部署:
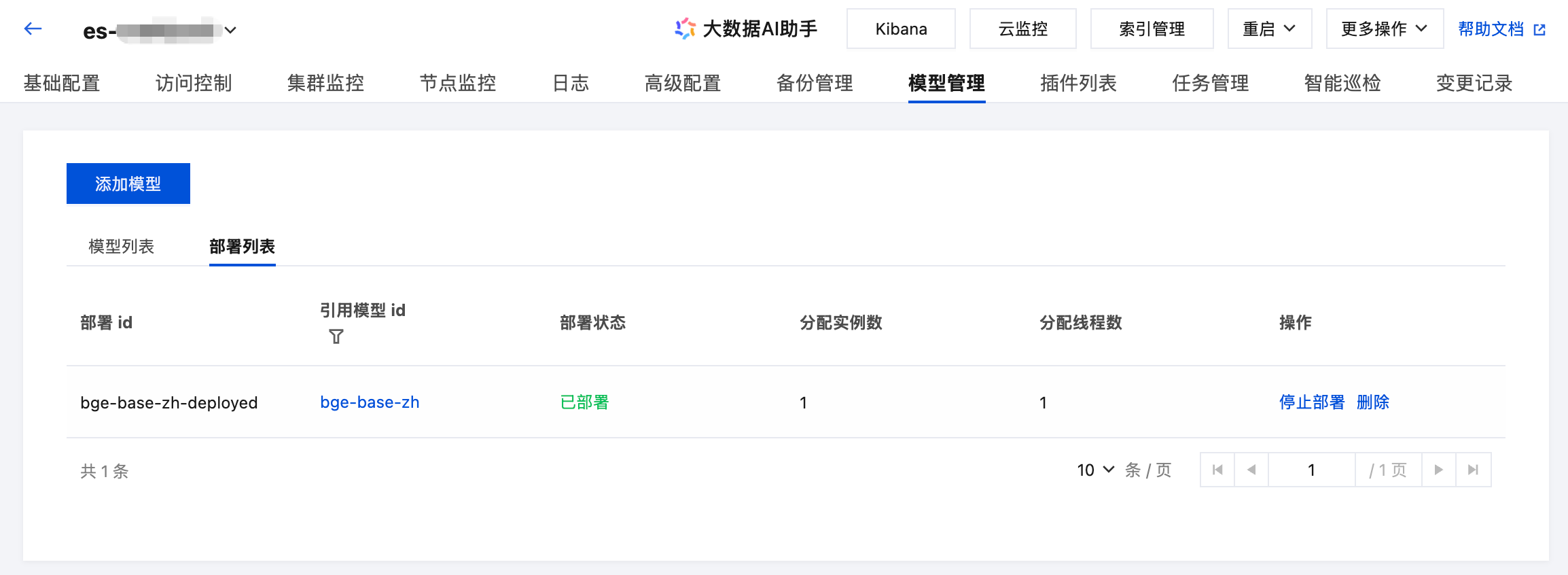
切换到“部署列表”查看模型部署状态:
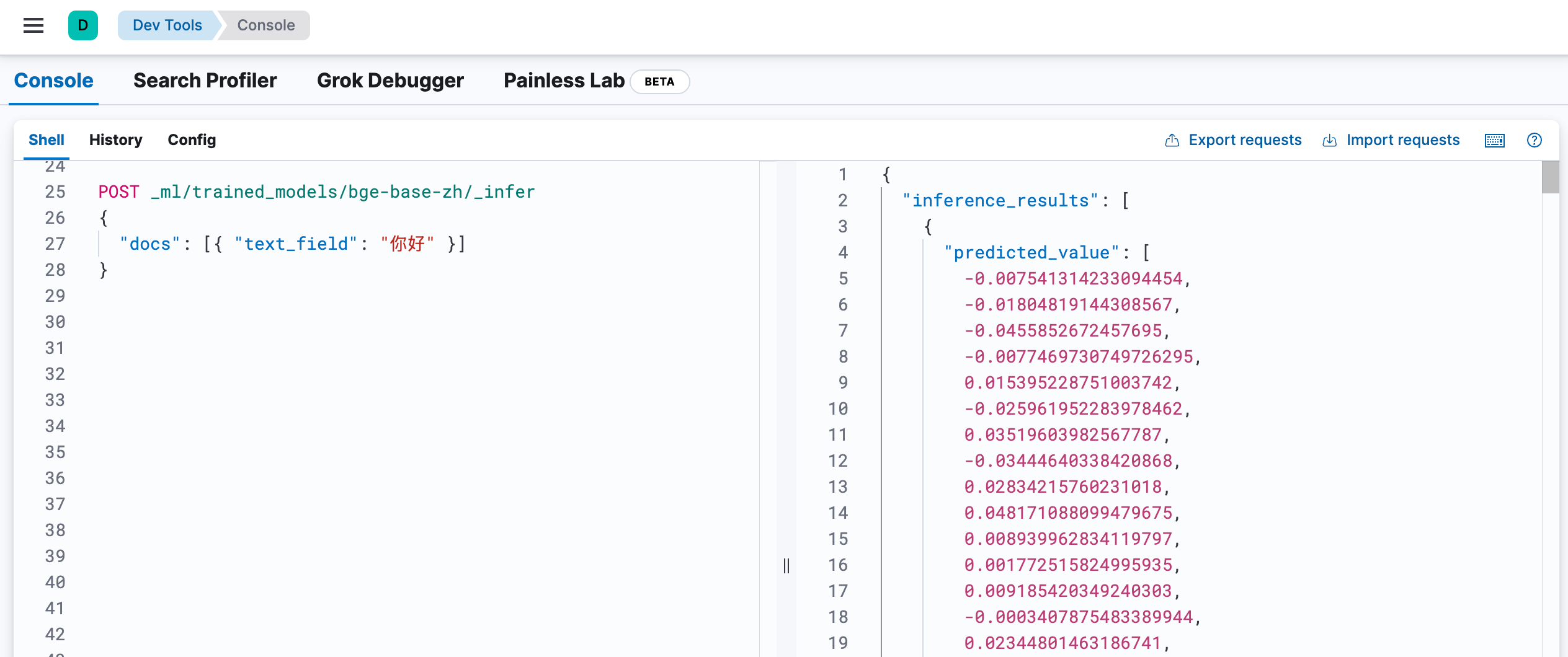
3. 测试推理服务
可以在 Kibana 的 Dev Tools 中测试如下:
POST _ml/trained_models/bge-base-zh/_infer{"docs": [{ "text_field": "你好" }]}
4. 创建推理端点(此步骤非必须)
如果您是在 ES 内部通过ingest pipeline调用模型服务,不需要创建推理端点,如果您希望通过inference API调用推理服务(例如semantic搜索等),可以参考下面方式创建推理端点。
PUT _inference/text_embedding/bge-base-zh-service{"service": "elasticsearch","service_settings": {"model_id": "bge-base-zh","num_allocations": 1,"num_threads": 1}}
创建推理端点后,可以调用_inference进行测试:
POST _inference/text_embedding/bge-base-zh-service/_infer{"input": "你好"}
机器学习节点监控和运维
您可以通过节点监控查看机器学习节点指标情况,根据负载情况及时对机器学习节点进行扩缩容。