应用场景
日志分析,例如 Web 日志、App 日志、数据库日志、服务器指标、网络指标、存储指标等, 这些场景的特点一般是写多读少、成本敏感。
版本特色
关键词:更高的写入性能,更低的成本。
采用存算分离、写入加速、查询/IO 并行化等亮点思想和技术,降低存储成本,提升写入性能。(推荐存算分离架构,也可以使用传统的热温架构,客户可根据实际业务按需选择)
在运维效率上,自治索引能实现索引创建、滚动、降冷、删除、故障自动修复的全自动化,并实现分片的智能调优,大幅减少了运维故障和资源投入。
说明:解决的主要问题
在存储方面,用户为了保证稳定性一般会设置2 - 3个副本,如果使用云盘,云盘底层也会存储3个副本,在存储上有较大冗余。
在计算方面,由于 ES 的主副分片都会解析文档、分词、索引等,所以主副本之间也存在重复计算和重复写入的问题。
另外,原生架构存储与计算耦合,数据和计算在同一台节点,资源无法独立弹性扩缩容,在集群扩缩的时候会涉及大量的数据搬迁,不仅耗时比较长,也非常浪费资源。
关键特性
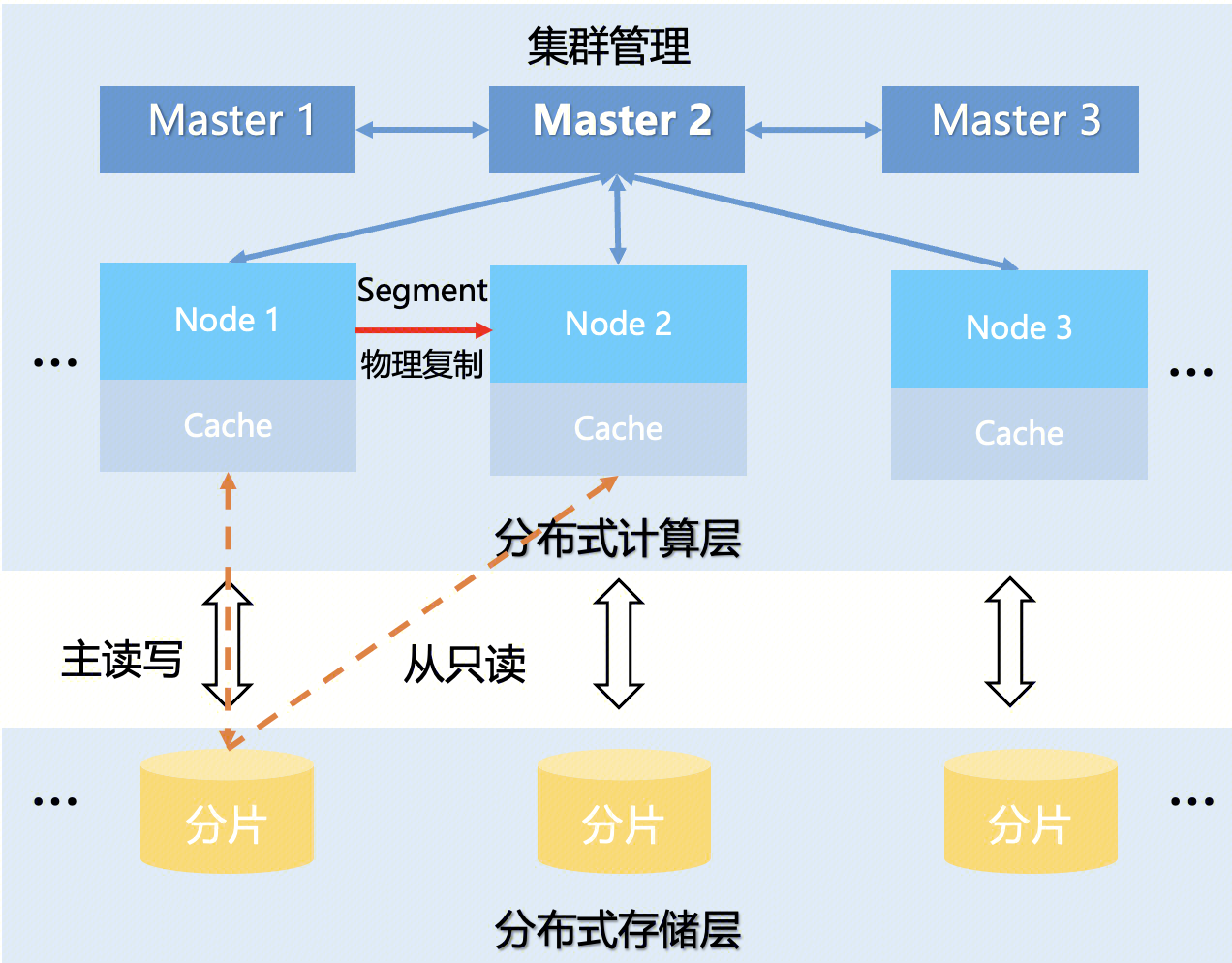
存算分离
存算分离的核心思路是基于物理复制消除副本冗余计算,并确保主从副本分片完全一致,同时采用 delta + base 架构,本地 SSD 扛高并发写入并承载 Merge 计算开销,合并好较大的数据文件实时下沉至海量的对象存储,基于对象存储实现高可用,同时相比云盘大幅降低存储成本。缓存模块同时对高频访问数据进行缓存,降低对象存储的访问频次。针对对象存储和本地磁盘访问性能差异,采用 IO 并行化技术结合多级缓存实现冷热一体混合搜索能力。
写入加速
写入加速的核心思想是基于内存 segment 消除副本冗余计算、网络开销、锁的争抢等,ES 写入数据时最终是通过 Lucene 写入到内存中,一段时间后 refresh 成 segment。我们可以在协调节点提前通过 Lucene 的 API 构建好 segment 并保存在内存中,然后把内存 segment 转发给具体索引分片,索引分片收到内存 segment 后定时追加到 Lucene 中,通过 segment 内存生成和拷贝,内存 merge,自定义 merge policy、定向路由等亮点思想和技术,提升写入吞吐3 - 5倍。
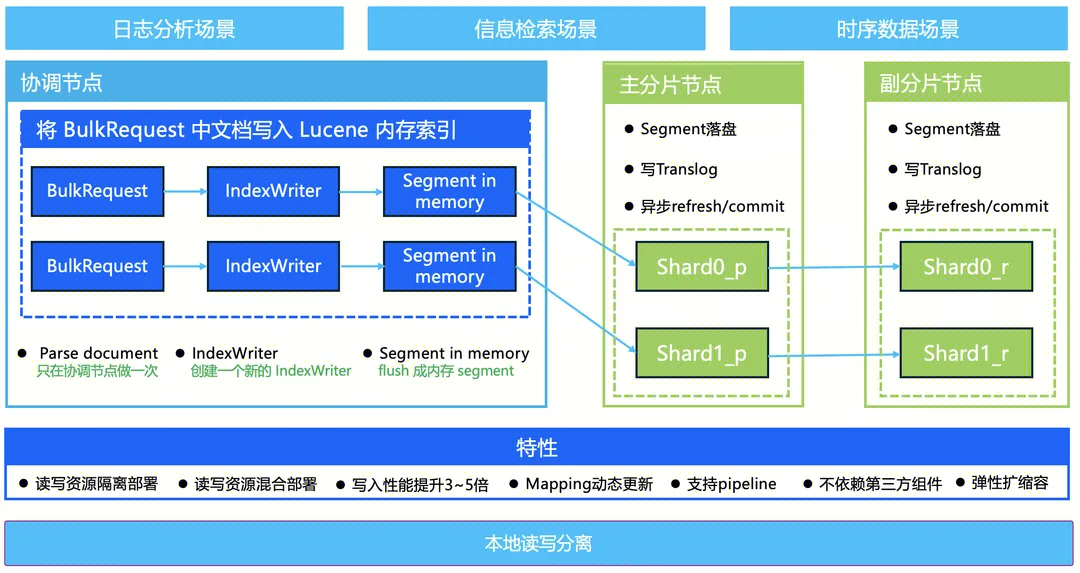
这里的写入加速优化可以理解为本地读写分离,或单一集群读写分离架构,协调节点实现 segment 内存构建并物理拷贝至主从副本。集群可以按读写分区节点部署,也可以混合部署。
说明:
读写分区部署:将集群中部分节点设置为专属协调节点,由专属协调节点提供写入计算能力,适合提升写入性能的同时更关心资源隔离的场景。
读写混合部署:集群中每台节点都提供写入计算能力,对比分区部署的优点是有更多的节点提供写入计算能力,写入性能提升更多,适合只提升写入性能不关心资源隔离场景。
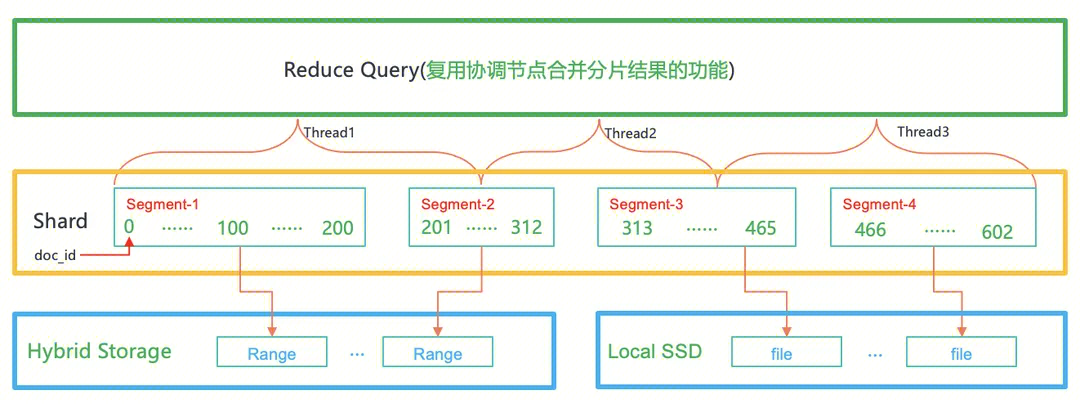
查询/IO 并行化
ES 查询模型是将查询请求拆分成分片级的子请求转发给各个分片执行,最后在协调节点合并各个分片的结果,在每个分片内部有多个 segment,默认情况下 ES 执行分片级查询时是单线程串行处理每个 segment 的,由于分片内的 segment 是独立的,可以尝试再拆分几个子请求,由多个线程并行处理,在数据节点合并多个线程的结果后再返回给协调节点,在数据节点合并每个线程的结果跟在协调节点合并每个分片的结果道理是相同的。该方案意在压榨空闲 CPU 资源,将 ES 的单个分片级请求拆分成3 - 5个子请求并行处理该分片下的 segment 或者 docs,根据 docs 或者 segment 切分,每个线程只处理一部分 docs 或者 segment,在数据节点合并每个线程的结果后再返回给协调节点,协调节点合并各个分片的结果返回给客户端,从而达到性能倍数级的提升。
效果测试
整体效果
腾讯云 ES 全新技术栈:采用存算分离、写入加速和查询/IO 并行化等先进技术,广泛应用于日志场景,实现冷热数据一体化搜索及弹性伸缩能力,成本可降低30% - 50%,最优情况下相比云盘可降低 80%。
存算分离:自研混合存储架构,实现冷热一体搜索,存储成本节约30% - 50%。
写入加速:无依赖、自闭环,读写资源隔离的同时提升 3+倍写入吞吐。
查询/IO 并行化:自研多级并行查询框架,支持全部查询场景,查询性能提升3 - 5倍。
性能压测
存算分离
压测环境:
集群:3台标准型 SA2 16核64G,1500GB SSD 云硬盘 x 1。
数据:http_logs。
工具:esrally。
压测结果:
从查询性能损耗可以看出,以本地盘为基准,Elastic 自研的 可搜索快照 查询性能损耗太大了,日志增强版自研的存算分离相较于本地盘查询性能损耗,仍在可接受的范围内,增加并行化压测后大部分场景比本地还要快2 - 3倍。(查询延时单位:ms)
查询类型 | 本地 SSD 盘 | 可搜索快照 | 存算分离 | 存算分离 + 并行化 |
match_all(全部匹配) | 3 | 59 | 3 | 4 |
term(单值精确匹配) | 6 | 71 | 16 | 7 |
terms(多值精确匹配) | 5 | 45 | 4 | 5 |
range(范围查询) | 12 | 28 | 23 | 9 |
aggs(聚合查询) | 1544 | 2575 | 2020 | 580 |
desc_sort_timestamp(按时间字段降序) | 65 | 187 | 81 | 33 |
asc_sort_timestamp(按时间字段升序) | 71 | 256 | 54 | 8 |
desc_sort_with_after_timestamp(降序排序中增加search_after) | 1140 | 1863 | 1968 | 440 |
asc_sort_with_after_timestamp(升序排序中增加search_after) | 936 | 1692 | 1389 | 395 |
写入加速
压测环境:
集群:3台标准型 SA2 16核64G,1500GB SSD 云硬盘 x 1。
数据:随机生成。
工具:编写代码消费 Kafka。
压测结果:
写入类型 | 副本 | 批次大小 | 写入性能 | 说明 |
ES 默认 | 1 | 5000 | 31w/s | 默认 ES 的写入性能 |
写入加速 | 1 | 5000 | 119w/s | ES 的3.8倍 |
查询/IO 并行化
压测环境:
集群:3台标准型 SA2 16核64G,1500GB SSD 云硬盘 x 1。
数据:geonames。
工具:esrally。
并发度:IO 并行化并发度设置为3。
压测结果:
IO 并行化并发度设置为3,性能普遍提升3倍左右,经过压测对比发现,P50,P90,P99耗时普遍减少5 - 10倍,查询抖动更少更稳定。
如果 CPU 核数更多,拆分的子请求可以更多,性能会更好,如果将并发度设置为5,理论上性能会提升5倍左右。
类别 | 短语查询(ms) | 聚合查询(ms) | 脚本查询(ms) | 自定义打分(ms) | 排序(ms) |
关闭并行化 | 43 | 43 | 374 | 408 | 143 |
打开并行化 | 5 | 4 | 132 | 125 | 44 |



