对一行日志进行处理,包括过滤、分发、分裂等函数。
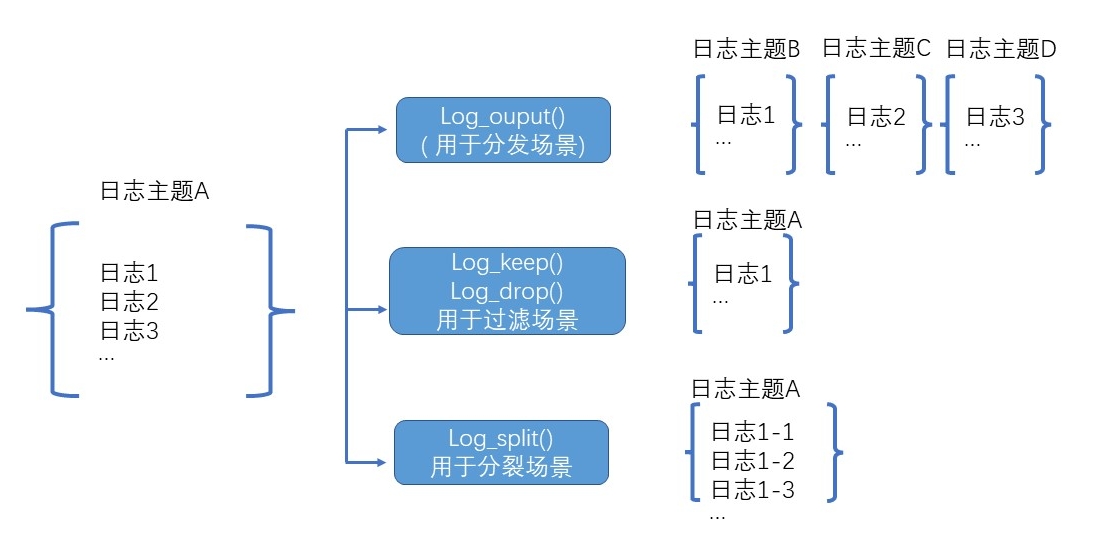
log_output 函数
函数定义
输出到指定的目标主题。可以配合分支条件使用,也可以单独使用。
语法描述
log_output(别名 Alias)
别名在配置加工任务时定义,如下图所示:
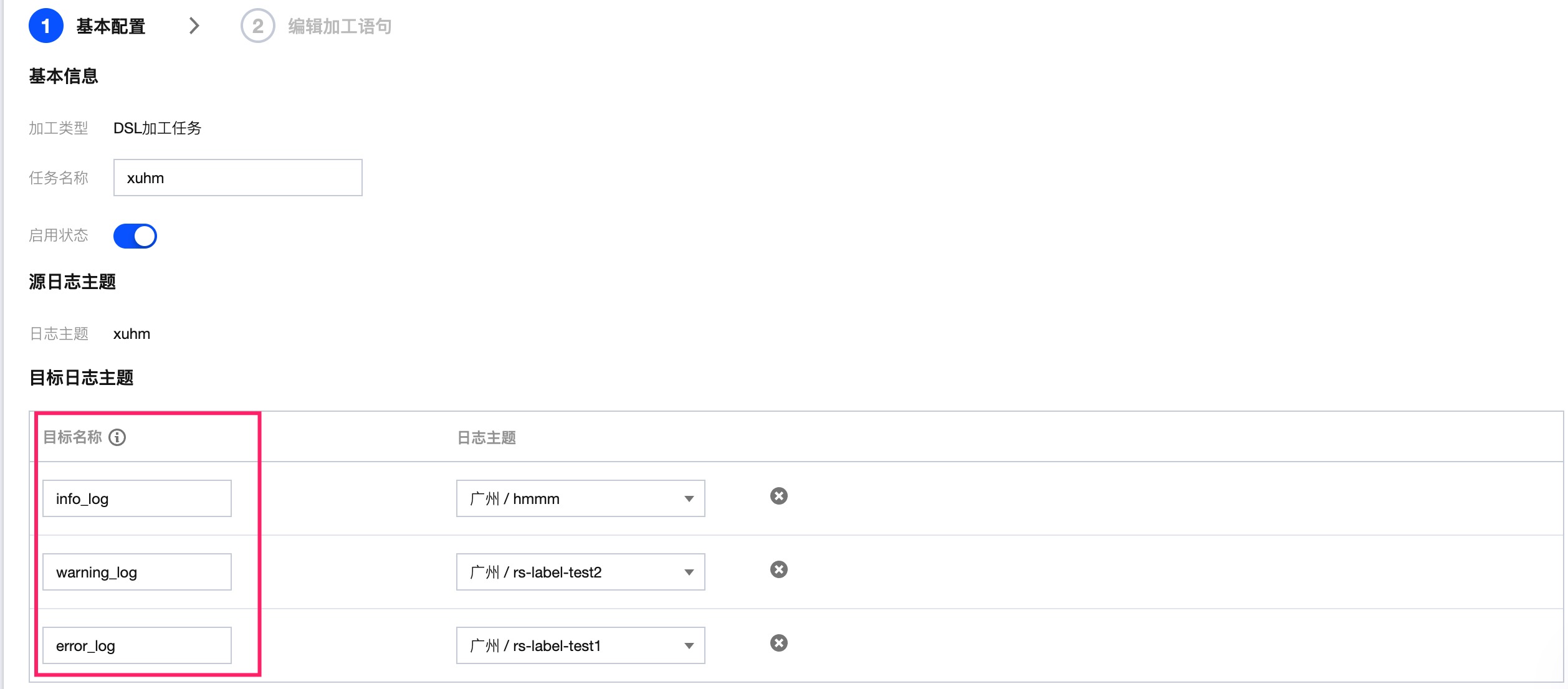
参数说明
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
alias | 目标主题的别名 | string | 是 | - | - |
示例
按照 loglevel 字段值为 waring/info/error 的情况,分发到三个不同的日志主题中。
原始日志:
[{"loglevel": "warning"},{"loglevel": "info"},{"loglevel": "error"}]
加工规则:
//按照loglevel字段值为waring/info/error的情况,分发到三个不同的日志主题中。t_switch(regex_match(v("loglevel"),regex="info"),log_output("info_log"),regex_match(v("loglevel"),regex="warning"),log_output("warning_log"),regex_match(v("loglevel"),regex="error"),log_output("error_log"))
加工结果:如下图所示

log_auto_output 函数
函数定义
将日志输出到动态的目标主题。例如您需要根据日志字段"pd"的值,动态创建多个目标日志主题,并将对应的日志分发至目标日志主题。假设 pd 的值为"CLB "、"Ckafka"、"COS"、"CDN",使用该函数,将会动态创建出名为"CLB "、"Ckafka"、"COS"、"CDN"的目标日志主题,并将相关的日志写入对应的主题,同时,您可对这些新建主题的索引类型、存储周期进行配置。
语法描述
log_auto_output(topic_name="", logset_name="", index_options="", period=3,storage_type=" ",hot_period=0)
参数说明
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数 默认值 | 参数说明 |
topic_name | 日志主题名称 | string | y | - | 参数 topic_name 中包含"|","|"将在生成的主题名称中被去除。 参数 topic_name 长度超出250字符,生成的日志主题名称仅有前250个字符,超出的会被截断。 |
logset_name | 日志集名称 | string | y | - | - |
index_options | all_index:开启键值、全文索引 no_index:不开启索引 content_index:开启全文 key_index:开启键值索引 | string | n | all_index | 如果 storage_type=cold,即低频存储,则 all_index 和 key_index 不会生效,即低频存储不支持键值索引。 |
period | 存储周期,一般取值范围是1 - 3600 天, 3640 代表永久存储 | number | n | 3 | 1 - 3600天。 |
storage_type | 日志主题的存储类型,可选值 hot:标准存储 cold:低频存储 | string | n | hot | 当为 cold 时,period 最小为7天。 |
hot_period | 0:关闭日志沉降 非0:开启日志沉降后标准存储的天数 HotPeriod 需要大于等于7,且小于 Period,仅在 StorageType 为 hot 时生效 | number | n | 0 | - |
tag_dynamic | 为日志主题添加动态标签,和 extract_tag() 函数配合使用,用于从日志字段中提取标签的 KV,例如:tag_dynamic=extract_tag(v("pd"),v("env"),v("team"), v("person")) | string | n | - | 和 tag_static 一起不超过10对标签。 |
tag_static | 为日志主题添加静态标签,例如:tag_static="Ckafka:test_env,developer_team:MikeWang" | string | n | - | 和 tag_dynamic 一起不超过10对标签示例。 |
注意:
修改 log_auto_output() 函数中的参数,并重启任务之后,仅对新生成的主题生效,已生成的主题不受影响。如您需要对已经生成日志集、日志主题进行修改,请前往 日志主题列表 或调用 API 进行修改。
在不修改 log_auto_output() 函数的前提下,您修改数据加工任务动态创建的主题名称、兜底日志集名称、兜底日志主题名称之后,数据分发逻辑不受影响。例如加工任务已动态创建日志主题“Nginx”,您将其改名为“Nginx001”,数据还是会写入这个“Nginx001”主题,而不会新创建一个叫做“Nginx”的日志主题。
删除数据加工任务(动态创建主题),不会删除已创建的日志集和日志主题。
示例
原始日志:
[{"pd": "CLB","dateTime": "2023-05-25T00:00:26.579"},{"pd": "Ckafka","time": "2023-05-25T18:00:55.350+08:00"},{"pd": "COS","time": "2023-05-25T00:06:20.314+08:00"},{"pd": "CDN","time": "2023-05-25T00:03:52.051+08:00"}]
加工规则:
log_auto_output(v("pd"),"我的日志集",index_options="content_index", period=3)
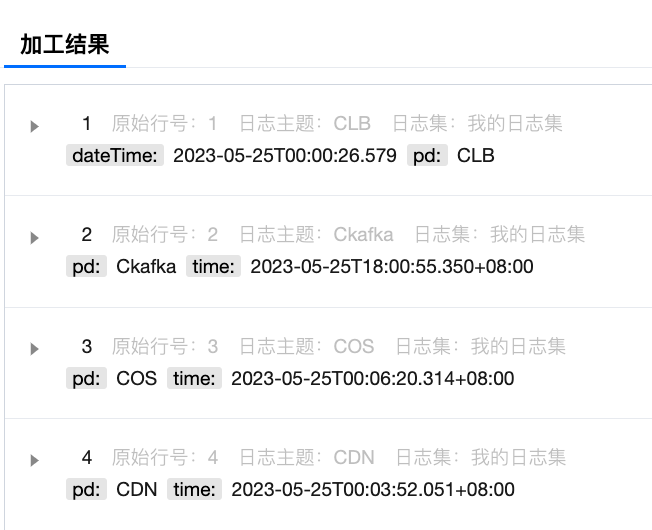
加工结果:自动生成了四个日志主题,分别是"CLB "、"Ckafka"、"COS"和"CDN",日志集名称为"我的日志集",如下图所示:
特殊情况处理
创建日志主题
特殊场景 | 处理逻辑 |
参数 topic_name 获取失败或者为""(空字符串),该行日志将进入名称为"null"的日志主题 | 例如指定 app 字段的值为 topicname,即日志主题名称,但某行日志中没有 app 字段,或者其值为" ",那么该行日志将写入名称为“null”的日志主题,“null”主题所属日志集,是本函数的日志集参数中指定的日志集。 说明: 如果您使用了字符串拼接来指定日志主题名称,例如 log_auto_output( str_join("-", "myPrefix", v("app")), "myLogSet",period=14,storage_type="hot",hot_period=10),那么当 app 不存在或者值为" "时,日志将写入名称为“myprefix”的日志主题。 |
重名主题(同一日志集下) | 已存在名为“Nginx”的日志主题,动态创建任务根据规则,也要创建名为“Nginx”的日志主题时,会加上 CreateByCLSETL 后缀,创建出的日志主题名为“Nginx-CreateByETL”。 |
创建日志集
特殊场景 | 处理逻辑 |
重名日志集(同一地域) | 如您手动创建名为“myLogSet”的日志集,动态创建任务根据函数规则也要创建名为“myLogSet”的日志集时,会自动加上 CreateByCLSETL 为后缀。 如果自动创建任务1,创建出来的日志集名称为“myLogSet”,自动创建任务2同样定义了日志集名称为“myLogSet”,此时自动创建任务2会使用同一个日志集名称“myLogSet”作为目标日志集,即不会再自动创建带有 CreateByCLSETL 后缀的日志集。 |
注意:
日志集和日志主题名称,不区分英文大小写,abc 和 Abc 在 CLS 侧代表同一个资源。
日志主题添加标签
特殊场景 | 处理逻辑 |
动态标签的 KV 值获取失败 | 例如指定 A 字段的值为标签的 Key,B 字段的值为标签的 Value,但某行日志没有 A 字段或者 B 字段,或者 A 字段 B 字段的值为空,标签添加失败。 |
标签的 KV 值前后有空格 | 标签添加失败。 |
动态标签和静态标签的总数超过10对 | 动态标签优先级较高,如添加完动态标签后,还不足10对,补充静态标签,但总个数不超过10对。 |
标签 KV 的长度超出限制 | 标签的 key 长度大于127,value 的长度大于255,标签添加失败。 |
说明:
如果您在 POC 时需要反复重建同名加工任务,其流程如下:
1. 先删除老的数据加工任务,否则还会持续生成日志主题。
2. 删除兜底主题 auto_undertake_topic_${etl-task-name} ,如果连续3次创建同名任务,超限兜底主题会创建失败,进而阻塞任务正常启动。
如果 POC 的数据是同一套,不是实时数据,建议删除老任务已经生成的日志集和日志主题。
log_split 函数
函数定义
使用分隔符结合 jmes 表达式,对特定字段进行拆分,拆分结果分裂为多行日志。
语法描述
log_split(字段名, sep=",", quote="\\", jmes="", output="")
参数说明
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 待提取的字段名 | string | 是 | - | - |
sep | 分隔符 | string | 否 | , | 任意单字符 |
quote | 将值包括起来的字符 | string | 否 | - | - |
jmes | 说明: 如果 jmes 中包含了特殊字符,例如 . \\ * + ? ^ $ | () [] {} - /时,需要加上转义符。 | string | 否 | - | - |
output | 单个字段名 | string | 是 | - | - |
示例
示例1:字段中有多个值的日志分裂
{"field": "hello Go,hello Java,hello python","status":"500"}
加工规则:
//使用分割符“,”,将日志分隔成三条。log_split("field", sep=",", output="new_field")
加工结果:
{"new_field":"hello Go","status":"500"}{"new_field":"hello Java","status":"500"}{"new_field":"hello python","status":"500"}
示例2:利用 JMES 对日志进行分裂。
{"field": "{\\"a\\":{\\"b\\":{\\"c\\":{\\"d\\":\\"a,b,c\\"}}}}", "status": "500"}
加工规则:
//a.b.c.d节点的值为“a,b,c”log_split("field", jmes="a.b.c.d", output="new_field")
加工结果:
{"new_field":"a","status":"500"}{"new_field":"b","status":"500"}{"new_field":"c","status":"500"}
示例3:包含有 JSON 数组的日志分裂。
{"field": "{\\"a\\":{\\"b\\":{\\"c\\":{\\"d\\":[\\"a\\",\\"b\\",\\"c\\"]}}}}", "status": "500"}
加工规则:
log_split("field", jmes="a.b.c.d", output="new_field")
加工结果:
{"new_field":"a","status":"500"}{"new_field":"b","status":"500"}{"new_field":"c","status":"500"}
log_drop 函数
函数定义
丢弃符合条件的日志。
语法描述
log_drop(条件1)
参数说明
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
condition | 值为 bool 类型的函数表达式 | bool | 是 | - | - |
示例
丢弃 status=200的日志,其余保留。
原始日志:
[{"field": "a,b,c","status": "500"},{"field": "a,b,c","status": "200"}]
加工规则:
log_drop(op_eq(v("status"), 200))
加工结果:
{"field":"a,b,c","status":"500"}
log_keep 函数
函数定义
保留符合条件的日志。
语法描述
log_keep(条件1)
参数说明
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
condition | 值为 bool 类型的函数表达式 | bool | 是 | - | - |
示例
保留 status=500的日志,其余丢弃。
原始日志:
[{"field": "a,b,c","status": "500"},{"field": "a,b,c","status": "200"}]
加工规则:
log_keep(op_eq(v("status"), 500))
加工结果:
{"field":"a,b,c","status":"500"}
log_split_jsonarray_jmes 函数
函数定义
将日志根据 Jmes 语法将 JSON 数组拆分和展开。
语法描述
log_split_jsonarray_jmes("field", jmes="items", prefix="")
参数说明
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 待提取的字段名 | string | 是 | - | - |
示例
示例1
原始日志:
{"common":"common","result":"{\\"target\\":[{\\"a\\":\\"a\\"},{\\"b\\":\\"b\\"}]}"}
加工规则:
log_split_jsonarray_jmes("result",jmes="target")fields_drop("result")
加工结果:
{"common":"common", "a":"a"}{"common":"common", "b":"b"}
示例2
原始日志:
{"common":"common","target":"[{\\"a\\":\\"a\\"},{\\"b\\":\\"b\\"}]"}
加工规则:
log_split_jsonarray_jmes("target",prefix="prefix_")fields_drop("target")
加工结果:
{"prefix_a":"a", "common":"common"}{"prefix_b":"b", "common":"common"}



