日志服务(Cloud Log Service,CLS)数据加工函数可以自由组合,来完成日志的清洗、结构化、过滤、分发、脱敏等场景。
如下图是一条含有 JSON 的日志,经过数据加工处理之后,变成结构化数据、然后对某个字段值进行脱敏、最后分发的流程。
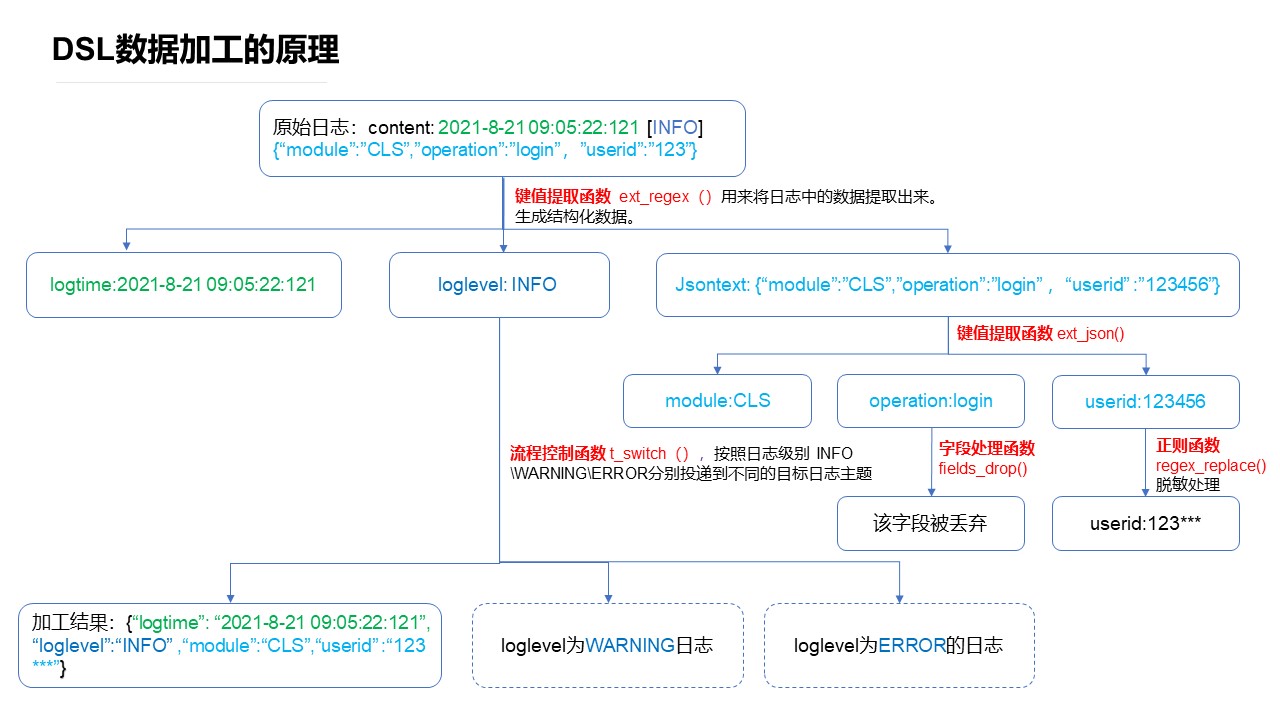
函数概览
键值提取函数类
从日志文本中提取字段/字段值。
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
基于分隔符提取字段值内容 | ext_sep("源字段名", "目标字段1,目标字段2,目标字段...", sep="分隔符", quote="不参与分割的部分", restrict=False, mode="overwrite") | 返回提取后的日志(LOG) | |
基于指定字符(串)提取字段值内容 | ext_sepstr("源字段名","目标字段1,目标字段2,目标字段...", sep="abc", restrict=False, mode="overwrite") | 返回提取后的日志(LOG) | |
提取 JSON 字符串格式的字段值 | 返回提取后的日志(LOG) ext_json("源字段名",prefix="",suffix="",format="full",exclude_node="不平铺的JSON节点") | 返回提取后的日志(LOG) | |
使用 Jmes 表达式提取字段值 | ext_json_jmes(“源字段名”, jmes= "提取JSON的公式", output="目标字段", ignore_null=True, mode="overwrite") | 返回提取后的日志(LOG) | |
基于两级分割符提取字段值 | ext_kv("源字段名", pair_sep=r"\\s", kv_sep="=", prefix="", suffix="", mode="fill-auto") | 返回提取后的日志(LOG) | |
基于正则表达式提取字段值 | ext_regex(“源字段名”, regex="正则表达式", output=“目标字段1,目标字段2,目标字段.......”, mode="overwrite") | 返回提取后的日志(LOG) | |
返回参数中第一个非 null 且非空字符的结果值 | ext_first_notnull(值1, 值2, ...) | 返回参数中第一个非 null 结果值 | |
基于 grok 语法提取匹配结果值 | ext_grok(字段值, grok="", extend="") | 返回提取后的日志(LOG) |
富化函数类
在已有字段的基础上,根据规则新增字段。
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
使用 csv 结构数据对日志中的字段进行匹配。当值相同时,可以将 csv 中的其他字段和值,添加到源日志中 | enrich_table(“csv 源数据”, “csv 富化字段”, output=“目标字段1,目标字段2,目标字段....”, mode="overwrite") | 返回映射后的日志(LOG) | |
使用 Dict 结构对日志中的字段值进行匹配。当指定的字段的值和 Dict 中的 Key 相同时,将此 Key 对应的 Value 赋值给日志中的另一字段 | enrich_dict(“JSON 字典”, "源字段名", output=目标字段, mode="overwrite") | 返回映射后的日志(LOG) | |
与目标表格进行映射,根据输入的字段名称返回字段值,可简单理解为日志和维度表关联。 | t_table_map(data, field, output_fields, missing=None, mode="fill-auto") | 返回映射后的日志(LOG) |
流程控制函数类
由于条件判断。
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
组合操作函数,类似于分支代码块的组合能力,可以组合多个操作函数,并按顺序执行,可以结合分支、输出函数使用 | compose("函数1","函数2", ...) | 返回日志(LOG) | |
对符合条件的日志,进行相应的函数处理,否则不进行任何处理 | t_if("条件", 函数) | 返回日志(LOG) | |
对不符合条件的日志,进行相应的函数处理,否则不进行任何处理 | t_if_not("条件",函数) | 返回日志(LOG) | |
基于条件判断,分别进行不同的函数处理 | t_if_else("条件", 函数1, 函数2) | 返回日志(LOG) | |
基于多分支条件,分别进行不同的函数处理,如果存在不符合所有条件的数据,将被丢弃 | t_switch("条件1", 函数1, "条件2", 函数2, ...) | 返回日志(LOG) |
行处理函数类
用于日志的分发、丢弃、拆分。
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
输出到指定的目标主题。可以配合分支条件使用,也可以单独使用 | log_output(日志主题别名),该参数在新建数据加工任务时,目标日志主题别名处配置 | 无返回,对目前的数据流进行输出 | |
将日志输出到动态的目标主题。例如您需要根据日志字段"pd"的值,动态创建多个目标日志主题,并将对应的日志分发至目标日志主题。 | log_auto_output(topic_name="", logset_name="", index_options="", period=3,storage_type=" ",hot_period=0) | 无返回,对目前的数据流进行输出 | |
使用分隔符结合 Jmes 表达式,对特定字段进行拆分,拆分结果分裂为多行日志 | log_split(字段名, sep=",", quote="\\", jmes="", output="") | 返回日志(LOG) | |
丢弃符合条件的日志 | log_drop(条件1) | 返回日志(LOG) | |
保留符合条件的日志 | log_keep(条件1) | 返回日志(LOG) | |
将日志根据 Jmes 语法将 JSON 数组拆分和展开 | log_split_jsonarray_jmes("field", jmes="items", prefix="") | 返回日志(LOG) |
字段处理函数
用于字段的增删改查、重命名。
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
为动态生成的主题打标签。从日志字段中提取标签值,并将这些标签值作为动态生成主题的标签 | extract_tag(标签名1,标签值1,标签名2,标签值2....) | 返回日志(LOG) | |
根据字段名进行匹配,删除匹配到的字段 | fields_drop(字段名1, 字段名2, ..., regex=False,nest=False) | 返回日志(LOG) | |
根据字段名进行匹配,保留匹配到的字段 | fields_keep(字段名1, 字段名2, ..., regex=False) | 返回日志(LOG) | |
根据正则表达式来匹配字段名,并将匹配到的字段打包到新的字段,新字段值使用 JSON 格式进行组织 | fields_pack(目标字段名, include=".*", exclude="", drop_packed=False) | 返回日志(LOG) | |
用来设置字段值,或者增加新字段 | fields_set(字段名1, 字段值1, 字段名2, 字段值2, mode="overwrite") | 返回日志(LOG) | |
字段重命名 | fields_rename(字段名1, 新字段名1, 字段名2, 新字段名2, regex=False) | 返回日志(LOG) | |
字段存在时,返回 True,否则返回 False | has_field(字段名) | 返回条件值(BOOL) | |
字段不存在时,返回 True,否则返回 False | not_has_field(字段名) | 返回条件值(BOOL) | |
获取字段值,返回对应字符串 | v(字段名) | 返回值字符串类型(STRING) |
字典和列表函数
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
获取列表(数组)的值 | array_get(数组,下标位置) | 返回值字符串类型(STRING) | |
JSON 中新增节点 | json_add(key,data) | 返回值字符串类型(STRING) | |
增加/删除/修改字典中的键值对 | json_edit("result", path="", key="",value="333",index=1,mode="edit") | 返回 dict | |
通过 Jmes 表达式,提取 JSON 字段值,并返回 Jmes 提取结果的 JSON 字符串 | json_select(v(字段名), jmes="") | 返回值字符串类型(STRING) | |
JSON 中增加 KV 对 | json_update(json值, key1, value1,key2, value2) | 返回值字符串类型(STRING) | |
解析 XML 值并转换为 JSON 字符串,输入值必须为 XML 字符串结构,否则会导致转换异常 | xml_to_json(字段值) | 返回值 dict | |
解析 JSON 字符串值并转换为 XML 字符串 | json_to_xml(字段值) | 返回值字符串类型(STRING) | |
判断是否为 JSON 字符串 | if_json(字段值) | 返回条件值(BOOL) |
正则处理函数类
使用正则公式对文本中的字符进行匹配、替换。
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
检测敏感信息,例如身份证、银行卡等敏感信息 | sensitive_detection(scope="", ratio=1, discover_items="", replace_items="") | 返回值字符串类型(STRING) | |
基于正则对数据进行匹配,返回是否匹配成功,可以选择全匹配还是部分匹配 | regex_match(字段值, regex="", full=True) | 返回条件值(BOOL) | |
基于正则对数据进行匹配,返回相应的部分匹配结果,可以指定匹配结果的第几个表达式,以及第几个分组(部分匹配+指定捕获组序号),如果最终没有匹配结果,则返回空字符串 | regex_select(字段值, regex="", index=1, group=1) | 返回值字符串类型(STRING) | |
基于正则对数据进行分割,返回 JSON Array 字符串(部分匹配) | regex_split(字段值, regex=\\"\\", limit=100) | 返回值字符串类型(STRING) | |
基于正则匹配并替换(部分匹配) | regex_replace(字段值, regex="", replace="", count=0) | 返回值字符串类型(STRING) | |
基于正则进行匹配,并将匹配结果添加到 JSON 数组中,并返回 Array 字符串(部分匹配) | regex_findall(字段值, regex="") | 返回值字符串类型(STRING) |
日期处理类
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
将时间类的字段值(特定格式的日期字符串或者时间戳),转换为指定时区、格式的目标日期字符串 | dt_str(值, format="格式化字符串", zone="") | 返回值字符串类型(STRING) | |
将时间类的字段值(特定格式的日期字符串),同时指定字段对应的时区,转换为 UTC 时间戳 | dt_to_timestamp(值, zone="") | 返回值字符串类型(STRING) | |
将时间类的时间戳字段,指定目标时区后,转换为时间字符串 | dt_from_timestamp(值, zone="") | 返回值字符串类型(STRING) | |
获取加工计算时的本地时间 | dt_now(format="格式化字符串", zone="") | 返回值字符串类型(STRING) | |
自定义日志时间,会按照您的加工规则生成新的日志时间,支持 秒、毫秒、微秒、纳秒。 | custom_cls_log_time(time) | UTC 时间戳类型 |
字符串处理类
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
判断是否存在子串 | str_exist(值1, 值2, ignore_upper=False) | 返回计算的结果(BOOL) | |
在值中指定范围内查找子串,返回子串出现的次数 | str_count(值, sub="", start=0, end=-1) | 返回子串次数(INT) | |
返回字符串长度 | str_len(值) | 返回字符串长度(INT) | |
返回大写字符串 | str_uppercase(值) | 返回值字符串类型(STRING) | |
返回小写字符串 | str_lowercase(值) | 返回值字符串类型(STRING) | |
使用拼接字符串,拼接多值 | str_join(拼接字符串1, 值1, 值2, ...) | 返回值字符串类型(STRING) | |
替换字符串,返回替换结果字符串 | str_replace(值, old="", new="", count=0) | 返回值字符串类型(STRING) | |
格式化字符串,返回格式化结果 | str_format(格式化字符串, 值1, 值2, ...) | 返回值字符串类型(STRING) | |
移除字符串的开头和结尾处的指定字符 | str_strip(值, chars="\\t\\r\\n") | 返回值字符串类型(STRING) | |
移除字符串开头处的指定字符。 | str_strip(值, chars="\\t\\r\\n") | 返回值字符串类型(STRING) | |
移除字符串结尾处的指定字符。 | str_strip(值, chars="\\t\\r\\n") | 返回值字符串类型(STRING) | |
在值中查找子串,并返回子串出现的位置 | str_find(值, sub="", start=0, end=-1) | 返回指定第一次出现在值中的子字符串的位置(INT) | |
判断字符串是否以指定字符串开头 | str_start_with(值, sub="", start=0, end=-1) | 返回是否匹配的结果(BOOL) | |
判断字符串是否以指定字符串结尾 | str_end_with(值, sub="", start=0, end=-1) | 返回是否匹配的结果(BOOL) |
类型转换函数类
逻辑表达式函数类
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
根据条件判断,返回相应的值 | op_if(条件1, 值1, 值2) | 条件为 True 时,返回值1,否则返回值2 | |
对值进行 and 运算,均为 True 时,返回 True,否则返回 False | op_and(值1, 值2, ...) | 返回计算的结果(BOOL) | |
对值进行 or 运算,若存在参数值为 False,则返回 False,否则返回 True | op_or(值1, 值2, ...) | 返回计算的结果(BOOL) | |
对值进行 not 运算 | op_not(值) | 返回计算的结果(BOOL) | |
对值进行比较,相等则返回 True | op_eq(值1, 值2) | 返回比较的结果(BOOL) | |
对值进行比较,值1大于或等于值2时返回 True | op_ge(值1, 值2) | 返回比较的结果(BOOL) | |
对值进行比较,值1大于值2时返回 True | op_gt(值1, 值2) | 返回比较的结果(BOOL) | |
对值进行比较,值1小于或等于值2时返回 True | op_le(值1, 值2) | 返回比较的结果(BOOL) | |
对值进行比较,值1小于值2时返回 True | op_lt(值1, 值2) | 返回比较的结果(BOOL) | |
对值进行求和运算 | op_add(值1, 值2) | 返回求值结果 | |
对值进行求差运算 | op_sub(值1, 值2) | 返回求值结果 | |
对值进行乘积运算 | op_mul(值1, 值2) | 返回求值结果 | |
对值进行除法运算 | op_div(值1, 值2) | 返回求值结果 | |
对多值累加求和 | op_sum(值1, 值2, ...) | 返回求值结果 | |
对值进行模计算 | op_mod(值1, 值2) | 返回求值结果 | |
对值进行是否为 null 判断,是则返回 True,否则返回 False | op_null(值) | 返回计算的结果(BOOL) | |
对值进行是否为非 null 判断,是则返回 True,否则返回 False | op_notnull(值) | 返回计算的结果(BOOL) | |
对字符串值进行比较,相等则返回 True | op_str_eq(值1, 值2, ignore_upper=False) | 返回计算的结果(BOOL) | |
生成随机数(两个参数之间的一个随机数),左闭右闭 | random(值1, 值2) | 返回求值结果 |
编解码函数类
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
将编码 URL 进行解码 | decode_url(值) | 返回值字符串类型(STRING) | |
计算并返回 MD5 值 | md5_encoding(值) | 计算并返回 MD5 值 | |
生成 universally unique identifier (UUID) ,即唯一识别码 | uuid() | 计算并返回 UUID 值 | |
对字符串进行指定格式的编码 | str_encode(值) | 返回值字符串类型(STRING) | |
对字符串进行指定格式的解码 | str_decode(值) | 返回值字符串类型(STRING) | |
将字符串进行 base64 编码 | base64_encode(值, format="RFC3548") | 返回base64字符串类型(STRING) | |
将字符串进行 base64 解码 | base64_decode(值, format="RFC3548") | 返回值字符串类型(STRING) |
IP 解析函数类
函数名称 | 函数功能 | 函数语法描述 | 返回值类型 |
解析出函数的地理位置 | geo_parse(字段值, keep=("country","province","city"), ip_sep=",") | 返回 JSON 字符串 | |
判断 IP 是否在该网段内, 支持多个网段 | is_subnet_of (网段列表, ip) | 返回计算的结果(BOOL) |
字段提取模式说明
相关函数
分类 | 函数 | 提取模式默认值 |
字段处理 | overwrite | |
键值提取 | overwrite | |
| overwrite | |
| overwrite | |
| overwrite | |
| overwrite | |
富化函数 | overwrite | |
| overwrite | |
| fill-auto | |
提取模式说明
原始日志:
{"a": "","b": 100}
参数名 | 说明 | 示例 | |
| | 加工语句 | 加工结果 |
add | 当目标字段不存在时,设置目标字段 | fields_set("c", 200,mode="add") | { "a":"", "b":"100", "c":"200" } |
add-auto | 当新值非空,且目标字段不存在时,设置目标字段。 | fields_set("c", "",mode="add-auto") | { "a":"", "b":"100" } |
fill | 当目标字段不存在或者值为空字符串时,设置目标字段。 | fields_set("a", "123",mode="fill") | { "a":"123", "b":"100" } |
fill-auto | 当新值非空,且目标字段不存在或者值为空字符串时,设置目标字段。 | fields_set("a", "123",mode="fill-auto") | { "a":"123", "b":"100" } |
overwrite | 总是设置目标字段。 | fields_set("a", "123",mode="overwrite") | { "a":"123", "b":"100" } |
overwrite-auto | 当新值非空字符串,设置目标字段。 | fields_set("b", "123",mode="overwrite-auto") | { "a":"null", "b":"123" } |



