本文介绍窗口函数的基础语法和示例。
窗口函数用于对指定的多行数据进行计算并返回计算的结果,与 GROUP BY 的区别在于其仅会将计算结果附加到每一行数据上,而不会对行本身进行合并。
语法
window_function (expression) OVER ([ PARTITION BY part_key ][ ORDER BY order_key ][ { ROWS | RANGE } BETWEEN frame_start AND frame_end ] )
参数说明
参数 | 说明 |
window_function | 窗口值计算方法,支持通用聚合函数、排序函数和取值函数。 |
PARTITION BY | 窗口分区依据。 |
ORDER BY | 窗口分区内多行数据排序依据。 |
{ ROWS |RANGE } BETWEEN frame_start AND frame_end | 窗口帧,即窗口分区内每行数据计算值时使用到的数据范围(行),未指定时代表窗口分区内的所有行。 使用示例: rows between current row and 1 following:当前行及后一行。 rows between 1 preceding and current row:当前行及前一行。 rows between 1 preceding and 1 following:前一行至后一行(共三行)。 rows between current row and unbounded following:当前行及后续所有行。 rows between unbounded preceding and current row:当前行及前面的所有行。 |
通用聚合函数
排序函数
排序函数不能使用窗口帧
函数 | 说明 |
rank() | 对每个窗口分区分别进行排名并返回值。相同的值拥有相同的排名,所以排名可能不是连续的。例如,有两个相同值的排名为1,则下一个值的排名为3。 |
dense_rank() | 与 rank() 类似,区别在于该函数排名是连续的。例如,有两个相同值的排名为1,则下一个值的排名为2。 |
cume_dist() | 统计窗口分区内各个值的累计分布,即窗口分区内值小于等于当前值的行数占窗口内总行数的比例。 |
ntile(n) | 将窗口分区内数据按照顺序分为n组,如果分区内的行数没有被平均分成 n 组,则从第一组开始,每组分配一个剩余值。例如:数据有6行,需要分为4组,则每行数据的组号为 1、1、2、2、3、4。 |
percent_rank() | 计算每行数据在窗口分区内的百分比排名,计算方式为(r - 1) / (n - 1),其中r为通过 rank() 获取到排名值,n为窗口分区内的总行数 |
row_number() | 返回窗口分区内每行数据(根据排序规则排序后)的序号,从1开始,每行均为唯一值。 |
取值函数
函数 | 说明 |
first_value(key) | 返回窗口分区内的第一个值。 |
last_value(key) | 返回窗口分区内最后一个值。 |
nth_value(key, offset) | 返回窗口分区内指定偏移后的值,offset 从1开始计算。如果 offset 为 null 或超过了窗口分区内行的数量,则返回null。offset 不允许为0或负数。 |
lead(key[, offset[, default_value]]) | 返回窗口分区内当前行向后指定偏移后的值,offset 从0开始计算,即当前行。offset 默认为1,如果 offset 为 null,则返回 null。如果偏移后的行超出了窗口分区,则返回 default_value,未指定时返回 null。 使用该函数时必须制定窗口分区内的排序规则(ORDER BY),并且不能使用窗口帧。 |
lag(key[, offset[, default_value]]) | 与 lead(key[, offset[, default_value]]) 函数类似,区别在于该函数会返回当前行向前指定偏移后的值。 |
示例
示例1:查询最近1小时每个接口最慢的5个请求及其请求 ID
选择时间范围为近1小时,并执行如下查询和分析语句,其中 action 为接口名称,timeCost 为接口响应时间,seqId 为请求ID。
查询和分析语句
* | select * from (select action,timeCost,seqId,rank() over (partition by action order by timeCost desc) as ranking order by action,ranking,seqId) where ranking<=5 limit 10000
查询和分析结果
action | timeCost | seqId | ranking |
ModifyXXX | 151 | d75427b3-c562-6d7a-354f-469963aab689 | 1 |
ModifyXXX | 104 | add0d353-1099-2c73-e9c9-19ad02480474 | 2 |
CreateXXX | 1254 | c7d591f0-2da6-292c-8abf-98a0716ff8c6 | 1 |
CreateXXX | 970 | d920cf7a-7e7b-524b-68e9-a957c454c328 | 2 |
CreateXXX | 812 | 16357f6d-33b3-83ea-0ae3-b1a2233d4858 | 3 |
CreateXXX | 795 | 0efdab5e-af5f-4a4a-0618-7961420d17a1 | 4 |
CreateXXX | 724 | fb0481f2-dcfc-9500-cb44-a139b774aceb | 5 |
DescribeXXX | 55242 | 4129dcda-46d7-9213-510e-f58cba29daf5 | 1 |
DescribeXXX | 17413 | e36cdeb0-cbc5-ce2b-dec7-f485818ab6c7 | 2 |
DescribeXXX | 10171 | cd6228f7-4644-ba45-f539-0fce7b09455b | 3 |
DescribeXXX | 9475 | 48b6f6e3-6d08-5a31-cd68-89006a346497 | 4 |
DescribeXXX | 9337 | 940b5398-e2ae-9141-801b-b7f0ca548875 | 5 |
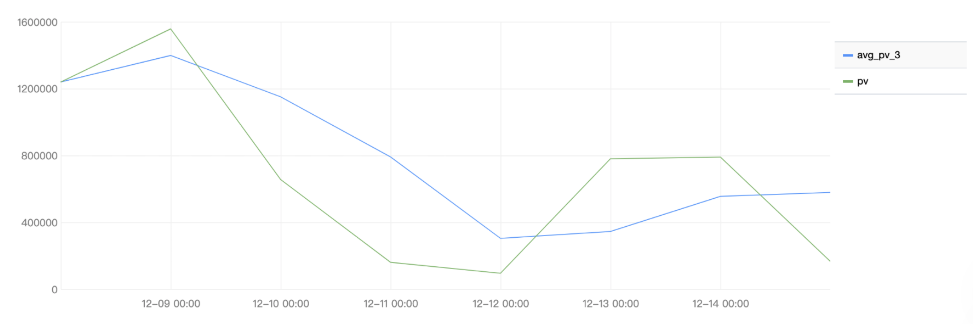
示例2:查询应用吞吐量的3日移动平均值变化趋势
选择查询和分析的时间范围为最近7天,并执行如下查询和分析语句,其中 pv 为每天的应用吞吐量,avg_pv_3 是3天移动平均后的应用吞吐量。
查询和分析语句
* | select avg(pv) over(order by analytic_time rows between 2 preceding and current row) as avg_pv_3,pv,analytic_time from (select histogram( cast(__TIMESTAMP__ as timestamp),interval 1 day) as analytic_time, count(*) as pv group by analytic_time order by analytic_time)
查询和分析结果