自定义消费原理
自定义消费是 CLS 自研的 SDK,旨在高效地从云端获取并处理日志数据。核心机制在于利用消费组进行协作,通过服务端自动管理的负载均衡原理,在消费者数量或日志分区发生变化时动态分配任务,从而确保数据处理的连续性与无重复性。是一个高可靠且可扩展的日志实时消费框架。
消费组消费流程
使用消费组消费数据时,服务端会管理消费组里的所有消费者的消费任务,根据主题分区和消费者的数量关系自动调整消费任务的均衡性,同时会记录每个主题分区的消费进度,保证不同消费者可以无重复消费数据。消费组消费的具体流程如下:
1. 创建消费组。
2. 每个消费者定期向服务端发送心跳。
3. 消费组根据主题分区负载情况自动分配主题分区给消费者。
4. 消费者根据所分配的分区列表,获取分区 offset 并消费数据。
5. 消费者周期性地更新分区的消费进度到消费组,便于下次消费组分配任务。
6. 重复步骤2 - 步骤6,直至消费结束。
负载均衡消费原理
消费组会根据活跃消费者和主题分区的数量动态调整每个消费者的消费任务,保证消费的均衡性。同时,消费者会保存每个主题分区的消费进度,保证故障恢复后可继续消费数据,避免重复消费。
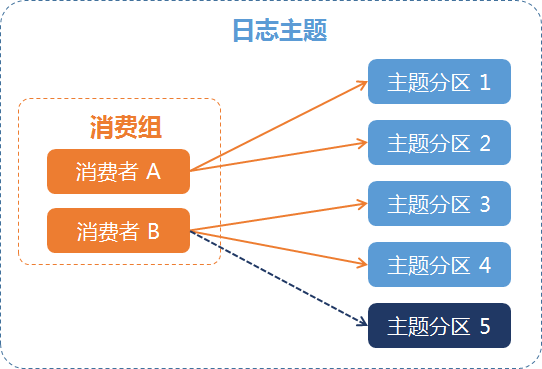
例一:主题分区发生变化
例如:某个日志主题有两个消费者,消费者 A 负责消费1、2号分区,消费者 B 负责消费3、4号分区,通过分裂操作新增主题分区5后,消费组会自动将5号分区分配给消费者 B 进行消费,如下图所示:
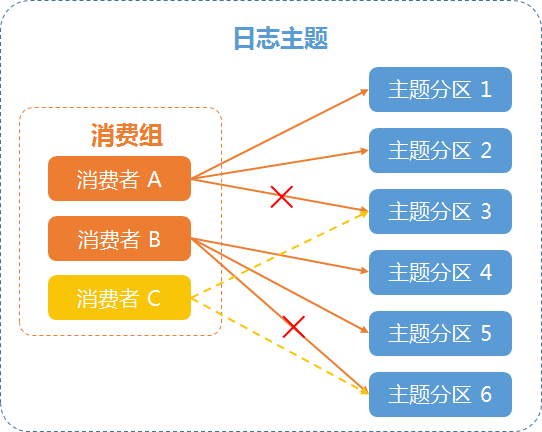
例二:消费者发生变化
例如:某个日志主题有两个消费者,消费者 A 负责消费1、2、3号分区,消费者 B 负责消费4、5、6号分区,新增一个消费者 C,消费组会重新进行均衡分配,将3、6号分区分配给新消费者 C 进行消费,如下图所示:
使用自定义消费
前提条件
子账号/协作者需要主账号授权,授权步骤参见 基于 CAM 管理权限,复制授权策略参见 CLS 访问策略模板。
操作步骤
1. 安装 SDK,具体可参见 tencentcloud-cls-sdk-python。
pip install git+https://github.com/TencentCloud/tencentcloud-cls-sdk-python.git
2. 创建消费者并启动消费者线程,该消费者会从指定的主题中消费数据。参考 消费 Demo-消费预过滤,该 Demo 展示的是一个对日志先过滤,再消费的示例,在消费组 Consumer 中增加一个过滤条件
log_keep(op_and(op_gt(v("status"), 400), str_exist(v("cdb_message"), "pwd"))),即可实现只消费 [状态码大于400且cdb_message字段包含"pwd"字符串] 的日志。
消费者参数说明
如下:配置参数 | 是否必填 | 说明 | 默认值 | 取值范围 |
endpoint | 是 | - | 支持地域:ALL | |
access_key_id | 是 | - | - | |
access_key | 是 | - | - | |
region | 是 | - | 支持地域:ALL | |
logset_id | 是 | 日志集 ID,仅支持一个日志集。 | - | - |
topic_ids | 是 | 日志主题 ID,多个主题请使用','隔开。 | - | - |
consumer_group_name | 是 | 消费者组名称。 | - | - |
internal | 否 | 内网:TRUE 公网:FALSE 说明: | FALSE | TRUE/FALSE |
consumer_name | 是 | 消费者名称。同一个消费者组内,消费者名称不可重复。 | - | 0-9、aA-zZ、'-'、'_'、'.'组成的字符串 |
heartbeat_interval | 否 | 消费者心跳上报间隔,2个间隔没有上报心跳,会被认为是消费者下线。 | 20 | 0-30分钟 |
data_fetch_interval | 否 | 消费者拉取数据间隔,不小于1秒。 | 2 | - |
offset_start_time | 否 | 拉取数据的开始时间,字符串类型的 UNIX 时间戳,精度为秒,例如 "1711607794",也可以直接配置为"begin"、"end"。 begin:日志主题生命周期内的最早数据。 end:日志主题生命周期内的最新数据。 | "end" | "begin"/"end"/UNIX 时间戳 |
max_fetch_log_group_size | 否 | 消费者单次拉取数据大小,默认2M,最大10M。 | 2097152 | 2M - 10M |
offset_end_time | 否 | 拉取数据的结束时间,支持字符串类型的 UNIX 时间戳,精度为秒,例如"1711607794"。不填写代表持续拉取。 | - | - |
query | 否 | 说明: 仅能支持部分数据加工函数。 | log_keep(op_and(op_gt(v("status"), 400), str_exist(v("message"), "access failed"))) 仅消费 status 字段大于400且 message 字段包含"access failed"关键字的日志。 | - |
注意:
消费开始时间:如您从指定时间点(如 offset_start_time=1711607794)消费了一次,如需再次从该时间点开始消费,请修改消费组的名称。



