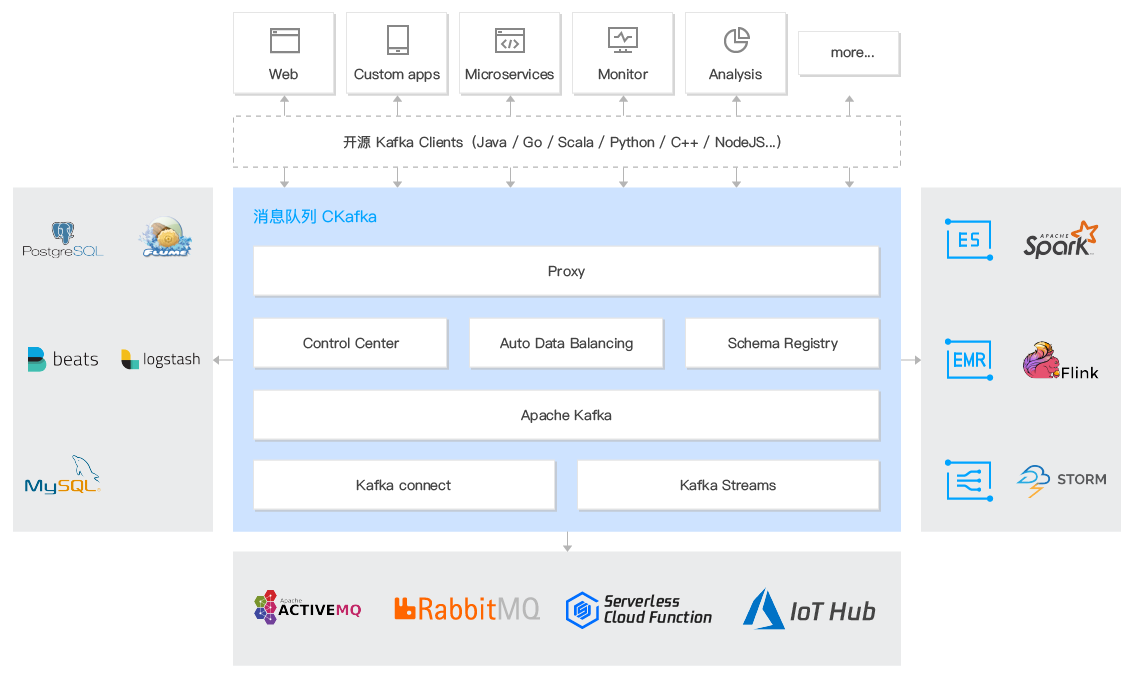
概述
消息队列 CKafka 版广泛应用于日志、大数据等上下游需要进行大规模数据交换的领域,例如网页追踪行为分析、日志汇聚、监控/链路数据聚合、流式数据处理、在线和离线分析等。
您可以通过以下方式让数据集成变得简单:
将消息队列 CKafka 版中的消息导入到腾讯云平台的 COS、Oceanus 等产品。
通过 SCF 触发器的方式连接 CKafka 及云上其他产品。
网页追踪
客户端浏览器/App 通过实时处理网站活动(PV、搜索、用户其他活动等),根据行为类型将消息发送至消息队列 CKafka 版 Topic 中,这些信息流可以被用于实时监控或离线统计分析等。
由于每个用户的 Page View 中会生成许多活动信息,因此网站活动跟踪需要很高的吞吐量,消息队列 CKafka 版可以满足高吞吐、离线处理等要求。

日志汇聚
消息队列 CKafka 版的高吞吐低延迟处理特性,易于支持多个数据源和分布式的数据处理(消费)。相比于中心化的日志汇聚系统,消息队列 CKafka 版可以在提供同样性能的条件下,实现更强的持久化保证以及更低的端到端延迟。
消息队列 CKafka 版的特性决定它非常适合作为“日志收集中心”。多台主机/应用可以将操作日志批量、异步地发送到消息队列 CKafka 版集群,而无需保存在本地或者 DB 中;消息队列 CKafka 版可以批量提交消息,对于生产者而言,几乎感觉不到性能的开支。此时消费者可以使用 Hadoop/Flink/Spark 等其他专业化的存储和分析系统对拉取的日志进行统计分析。

大数据场景
在一些大数据相关的业务场景中,需要对大量并发数据进行处理和汇总,此时对集群的处理性能和扩展性都有很高的要求。消息队列 CKafka 版在数据分发机制上的实现,磁盘存储空间的分配、消息格式的处理、服务器的选择以及数据压缩等方面,也决定其适合处理海量的实时消息,并能汇总分布式应用的数据,方便系统运维。
在具体的大数据场景中,消息队列 CKafka 版能够很好地支持离线数据、流式数据的处理,并能够方便地进行数据聚合、分析等操作。
用户链路观测
在一个典型的微服务架构中,系统由多个独立服务组成,每个服务都会产生大量的监控数据(例如 CPU、内存使用率)、日志数据(例如请求日志、错误日志)和 Trace 数据(例如服务调用链路)。为了实现对系统的全面可观测性,可以将这些数据统一采集并发送到 CKafka 中。下游通过 Flink Stream 实时消费这些数据,进行聚合、分析和异常检测,帮助运维团队快速发现和解决问题,提升系统的稳定性和可维护性。

物联网数据采集分发
在物联网场景中,设备通过 MQTT 协议,将设备数据投递到 CKafka,经过规则引擎分发到不同的系统做进一步的处理。例如车辆通过搭载的传感器和控制器收集各种信息,例如车辆位置、速度、油量、发动机状态等,这些信息需要实时或定期传输到车厂的服务器,以便进行数据分析、故障预警、远程控制等操作。
终端设备通过 MQTT 协议接入消息队列 MQTT 版,通过规则引擎对接 CKafka 集群实现数据的转发。
车联网服务平台、高精地图服务、定位服务和其他车联网相关应用可以直接通过订阅 CKafka 数据进行消费,同时通过消息队列 MQTT 版实现对车控(远程控制)消息的双向通信。

云函数触发器
消息队列 CKafka 版可以作为云函数触发器,在消息队列中接收到消息时将触发云函数的运行,并会将消息作为事件内容传递给云函数。例如,CKafka 触发云函数时,云函数可以对消息进行结构变换、内容过滤等处理或者将消息投递到 Elasticsearch Service(ES)中。
说明:




