一、算法原理
(一)维度归因
1. 什么是波动归因?
目前的波动归因功能是针对维度字段的下钻归因,维度归因指通过分析业务指标在不同维度(如用户地域、设备类型、广告主等)上的分布变化,定位指标波动根本原因的算法。例如,当广告收入突然下降时,维度归因能快速识别是某个地区的用户活跃度降低,还是某个广告位的配置错误导致。
核心目标 :
将复杂的指标波动(如收入、点击率变化)拆解到具体维度,帮助业务人员快速定位问题根源,支持数据驱动的决策。
2. 算法核心机制
解释力(Explanatory Power)
定义 :衡量某一维度对指标波动的贡献程度。
公式 :EPij= (实际值i - 预测值i) / (整体实际值 - 整体预测值)

例如,若某广告主的收入下降占整体下降的50%,则其解释力为50%。
作用 :筛选出对波动影响最大的维度元素(如某个浏览器版本、广告主)。
简洁性(Succinctness)
定义 :用最少的维度元素解释最大的波动。
实现 :优先选择解释力高且元素数量少的维度组合。
例如,若“浏览器类型=Chrome”能解释80%的收入下降,则无需列举其他次要因素。
惊喜度(Surprise)
定义 :衡量维度分布变化的异常程度,通过JS散度 (Jensen-Shannon Divergence)计算。
公式 :Sij=0.5[plog(2p/(q + p)) + qlog(2q/(q + p))]

(p):预测分布(如某浏览器历史收入占比30%),
(q):实际分布(如该浏览器当日收入占比5%)。
作用 :排除正常波动,聚焦分布显著变化的维度(如某浏览器突然无收入)。
3. 算法实践案例:
数据输入 :
预测值与实际值(如每小时广告收入、点击量)。
多维度数据(广告主、设备类型、地域等)。
根因筛选流程 :
步骤1 :计算每个维度元素的解释力,筛选出贡献超过阈值的元素。
步骤2 :按简洁性原则,组合最少元素解释最大波动。
步骤3 :通过惊喜度排序,优先输出分布变化最异常的维度(如某设备类型收入占比从50%骤降至0%)。
衍生指标处理 (支持中):
对于点击率(CTR)、每点击成本(CPC)等衍生指标,采用偏导数法计算元素贡献4。
例如,若某广告主的点击量增加但收入下降,可能因其低价值广告占比较高,算法会识别其对CPC下降的贡献。
(二)指标归因
1. 线性模型/ElasticNet:
用于数据量较少以及简单线形场景;
贡献度计算公式:贡献度等于特征建模的参数*(该特征基期平均值-现期平均值)
contribi = coefi×( avg(xcurr,i) − avg(xbase,i) )
2. 树模型/XGBoost + SHAP:
用于数据量足够和复杂非线性场景。
使用XGBoost算法进行模型建模。
使用shap.explainer在XGBoost树上计算shap值,通过 SHAP 值解释每个特征在预测目标上的边际贡献,基期与现期的差值即为最终贡献。
二、功能配置
(一)权限开关
波动归因作为腾讯云 ChatBI 的智能工具,支持配置此功能的配置。
配置维度:项目维度生效
拥有配置权限的角色:企业管理员、本项目管理员(其他角色不可见配置按钮)
配置路径:ChatBI > 配置 > 智能工具 > 波动归因
配置按钮如下:
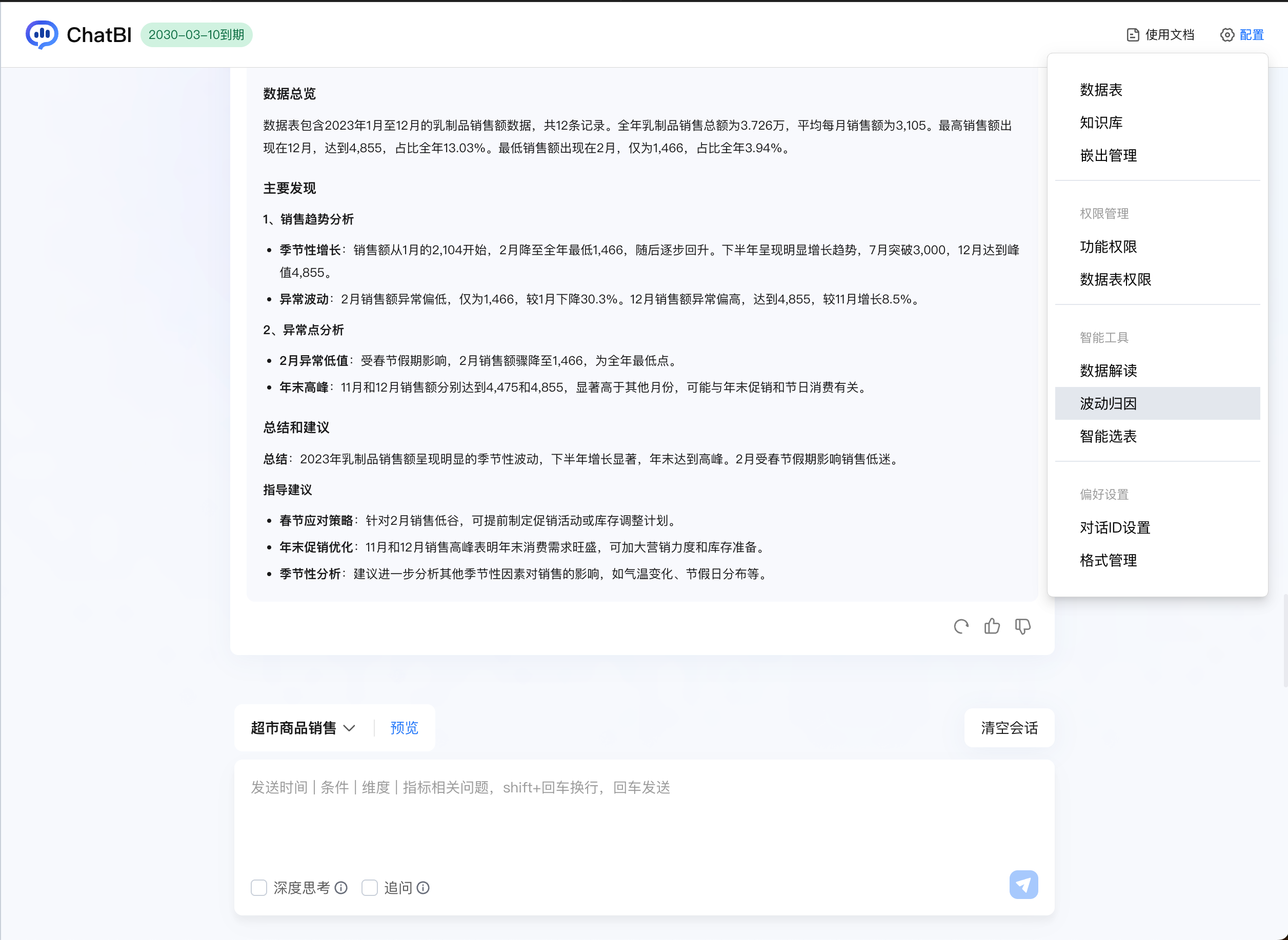
单击波动归因按钮进行配置
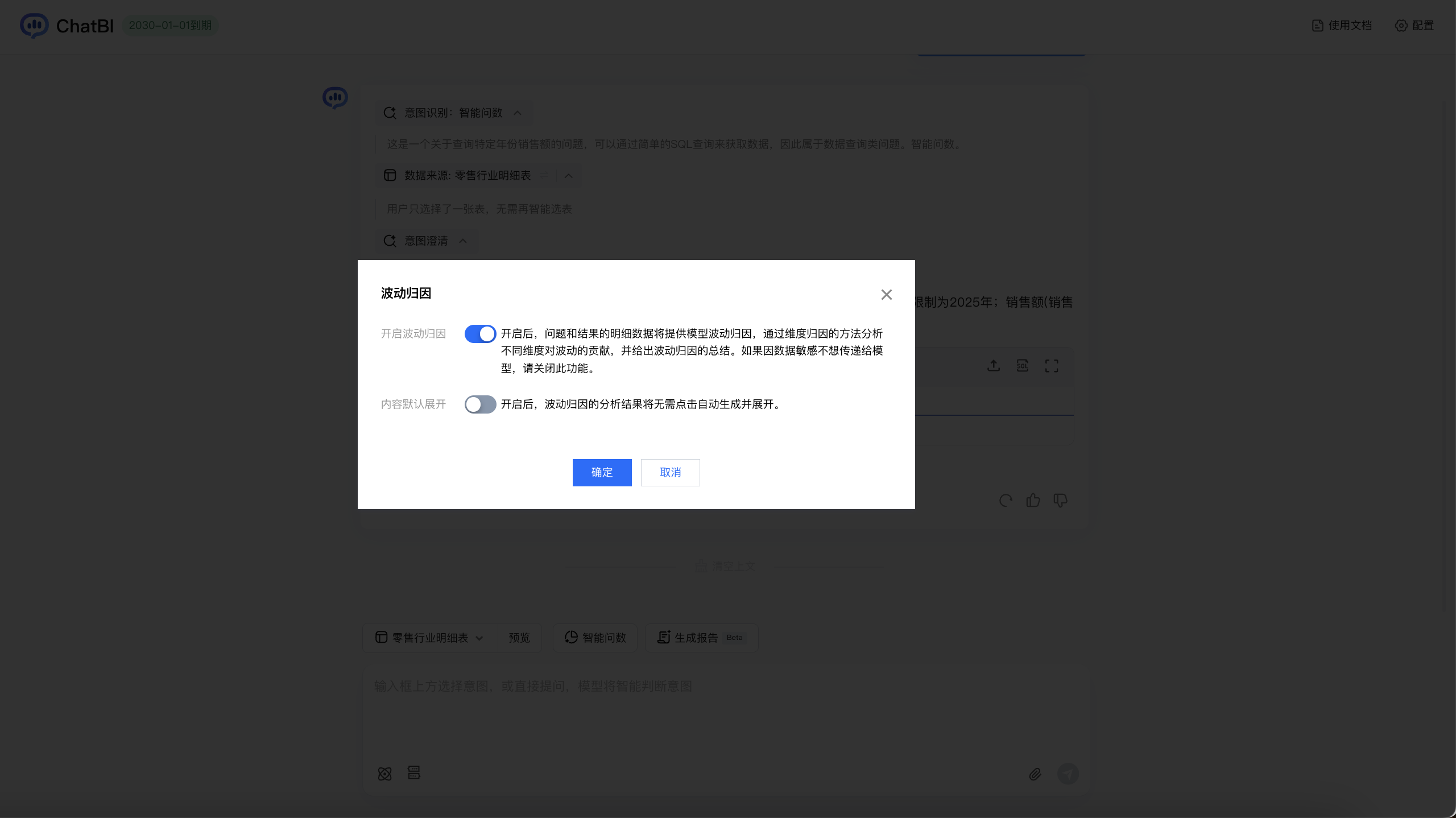
开启波动归因:开启后,问题和结果的明细数据将提供模型波动归因,通过维度归因的方法分析不同维度对波动的贡献,并给出波动归因的总结。如果因数据敏感不想传递给模型,请关闭此功能。
内容默认展开:默认关闭,开启后,波动归因的分析结果将无需点击自动生成并展开。
(二)维度智能推荐配置
为了使波动归因的报告更加符合业务实际,支持大模型在波动归因前进行字段智能推荐,并且也支持用户进行字段优先级的自定义配置,
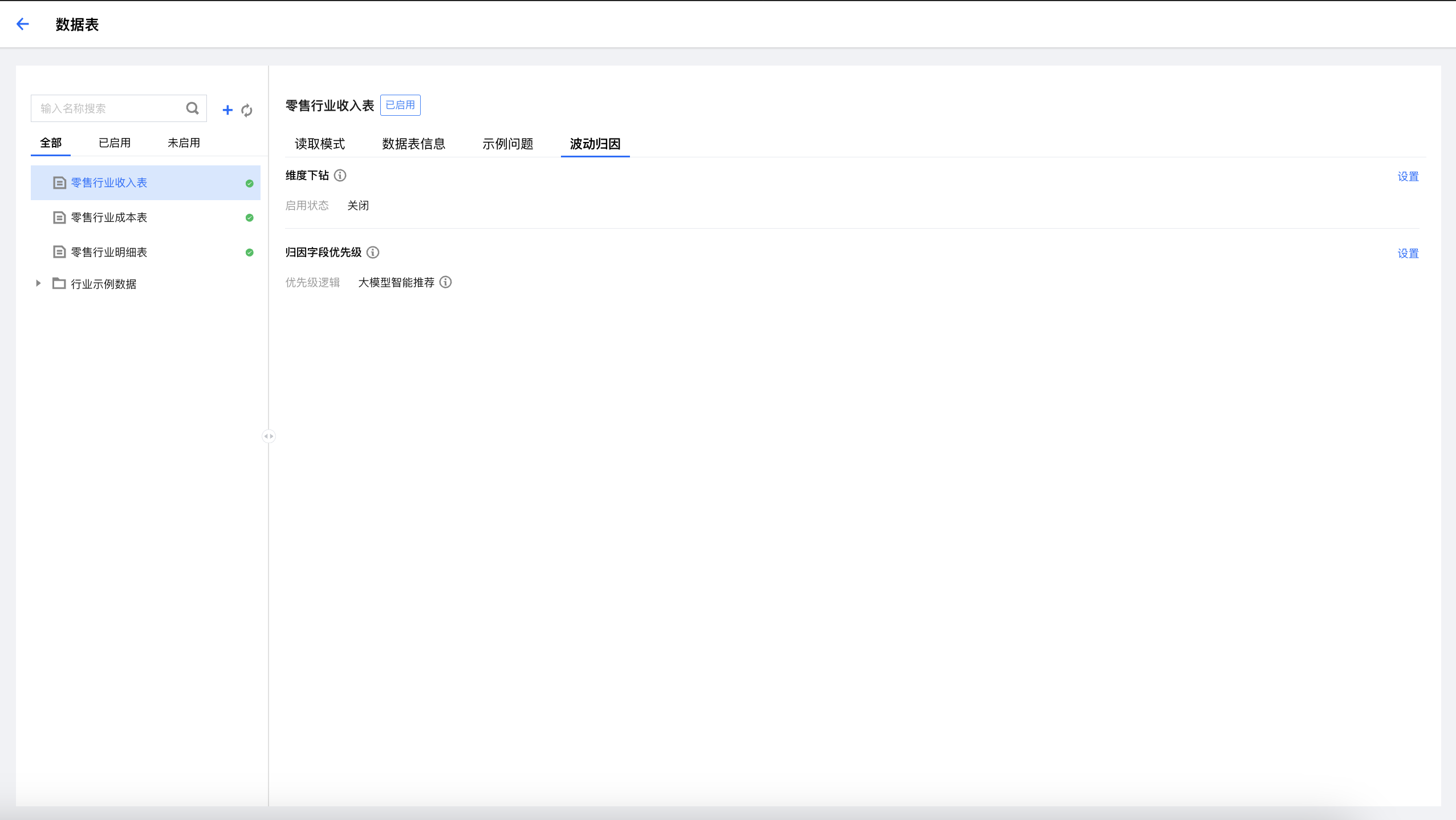
配置维度:表级别生效
拥有配置权限的角色:数据表有编辑权限角色
配置路径:ChatBI > 配置 > 数据表 > 波动归因
优先级逻辑:
大模型智能推荐(默认逻辑):大模型会根据问题、数据分布和字段语义智能选择维度进行计算和排序。维度下的唯一值超过70%如序列号,模型将删除此维度。维度超过20个为保证速度会智能选择20个维度进行分析。
大模型智能推荐+自定义配置:在大模型智能推荐的基础上支持自定义配置优先归因维度,自定义维度的优先级大于模型推荐的维度。
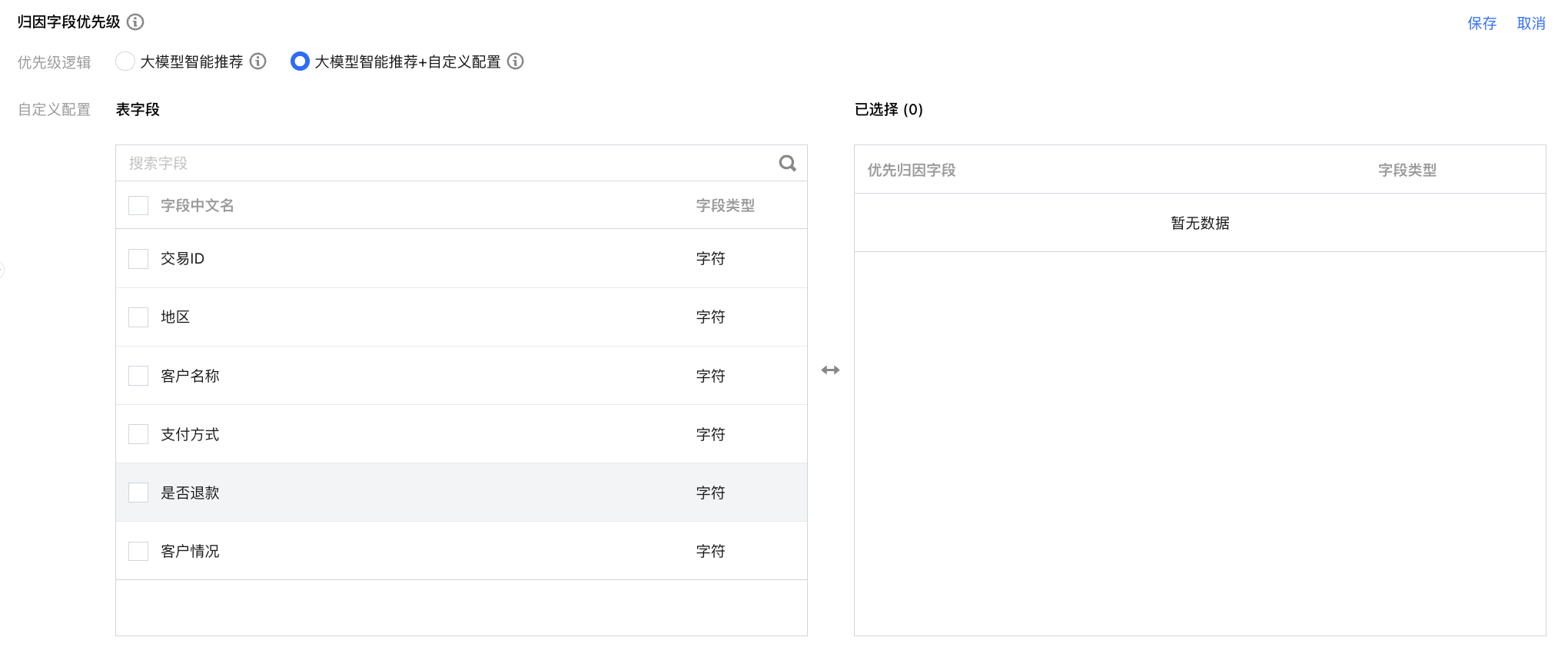
呈现逻辑(前20维度):自定义配置字段>模型智能推荐>模型智能不推荐
(三)维度下钻配置
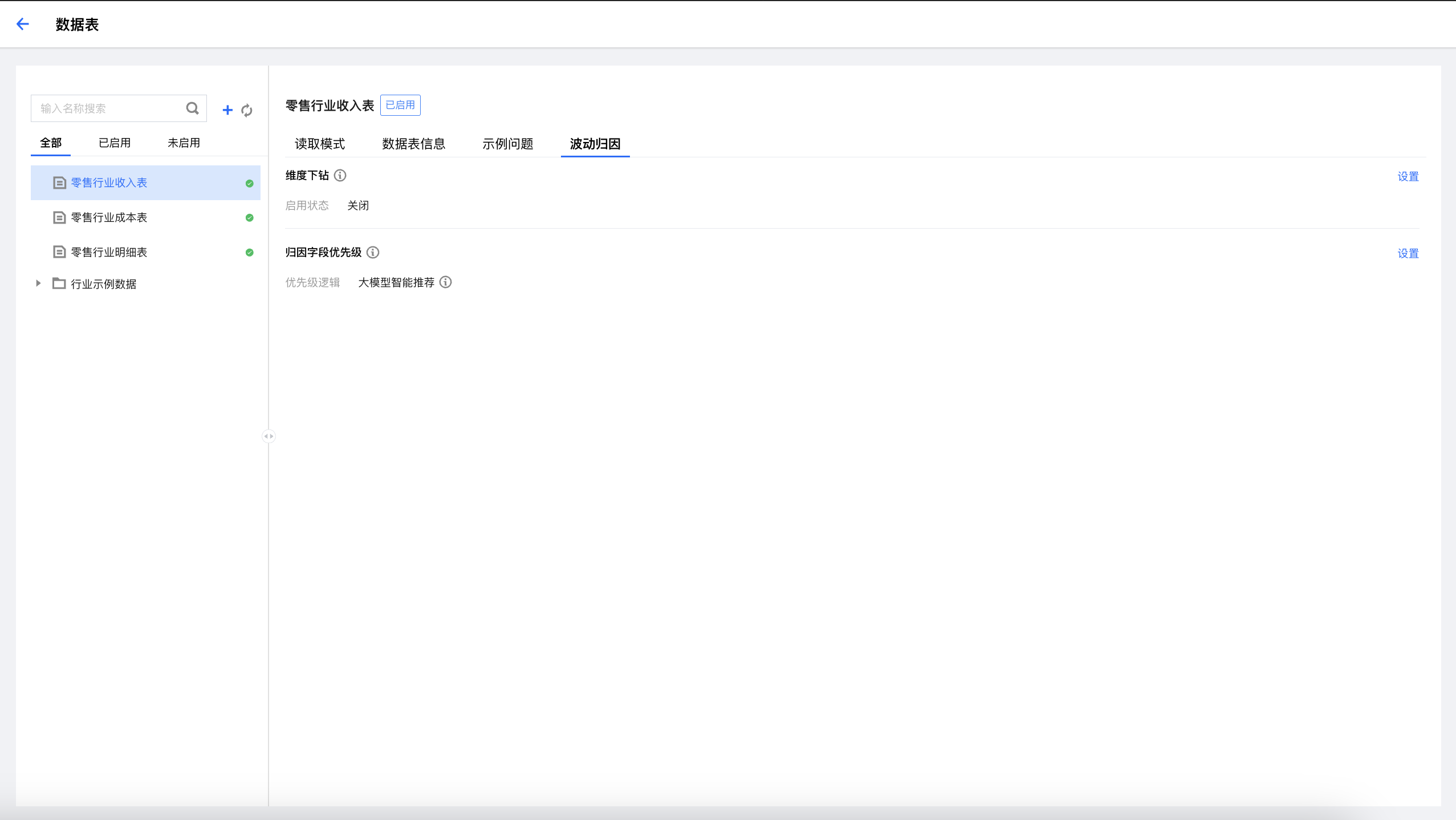
当维度归因中的不同维度存在层级关系,配置后支持按照层级关系进行下钻,下钻路径最多支持配置10条。
配置维度:表级别生效
拥有配置权限的角色:数据表有编辑权限角色
配置路径:ChatBI > 配置 > 数据表 > 波动归因
默认状态:关闭。
切换为启用状态,有两种下钻路径配置方式

大模型生成:将传递数据表的维度字段以及前5行数据内容进行下钻路径智能生成,如果数据信息敏感可以使用手动配置。
手动设置:用户手动输入下钻路径。
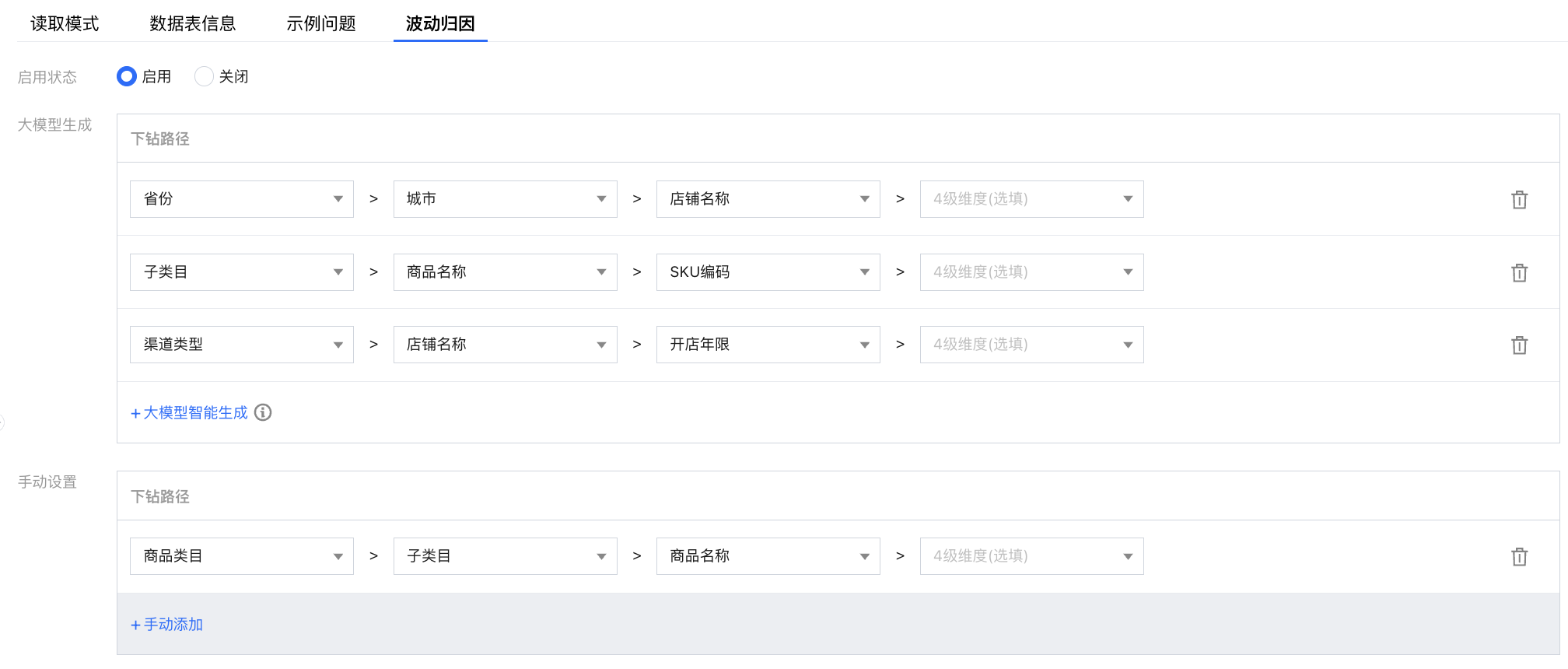
保存结果:
(四)影响因素配置(事件知识库)
拥有配置权限的角色:项目管理员
配置路径:ChatBI > 配置 > 知识库 > 事件知识库
事件知识库:录入某个时间发生的事件,大模型会应用事件知识解读和归因数据。事件知识仅在波动归因模块生效。知识过多会影响问答效果,每张数据表的知识条数推荐不要超过30条
三、功能使用
(一)触发逻辑
单一聚合指标:目前仅支持单一的聚合指标,例如收入情况。支持sum数值/count字符/distinct(count)字符。
明确的时间条件:例如2024年,可以支持所有时间。
基期数据:波动归因的前提是需要计算波动数据,因此必须有基期时间的数据。例如:请计算2024年的收入情况?现期是2024年,那么必须有基期2023年的数据。
(二)报告各部分效果
1. 波动分析

2023年与2024年销售额的波动变化情况和同比率变化
绿色代表减少,红色代表增长。
2. 维度归因分析
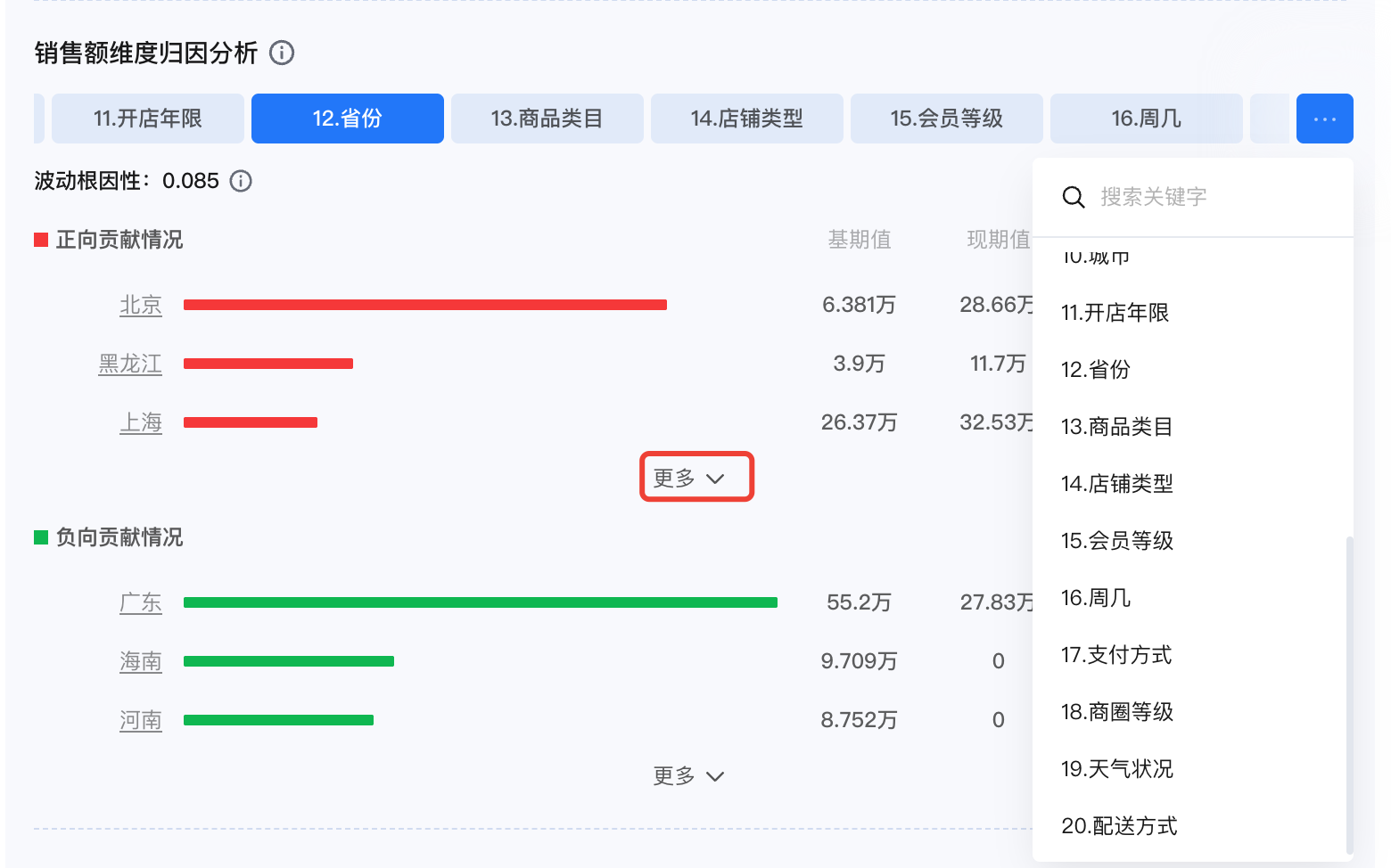
模型将根据2023年1月与2024年1月用户消费金额的波动情况进行归因分析,并按照影响程度从大到小进行维度排序。
说明:
计算方法为分布差异法,即维度相对波动变化的偏移程度,偏移程度越大对波动的影响越大,排名并非是同比增长情况。
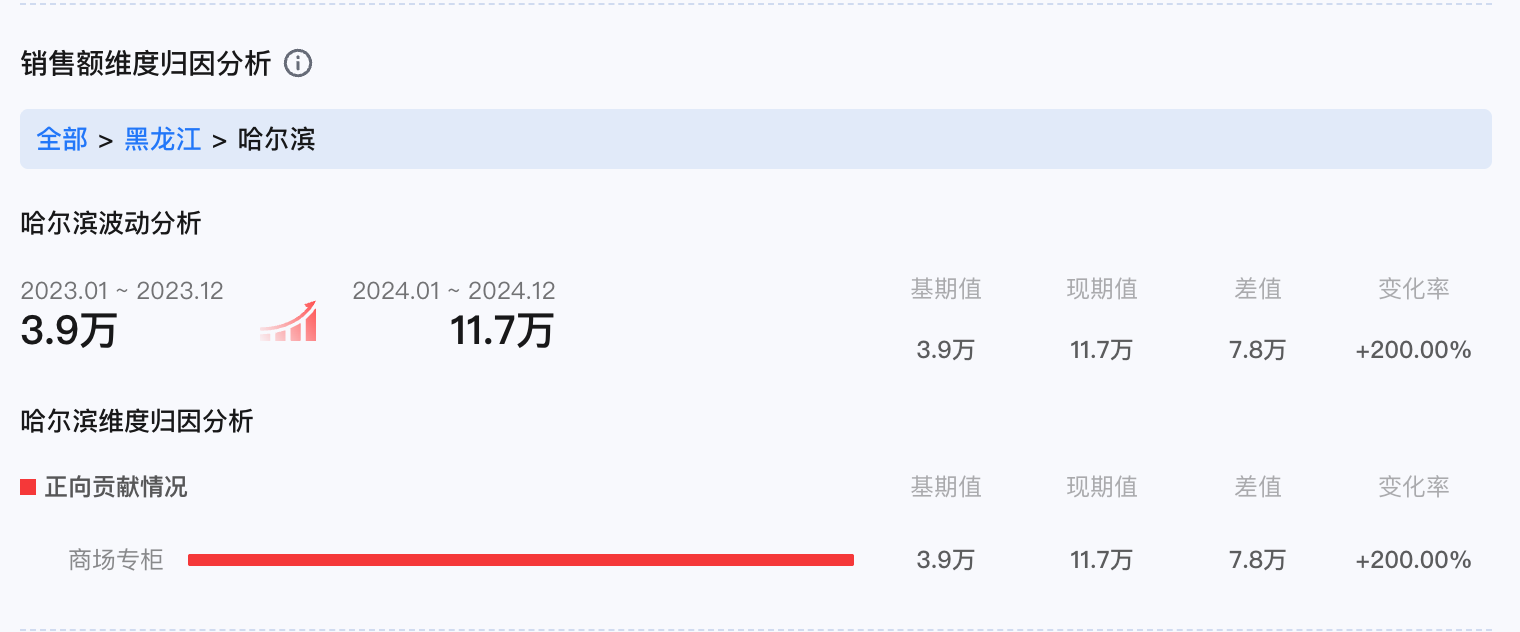
维度下钻:提供维度下钻部分配置的层级关系,可以按照下钻层级计算下一层对上一层的贡献情况。
3. 指标归因分析
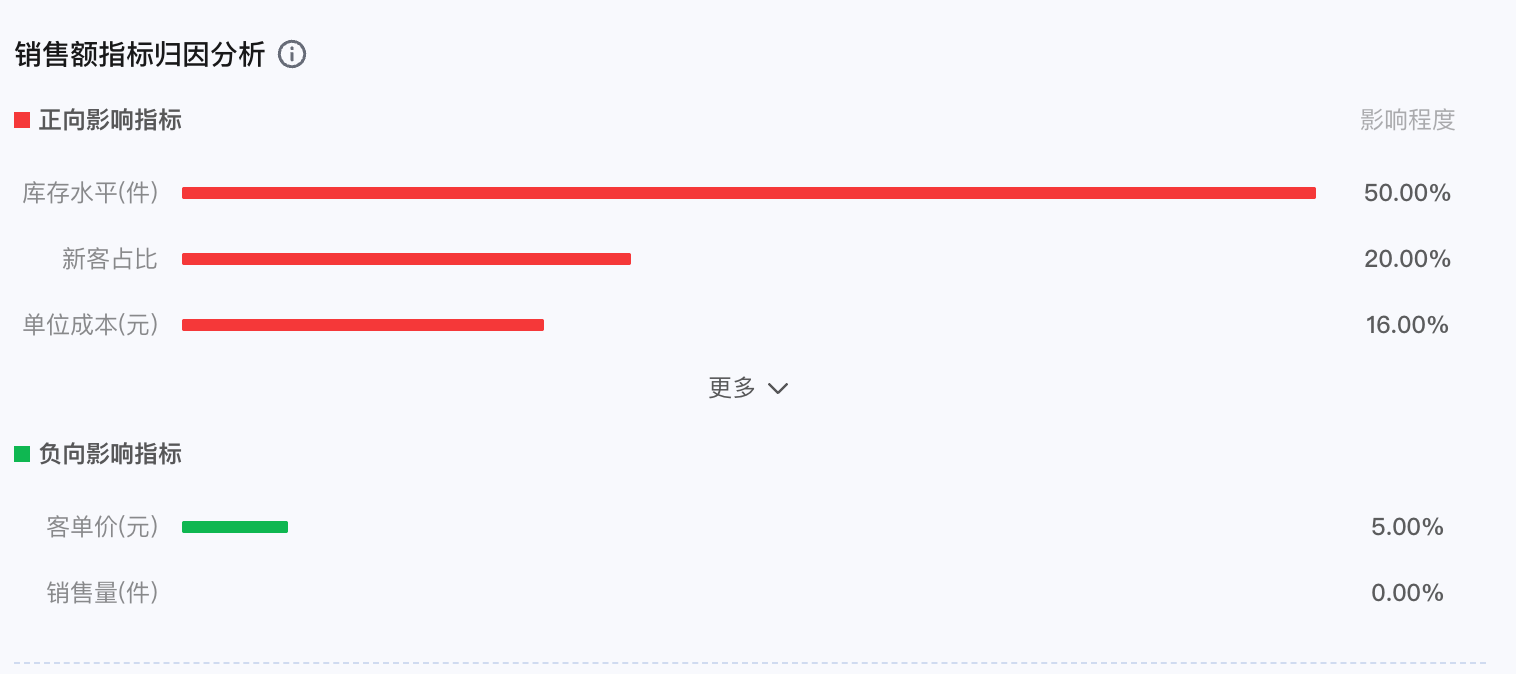
指标归因使用XGBoost算法计算各指标的影响大小,再采用 SHAP算法量化每个指标的影响程度。影响程度代表了该指标变化对核心指标变化的影响大小和方向。
正向指标代表对分析指标呈拉动作用,负向指标代表对分析指标呈拖累作用。影响程度则体现该指标对目标指标变化的影响权重。例如:毛利、收入、成本三个指标,当毛利作为分析指标,收入对毛利呈正向影响,成本则对毛利呈负向影响。
影响程度为0时,1)当归因指标的基期和现期值数据较少或者完全一致,会导致影响程度为0,此时该指标无分析意义;2)该指标对目标指标的影响程度为0,即不相干指标。
4. 影响因素分析
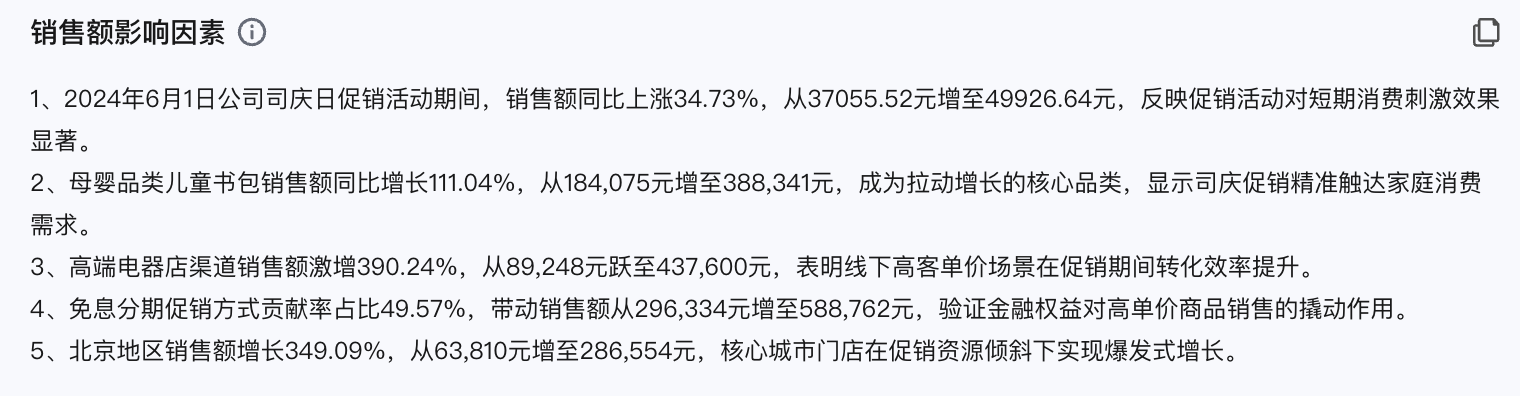
5. 总结和建议

根据用户问题和工具分析结果,从通用知识库中召回相关知识,包括行业知识、节假日信息等。当前支持分析波动归因的前5个top维度。
6. 时间对比周期自定义

支持自定义调整对比的时间周期,波动归因支持按照数据表本身的时间颗粒度做自定义时间对比。
满足客户的非标准时间周期对比需求,例如对比不同年份的春节、对比618大促前后,时间周期随客户自由选择;
7. 快捷同环比
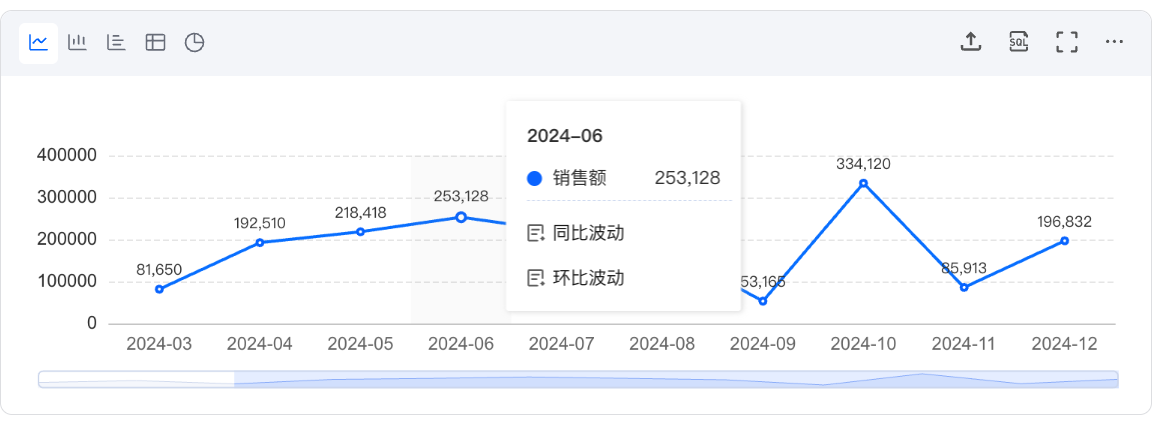
当问题中存在多个时间点时,支持在线图、柱图、条图进行快捷同环比选择。



