本文为您介绍通过 EMR 控制台快速创建一个 EMR on TKE 集群、并完成作业提交及查看运行结果的整套操作流程。
准备工作
1. 在使用 EMR 集群前,需要注册腾讯云账号并完成实名认证,具体操作请参见 实名认证账号归属介绍。
2. 完成对弹性 MapReduce 的服务账号授予系统默认角色 EMR_QCSRole,具体操作请参见 角色授权。
3. 完成对弹性 MapReduce的服务账号授权服务相关角色,具体操作请参见 管理权限。
4. 在线账号充值,EMR on TKE 提供按量计费,在创建集群前需要进行账号余额充值,确保余额大于等于创建集群所需配置费用(不包含:代金券、折扣卷、优惠券等),具体操作请参见 在线充值 。
创建集群
配置项 | 配置项说明 | 示例 |
集群名称 | 集群的名称,可自定义 | EMR-7sx2aqmu |
地域 | 集群所部署的物理数据中心 注意:集群创建后,无法更改地域,请谨慎选择。 | 北京、上海、广州、南京、新加坡等 |
容器类型 | 服务角色由底层容器提供资源进行部署,支持 TKE 标准集群和 TKE Serverless 集群 | TKE |
集群网络及子网 | 用于购买 db 使用,需保持网络与容器集群网络一致 | 广州七区 |
安全组 | 集群维度配置安全组 | 创建新安全组 |
计费模式 | 集群部署计费模式 | 按量计费 |
集群类型 | 支持数据湖和机器学习集群类型,默认数据湖集群类型。 | 数据湖 |
产品版本 | 不同产品版本上捆绑的组件和组件的版本不同 | EMR-TKE1.0.0 版本中内置的是 Hadoop 2.8.5、Spark 3.2.1 等。 |
部署服务 | 非必选组件,根据自身需求组合搭配自定义部署,最少选择一个组件 | Hive-2.3.9、Impala-3.4.1等 |
COS 存储桶 | 用于存储日志,jar 包等信息 | - |
设置密码 | 设置 webUI 密码,当前密码仅用于初始设置服务 webUI 访问密码。 | 8-16个字符,包含大写字母、小写字母、数字和特殊字符四种,特殊符号仅支持!@%^*,密码第一位不能为特殊字符 |
提交作业及查看运行结果
集群创建成功后,您可以在该集群创建并提交作业。本文以提交 Kyuubi Spark 和 Hive on Spark 作业和查看作业信息为例,操作如下。
Hue 提交
1. 在集群列表中单击对应的集群 ID/名称进入集群详情页。
2. 在集群详情页中单击集群服务,选择 hue。
3. 在角色管理页面的操作列中打开更多下拉选项框,单击开启网络访问,然后选择公网LB,单击确认开启,待流程结束后,hue 所在 pod 的公网 LB 成功创建。
4. 单击右上角查看信息/查看WebUI,查看 HUE 的访问地址,单击访问 hue的WebUI。
5. 通过认证进入 hue 页面,通常认证用户为 root,密码为集群创建时的密码。
6. 通过 hive tab 可以提交 hive on spark 任务。
7. 通过 SparkSql_Kyuubi 可以提交 sparksql 任务。
Hive on Spark 建表及查询:


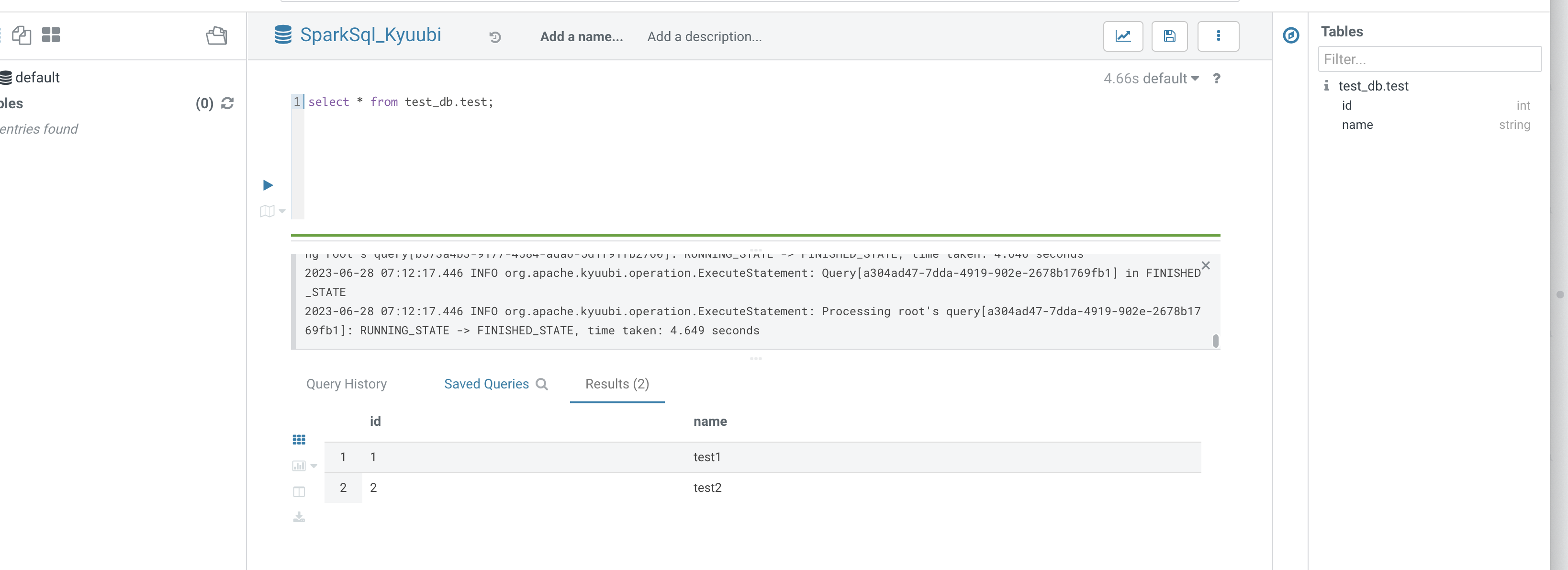
JDBC 提交 Hive Spark
1. 如果您需要使用外网 IP 连接 hiveserver,请在集群服务 > Hive > HiveServer2 > 操作 > 更多 > 开启网络访问中开启 hiveserver2外网。
2. 如果使用外网链接,需要到集群信息中查看安全组,前往云服务器 > 安全组中编辑该安全组,为7001端口放开客户端 IP 的访问,若使用内网访问,则可跳过1,2步骤。
使用 maven 编写 jdbc 代码
首先在 pom.xml 中引入以下 jdbc 所需依赖:
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>2.3.7</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.8.5</version></dependency>
引入以下打包和编译插件:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.8</source><target>1.8</target><encoding>utf-8</encoding></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
新建 HiveJdbcTest.java 如下:
package org.apache.hive;import java.sql.*;/*** Created by tencent on 2023/6/20.*/public class HiveJdbcTest {private static String driverName ="org.apache.hive.jdbc.HiveDriver";public static void main(String[] args)throws SQLException {try {Class.forName(driverName);} catch (ClassNotFoundException e) {e.printStackTrace();System.exit(1);}Connection con = DriverManager.getConnection("jdbc:hive2://$hs2host:7001/test_db", "hadoop", "");Statement stmt = con.createStatement();String tableName = "test_jdbc";stmt.execute("drop table if exists " + tableName);stmt.execute("create table " + tableName +" (key int, value string)");System.out.println("Create table success!");// show tablesString sql = "show tables '" + tableName + "'";System.out.println("Running: " + sql);ResultSet res = stmt.executeQuery(sql);if (res.next()) {System.out.println(res.getString(1));}// describe tablesql = "describe " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(res.getString(1) + "\\t" + res.getString(2));}sql = "insert into " + tableName + " values (42,\\"hello\\"),(48,\\"world\\")";stmt.execute(sql);sql = "select * from " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(String.valueOf(res.getInt(1)) + "\\t"+ res.getString(2));}sql = "select count(1) from " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(res.getString(1));}}}
将代码中的 $hs2host 替换为您的 hiveserver2 地址。
该程序会在 test_db 中创建 test_jdbc 表,写入两条数据并查询输出该数据。执行下面的命令对整个工程打包:
mvn package
上传 jar 并运行
将上述命令打包的 jar 上传到可以访问到 hiveserver2 服务的机器或者本地(如果是本地,则保证能正常访问 hiveserver2),通过以下命令运行:
java -classpath ${package}-jar-with-dependencies.jar org.apache.hive.HiveJdbcTest
其中 package 为您自定义的 artifactId-version。运行结果如下:
Create table success!Running: show tables 'test_jdbc'test_jdbcRunning: describe test_jdbckey intvalue stringRunning: select * from test_jdbc42 hello48 worldRunning: select count(1) from test_jdbc2
JDBC 提交 Kyuubi Spark
1. 如果您需要使用外网 IP 连接 KyuubiServer,请在集群服务 >Kyuubi > KyuubiServer > 操作 > 更多 > 开启网络访问中开启 KyuubiServer 外网。
2. 如果使用外网链接,需要到集群信息中查看安全组,前往云服务器 > 安全组中编辑该安全组,为10009端口放开客户端 IP 的访问,若使用内网访问,则可跳过1,2步骤。
使用 maven 编写 jdbc 代码
jdbc 依赖和打包插件配置与 JDBC 提交 Hive Spark 中一致。需要创建创建 KyuubiJdbcTest.java,内容如下:
package org.apache.hive;import java.sql.*;/*** Created by tencent on 2023/6/20.*/public class KyuubiJdbcTest {private static String driverName ="org.apache.hive.jdbc.HiveDriver";public static void main(String[] args)throws SQLException {try {Class.forName(driverName);} catch (ClassNotFoundException e) {e.printStackTrace();System.exit(1);}Connection con = DriverManager.getConnection("jdbc:hive2://$kyuubihost:10009/test_db", "hadoop", "");Statement stmt = con.createStatement();String tableName = "test_kyuubi";stmt.execute("drop table if exists " + tableName);stmt.execute("create table " + tableName +" (key int, value string)");System.out.println("Create table success!");// show tablesString sql = "show tables '" + tableName + "'";System.out.println("Running: " + sql);ResultSet res = stmt.executeQuery(sql);if (res.next()) {System.out.println(res.getString(1));}// describe tablesql = "describe " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(res.getString(1) + "\\t" + res.getString(2));}sql = "insert into " + tableName + " values (42,\\"hello\\"),(48,\\"world\\")";stmt.execute(sql);sql = "select * from " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(String.valueOf(res.getInt(1)) + "\\t"+ res.getString(2));}sql = "select count(1) from " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(res.getString(1));}}}
将代码中的 $kyuubihost 替换为您的 kyuubiserver 地址。
该程序会在 test_db 中创建 test_jdbc 表,写入两条数据并查询输出该数据。执行下面的命令对整个工程打包:
mvn package
上传 jar 并运行
上传过程与 JDBC 提交 Hive Spark 中一致,通过以下命令运行 KyuubiJdbcTest:
java -classpath ${package}-jar-with-dependencies.jar org.apache.hive.KyuubiJdbcTest其中package为您自定义的artifactId-version。运行结果如下:Create table success!Running: show tables 'test_kyuubi'test_dbRunning: describe test_kyuubikey intvalue stringRunning: select * from test_kyuubi42 hello48 worldRunning: select count(1) from test_kyuubi2
销毁集群
当创建的集群不再使用时,可以销毁集群,退还关联资源;销毁集群将强制终止集群所提供的服务,并释放关联资源。
在 EMR on TKE 页面,选择目标集群的更多中的销毁;在弹出的对话框中,单击立即销毁。



