功能介绍
Spark on Yarn 使用 Yarn 作为资源调度器,在 Hadoop2.7.2 之后 Yarn 在容器调度器 Capacity Scheduler 基础上增加了标签调度。
Capacity Scheduler 是一个多租户资源调度器,其核心思想是 Hadoop 集群中的可用资源由多个组织共享,这些组织根据自己的计算需求共同为集群提供计算能力。Capacity Scheduler 具有分层队列、容量保证、安全性、弹性资源、多租户、基于资源的调度、映射等特性。集群的所有资源全部分配给多个队列,提交到队列的所有应用程序都可以使用分配给队列的资源,其他组织未使用的空闲资源可以非抢占式地分配给运行低于容量的队列上的应用程序,确保应用程序获得资源容量下限的同时能弹性的满足不同应用程序的资源需求。
Capacity Scheduler 将集群资源粗略地分配给不同的队列,不能指定队列中应用程序的运行位置。标签调度在 Capacity Scheduler 之上通过给集群各节点打上不同的 Node Label 进行更细粒度的资源划分,应用程序可以指定运行的位置。节点标签具有以下特点:
1. 一个节点只有一个节点标签(也即属于一个节点分区),集群按节点分区被划分为多个不相交的子集群。
2. 根据匹配策略,节点分区具有两种类型:独占和非独占。独占的节点分区将容器分配给完全匹配节点分区的节点;非独占的节点分区将空闲资源共享给请求 default 分区的容器。
3. 每个队列通过设置可访问的节点标签来指定应用程序运行的节点分区。
4. 可以设置每个节点分区内不同队列的资源占比。
5. 在资源请求中指定所需的节点标签,仅在节点具有相同标签时才分配。如果未指定节点标签要求(可通过配置项修改队列的默认标签名),则仅在属于 default 分区的节点上分配此类资源请求。
配置说明
1. 设置 ResourceManager 启用 Capacity Scheduler
标签调度无法单独使用,只能配合 Capacity Scheduler 使用。Yarn 使用 Capacity Scheduler 作为默认调度器,如果您现在正使用其他调度器,请先启动 Capacity Scheduler。在
${HADOOP_HOME}/etc/hadoop/yarn-site.xml 中设置:<property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value></property>
2. 配置 Capacity Scheduler 参数
在
${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml 中设置 yarn.scheduler.capacity.root 是 Capacity Scheduler 预定义的根队列,其他队列均为根队列的子队列。所有队列以树的形式组织。yarn.scheduler.capacity.<queue-path>.queues 用于设置 queue-path 路径下的子队列,使用逗号分隔。示例:
<property><name>yarn.scheduler.capacity.root.queues</name><value>q1,q2,q3</value></property><property><name>yarn.scheduler.capacity.root.q1.queues</name><value>q11,q12</value></property><property><name>yarn.scheduler.capacity.root.q2.queues</name><value>q21,q22</value></property>
其他 Capacity Scheduler 配置请查询文档。
3. 设置 ResourceManager 启用 Node Label
在
yarn-site.xml中设置。<property><name>yarn.node-labels.fs-store.root-dir</name><value>hdfs://namenode:port/path-to-store/node-labels/</value></property><property><name>yarn.node-labels.enabled</name><value>true</value></property><property><name>yarn.node-labels.configuration-type</name><value>centralized or delegated-centralized or distributed</value></property>
注意
1. 确保已创建
yarn.node-labels.fs-store.root-dir,且 ResourceManager 有权访问。2. 若将节点标签保存在 RM 的本地文件系统,可使用
file://home/yarn/node-label 等路径。但是为了保证集群的高可用,避免 RM 宕机而丢失标签信息,建议将标签信息保存在 HDFS 上。3. 在 hadoop2.8.2 下需要配置
yarn.node-labels.configuration-type 配置项。4. 配置 Node Label
在
etc/hadoop/capacity-scheduler.xml中设置。配置项 | 描述 |
yarn.scheduler.capacity. <queue-path>.capacity | 设置队列可以访问属于 DEFAULT 分区的节点的百分比。每个 parent 队列下直接子队列的 DEFAULT 容量总和必须等于100。 |
yarn.scheduler.capacity. <queue-path>.accessible-node-labels | 设置队列可以访问的特定标签列表,用逗号分隔,如“HBASE,STORM”意味着队列可以访问标签 HBASE 和 STORM。所有队列都可以在没有标签的情况下访问节点,如果不指定此字段,则将从其父字段继承。如果用户想限制队列仅访问没有标签的节点,该字段只需留空即可。 |
yarn.scheduler.capacity. <queue-path>.accessible-node-labels.<label>.capacity | 设置队列可以访问属于 <label>分区的节点百分比。每个 parent 队列下直接子队列的<label>容量总和必须等于100,默认为0。 |
yarn.scheduler.capacity. <queue-path>.accessible-node-labels.<label>.maximum-capacity | 与 Capacity Scheduler 配置项 yarn.scheduler.capacity. <queue-path>.maximum-capacity 类似,它指定了<queue-path>在<label>分区的最大容量,默认为100。 |
yarn.scheduler.capacity. <queue-path>.default-node-label-expression | 当资源请求未指定节点标签时,应用将被提交到该值对应的分区。默认情况下,该值为空,即应用程序将被分配没有标签的节点上的容器。 |
应用示例
准备工作
1. 准备集群
确认您已经开通了腾讯云,并且创建了一个 EMR 集群。
2. 检查 YARN 组件配置
在“集群服务”页面中,选择 YARN 组件进入组件管理界面,然后切换至配置管理标签页,修改
yarn-site.xml中相关参数,保存并重启所有 YARN 组件。在角色管理标签页确认 ResourceManager 服务所在节点 IP,之后切换至配置管理标签页修改yarn-site.xml中相关参数,保存并重启所有 YARN 组件。在集群列表中单击集群实例 ID,进入集群信息页面,然后单击左侧菜单栏集群服务,选择 YARN 组件管理中操作 > 配置管理。
确认 RM 的 IP 地址。
在 YARN 组件“配置管理”页面,选择维度为节点维度,选择节点为 RM 的 IP 地址,单击编辑配置修改 RM 所在节点
yarn-site.xml的yarn.resourcemanager.scheduler.class参数。
在 Capacity-Scheduler.xml 中配置 Node Label 与队列的映射关系和占比
1. 创建存储节点标签的 HDFS 目录。

2. 在
core-site.xml中获取 NN 的 IP 和 Port。
3. 在 master 节点
yarn-site.xml中新建配置项后,重启 ResourceManager。
4. 使用
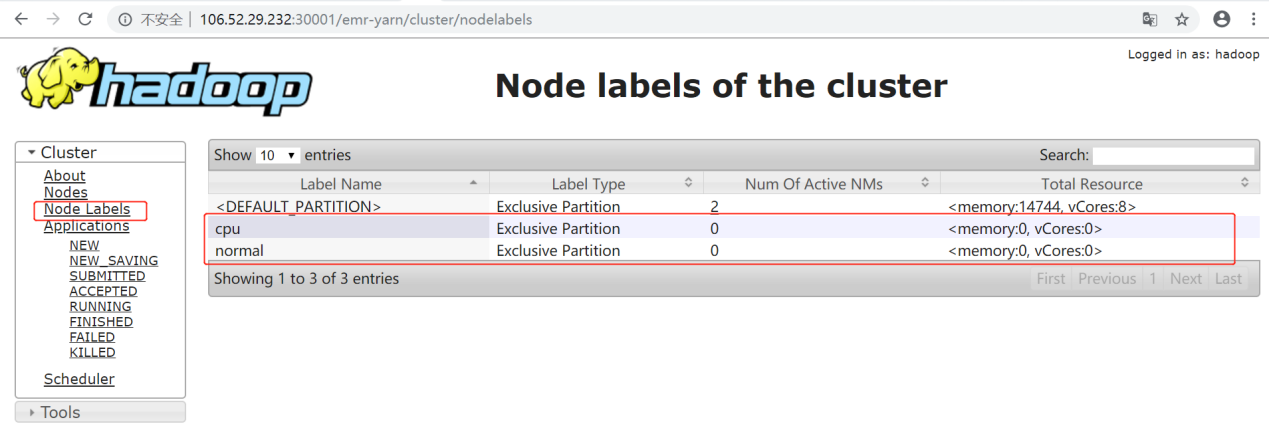
yarn rmadmin -addToClusterNodeLabels命令新增标签。
5. 使用
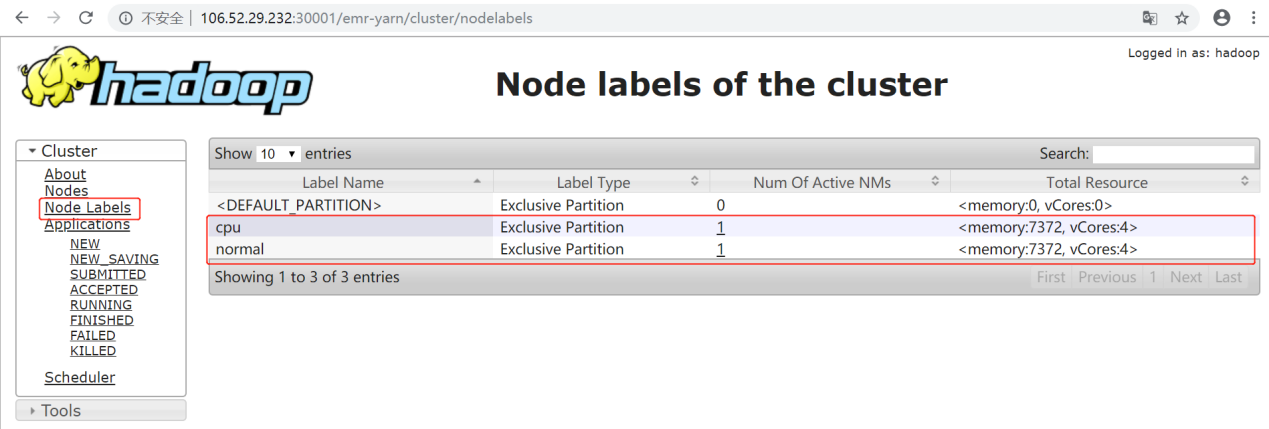
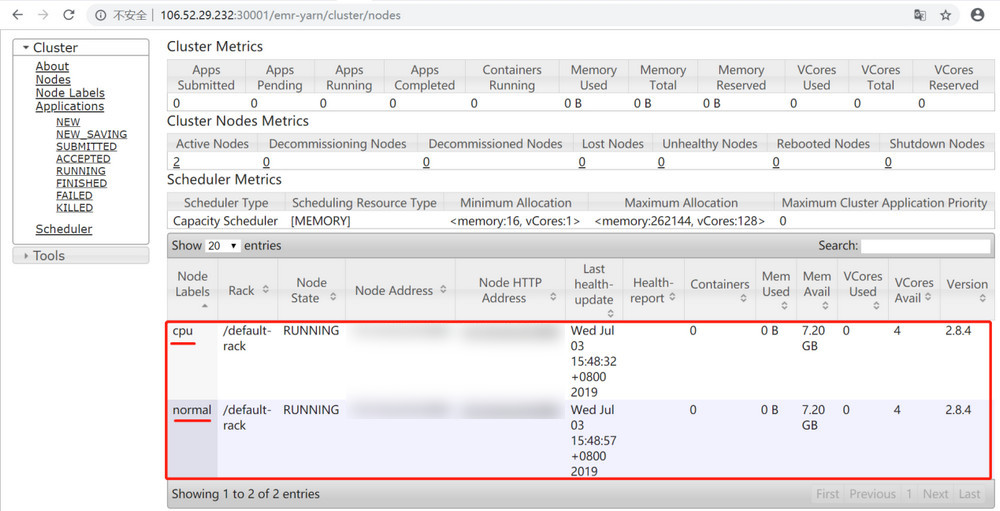
yarn rmadmin -replaceLabelsOnNode命令给节点打标签。
6. 编辑
capacity-scheduler.xml中的配置项,配置集群队列、队列的资源占比和队列的可访问标签。示例如下:<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.8</value></property><property><name>yarn.scheduler.capacity.maximum-applications</name><value>1000</value></property><property><name>yarn.scheduler.capacity.root.queues</name><value>default,dev,product</value></property><property><name>yarn.scheduler.capacity.root.default.capacity</name><value>20</value></property><property><name>yarn.scheduler.capacity.root.dev.capacity</name><value>40</value></property><property><name>yarn.scheduler.capacity.root.product.capacity</name><value>40</value></property><property><name>yarn.scheduler.capacity.root.accessible-node-labels.cpu.capacity</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.accessible-node-labels.normal.capacity</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.accessible-node-labels</name><value>*</value></property><property><name>yarn.scheduler.capacity.root.dev.accessible-node-labels.normal.capacity</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.product.accessible-node-labels.cpu.capacity</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.dev.accessible-node-labels</name><value>normal</value></property><property><name>yarn.scheduler.capacity.root.dev.default-node-label-expression</name><value>normal</value></property><property><name>yarn.scheduler.capacity.root.product.accessible-node-labels</name><value>cpu</value></property><property><name>yarn.scheduler.capacity.root.product.default-node-label-expression</name><value>cpu</value></property><property><name>yarn.scheduler.capacity.normal.sharable-partitions</name><value>cpu</value></property><property><name>yarn.scheduler.capacity.normal.require-other-partition-resource</name><value>true</value></property><property><name>yarn.scheduler.capacity.cpu.sharable-partitions</name><value></value></property><property><name>yarn.scheduler.capacity.cpu.require-other-partition-resource</name><value>true</value></property></configuration>
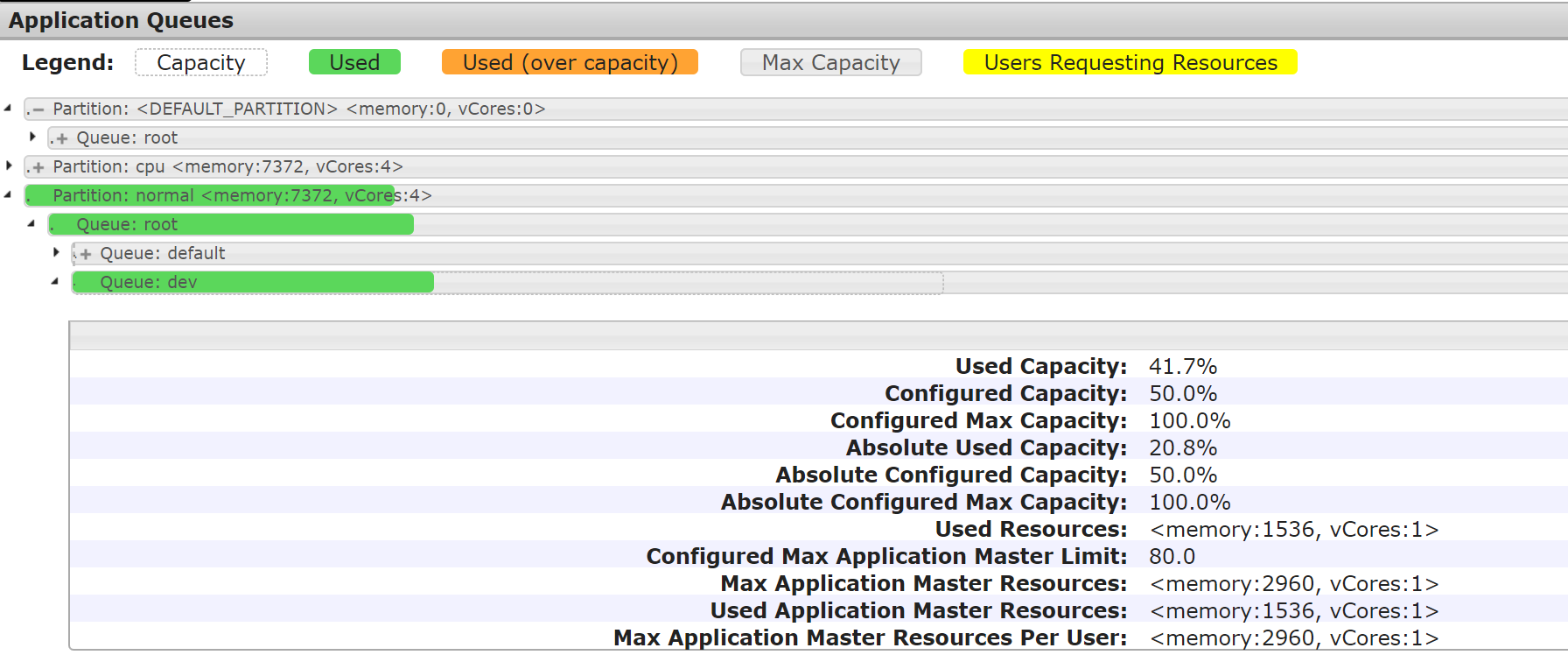
在 Scheduler 面板中可以看到,测试集群的3个分区、分区资源分配情况、包含队列情况。在 Application Queues 面板中,共有3个分区:default、normal、cpu,其中 default 分区是默认分区,normal 分区是由带有 normal 标签的节点组成的分区、cpu 分区是由带有 cpu 标签的节点组成的分区。在测试环境中,共有两个节点,这两个节点分别被标记为 normal 和 cpu。单击分区左侧的+号,能够展开该分区中包含的队列。
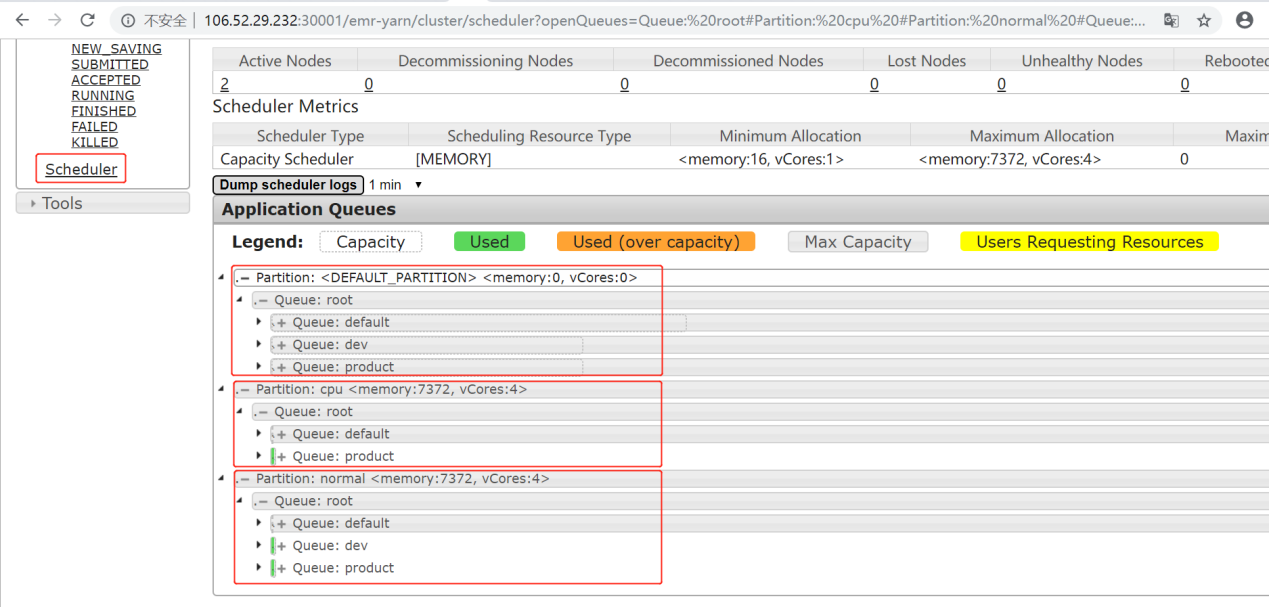
验证标签调度
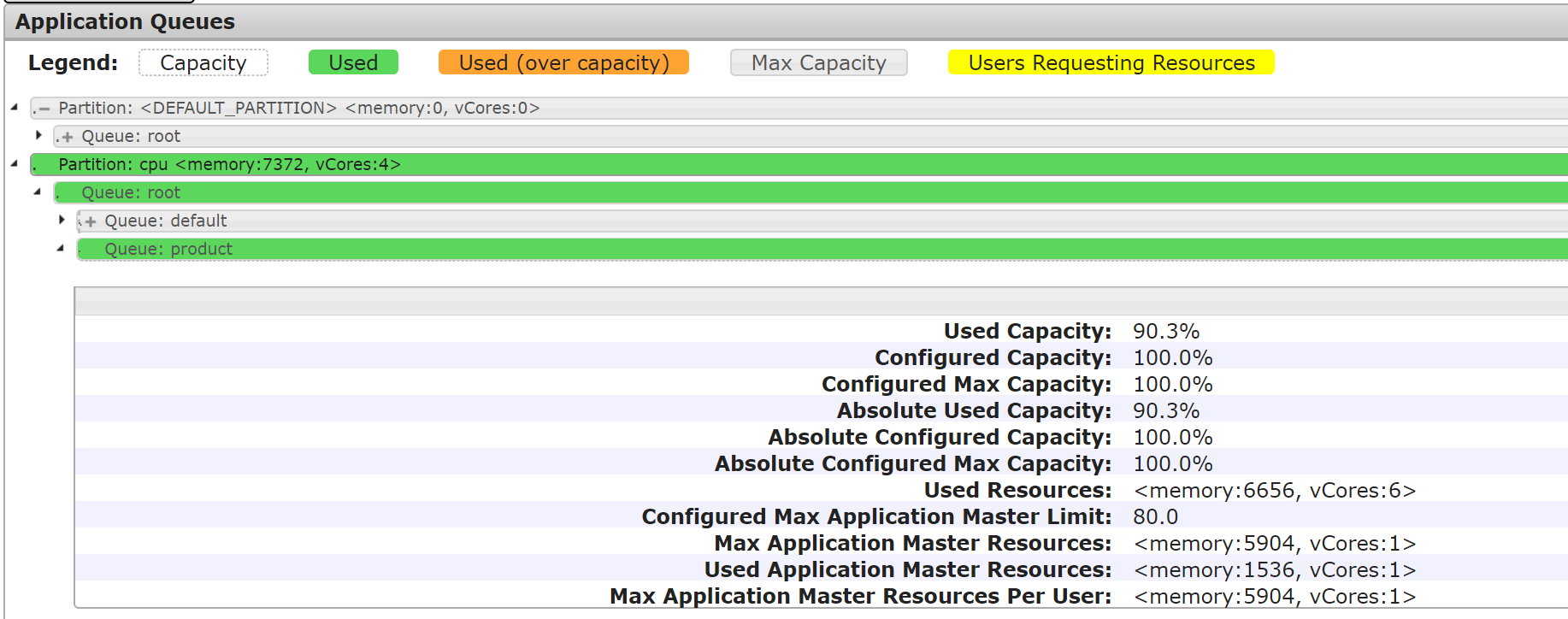
测试一:将任务提交到 product 队列
[hadoop@172 hadoop]$ cd /usr/local/service/hadoop[hadoop@172 hadoop]$ yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.8.4-tests.jar sleep -Dmapreduce.job.queuename=product -m 32 -mt 1000
任务提交后各分区的队列资源占用情况如下图所示:
测试二:将任务提交到 dev 队列
[hadoop@172 hadoop]$ cd /usr/local/service/hadoop[hadoop@172 hadoop]$ yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.8.4-tests.jar sleep -Dmapreduce.job.queuename=dev -m 32 -mt 1000
任务提交后各分区的队列资源占用情况如下图所示: