Demo 关键逻辑讲解
消息生产逻辑
下文首先对消息生产逻辑进行简要说明,有助于用户理解消费逻辑。
我们采用 Protobuf 进行序列化,各语言 Demo 中均附带有 Protobuf 定义文件。文件中定义了几个关键结构:Envelope 是最终发送的 Kafka 消息结构;Entry 是单个订阅事件结构;Entries 是 Entry 的集合。主要数据结构关系如下所示:
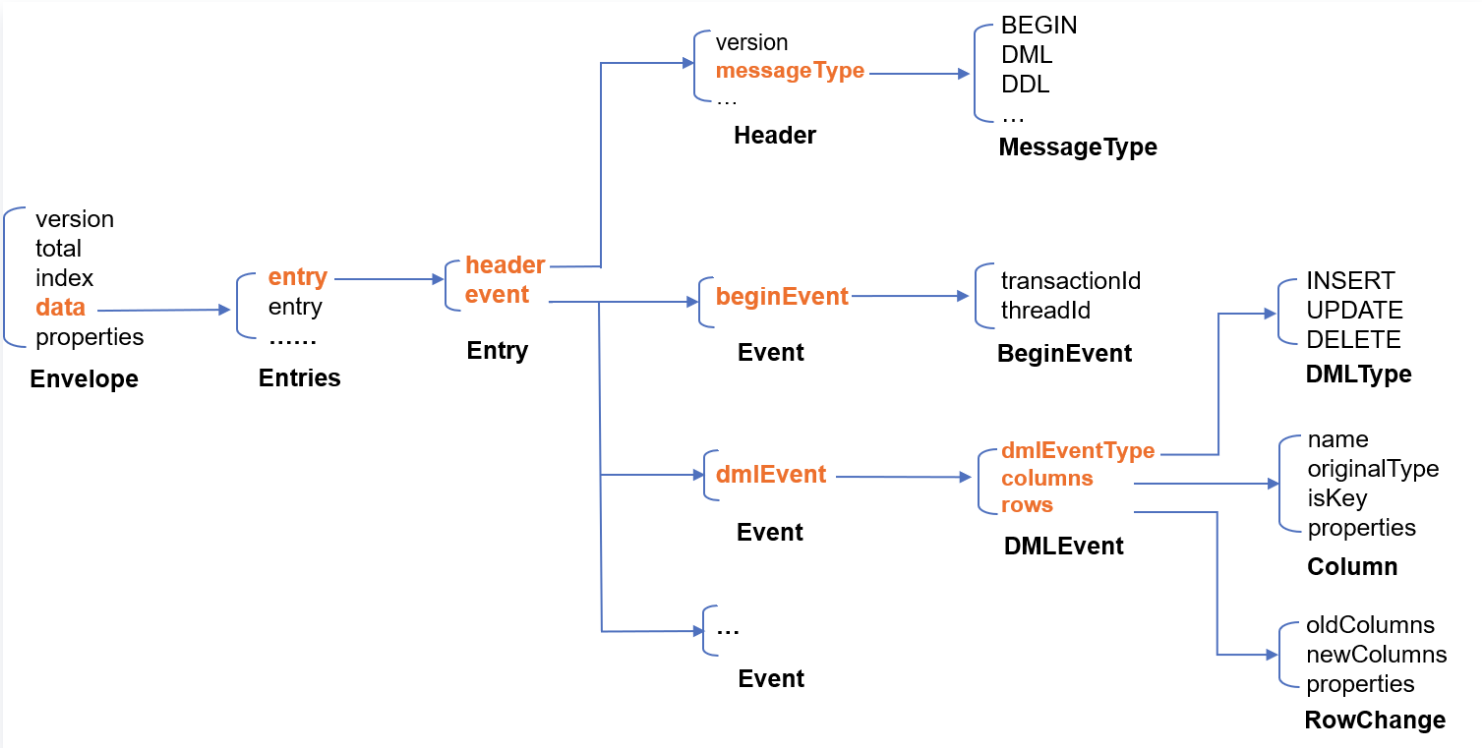
生产过程如下:
1. 拉取 Binlog 消息,将每个 Binlog Event 编码为一个 Entry 结构体。
message Entry { //Entry 是单个订阅事件结构,一个事件相当于 MySQL 的一个 binlog eventHeader header = 1; //事件头Event event = 2; //事件体}message Header {int32 version = 1; //Entry 协议版本SourceType sourceType = 2; //源库的类型信息,包括 MySQL,Oracle 等类型MessageType messageType = 3; //消息的类型,也就是 Event 的类型,包括 BEGIN、COMMIT、DML 等uint32 timestamp = 4; //Event 在原始 binlog 中的时间戳int64 serverId = 5; //源的 serverIdstring fileName = 6; //源 binlog 的文件名称uint64 position = 7; //事件在源 binlog 文件中的偏移量string gtid = 8; //当前事务的 gtidstring schemaName = 9; //变更影响的 schemastring tableName = 10; //变更影响的 tableuint64 seqId = 11; //全局递增序列号uint64 eventIndex = 12; //如果大的 event 分片,每个分片从0开始编号,当前版本无意义,留待后续扩展用bool isLast = 13; //当前 event 是否 event 分片的最后一块,是则为 true,当前版本无意义,留待后续扩展用repeated KVPair properties = 15;}message Event {BeginEvent beginEvent = 1; //binlog 中的 begin 事件DMLEvent dmlEvent = 2; //binlog 中的 dml 事件CommitEvent commitEvent = 3; //binlog 中的 commit 事件DDLEvent ddlEvent = 4; //binlog 中的 ddl 事件RollbackEvent rollbackEvent = 5; //rollback 事件,当前版本无意义HeartbeatEvent heartbeatEvent = 6; //源库定时发送的心跳事件CheckpointEvent checkpointEvent = 7; //订阅后台添加的 checkpoint 事件,每10秒自动生成一个,用于 Kafka 生产和消费位点管理repeated KVPair properties = 15;}
2. 为减少消息量,将多个 Entry 合并,合并后的结构为 Entries,Entries.items 字段即为 Entry 顺序列表。合并的数量以合并后不超过 Kafka 单个消息大小限制为标准。对单个 Event 就已超过大小限制的,则不再合并,Entries 中只有唯一 Entry 。
message Entries {repeated Entry items = 1; //entry list}
3. 对 Entries 进行 Protobuf 编码得到二进制序列。
4. 将 Entries 的二进制序列放入 Envelope 的 data 字段。当存在单个 Binlog Event 过大时,二进制序列可能超过 Kafka 单个消息大小限制,此时我们会将其分割为多段,每段装入一个 Envelope。
Envelope.total 和 Envelope.index 分别记录总段数和当前 Envelope 的序号(从0开始)。
message Envelope {int32 version = 1; //protocol version, 决定了 data 内容如何解码uint32 total = 2;uint32 index = 3;bytes data = 4; //当前 version 为1, 表示 data 中数据为 Entries 被 PB 序列化之后的结果repeated KVPair properties = 15;}
5. 对上一步生成的一个或多个 Envelope 依次进行 Protobuf 编码,然后投递到 Kafka 分区。同一个 Entries 分割后的多个 Envelope 顺序投递到同一个分区。
消息消费逻辑
下文对消费逻辑进行简要说明。我们提供的三种语言的 Demo 均遵循相同的流程。
1. 创建 Kafka 消费者。
2. 启动消费。
3. 依次消费原始消息,并根据消息中的分区找到分区对应的 partitionMsgConsumer 对象,由该对象对消息进行处理。
4. partitionMsgConsumer 将原始消息反序列化为 Envelope 结构。
// 将 Kafka 消息的 Value 值转换为 Envelopeenvelope := subscribe.Envelope{}err := proto.Unmarshal(msg.Value, &envelope)
5. partitionMsgConsumer 根据 Envelope 中记录的 index 和 total 连续消费一条或者多条消息,直到 Envelope.index 等于 Envelope.total-1(参见上面消费生产逻辑,表示收到了一个完整的 Entries )。
6. 将收到的连续多条 Envelope 的 data 字段顺序组合到一起。将组合后的二进制序列用 Protobuf 解码为 Entries 。
if envelope.Index == 0 {pmc.completeMsg = envelope} else {// 对进行过拆分的 Entries 二进制序列做拼接pmc.completeMsg.Data = append(pmc.completeMsg.Data, envelope.Data...)}if envelope.Index < envelope.Total-1 {return nil}// 将 Envelope.Data 反序列化为 Entriesentries := subscribe.Entries{}err = proto.Unmarshal(pmc.completeMsg.Data, &entries)
7. 对 Entries.items 依次处理,打印原始 Entry 结构或者转化为 SQL 语句。
8. 当消费到 Checkpoint 消息时,做一次 Kafka 位点提交。Checkpoint 消息是订阅后台定时写入 Kafka 的特殊消息,每10秒一个。
数据库字段映射和存储
本节介绍数据库字段类型和序列化协议中定义的数据类型之间的映射关系。
源数据库(如 MySQL)字段值在 Protobuf 协议中用如下所示的 Data 结构来存储。
message Data {DataType dataType = 1;string charset = 2; //DataType_STRING 的编码类型, 值存储在 bv 里面string sv = 3; //DataType_INT8/16/32/64/UINT8/16/32/64/Float32/64/DataType_DECIMAL 的字符串值bytes bv = 4; //DataType_STRING/DataType_BYTES 的值}
其中 DataType 字段代表存储的字段类型,可取枚举值如下图所示。
enum DataType {NIL = 0; //值为 NULLINT8 = 1;INT16 = 2;INT32 = 3;INT64 = 4;UINT8 = 5;UINT16 = 6;UINT32 = 7;UINT64 = 8;FLOAT32 = 9;FLOAT64 = 10;BYTES = 11;DECIMAL = 12;STRING = 13;NA = 14; //值不存在 (N/A)}
其中 bv 字段存储 STRING 和 BYTES 类型的二进制表示,sv 字段存储 INT8/16/32/64/UINT8/16/32/64/DECIMAL 类型的字符串表示,charset 字段存储 STRING 的编码类型。
MySQL/TDSQL 原始类型与 DataType 映射关系如下(对 UNSIGNED 修饰的 MYSQL_TYPE_INT8/16/24/32/64 分别映射为 UINT8/16/32/32/64):
说明:
1. 关于时区的相关说明。
DATE,TIME,DATETIME 类型不支持时区。TIMESTAMP 类型支持时区,该类型字段表示:存储时,系统会从当前时区转换为 UTC(Universal Time Coordinated)进行存储;查询时,系统会从 UTC 转换为当前时区进行查询。综上,如下表中 "MYSQL_TYPE_TIMESTAMP" 和 "MYSQL_TYPE_TIMESTAMP_NEW" 字段会携带时区信息,用户在消费数据时可自行转换。(例如,DTS 输出的时间格式是带时区的字符串"2021-05-17 07:22:42 +00:00",其中,"+00:00"表示 UTC 时间,用户在解析和转换的时候需要考虑时区信息。)
2. 对于源端 MySQL 的数值类型,DTS 写入 Kafka 时会转为字符串类型,其中 FLOAT 和 DOUBLE 类型在转为字符串时如果绝对值小于 1e-4 或大于等于 1e+6,那么结果将使用科学计数法表示。科学计数法以尾数乘以10的幂的形式表示浮点数,这样可以更清晰地表示其数量级和精确值,同时能够节省存储空间。如果在消费端用户需要转换为数值类型,请注意对科学记数法表示的浮点数字符串做特殊处理。
MySQL 字段类型(TDSQL 支持与 MySQL 相同的类型) | 对应的 Protobuf DataType 枚举值 |
MYSQL_TYPE_NULL | NIL |
MYSQL_TYPE_INT8 | INT8 |
MYSQL_TYPE_INT16 | INT16 |
MYSQL_TYPE_INT24 | INT32 |
MYSQL_TYPE_INT32 | INT32 |
MYSQL_TYPE_INT64 | INT64 |
MYSQL_TYPE_BIT | INT64 |
MYSQL_TYPE_YEAR | INT64 |
MYSQL_TYPE_FLOAT | FLOAT32 |
MYSQL_TYPE_DOUBLE | FLOAT64 |
MYSQL_TYPE_VARCHAR | STRING |
MYSQL_TYPE_STRING | STRING |
MYSQL_TYPE_VAR_STRING | STRING |
MYSQL_TYPE_TIMESTAMP | STRING |
MYSQL_TYPE_DATE | STRING |
MYSQL_TYPE_TIME | STRING |
MYSQL_TYPE_DATETIME | STRING |
MYSQL_TYPE_TIMESTAMP_NEW | STRING |
MYSQL_TYPE_DATE_NEW | STRING |
MYSQL_TYPE_TIME_NEW | STRING |
MYSQL_TYPE_DATETIME_NEW | STRING |
MYSQL_TYPE_ENUM | STRING |
MYSQL_TYPE_SET | STRING |
MYSQL_TYPE_DECIMAL | DECIMAL |
MYSQL_TYPE_DECIMAL_NEW | DECIMAL |
MYSQL_TYPE_JSON | BYTES |
MYSQL_TYPE_BLOB | BYTES |
MYSQL_TYPE_TINY_BLOB | BYTES |
MYSQL_TYPE_MEDIUM_BLOB | BYTES |
MYSQL_TYPE_LONG_BLOB | BYTES |
MYSQL_TYPE_GEOMETRY | BYTES |



