磁盘 IO 精细调度能力提供了一系列功能,保证业务磁盘方面的服务质量保证。灵活限制容器对磁盘传输的使用量。
使用限制
1. 部署 QoS Agent。
2. 在集群里的组件管理页面,找到部署成功的 QoS Agent,单击右侧的更新配置。
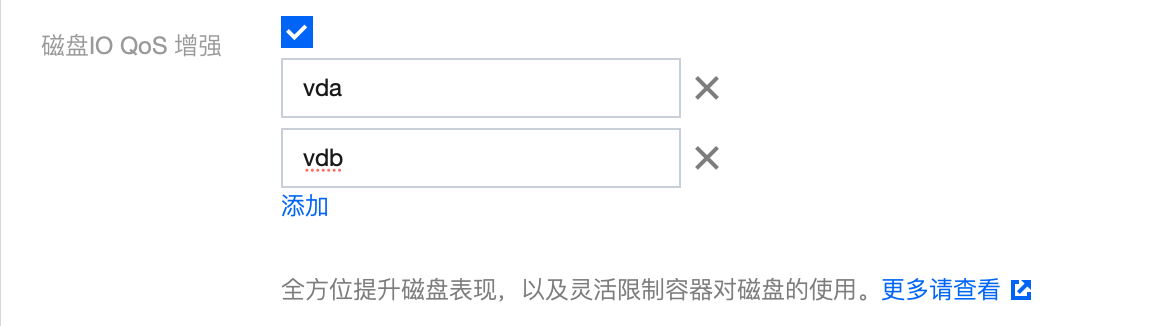
3. 在修改 QoS Agent 的组件配置页面,勾选磁盘 IO QoS 增强。
4. 输入参数指定限制的磁盘名称,如下图所示,可输入多个:
注意:
1. 磁盘名要符合实际设备名称,获取节点磁盘名称的方式请参见 如何确定节点的磁盘名。
2. 在控制台输入时,每次输入一个磁盘设备的名称,请单击添加,增加新的磁盘名称。请勿一次性输入多个磁盘名称。
3. 如果节点上缺少对应的磁盘名,则磁盘 IO 精细调度无法生效。
4. 非原生不支持该功能,请确保集群中有原生节点,并且配置了磁盘 IO 限制的 Pod 调度到了原生节点上。
5. 单击完成。
功能1:磁盘 IOPS 限制(direct IO + buffer IO)
1. 根据上述使用限制部署组件、打开相关开关、输入相关磁盘名称。
2. 部署业务。
3. 部署关联该业务的 PodQOS 对象,选择需要作用的业务,示例如下:
apiVersion: ensurance.crane.io/v1alpha1kind: PodQOSmetadata:name: aspec:labelSelector:matchLabels:k8s-app: a # 选择业务的 LabelresourceQOS:diskIOQOS:diskIOLimit:readIOps: 1024 # readIOps 代表限制 Pod 读 IO 的量,单位为 IOPS/swriteIOps: 1024 # writeIOps 代表限制 Pod 写 IO 的量,单位为 IOPS/s
针对 buffer IO 的限速机制
由于低版本内核或 cgroup v1 对 Buffer IO 无法有效限速,有可能造成 Buffer IO 干扰业务正常 IO(数据库场景经常使用direct IO)。TKE 基于 cgroup v1 提供了 Buffer IO 限速功能。基于 cgroup v2 的 Buffer IO 限速和上游内核保持一致。
cgroup v1 无法支持限速的主要原因在于异步刷脏页的时候,内核无法得知这个 IO 应该提交给哪个 blkio cgroup。示例如下:
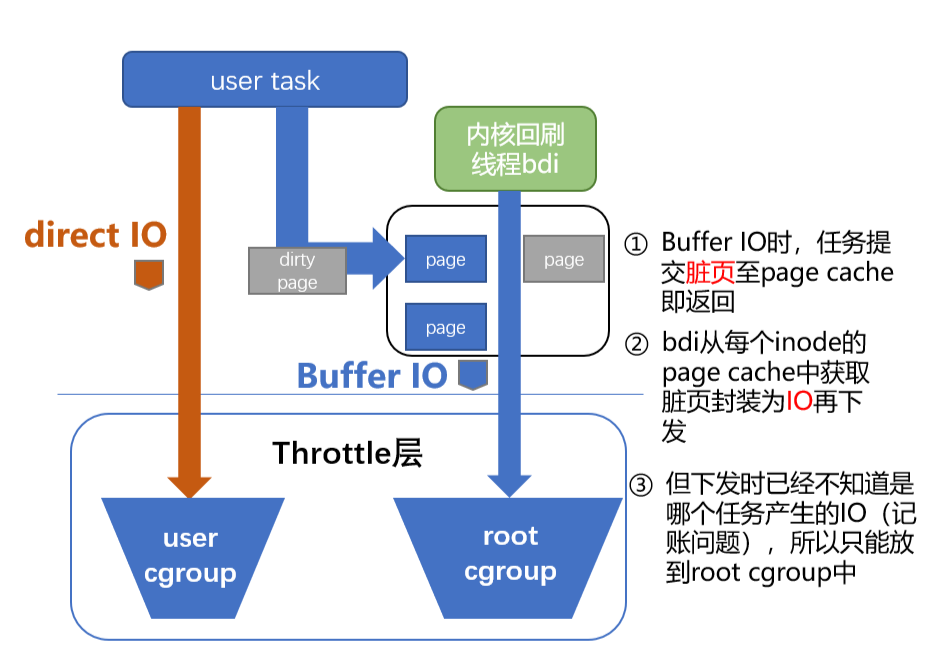
为了解决这个记账问题,TKE 将 page cache 所属的 cgroup 和对应的 blkio cgroup 进行绑定。之后异步刷盘时,内核线程便可以确定目标 blkio cgroup。
功能2:磁盘 BPS 限制(direct IO + buffer IO)
1. 根据上述使用限制部署组件、打开相关开关、输入相关磁盘名称。
2. 部署业务。
3. 部署关联该业务的 PodQOS 对象,选择需要作用的业务,示例如下:
apiVersion: ensurance.crane.io/v1alpha1kind: PodQOSmetadata:name: aspec:labelSelector:matchLabels:k8s-app: aresourceQOS:diskIOQOS:diskIOLimit:readBps: 1048576 # readBPS 限制 Pod 读带宽,单位为 mbpswriteBps: 1048576 # writeBPS 限制 Pod 写带宽,单位为 mbps
常见问题
如何确定节点的磁盘名?
1. 登录需要开启磁盘 IO 的原生节点,操作详情请参见 原生节点开启 SSH 密钥登录。
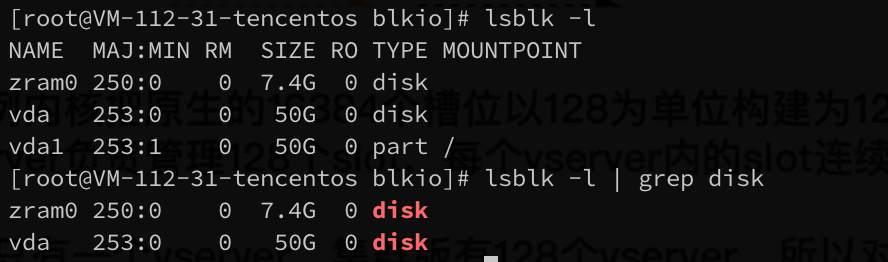
2. 执行以下命令,以获取所有的磁盘设备:
lsblk -l | grep disk
执行结果如下图所示:
注意:
1. 下图中的 zram0 是用于虚拟内存压缩的模块,不是磁盘名。
2. 下图中的 vda1 是一个 part 分区块,也不是磁盘名。
3. 下方示例仅展示了一个磁盘,其磁盘名为:vda。
社区 BFQ 问题可能导致原生节点内核 panic
建议:升级 QoS Agent 版本到1.1.2以上,以避免由于 Linux 社区内核 BFQ 模块的 bug 导致原生节点内核发生 panic。相关问题如下:
查询方案:您可以通过在节点上执行命令
cat /sys/block/[磁盘名称]/queue/scheduler 来确认调度策略,如果输出包含[bfq]字段,则表示已启用 BFQ,需要进行更改。修改方案:将调度策略更改为 mq-deadline。例如,如果磁盘名称为 vda,则可以使用以下方式进行修改:
echo mq-deadline > /sys/block/vda/queue/scheduler



