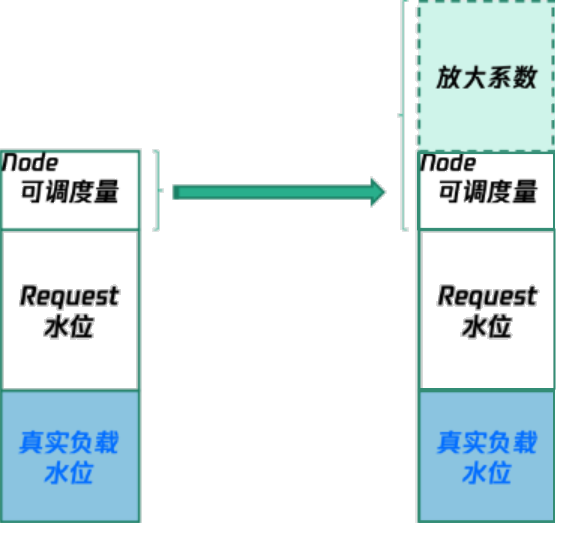
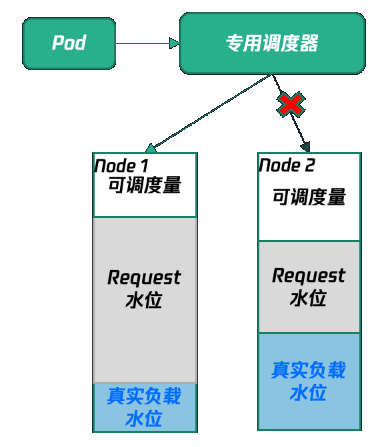
Kubernetes 的调度逻辑为按照 Pod 的 Request 进行调度。节点上的可调度资源会被 Pod 的 Request 量占用,且无法腾挪。原生节点专用调度器是容器服务 TKE 基于 Kubernetes 原生 Kube-scheduler Extender 机制实现的调度器插件,可以虚拟放大节点的容量,用来解决节点资源都被占用,但本身利用率很低的问题。
部署在集群内的 Kubernetes 对象
Kubernetes 对象名称
类型
请求资源
所属 Namespace
crane-scheduler-controller
Deployment
每个实例 CPU: 200m Memory:200Mi,共计1个实例
kube-system
crane-descheduler
Deployment
每个实例 CPU: 200m Memory:200Mi,共计1个实例
kube-system
crane-scheduler
Deployment
每个实例 CPU: 200m Memory:200Mi,共计3个实例
kube-system
crane-scheduler-controller
Service
-
kube-system
crane-scheduler
Service
-
kube-system
crane-scheduler
ClusterRole
-
kube-system
crane-descheduler
ClusterRole
-
kube-system
crane-scheduler
ClusterRoleBinding
-
kube-system
crane-descheduler
ClusterRoleBinding
-
kube-system
crane-scheduler-policy
ConfigMap
-
kube-system
crane-descheduler-policy
ConfigMap
-
kube-system
ClusterNodeResourcePolicy
CRD
-
-
CraneSchedulerConfiguration
CRD
-
-
NodeResourcePolicy
CRD
-
-
crane-scheduler-controller-mutating-webhook
MutatingWebhookConfiguration
-
-
应用场景
场景1:解决节点装箱率高但利用率低的问题
说明:
基本概念如下:
装箱率:节点上所有 Pod 的 Request 之和除以节点实际的规格。
利用率:节点上所有 Pod 的真实用量之和除以节点实际的规格。
Kubernetes 原生调度器是基于 Pod Request 资源进行调度,因此,即使此时节点上的真实用量很低,但节点上所有 Pod 的 Request 之和接近节点实际规格,也无法调度新的 Pod 上来,造成较大的资源浪费。并且,业务通常为了保证自己服务的稳定性,倾向申请过量的资源,即较大的 Request,导致节点资源被占用,无法腾挪。此时节点的装箱率很高,但实际资源利用率较低。
此时可以使用原生节点专用调度器,虚拟放大节点的 CPU 和内存的规格,使得节点可调度资源被虚拟放大,可以调度进更多的 Pod。示例图如下所示:
该组件卸载后,只会删除原生节点专用调度器有关调度逻辑,不会对原生 Kube-Scheduler 的调度功能有任何影响。原生节点上存量的 Pod 因为已经调度,不受影响。但原生节点上 kubelet 重启时,可能会引发 Pod 的驱逐,因为此时可能原生节点上 Pod 的 Request 之和可能大于原生真实的规格。
当调低放大系数时,原生节点上存量的 Pod 因为已经调度,不受影响。但原生节点上 kubelet 重启时,可能会引发 Pod 的驱逐,因为此时可能原生节点上 Pod 的 Request 之和可能大于原生节点当前放大后的规格。