概述
PlacementPolicy 是 TKE(Tencent Kubernetes Engine)提供的一种智能调度策略,旨在帮助用户在 Kubernetes 集群中更灵活地管理 Pod 的调度行为。通过 PlacementPolicy,用户可以根据业务需求自定义资源的优先级,实现扩容时优先使用高优先级节点,缩容时优先释放低优先级节点,从而在降本增效与业务稳定性之间找到最佳平衡点。该功能重点解决了原生 Kubernetes 调度器存在的以下痛点:
客户痛点
1. 业务场景与调度能力错配
1.1 K8s 原生调度以资源供需匹配为核心,缺乏对业务价值和业务语义(成本/性能/高可用)的抽象表达。
1.2 企业实际需求中的“业务目标→调度策略→资源分配”传导链断裂。
2. 云资源特性与调度策略割裂
云厂商 IaaS 层产品化节点特性未被纳入调度决策体系,例如:
节点类型:原生节点、超级节点、普通节点、注册节点等。
节点计费特性:包年包月、按量计费等。
3. 配置复杂度与用户体验矛盾
3.1 K8s 原生调度器提供原子化调度 API,需要用户根据业务语义自行组合使用,要求用户具备调度器内部实现知识,例如:污点、拓扑等。
3.2 K8s 原生调度策略变更的运维成本与业务连续性存在冲突,关注点未分离,调度策略变更对 workload 存在侵入,需要重建 Pod。
核心特性
智能成本优化
在业务扩容或重建时,PlacementPolicy 会优先使用低成本资源。在业务缩容时,优先释放高成本资源上的业务,进一步降低运营成本,提升资源利用效率。
高可用性保障
针对高可用性要求严格的业务(如核心交易系统、关键基础设施等),PlacementPolicy 能够在确保业务多可用区平均分布的同时,兼顾成本最优。
灵活调整调度规则
PlacementPolicy 允许用户在保证存量业务无损的前提下,仅针对新增或重建的 Pod 动态调整调度规则,避免对整个应用进行重建,从而降低运维复杂性和风险。
功能流程
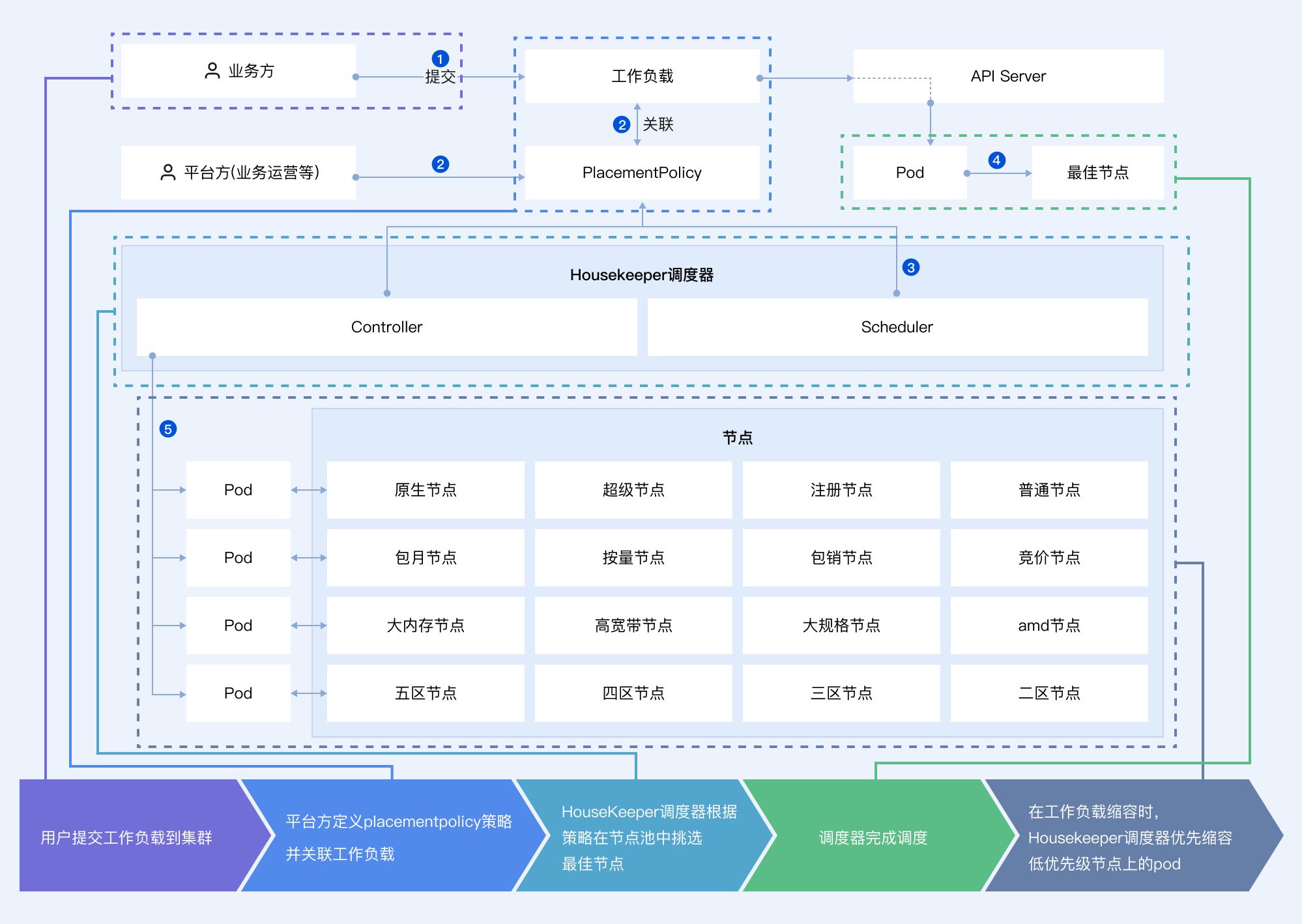
1. 提交工作负载:用户的业务方提交工作负载到集群。
2. 定义 PlacementPolicy:用户的平台方在集群中定义 PlacementPolicy,并将工作负载与之关联。
3. PlacementPolicy 调度:当工作负载扩容或者重建等需要调度场景时,TKE Crane 调度器根据 PlacementPolicy 定义,在节点池里挑选最佳节点。
4. Pod Bind:TKE Crane 调度器向 API Server 提交 Pod 的调度结果,进行绑定。
5. 控制 Pod 缩容顺序:TKE Crane 调度器根据 PlacementPolicy 定义,按需为 Pod 打上 pod-deletion-cost,控制 Pod 缩容的顺序。当工作负载缩容时,低优先级节点上的 Pod 会被优先销毁。
前提条件
1. 已创建 TKE 容器集群,并升级至目标版本。
2. 已安装 CraneScheduler 调度器,并升级至目标版本。CraneScheduler 组件的安装及升级操作请参见 组件的生命周期管理。
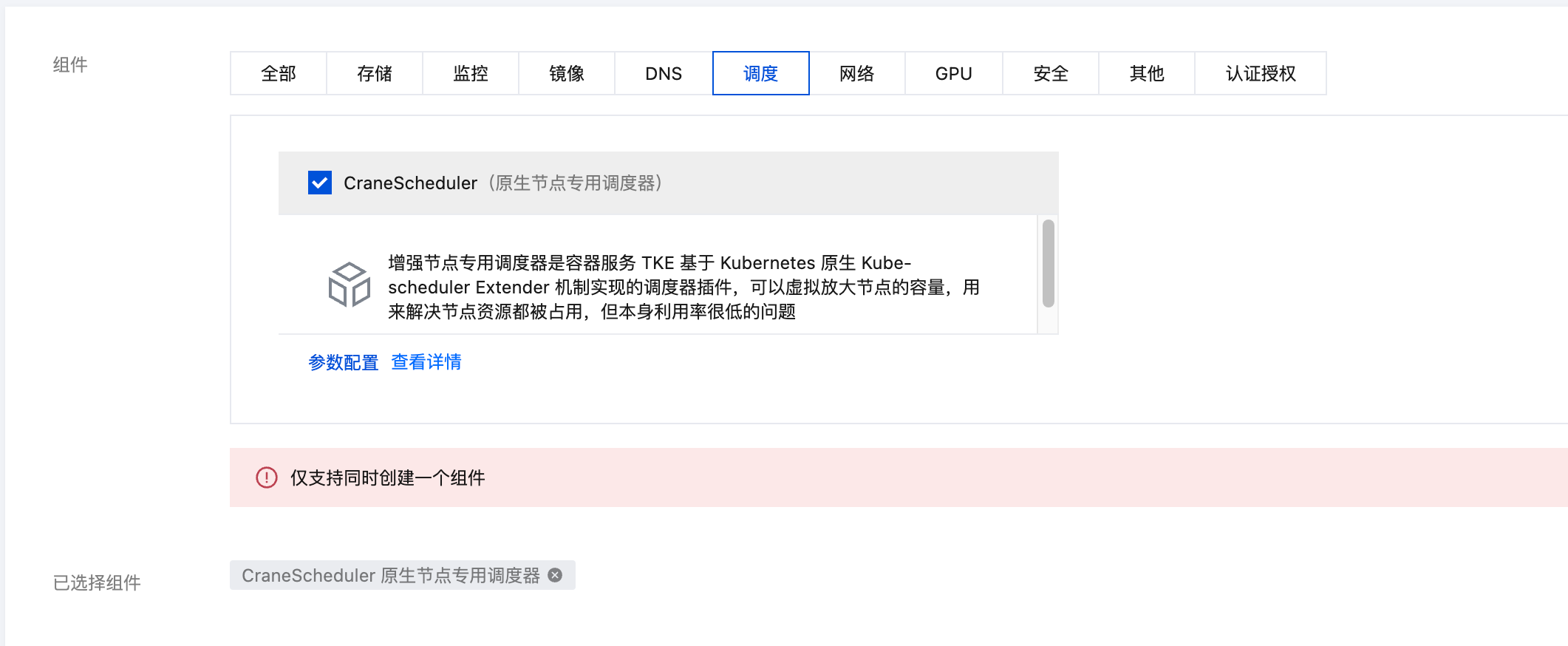
3. 版本要求:
TKE 集群版本要求:1.22 及以上版本。
CraneScheduler 调度器版本要求:1.6.0及以上版本。
使用限制
PlacementPolicy 支持的 TKE 节点类型:普通节点、原生节点、超级节点。
PlacementPolicy 支持的工作负载类型:
Pod 扩容场景:支持 TKE 全部类型的工作负载
Pod 缩容场景:仅支持 Deployment 类型的工作负载。
当开启节点池自动扩缩容能力时,并且您同时设置了 “DoNotSchedule” 和 “max” 字段,存在无法扩容节点的可能性。建议您开启节点池自动扩缩容能力时,尽量避免设置 “DoNotSchedule” 和 “max” 字段。PlacementPolicy 和 CA 的联动能力将持续优化。
本功能与 pod-deletion-cost 冲突,不能同时使用。关于 pod-deletion-cost 的更多信息,请查看 pod-deletion-cost。
按量计费模式的超级节点的优先级配置,需要先取消超级节点上的 taint,或为 Pod 添加忽略 taint 的 toleration。
kubectl taint node $SuperNodeName eks.tke.cloud.tencent.com/eklet-
使用方式
注意:
PlacementPolicy 是全局调度策略,优先级高于负载调度等其他策略。
创建 PlacementPolicy 定义弹性资源优先级
apiVersion: scheduling.crane.io/v1alpha1kind: PlacementPolicymetadata:name: testpolicyspec:targets:podSelectors:- matchExpressions:- key: appoperator: Invalues:- nginxnamespaces:include: #默认为空,空值代表选择全部。该值不能与exclude冲突。exclude: #默认为空,空值代表不排除任何namespaceworkloadRefs:- name: nginxnamespace: defaultkind: DeploymentapiVersion: apps/v1matchExpressions:- key: testkeyoperator: Invalues:- testvaluenodeGroups:- name: nativegroupsnodeType: nativenodeSelectorTerms:- matchExpressions:- key: node.tke.cloud.tencent.com/instance-charge-typeoperator: Invalues:- PrepaidChargenodeResourceFitStrategy:type: MostAllocatedresources:- name: cpuweight: 1- name: memoryweight: 1whenUnsatisfiable: ScheduleAnywaypriority: 100max: 4- name: supergroupsnodeType: superwhenUnsatisfiable: ScheduleAnywaypriority: 0
字段说明:
targets:选择该策略的生效范围,支持按 pod、workload、namespace 三种维度进行筛选。targets下的所有字段取交集。若全为空,表示选择集群中所有非 DaemonSet pod。
podSelectors:可选,通过 pod label 选择 pod,多个 matchExpressions 条件取并集。
matchExpressions:matchExpressions 若指定了多个key,需同时满足。
namespaces:可选,选择特定命名空间下的 namespace。
include: 默认为空,空值代表选择全部。该值不能与 exclude 冲突。支持数组。
exclude: 默认为空,空值代表不排除任何 namespace。支持数组。
workloadRefs:可选,选择特定的 workload 。支持指定 workload name、namespace、类型等条件筛选。
name:可选,为空表示不限制。
namespace:可选,为空表示不限制。
kind:可选,为空表示不限制,默认为非 DaemonSet pod,支持 Deployment,Statefulset,Job等。
apiVersion:可选,为空表示不限制。
matchExpressions:可选,为空表示不限制,该字段仅支持 Deployment。判断 Deployment 的 label 是否满足 matchExpressions。
nodeGroups:必选,指定被调度的资源分组和优先级。
name:必选,调度资源组名称。
nodeType:必选,指定该组的节点类型,可选值为 native, super, general;native 代表原生节点,super 代表超级节点,general 代表普通节点;一个调度资源组仅支持配置1个节点类型。
nodeSelectorTerms:可选,支持 nodeSelectorTerms 的方式选择节点,目前仅支持 matchExpressions 的表述方式,多个 matchExpressions 满足任一即可。
matchExpressions:matchExpressions 若指定了多个 key,需同时满足。
nodeResourceFitStrategy:可选,定义该节点组里根据节点资源情况计算节点的分数。不设置则表示默认不开启。它包含以下子字段:
type:必选,指定评分策略类型,可选值支持:LeastAllocated 和 MostAllocated;LeastAllocated 代表优先选择已分配资源较少的节点,MostAllocated 代表优先选择已分配资源较多的节点。
resources:可选,指定参与节点资源评分的资源名称(如 cpu、memory)以及每种资源在评分计算中的权重。由一个列表组成,每个元素包含以下两个字段:
name:资源名称(字符串)。可以是标准资源(如 cpu、memory),也可以是扩展资源(如 nvidia.com/gpu)。
weight:权重值(整数)。表示该资源在评分计算公式中的相对重要性,范围通常为 1 到 100。
whenUnsatisfiable:可选,定义无法满足该节点组约束时的行为。可选值支持:DoNotSchedule 和 ScheduleAnyway。默认为 ScheduleAnyway。
DoNotSchedule:如果无法满足该节点组约束,Pod 将保持在
Pending 状态,直到有足够的资源满足约束。ScheduleAnyway:即使无法满足节点组约束,Kubernetes 调度器仍然会尝试调度该 Pod 到不满足该约束的节点上。
priority:ScheduleAnyway 的子属性,指定该组的优先级,范围[0,1000]。
max:可选,该 Pod 所在的 workload 最多有N个副本在这个节点组,取值范围[0,1000]。该字段可用于高可用场景,如:指定 workload 在某个 zone 上最大副本数。也常用于降本场景,如:指定稳态资源池最大副本数,超出后调度至弹性节点池。
作用范围
命中 PlacementPolicy 策略的新建工作负载,将立刻生效。
命中 PlacementPolicy 策略的存量工作负载,对于新扩容的 Pod 将立刻生效;或者工作负载重建后全部生效。
当一个对象匹配多个 PlacementPolicy 策略时,优先级以创建时间最新的为准。
使用场景示例
场景一:降本场景(基于节点池的调度策略)
假设您在集群中使用了原生节点,并划分了两个节点池 pool1 和 pool2。出于业务考虑,您希望 Pod 优先调度到 pool1 节点池,资源不足时,再调度至 pool2 节点池。
步骤1:创建 PlacementPolicy 定义弹性资源优先级
apiVersion: scheduling.crane.io/v1alpha1kind: PlacementPolicymetadata:name: testpolicyspec:targets:namespaces:include:- defaultpodSelectors:- matchExpressions:- key: appoperator: Invalues:- nginxnodeGroups:- name: pool1nodeType: nativenodeSelectorTerms:- matchExpressions:- key: node.tke.cloud.tencent.com/machinesetoperator: Invalues:- np-9559uqj3whenUnsatisfiable: ScheduleAnywaypriority: 100- name: pool2nodeType: nativenodeSelectorTerms:- matchExpressions:- key: node.tke.cloud.tencent.com/machinesetoperator: Invalues:- np-eaw5t0enwhenUnsatisfiable: ScheduleAnywaypriority: 0
步骤2:部署业务(如 nginx)
注意:
应用需要满足 PlacementPolicy 中目标 targets 的要求,如在上述场景中:label 指定 key 为 app,value 为 nginx。
例如,使用以下 YAML 内容创建 Deployment,部署2个 Pod。
apiVersion: apps/v1kind: Deploymentmetadata:name: nginxlabels:app: nginxspec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:name: nginxlabels:app: nginxspec:containers:- env:- name: PATHvalue: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin- name: NGINX_VERSIONvalue: 1.27.4- name: NJS_VERSIONvalue: 0.8.9- name: NJS_RELEASEvalue: 1~bookworm- name: PKG_RELEASEvalue: 1~bookworm- name: DYNPKG_RELEASEvalue: 1~bookwormimage: ccr.ccs.tencentyun.com/halewang/nginx:1.27.4name: nginxresources:limits:cpu: 2requests:cpu: 2
执行以下命令,创建应用 Nginx。
kubectl apply -f nginx.yaml
执行以下命令,查看部署结果。
kubectl get pods -o wide
预期输出:
Pod 优先调度到 pool1 下的节点(10.2.2.8和10.2.2.4节点属于节点池 pool1)。

步骤3:扩容您的业务,确认 PlacementPolicy 已生效
将工作负载副本数从 2 调整至 4。当 pool1 节点池中的资源不足时,调度至次优先级的节点池 pool2。
场景二:降本场景(基于计费方式的调度策略)
您仅使用了原生节点,资源池中有两种计费类型的资源:按量计费和包年包月的计费方式,您希望 Pod 优先调度至包年包月的节点上,不满足后再调度至按量计费的节点上。缩容时,优先缩容按量计费的节点,最终实现成本最优的效果。
apiVersion: scheduling.crane.io/v1alpha1kind: PlacementPolicymetadata:name: chargetypepolicyspec:targets:namespaces:include:- defaultnodeGroups:- name: prepaid #包月计费nodeType: nativenodeSelectorTerms:- matchExpressions:- key: node.tke.cloud.tencent.com/instance-charge-typeoperator: Invalues:- PrepaidChargewhenUnsatisfiable: ScheduleAnywaypriority: 100- name: postpaid #按量计费nodeType: nativenodeSelectorTerms:- matchExpressions:- key: node.tke.cloud.tencent.com/instance-charge-typeoperator: Invalues:- PostpaidByHourwhenUnsatisfiable: ScheduleAnywaypriority: 0
其他步骤如场景一,不再赘述。
场景三:流量洪峰/潮汐场景(基于节点类型的调度策略)
通常您会维持基于原生节点的稳态资源池,用于您日常的资源运维。在流量洪峰的场景下,会调度至弹性资源池,进行快速资源扩容。您可以设置资源池的优先级,优先调度至稳定资源池,有流量洪峰的敏态场景下,调度至弹性资源池。
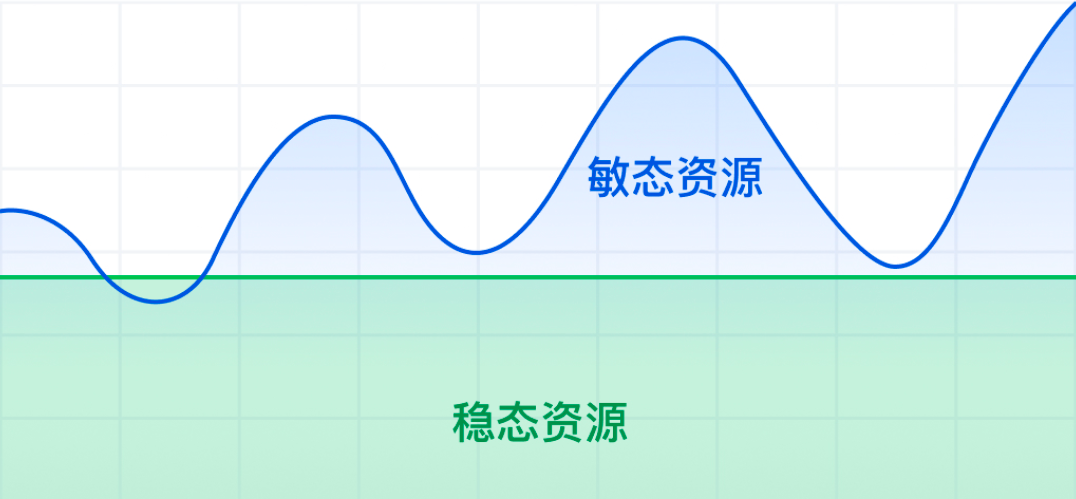
例如:
您命名空间 pro 下的应用具有流量洪峰的特性,您希望:
日常情况下:Pod 优先调度至原生节点类型的稳态资源池。由于您对资源池的用途进行了划分,您希望该业务均调度至 id 为:np-isagw4ni,np-manr12ry 的资源池上。
突发流量的情况下:pod 调度至超级节点类型的弹性资源池,ID 为 np-flr86fpw。
apiVersion: scheduling.crane.io/v1alpha1kind: PlacementPolicymetadata:name: testpolicyspec:namespaces:include:- pronodeGroups:- name: native_node_pool # 稳态资源池nodeType: nativenodeSelectorTerms: # 如对原生节点资源池有特定要求,可设置node pool id属性- matchExpressions:- key: node.tke.cloud.tencent.com/machinesetoperator: Invalues:- np-isagw4ni- np-manr12rywhenUnsatisfiable: ScheduleAnywaypriority: 100- name: super_node_pool # 敏态资源池nodeType: supernodeSelectorTerms:- matchExpressions:- key: tke.cloud.tencent.com/nodepool-idoperator: Invalues:- np-flr86fpwwhenUnsatisfiable: ScheduleAnywaypriority: 0
其他步骤如场景一,不再赘述。
注意:
上述仅为示例,实际的稳态资源节点类型和节点池以您实际业务使用为准。如您同时使用多种节点类型,请根据实际诉求配置 priority。
排查手段
如何得知调度规则已在调度过程中生效?
可以从 crane-scheduler 的日志中找到相关逻辑:
1. 获取 Pod 生效的预选策略:
kubectl -nkube-system logs $craneSchedulerPodName | grep preScore
如:PlacementPolicyName 为 prepaidhousekeeper。

2. 获取 Pod 生效的优选策略:
kubectl -nkube-system logs $craneSchedulerPodName | grep preScore
如:PlacementPolicyName 为 prepaidhousekeeper。

3. 确认 Pod 无法调度的原因是否是因为 PlacementPolicy 的拦截:
kubectl describe po $pendingPodName
关注输出中的关键词:Violate placementpolicy。




