业务场景
对于某些核心的应用(如流量网关),我们不希望升级过程中出现任何故障。在升级这类核心应用时,会采用极为保守的策略,宁愿操作繁琐,也要确保风险完全可控。这意味着需要先确保待升级的 Pod 完全被摘流,然后再手动重建 Pod 触发升级,持续经现网流量灰度一段时间后,如果一切正常,再逐步扩大灰度范围。如果期间发现任何问题,可随时回滚已升级副本。
升级导致故障的可能情况
下面列举一些在升级时可能导致故障的情况:
1. 应用的优雅终止逻辑可能不够完善,导致在 Pod 停止时部分存量连接异常。
2. 存量长连接迟迟不断开,可能超过
terminationGracePeriodSeconds,导致 Pod 停止时,存量连接异常关闭。3. 新版应用可能引入隐藏 BUG 或不兼容改动,这些问题可能在健康检查中无法被探测到,等上线后一段时间才被动发现。
4. CLB 摘流和 Pod 停止两个过程异步并行执行,在极端的场景下,Pod 已经开始进入优雅终止流程,不再接收增量连接,但 CLB 还没有来得及摘流(改变权重),导致个别新连接被调度到正在停止的 Pod 而无法得到处理。
流量完全无损升级的方法
在 TKE 环境中,可以使用 StatefulSet 来部署核心应用,并配合 TKE 的 Service 注解来实现对指定序号的 Pod 提前摘流,再结合 StatefulSet 的
OnDelete 更新策略对 Pod 进行手动重建更新来实现流量完全无损的升级。以下是大致的升级流程: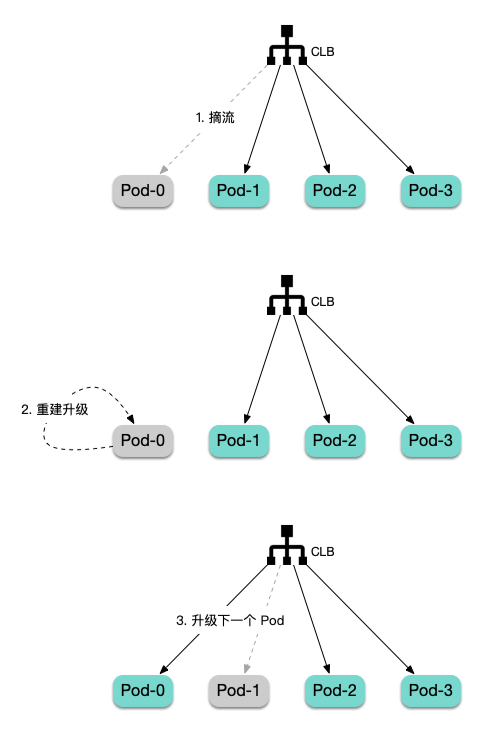
操作步骤
创建 StatefulSet
apiVersion: apps/v1kind: StatefulSetmetadata:name: nginxspec:replicas: 10podManagementPolicy: Parallelselector:matchLabels:app: nginxserviceName: nginxtemplate:metadata:annotations:tke.cloud.tencent.com/networks: tke-route-eni # GlobalRouter 与 VPC-CNI 混用时显式声明使用 VPC-CNIlabels:app: nginxspec:containers:- image: nginx:1.25.3imagePullPolicy: IfNotPresentname: nginxports:- containerPort: 80name: httpprotocol: TCPresources: # GlobalRouter 与 VPC-CNI 混用时显式声明使用 VPC-CNIlimits:tke.cloud.tencent.com/eni-ip: "1"requests:tke.cloud.tencent.com/eni-ip: "1"updateStrategy:type: OnDelete # 重要:使用手动重建触发升级而非滚动更新---apiVersion: v1kind: Servicemetadata:labels:app: nginxannotations:service.cloud.tencent.com/direct-access: "true" # 重要:启用 CLB 直连 Podname: nginxspec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: nginxtype: LoadBalancer
说明:
StatefulSet 的
updateStrategy 使用 OnDelete。确保 Pod 使用 VPC-CNI 网络或调度到超级节点,便于启用 CLB 直连。
添加 Service 注解启用 CLB 直连。
逐个升级
1. 首先将 StatefulSet 所使用的镜像替换为新的镜像(升级后期望使用的镜像版本)。
kubectl set image statefulset/nginx nginx=nginx:1.25.4
2. 将 StatefulSet 副本数加1,因为副本重建的过程中副本数会少1个,提前增加1个副本可避免升级过程中 Pod 的平均负载过高导致业务异常:
kubectl scale --replicas=11 statefulset/nginx
3. 选择工作负载 > StatefulSet,单击操作栏中的更多 > 编辑 Annotation,为 Service 添加注解:
service.cloud.tencent.com/lb-rs-weight: '{"defaultWeight":10,"groups":[{"key":{"proto":"TCP","port":80},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[0]}]}]}]}'
key 里填入 Service 里声明的端口和协议,如果有多个端口,需在 groups 数组里再加一份配置(只有 key 不同),示例如下:service.cloud.tencent.com/lb-rs-weight: '{"defaultWeight":10,"groups":[{"key":{"proto":"TCP","port":80},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[0]}]}]},{"key":{"proto":"TCP","port":8080},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[0]}]}]}]}'
statefulSets 里的 name 填入 StatefulSet 的名称。podIndexes 里填入接下来计划升级的 Pod 序号,一般从0开始。weight 设置为0,将该序号的 Pod 从 CLB 后端摘流(增量连接不再调度过去,等待存量连接结束)。4. 在 CLB 控制台,选择实例 ID > 监听器管理,点击监听器,查看对应 CLB 的监听器绑定的后端服务,确认将要升级的 Pod IP 的流量权重为0:
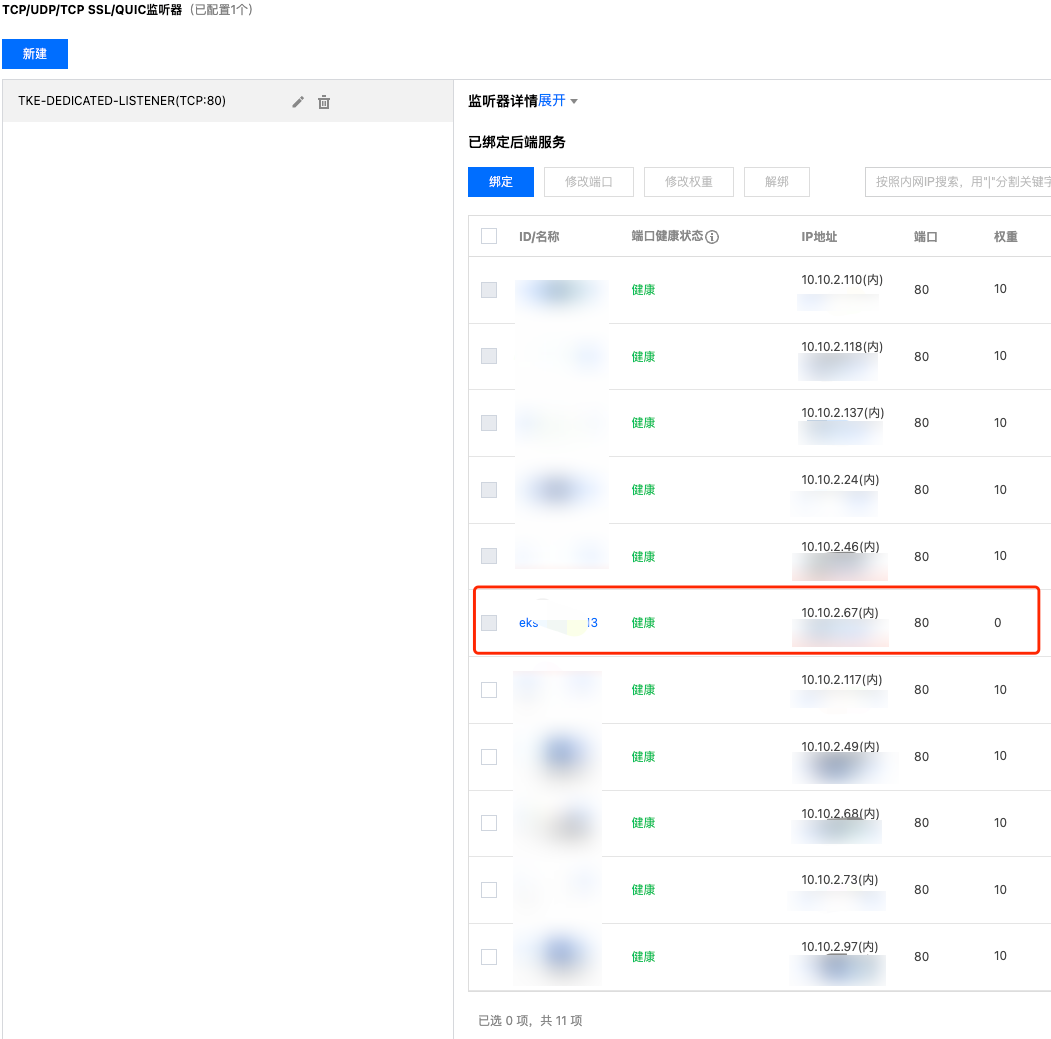
5. 等待存量连接和流量完全归零,可在 CLB 控制台,选择实例 ID > 监听器管理,在监控页面确认(输入对应的监听器和后端服务进行过滤)。
6. 删除计划升级的 Pod,触发重建升级:
kubectl delete pod nginx-0
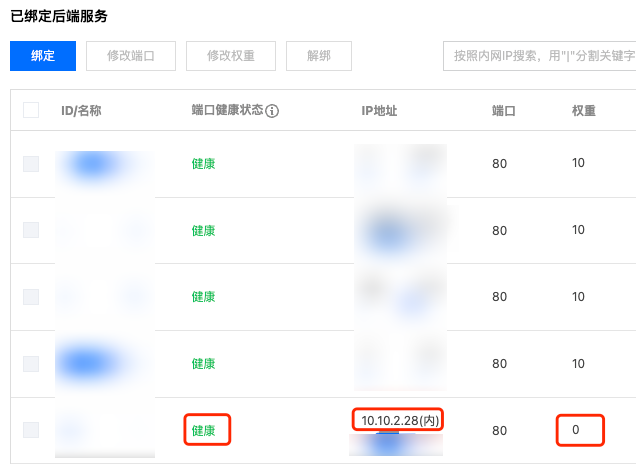
7. 观察升级后的 Pod 运行状态、镜像和健康状态,以确保它们都符合预期(可以通过现网流量验证一段时间,如果发现异常,可以回滚镜像版本并再次按照步骤 3~5 回滚):
$ kubectl get pod -o wide nginx-0NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESnginx-0 1/1 Running 0 86s 10.10.2.28 10.10.11.3 <none> 1/1$ kubectl get pod nginx-0 -o yaml | grep image:- image: nginx:1.25.4image: docker.io/library/nginx:1.25.4
8. 修改 Service 注解中的
podIndexes,准备升级下一个 Pod:service.cloud.tencent.com/lb-rs-weight: '{"defaultWeight":10,"groups":[{"key":{"proto":"TCP","port":80},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[1]}]}]}]}'
9. 循环 3~7 的步骤,直到倒数第二个副本升级完成。
10. 删除
service.cloud.tencent.com/lb-rs-weight 这个 Service 注解,恢复所有 Pod 的流量权重。11. 恢复 StatefulSet 的副本数(缩掉最后一个冗余的副本):
kubectl scale --replicas=10 statefulset/nginx
至此,完成升级。
分批升级
如果副本数较多,逐个升级可能会显得过于繁琐。在这种情况下,您可以选择分批升级,即从每次升级1个 Pod 变为每次升级多个 Pod,操作步骤与 逐个升级 基本一致,主要的区别在于每次操作的 Pod 数量:
提前扩容的副本数和每次删除重建的副本数从1个调整为多个。
service.cloud.tencent.com/lb-rs-weight 注解里的 podIndexes 从1个调整为多个。例如,如果每次升级4个 Pod,您需要在注解中指定这4个 Pod:service.cloud.tencent.com/lb-rs-weight: '{"defaultWeight":10,"groups":[{"key":{"proto":"TCP","port":80},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[0,1,2,3]}]}]}]}'



