说明:
告警仅针对 TokenHub 控制台已采集的指标生效,未在用量统计或模型监控中暴露的指标不支持告警。当前仅支持文本生成模型的告警配置。
告警视图
TokenHub 已与腾讯云可观测平台打通,新建告警视图操作步骤如下:
1. 在告警管理 > 告警配置中,选择告警策略页签。
2. 单击新建策略,选择自定义告警策略。
3. 在新建告警策略中,于策略类型下拉框选择大模型服务平台 TokenHub,即可对运行指标配置告警策略。
在策略类型大模型服务平台 TokenHub 的二级菜单中提供 6 个告警视图,与控制台的筛选维度对应。每个视图下进一步细分为用量指标和性能指标两个策略子类,分别对应用量统计页面和模型监控页面的指标集合,您可以根据要监控的对象选择对应视图。
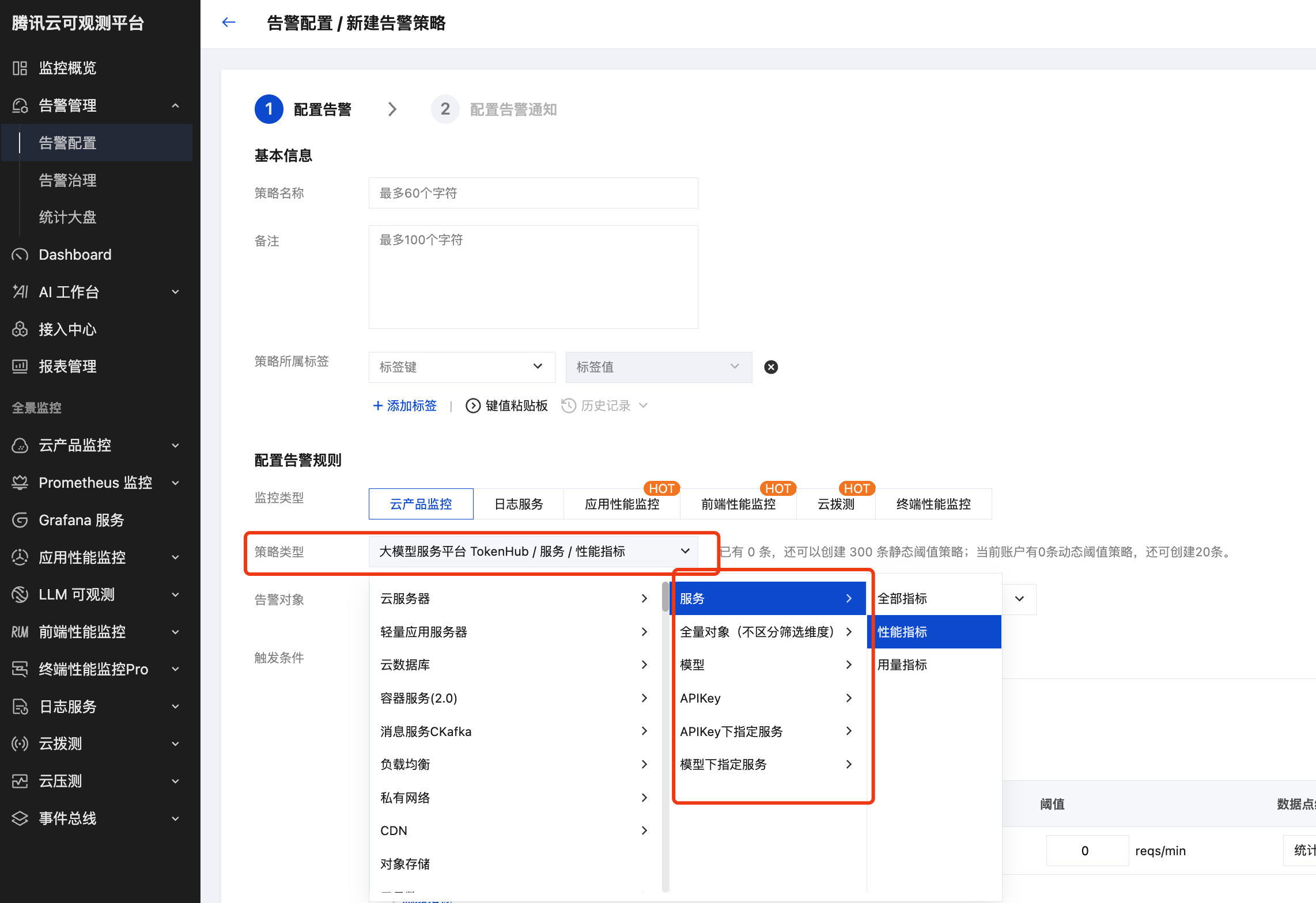
告警视图 | 控制台筛选维度 | 适用场景 |
服务 | 对应模型监控页面,按服务维度聚合 | 监控单个在线推理服务整体的监控指标配置告警。 |
模型 | 对应模型监控页面,按模型维度聚合 | 监控单个模型在所有服务上的监控指标配置告警。 |
APIKey | 对应用量统计 > 用量趋势 页面,按 API Key 维度聚合全部服务 | 按业务线 / 子账号维度监控 Key 的用量与性能,覆盖全部服务。 |
APIKey 下指定服务 | 对应用量统计 > 用量趋势 页面,按 API Key × 服务(二级筛选) | 同一 Key 调用了多个服务时,区分到具体某个服务的监控告警。 |
模型下指定服务 | 对应用量统计 > 用量趋势 页面,按模型 × 服务(二级筛选) | 同一模型部署在多个服务上时,区分到具体某个服务的监控告警。 |
全量对象 | 当前账号(Uin 维度)的所有监控对象 | 监控账号级总量,例如该 Uin 下 Token 消耗总量。 |
说明:
“APIKey 下指定服务”与“模型下指定服务”对应控制台的二级下拉联动。
告警指标说明
用量指标:参考 用量统计,包括总 Token 数、输入 / 输出 Token 数、每分钟 Token 数(TPM)、缓存读写 Token 数等。
性能指标:参考 模型监控,包括每分钟请求数(RPM)、首 Token 延迟(TTFT)、每 Token 输出延迟(TPOT)、非流式接口延时、限流错误率、超时错误率、错误率、缓存命中率。
配置告警
在腾讯云可观测平台的新建告警策略页面完成基本信息、告警规则、告警通知三段配置即可生效。
步骤 1:基本信息
配置项 | 说明 |
策略名称 | 最多 60 个字符,建议体现告警对象与指标,如 tokenhub-glm5-input-tpm。 |
备注 | 最多 100 个字符,可填写业务说明。 |
策略所属标签 | 按需添加标签,便于策略归类与权限管理。 |
步骤 2:配置告警规则
配置项 | 说明 |
监控类型 | 选择云产品监控。 |
策略类型 | 选择大模型服务平台 TokenHub,选择具体视图(服务 / 全量对象 / 模型 / APIKey / APIKey 下指定服务 / 模型下指定服务),选择用量指标或性能指标。 |
告警对象 | 支持指定实例或全部实例。选择“指定实例”时,需在右侧下拉框选择具体的服务、模型或 API Key。 |
触发条件 | 支持选择模板或手动配置。手动配置时按“指标 + 比较关系 + 阈值 + 数据点统计粒度 + 异常持续 + 告警频率”组合定义。 |
步骤 3:配置告警通知
常见配置案例
案例 1:监控某个模型的每分钟输入 Token 数(TPM)
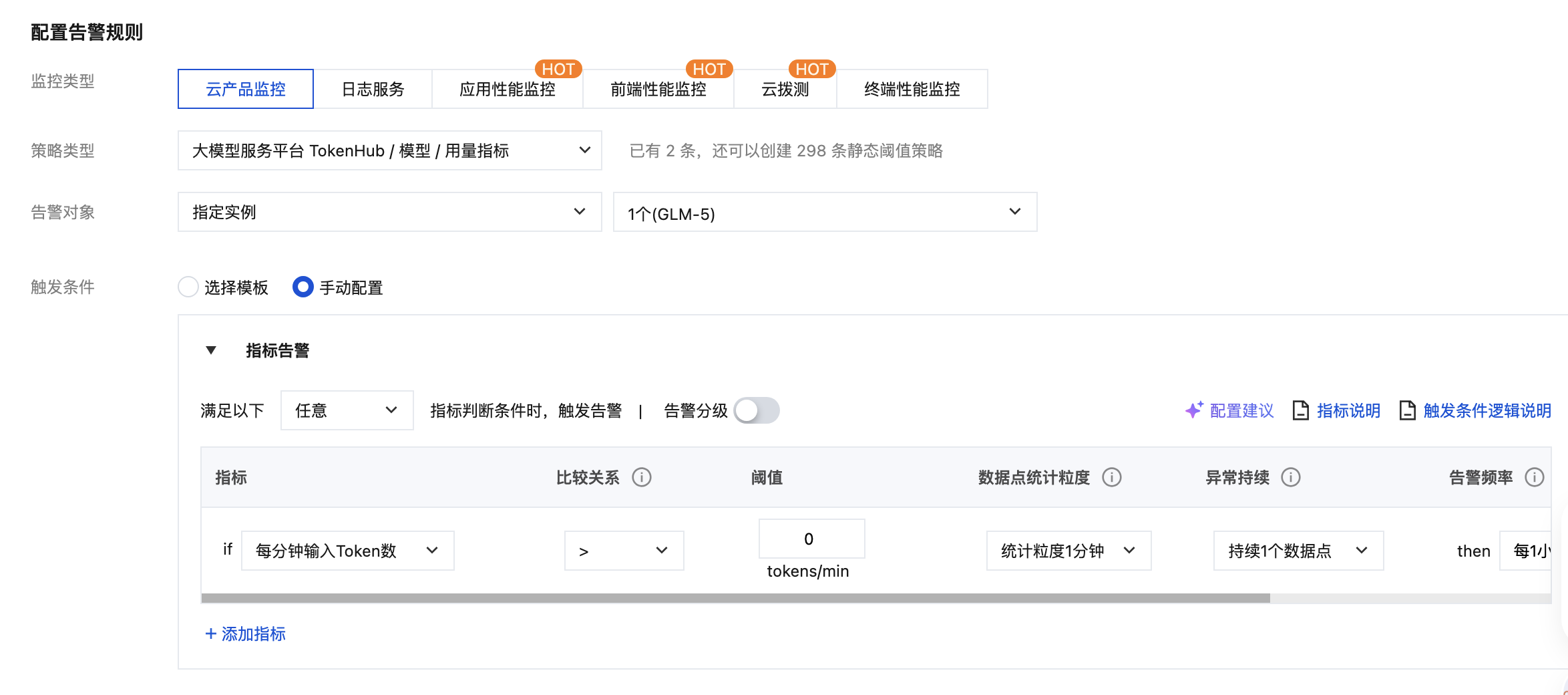
场景:业务侧使用
glm-5 模型,担心突发流量导致输入 TPM 触达配额上限,希望在接近上限时提前告警。配置步骤:
步骤 | 配置项 | 取值 |
1 | 策略类型 | 在大模型服务平台 TokenHub 下,依次选择模型和用量指标。 |
2 | 告警对象 | 选择指定实例,并选择 glm-5。 |
3 | 触发条件 | 选择手动配置。 |
4 | 指标 | 每分钟输入 Token 数 |
5 | 数据点统计粒度 | 1 分钟 |
说明:
选择“模型”视图意味着对该模型在所有服务、所有 Key 下的合计输入 TPM 计算告警;如需精确到某个服务,请改用 模型下指定服务 视图。
输出侧若同样需要监控,可叠加一条“每分钟输出 Token 数”指标,或在同一策略中通过“添加指标”加入。
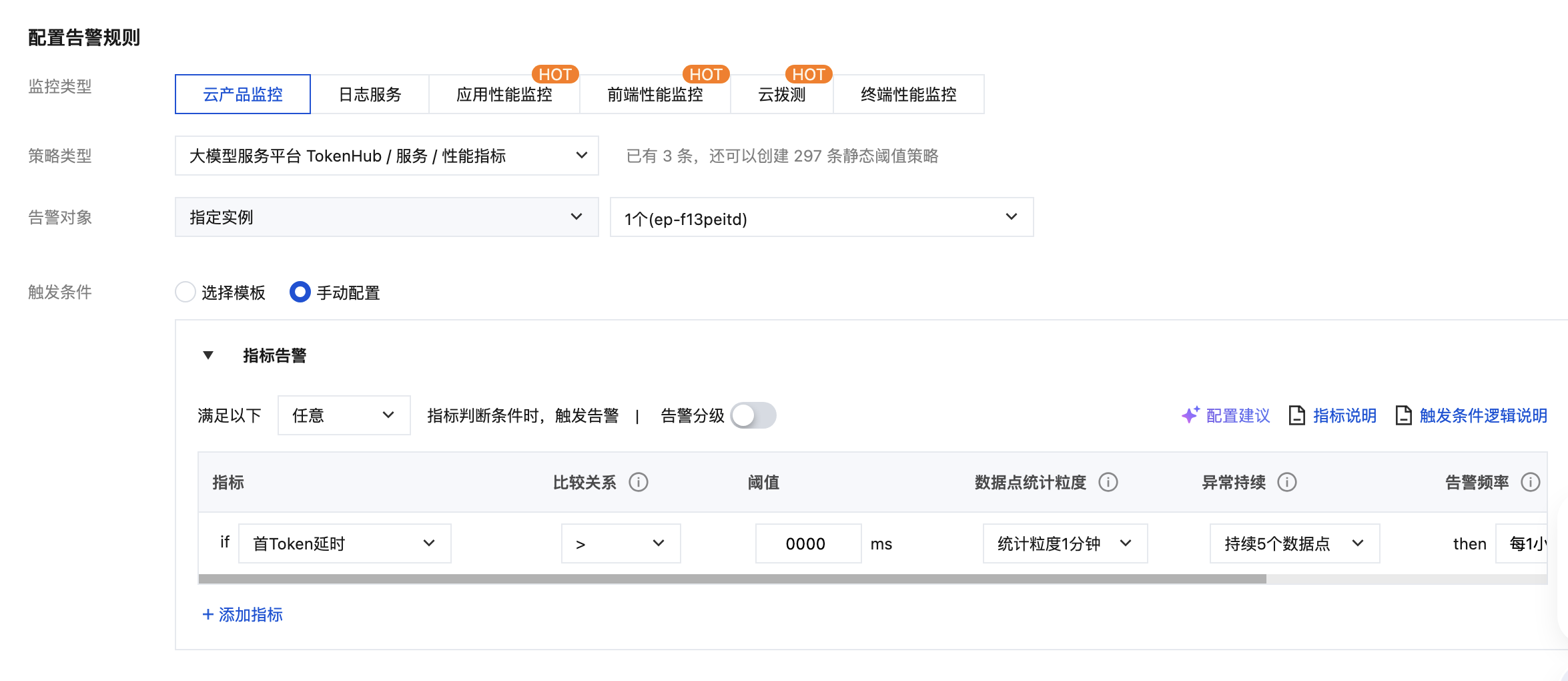
案例 2:监控某个服务的首 Token 延迟(TTFT)
场景:在线推理服务对响应速度敏感,希望在 TTFT 持续劣化时及时告警。
配置步骤:
步骤 | 配置项 | 取值 |
1 | 策略类型 | 在大模型服务平台 TokenHub 下,依次选择服务和性能指标。 |
2 | 告警对象 | 选择指定实例,并选择 ep-xxx。 |
3 | 触发条件 | 选择手动配置。 |
4 | 指标 | 首 Token 延迟(TTFT) |
5 | 比较关系 / 阈值 | > 2000(单位 ms,按业务 SLA 设定) |
6 | 数据点统计粒度 | 1 分钟 |
说明:
TTFT 仅统计流式请求;若服务以非流式调用为主,建议改用 非流式接口延时 指标。
异常持续设为 5 个数据点(5 分钟)可有效过滤偶发抖动,避免单点波动产生误告警。
同时关注超时错误率和错误率两项指标可形成完整的服务健康度监控体系,建议在同一策略中通过“添加指标”组合配置。
常见问题
Q1:告警对象下拉框为什么找不到我刚创建的服务 / Key?
云可观测平台的对象列表存在数据同步延迟,新建对象通常 5~10 分钟后才会出现在下拉框中,请稍后重试。
Q2:为什么“全量对象(不区分筛选维度)”视图下的告警和单个对象告警结果不一致?
“全量对象”视图统计的是当前账号下所有对象的合计值,单个对象告警仅针对该对象。两者口径不同,应根据监控目的分别使用——监控账号级总量用“全量对象”,监控单点风险用具体对象视图。



