背景介绍
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
HAI 已提供 DeepSeek-R1 模型预装环境,用户可在 HAI 中快速启动,进行测试并接入业务。
快速使用
步骤一:创建 DeepSeek-R1 应用
1. 登录 高性能应用服务 HAI 控制台。
2. 单击新建,进入高性能应用服务 HAI 购买页面。
选择应用:选择社区应用,应用选择 DeepSeek-R1 AnythingLLM。
地域:建议选择靠近自己实际地理位置的地域,降低网络延迟、提高您的访问速度。
算力方案:选择合适的算力套餐。
说明:
在单并发访问模型的情况下,建议最低配置如下:
模型 | 参数量级 | 推荐算力套餐 |
DeepSeek-R1 | 1.5B/7B/8B/14B | GPU 基础型 |
DeepSeek-R1 | 32B | GPU 进阶型 |
实例名称:自定义实例名称,若不填则默认使用实例 ID 替代。
购买数量:默认1台。
3. 单击立即购买。
4. 核对配置信息后,单击提交订单,并根据页面提示完成支付。
5. 等待创建完成。单击实例任意位置并进入该实例的详情页面。同时您将在站内信中收到登录密码。此时,可通过可视化界面(GUI)或命令行(Terminal)使用 DeepSeek 模型。
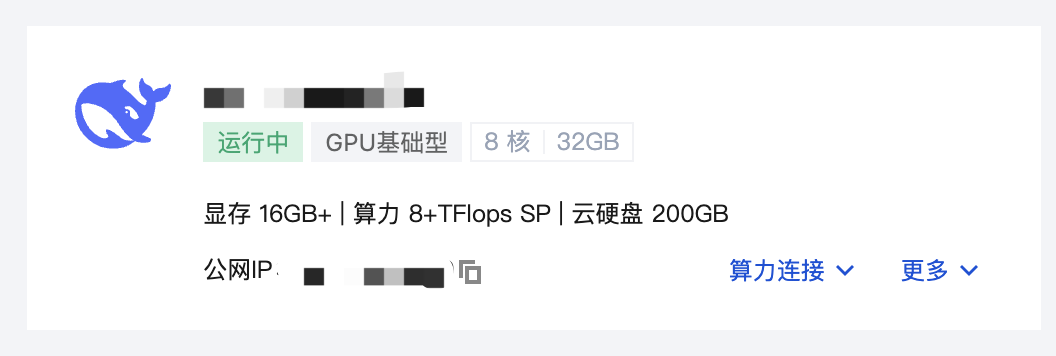
6. 您可以在此页面查看 DeepSeek-R1 详细的配置信息,到此为止,说明您的 DeepSeek-R1 应用实例购买成功。
步骤二:使用 DeepSeek-R1 模型
等待几分钟创建完成后,将在站内信中收到登录密码。此时,可通过可视化界面 (GUI) 或命令行 (Terminal) 使用 DeepSeek 模型。
通过 OpenWebUI 可视化界面使用(推荐)
1. 登录 高性能应用服务 HAI 控制台,选择算力连接 > OpenWebUI。

2. 在新窗口中,单击开始使用。
3. 自定义名称、电子邮箱、密码,创建管理员账号。

4. 开始使用
通过 AnythingLLM 可视化界面使用(推荐)
1. 登录 高性能应用服务 HAI 控制台,选择算力连接 > AnythingLLM。

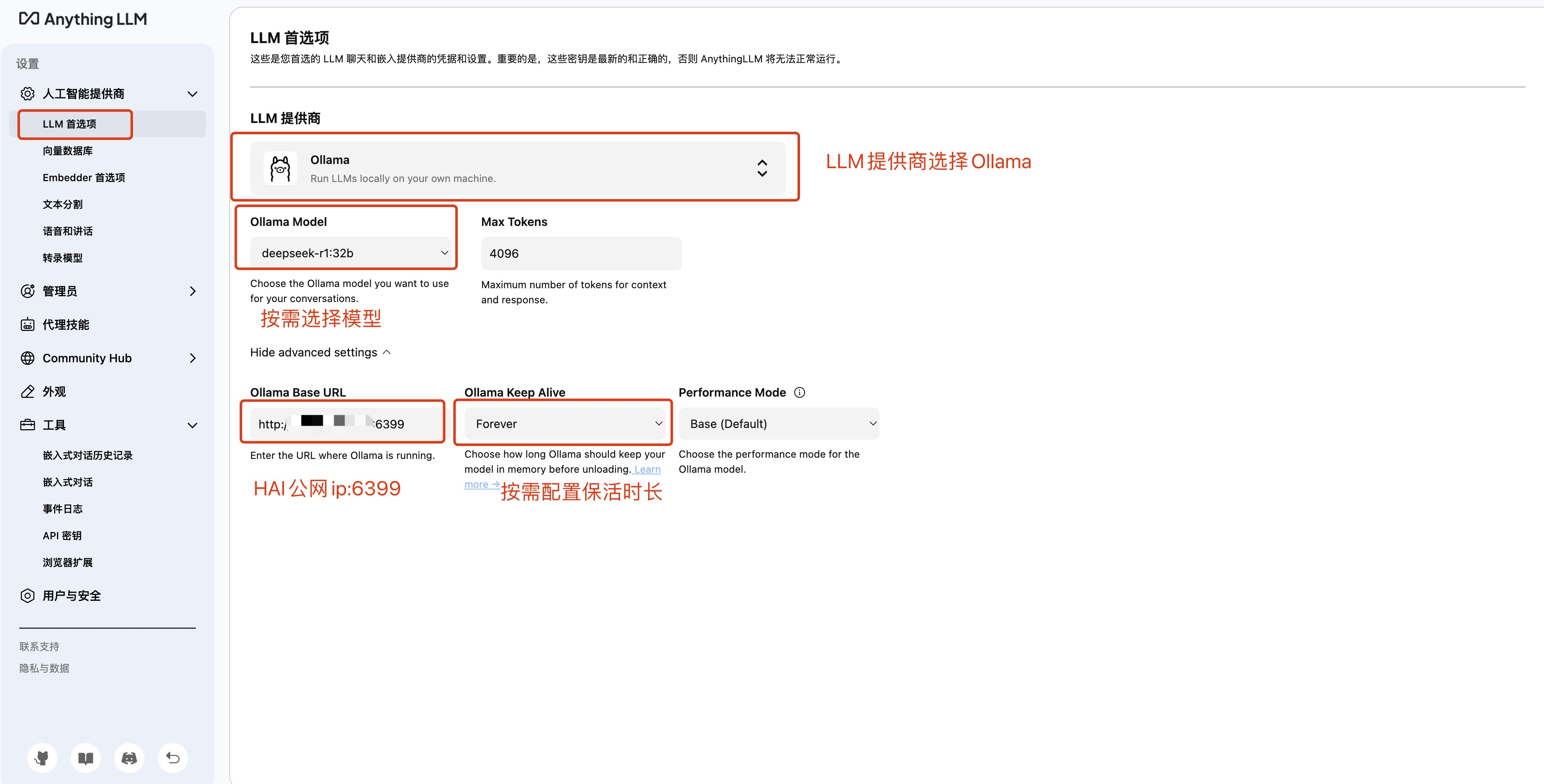
2. 新建窗口后,单击页面左下角设置,进入设置页面。单击左侧导航栏 LLM 首选项进入配置。
将 LLM 提供商选择为 Ollama。
将 Ollama Base URL 修改为:该台 HAI 实例的公网 IP:6399。
在 Ollama Model 处选择需要使用的模型,例如:deepseek-r1:32b。
在 Ollama Keep Alive 处按需配置保活时长。(模型在每次超过保活时长后会被移除,再次使用时需重新载入模型,耗时较久,若不存在频繁切换模型诉求,建议将保活时长尽可能调大。)
3. 配置完成后,回到项目页面,单击 upload a document 上传本地文件。
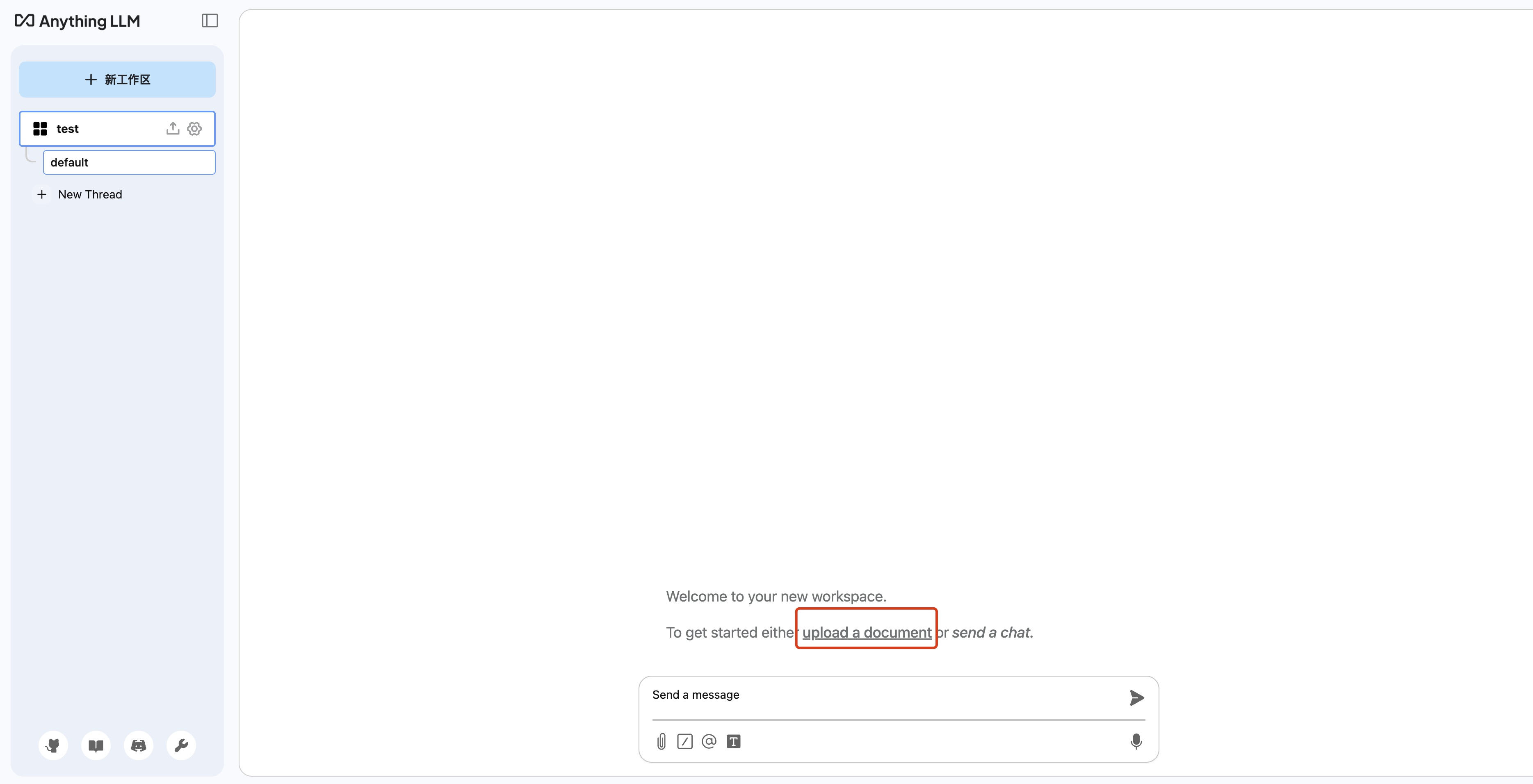
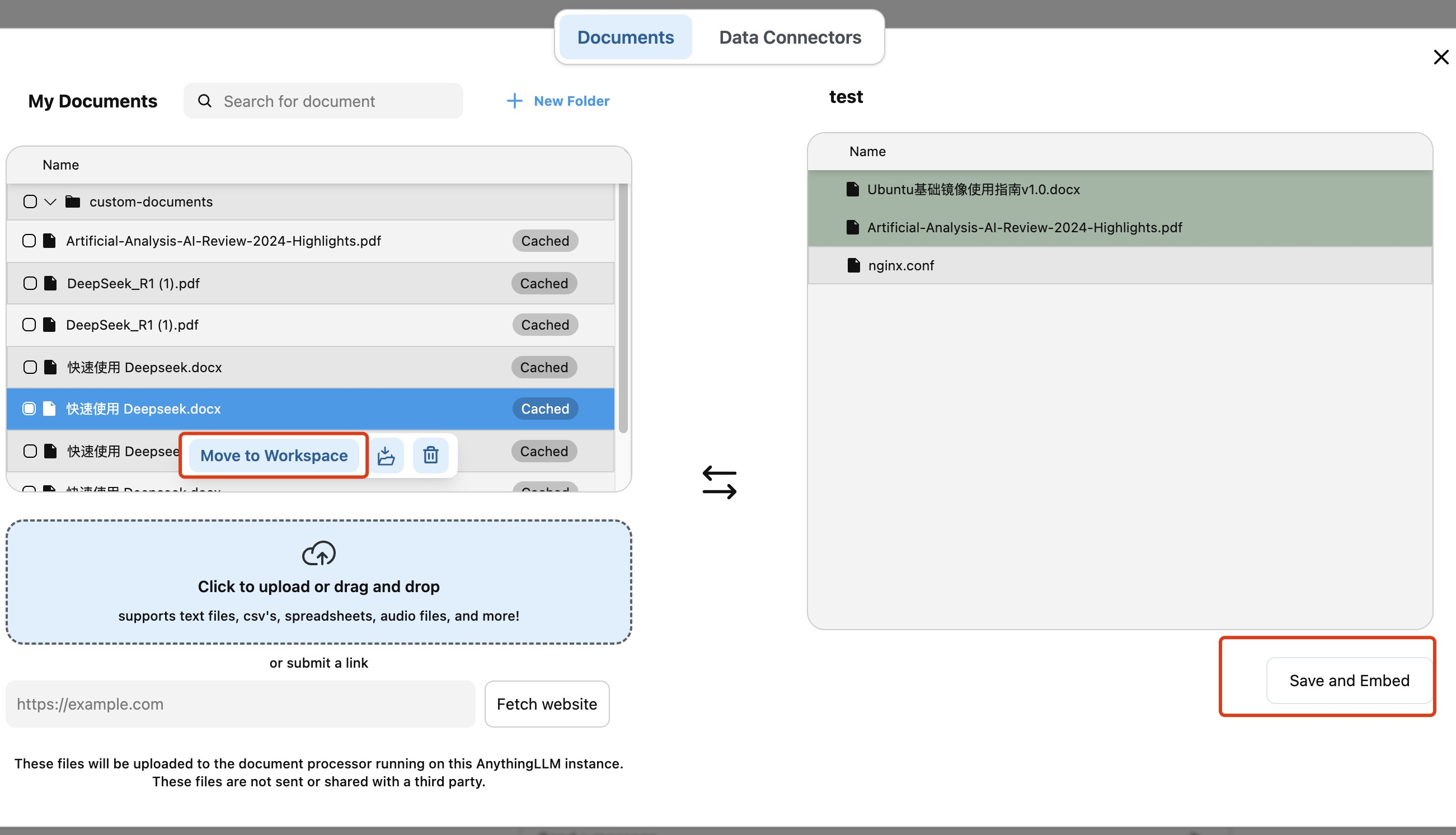
4. 上传文件后,选中希望使用的文件,单击 Move to Workspace 将文件添加至项目。单击 Save and Embed,完成配置。
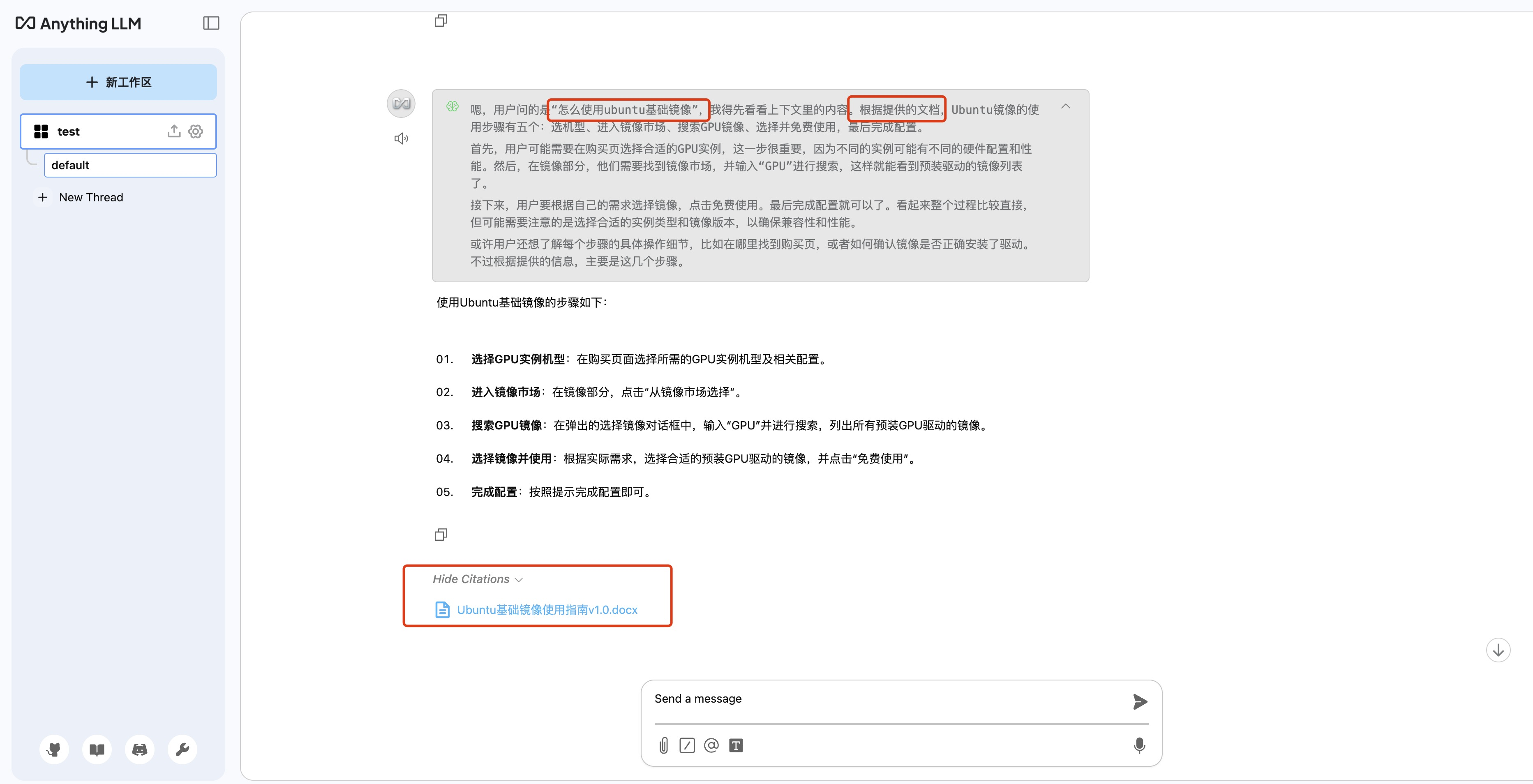
5. 您可直接与模型进行对话,模型会根据对话内容智能调用本地知识库内容。
通过终端连接命令行使用
1. 在 高性能应用服务 HAI 控制台,选择算力连接 > 终端连接(SSH)。
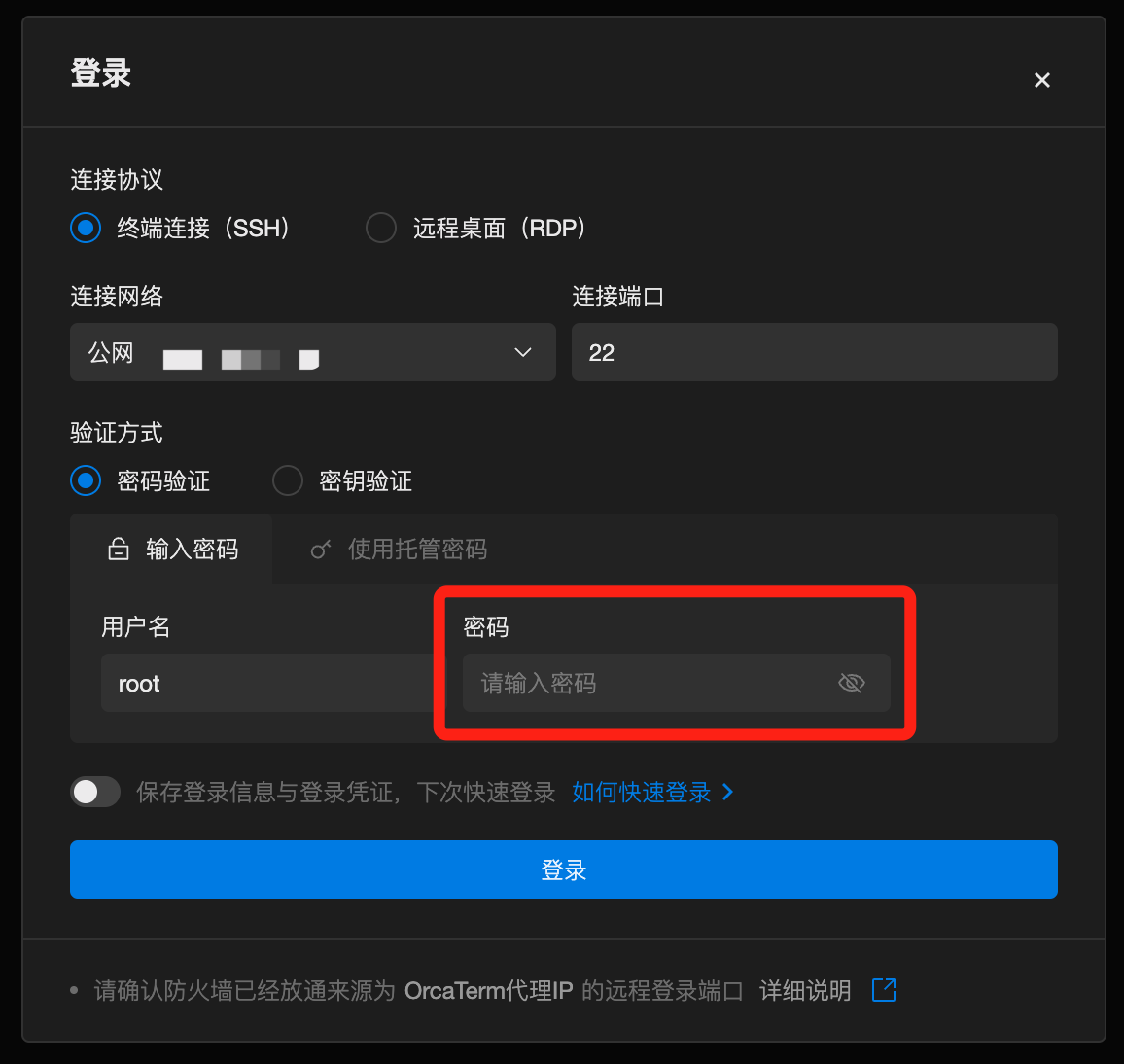
2. 在弹出的 OrcaTerm 登录页面中,输入站内信中的登录密码,单击登录。
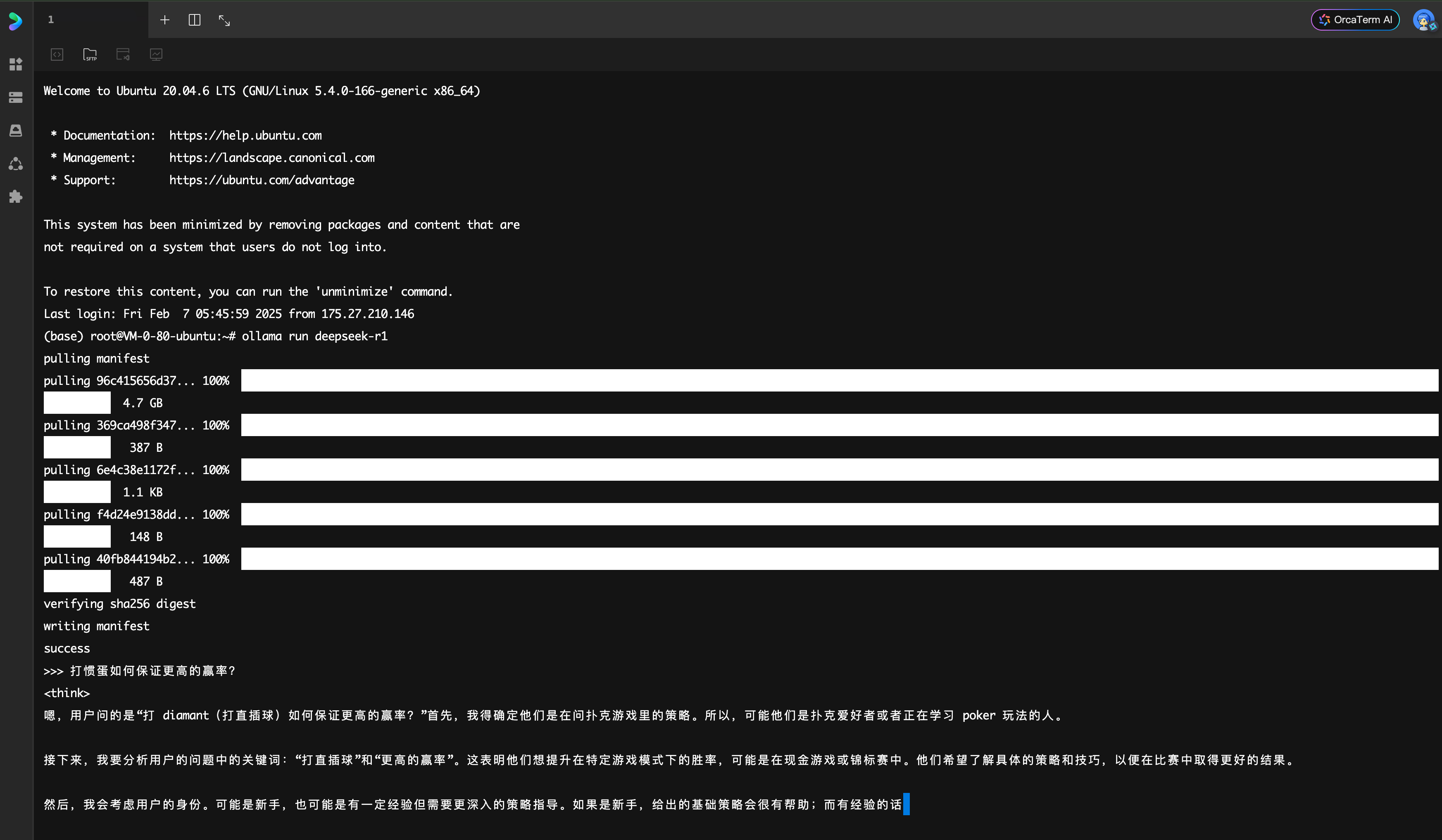
3. 登录成功后,输入以下命令加载默认模型:
ollama run deepseek-r1运行结果如下:
通过 JupyterLab 命令行使用
1. 在 高性能应用服务 HAI 控制台,选择算力连接 > JupyterLab。

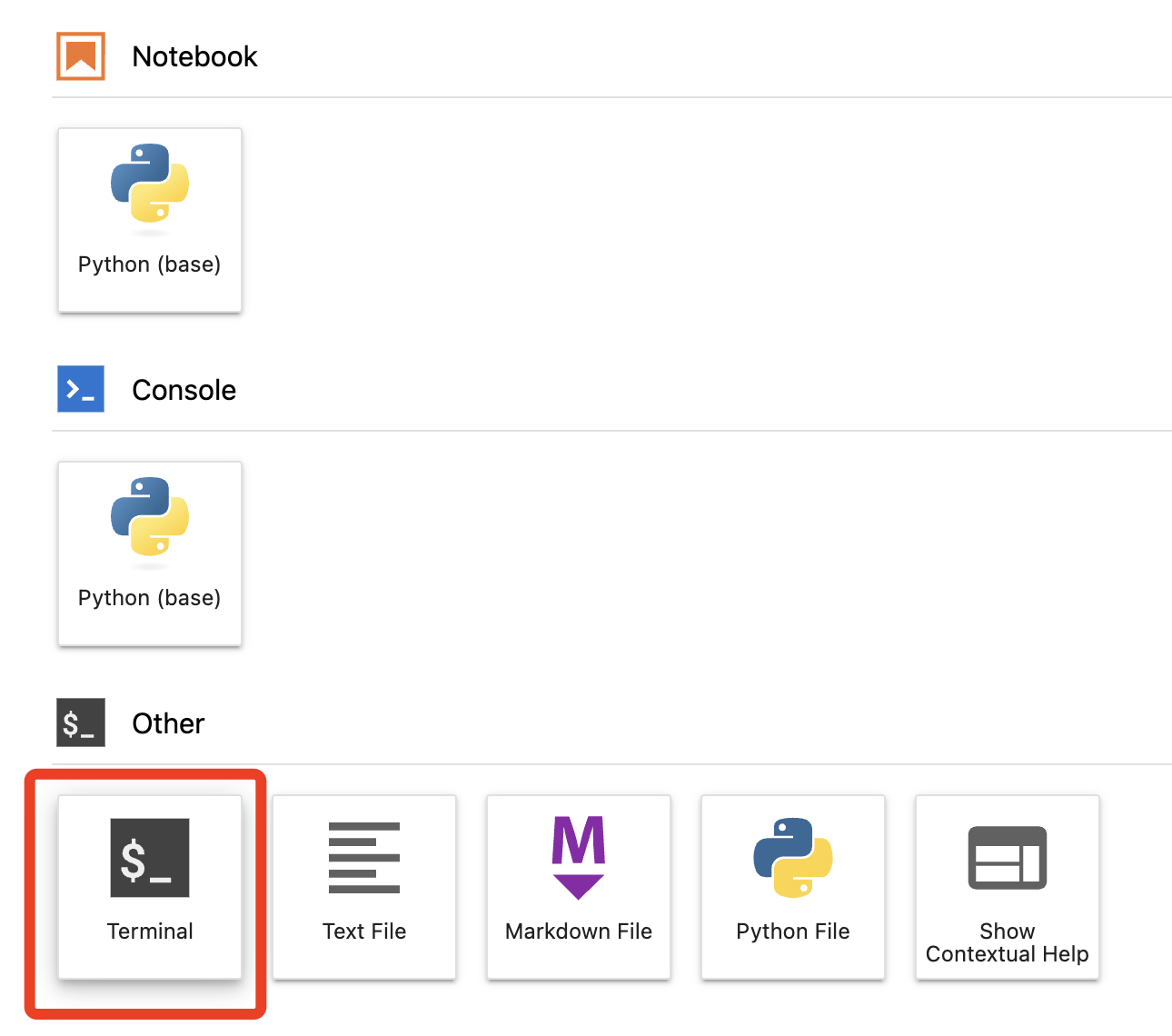
2. 新建一个 Terminal。
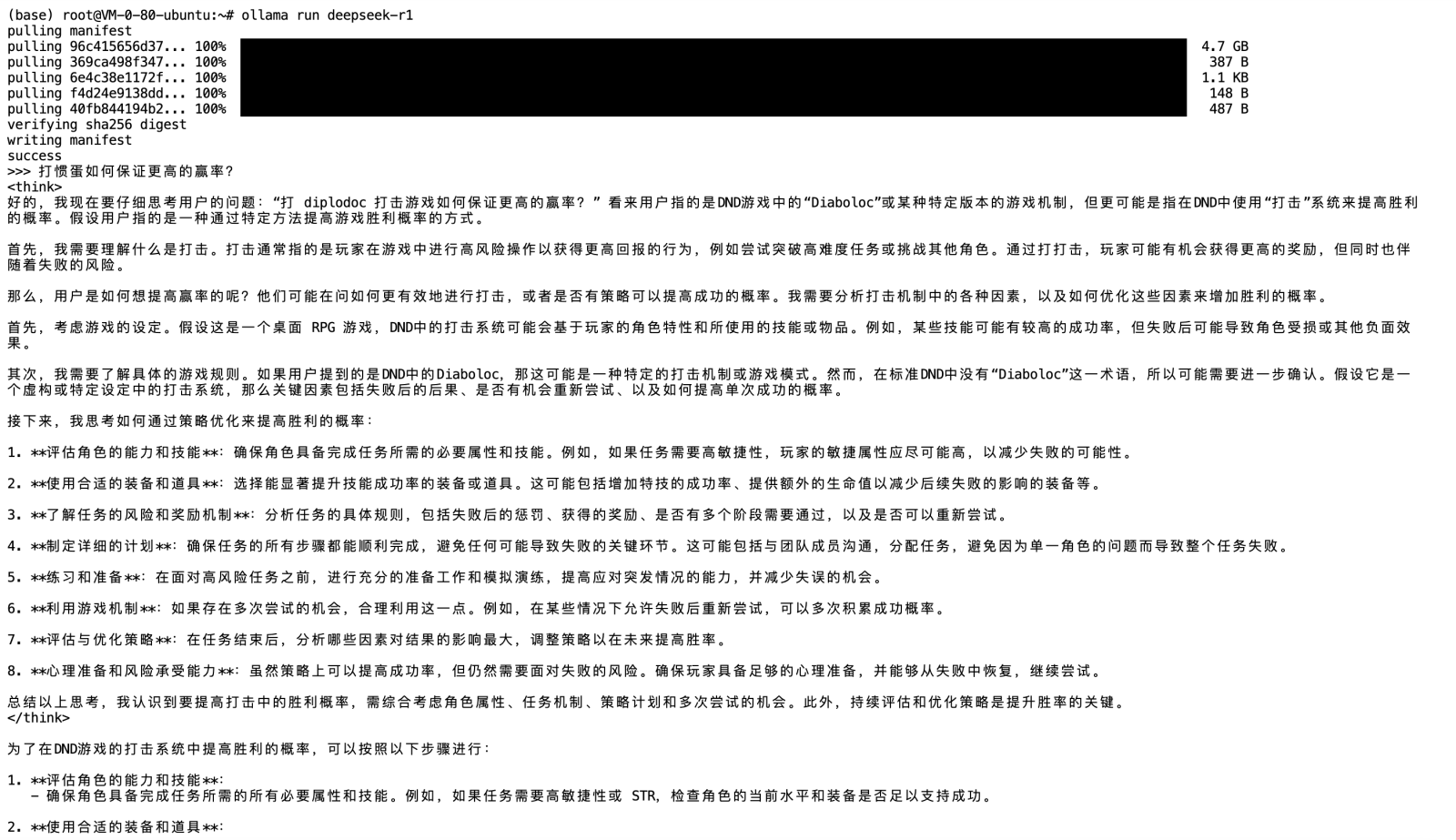
3. 输入以下命令加载默认模型:
ollama run deepseek-r1运行效果如下:
进阶使用
切换不同参数量级
若默认的模型无法满足需求,可通过以下命令自定义模型参数量级:
DeepSeek-R1-Distill-1.5B
ollama run deepseek-r1:1.5bDeepSeek-R1-Distill-7B
ollama run deepseek-r1:7bDeepSeek-R1-Distill-8B
ollama run deepseek-r1:8bDeepSeek-R1-Distill-14B
ollama run deepseek-r1:14bDeepSeek-R1-Distill-32B
ollama run deepseek-r1:32bAPI 调用
场景案例
搭建个人知识库
1. 下载 Cherry Studio:一款支持多个大语言模型(LLM)服务商的桌面客户端。
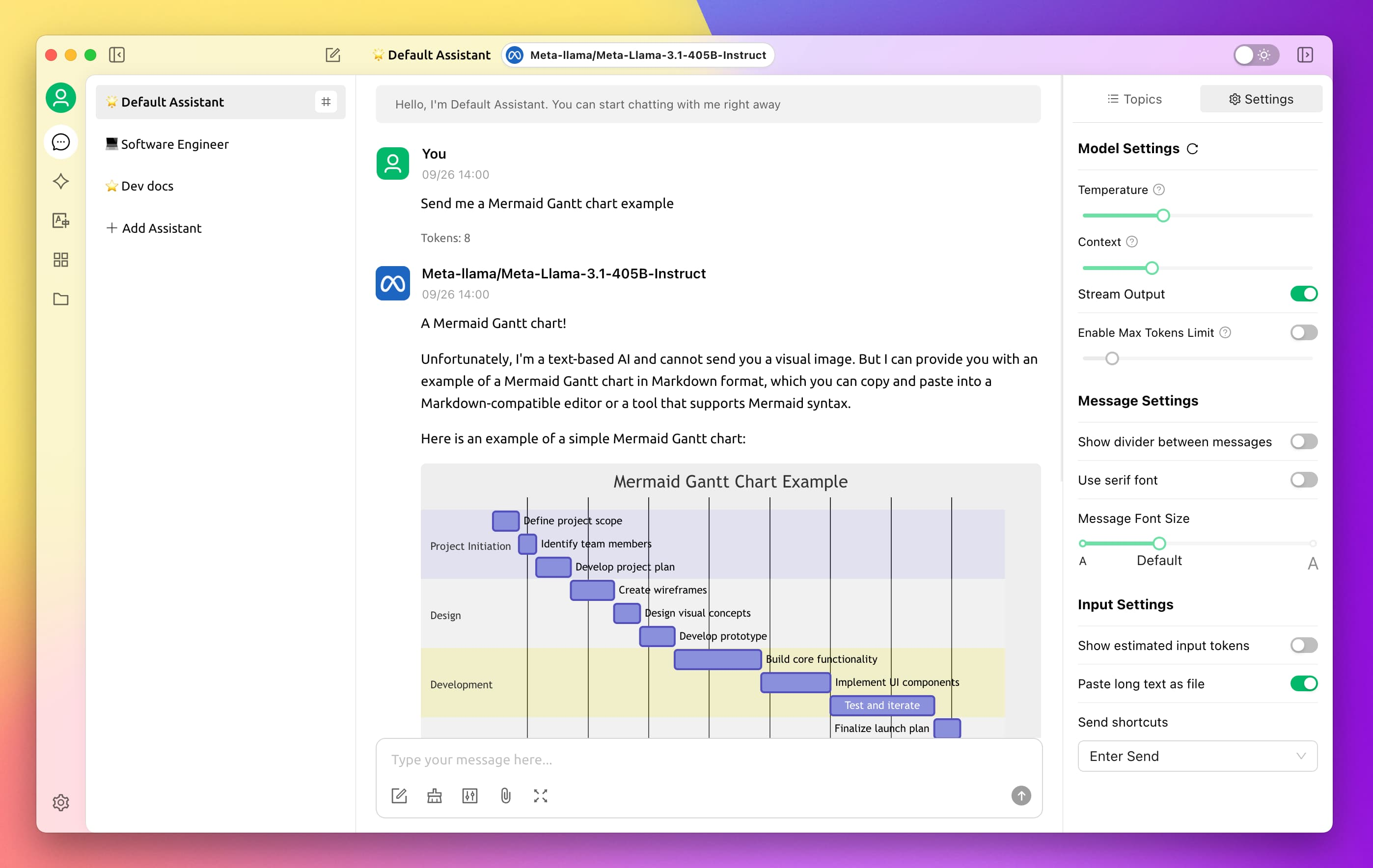
2. 配置 API:进入设置界面,选择模型服务中的 Ollama,填写 API 地址及模型名称。
2.1 API 地址:将默认的 localhost 替换为 HAI 实例的公网 IP,将端口号由11434修改为6399。
2.2 单击下方的添加按钮添加模型,模型 ID 输入“deepseek-r1:7b”或“deepseek-r1:1.5b”
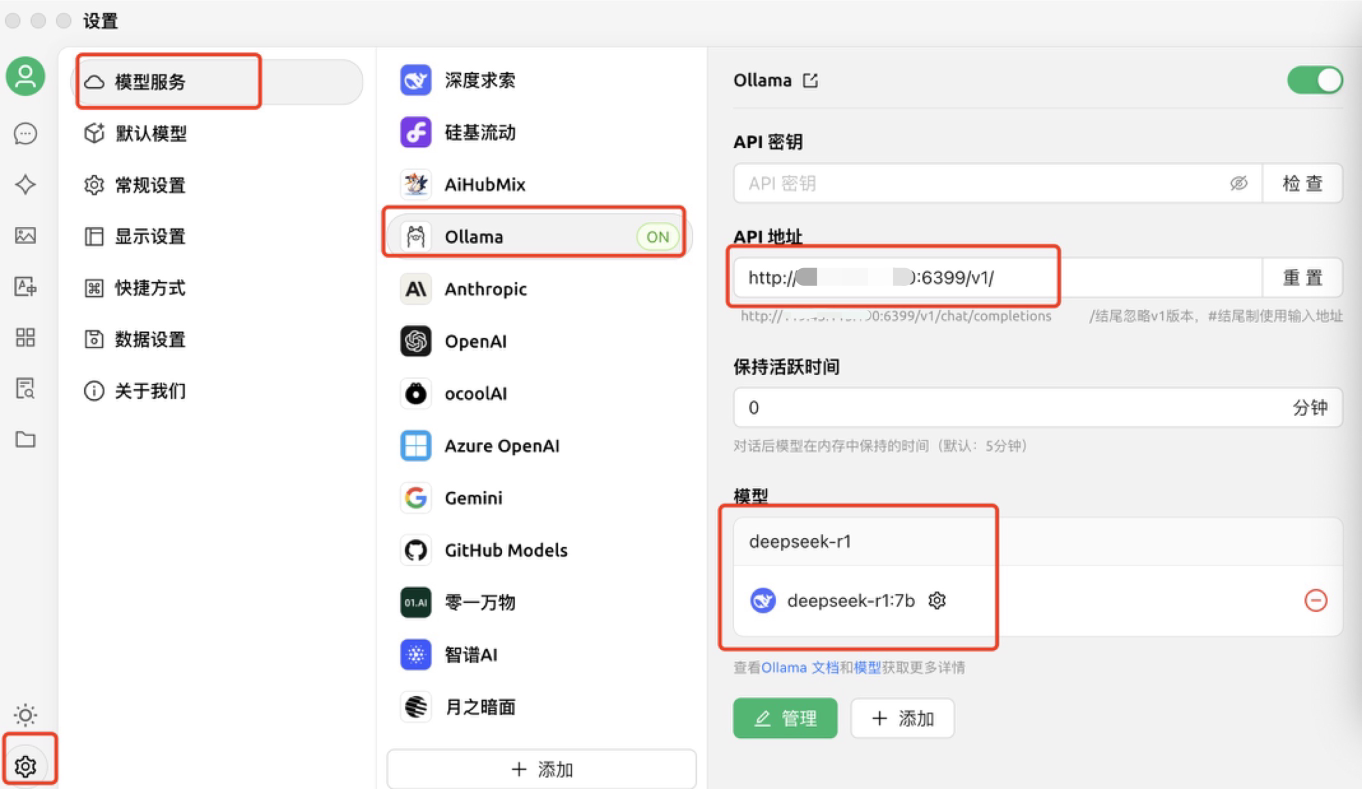
3. 检查连通性:单击 API 密钥右侧的检查,API 密钥不需填写,页面显示“连接成功”即可完成配置。

4. 添加本地知识库文件并使用:若需使用本地知识库,您可按如下步骤进行配置(以 bge-m3 嵌入模型为例)。
4.1 下载嵌入模型:单击算力连接,选择 JupyterLab。进入后打开 terminal,输入
ollama pull bge-m3。
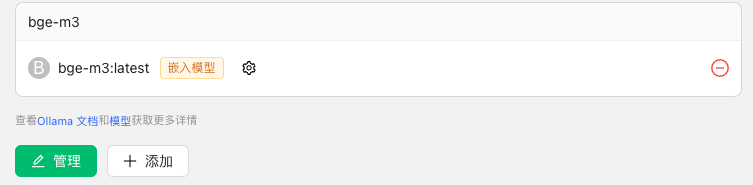
4.2 添加嵌入模型:下载完成后,返回 Cherry Studio。进入 ollama 模型服务页面,单击下方添加按钮添加模型,模型 ID 输入“bge-m3:latest”。
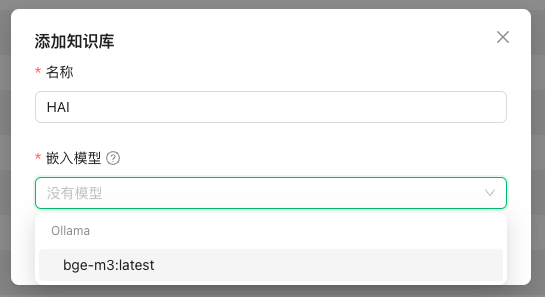
4.3 添加知识库:添加完成后,进入“知识库”页面,单击添加,嵌入模型选择“bge-m3:latest”,完成后即可上传本地文件,进行知识库管理。

常见问题
目前支持哪些参数量级的模型?
目前 HAI 已支持1.5B、7B、8B、14B、32B 的 DeepSeek-R1。70B、671B 将在近期推出,欢迎持续关注。
Ollama/API 的端口号是哪个?
如何通过 API 使用模型?
中国大陆地域通过 Ollama 下载模型速度慢怎么办?

提示资源紧张,排队人数过多,如何处理?
由于 DeepSeek 使用火热,部分地域可能出现售罄情况,无法成功创建实例。已付款项将会原路退回。建议更换地域重新购买或稍后重试。
社区交流
如有使用问题,欢迎加入腾讯云 DeepSeek 部署交流群。我们期待您的建议与反馈。




