背景介绍
腾讯云高性能应用服务 HAI 是为开发者量身打造的澎湃算力平台。无需复杂配置,便可享受即开即用的 GPU 云服务体验。在 HAI 中,根据应用智能匹配并推选出最适合的 GPU 算力资源,以确保您在数据科学、LLM、AI 作画等高性能应用中获得最佳性价比。
HAI 服务优势
智能选型 :根据应用匹配推选 GPU 算力资源,实现最高性价比。同时,打通必备云服务组件,大幅简化云服务配置流程。
一键部署 :分钟级自动构建 LLM、AI作画等应用环境。提供多种预装模型环境,包含如 StableDiffusion、ChatGLM2 等热门模型。
可视化界面 :友好的图形界面,AI 调试更为简单。
场景介绍
体验 高性能应用服务 HAI 一键部署 ChatGLM2-6B。具体步骤见快速使用 ChatGLM 对话模型应用。
开发者体验 JupyterLab 、 Cloud Studio 进行 ChatGLM2-6B API 的配置调用。
开发者使用 Cloud Studio 应用推荐 ChatGPT Next Web 快速开发调用 ChatGLM2-6B OpenAI API 服务,搭建自己的 GPT。
开发者使用 高性能应用服务 HAI 快速部署 ChatGLM2-6B-int4 本地模型及基于 P-Tuning v2 的微调。
API 服务启用
使用 JupyterLab 启动
步骤一:进入 jupyter_lab 页面
1. 进入 jupyter_lab 控制台操作界面。
2. 在实例列表中选择更多 > JupyterLab 并进入该实例的详情页。

3. 初步认识并操作 JupyterLab。
4. 选择使用终端命令行操作。

注意:
如果您购买使用的是 基础型算力服务器(0.88元/小时) 请您在开始实验前输入以下关闭 webui 功能的命令,提高服务器的性能,以便后续实验能快速正常进行:
输入代码:
apt-get update && apt-get install sudosudo apt-get updatesudo apt-get install psmiscsudo fuser -k 6889/tcp #执行这条命令将关闭 HAI提供的 chatglm2_gradio webui功能
输入命令 用于开启 API 服务:
cd ./ChatGLM2-6Bpython api.py
步骤二:新增服务器端口规则
1. 找到需要新增的实例,单击 ID/实例名,进入实例详情页面。
2. 在端口配置页面。单击编辑规则。
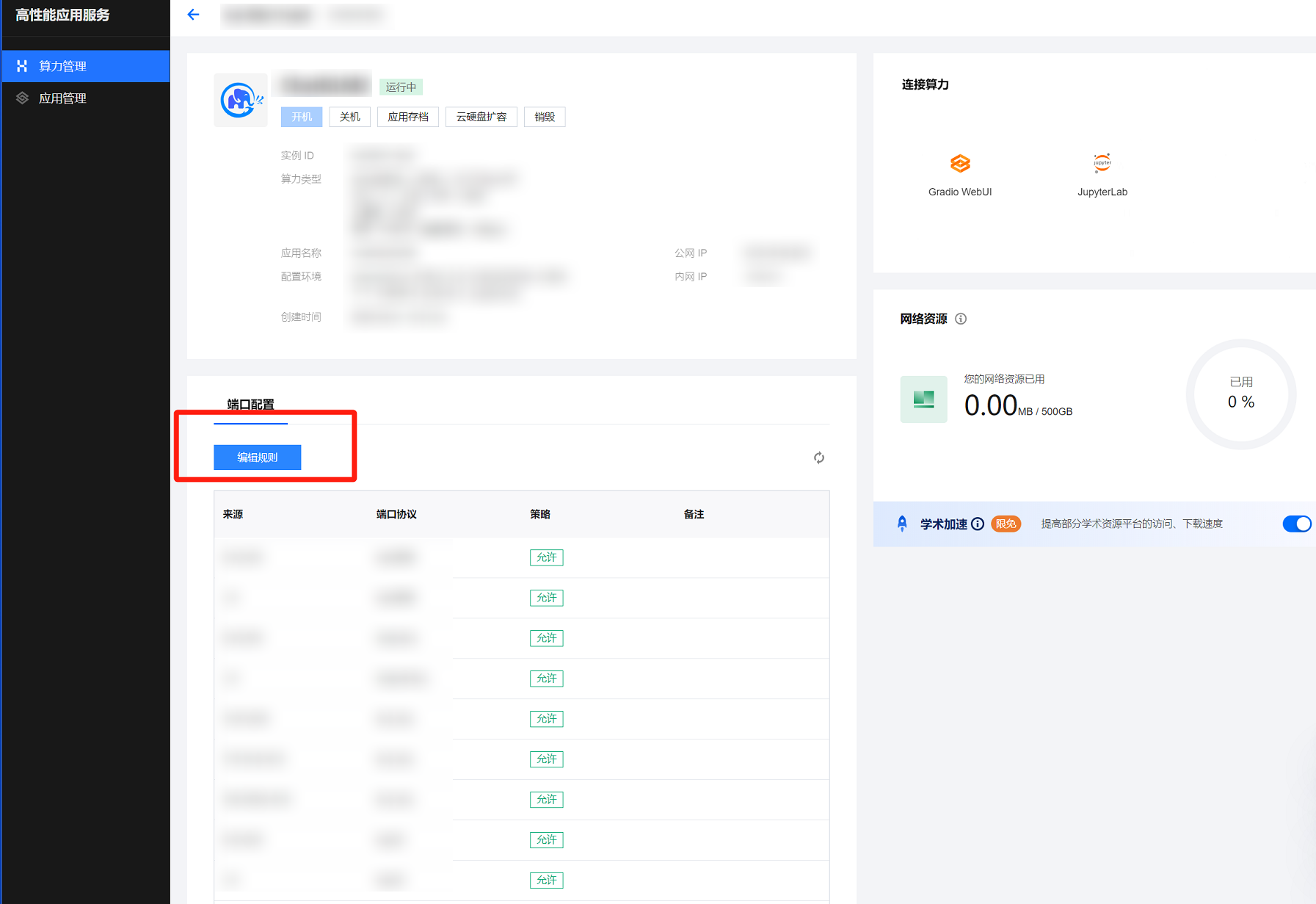
3. 在选择入站规则窗口中单击添加规则。
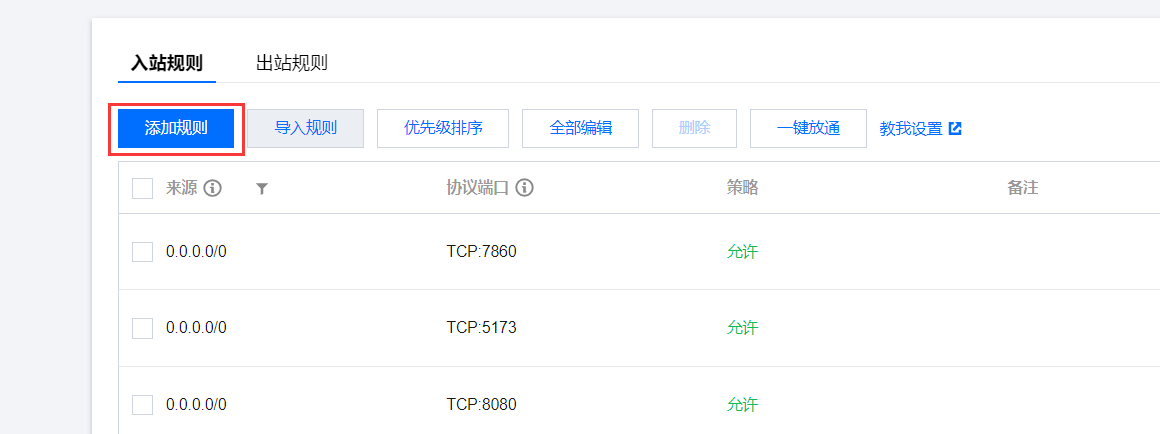
4. 添加入站规则 (来源: 0.0.0.0/0 协议端口: TCP:8000)

使用 Cloud Studio 启动
步骤一:打开 Cloud Studio 并创建开发空间
1. 进入 Cloud Studio 页面,单击立即使用。
2. 在 Cloud Studio 页面,单击右侧的新建模板。
3. 在新建工作空间弹窗中,输入空间名称 ,选择代码来源为空 ,开发环境为 Python 即可。
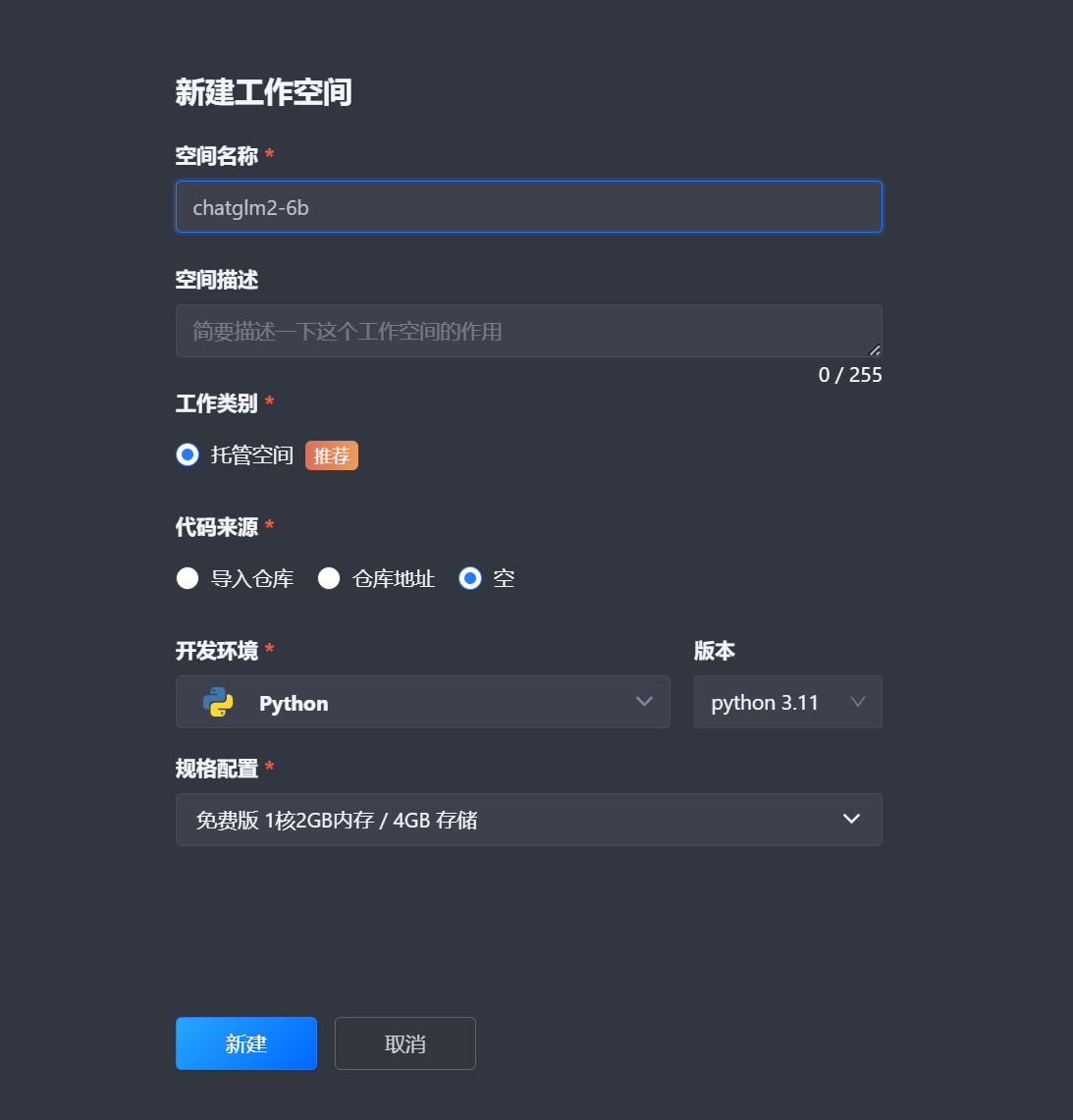
4. 单击新建。并完成工作空间创建。
步骤二:编写调用代码并运行测试
1. 在 workspace 下鼠标右键选择并选择新建文件。

2. 创建
get_api.py 代码文件,并复制以下代码用于测试请求。注意:
请确保将代码中的地址和端口更改为您的 API 服务器的实际地址和端口。
import requests# 定义测试数据,以及FastAPI服务器的地址和端口server_url = "http://0.0.0.0:8000" # 请确保将地址和端口更改为您的API服务器的实际地址和端口test_data = {"prompt": "'你好,发热了怎么办?'","history": [],"max_length": 50,"top_p": 0.7,"temperature": 0.95}# 发送HTTP POST请求response = requests.post(server_url, json=test_data)# 处理响应if response.status_code == 200:result = response.json()print("Response:", result["response"])print("History:", result["history"])print("Status:", result["status"])print("Time:", result["time"])else:print("Failed to get a valid response. Status code:", response.status_code)
3. 查看 ChatGLM2-6B 实例公网地址,并修改代码中服务器地址部分。
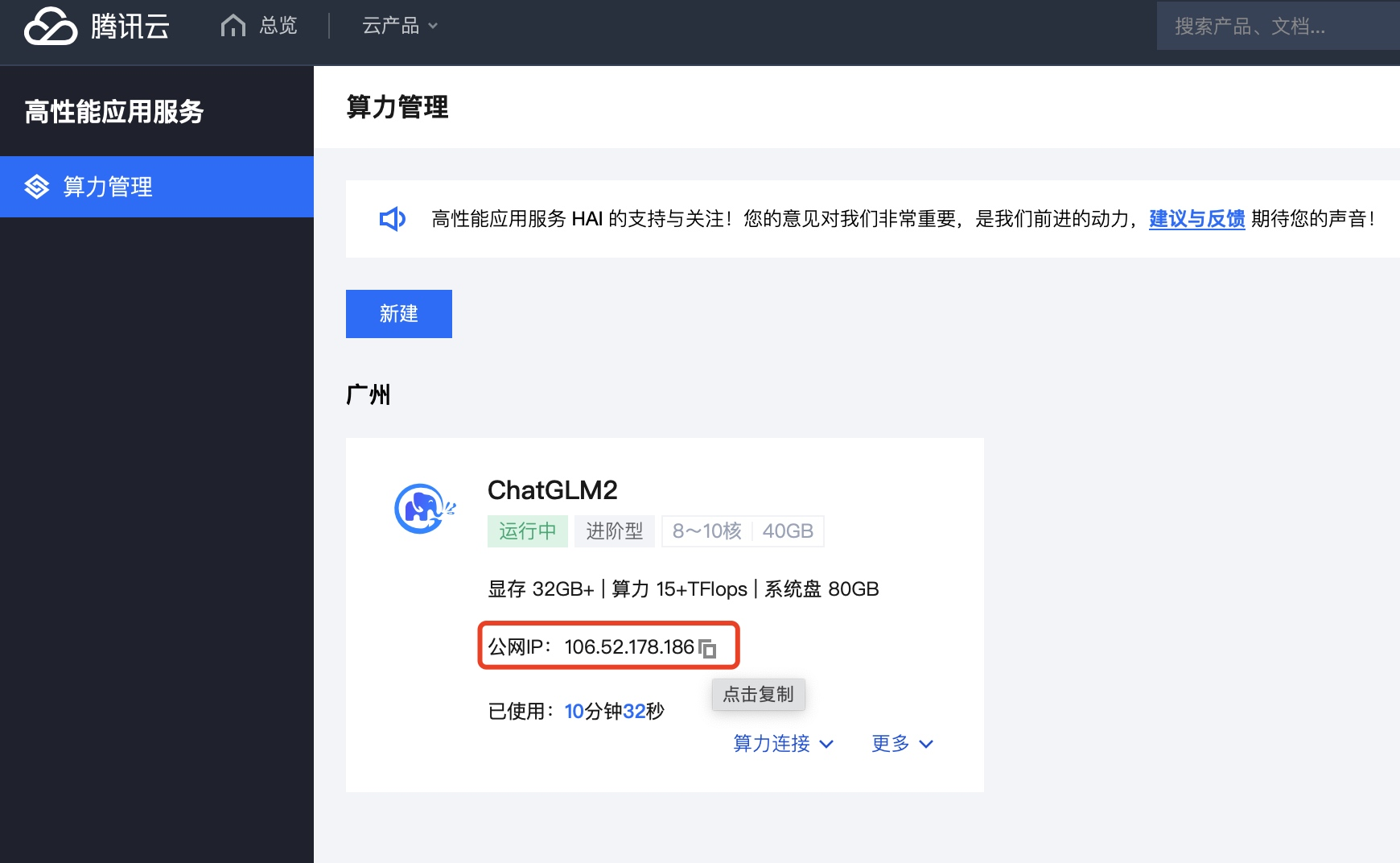
4. 修改完代码文件,可单击右上角的运行进行测试。

5. 返回请求结果如下图所示:
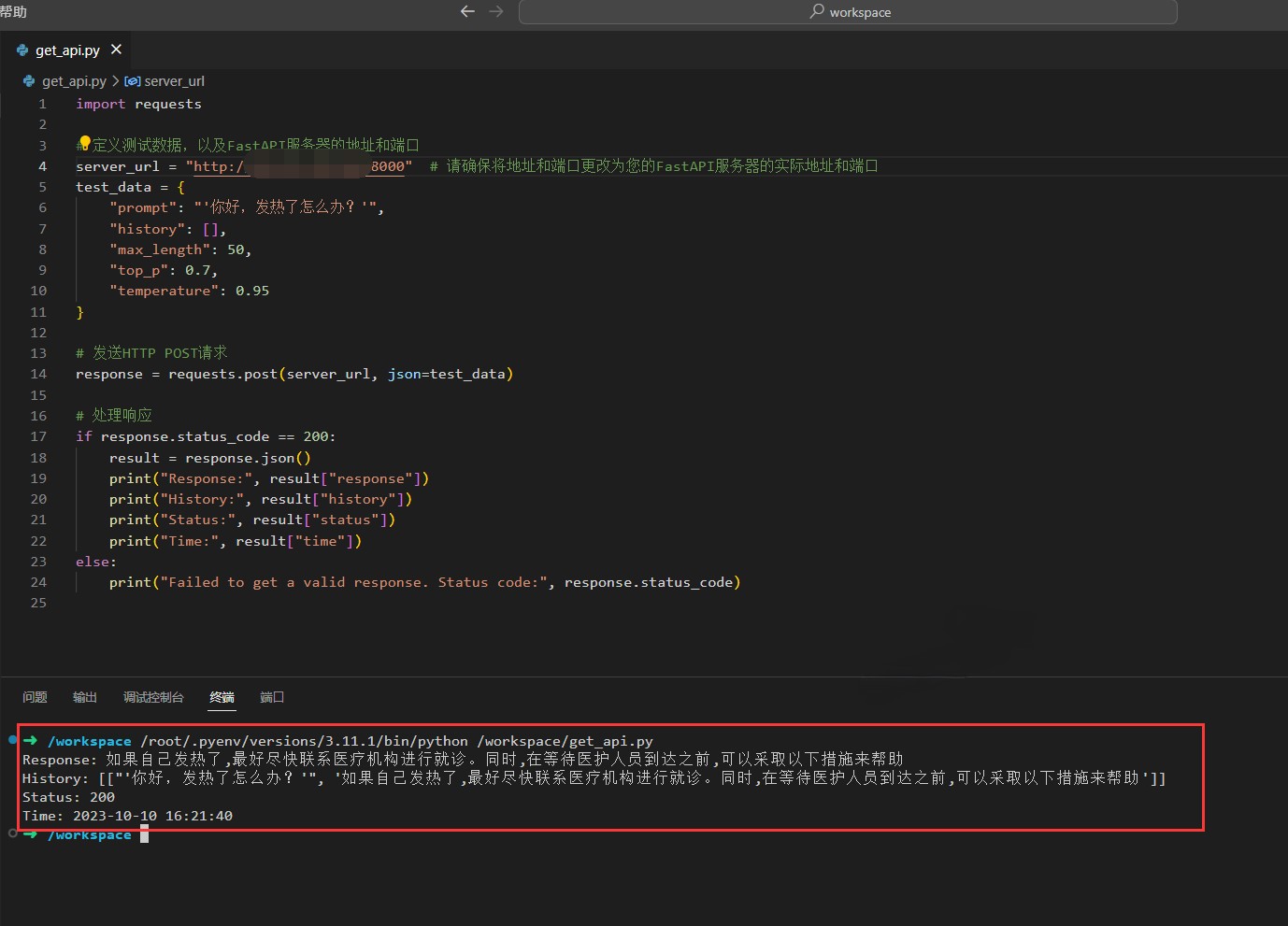
使用 JupyterLab 开发并使用 Cloud Studio 调用测试
步骤一:使用 JupyterLab 编写基于 FastAPI 编写的服务器端代码并开启服务
1. 在 JupyterLab 中选择文件夹操作界面,依次打开 root 文件夹下的 ChatGLM2-6B 文件夹,并创建一个 Python File ,拷贝一下代码并保存,同时将文件名修改为 chatglm2-6b-stream-api.py ,最后开启 API 服务。
2. 粘贴
chatglm2-6b-stream-api.py 代码。# -*-coding:utf-8-*-'''File Name:chatglm2-6b-stream-api.pyAuthor:LuofanTime:2023/6/26 13:33'''import osimport sysimport jsonimport torchimport uvicornimport loggingimport argparsefrom fastapi import FastAPIfrom transformers import AutoTokenizer, AutoModelfrom fastapi.middleware.cors import CORSMiddlewarefrom sse_starlette.sse import ServerSentEvent, EventSourceResponsedef getLogger(name, file_name, use_formatter=True):logger = logging.getLogger(name)logger.setLevel(logging.INFO)console_handler = logging.StreamHandler(sys.stdout)formatter = logging.Formatter('%(asctime)s %(message)s')console_handler.setFormatter(formatter)console_handler.setLevel(logging.INFO)logger.addHandler(console_handler)if file_name:handler = logging.FileHandler(file_name, encoding='utf8')handler.setLevel(logging.INFO)if use_formatter:formatter = logging.Formatter('%(asctime)s - %(name)s - %(message)s')handler.setFormatter(formatter)logger.addHandler(handler)return loggerlogger = getLogger('ChatGLM', 'chatlog.log')MAX_HISTORY = 3class ChatGLM():def __init__(self) -> None:logger.info("Start initialize model...")self.tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True)self.model = AutoModel.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True).cuda()self.model.eval()logger.info("Model initialization finished.")def clear(self) -> None:if torch.cuda.is_available():with torch.cuda.device(f"cuda:{args.device}"):torch.cuda.empty_cache()torch.cuda.ipc_collect()def answer(self, query: str, history):response, history = self.model.chat(self.tokenizer, query, history=history)history = [list(h) for h in history]return response, historydef stream(self, query, history):if query is None or history is None:yield {"query": "", "response": "", "history": [], "finished": True}size = 0response = ""for response, history in self.model.stream_chat(self.tokenizer, query, history):this_response = response[size:]history = [list(h) for h in history]size = len(response)yield {"delta": this_response, "response": response, "finished": False}logger.info("Answer - {}".format(response))yield {"query": query, "delta": "[EOS]", "response": response, "history": history, "finished": True}def start_server(http_address: str, port: int, gpu_id: str):os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID'os.environ['CUDA_VISIBLE_DEVICES'] = gpu_idbot = ChatGLM()app = FastAPI()app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"])@app.get("/")def index():return {'message': 'started', 'success': True}@app.post("/chat")async def answer_question(arg_dict: dict):result = {"query": "", "response": "", "success": False}try:text = arg_dict["query"]ori_history = arg_dict["history"]logger.info("Query - {}".format(text))if len(ori_history) > 0:logger.info("History - {}".format(ori_history))history = ori_history[-MAX_HISTORY:]history = [tuple(h) for h in history]response, history = bot.answer(text, history)logger.info("Answer - {}".format(response))ori_history.append((text, response))result = {"query": text, "response": response,"history": ori_history, "success": True}except Exception as e:logger.error(f"error: {e}")return result@app.post("/stream")def answer_question_stream(arg_dict: dict):def decorate(generator):for item in generator:#yield ServerSentEvent(json.dumps(item, ensure_ascii=False), event='delta')yield ServerSentEvent(json.dumps(item, ensure_ascii=False))try:text = arg_dict["query"]ori_history = arg_dict["history"]logger.info("Query - {}".format(text))if len(ori_history) > 0:logger.info("History - {}".format(ori_history))history = ori_history[-MAX_HISTORY:]history = [tuple(h) for h in history]return EventSourceResponse(decorate(bot.stream(text, history)))except Exception as e:logger.error(f"error: {e}")return EventSourceResponse(decorate(bot.stream(None, None)))@app.get("/free_gc")def free_gpu_cache():try:bot.clear()return {"success": True}except Exception as e:logger.error(f"error: {e}")return {"success": False}logger.info("starting server...")uvicorn.run(app=app, host=http_address, port=port, workers=1)if __name__ == '__main__':parser = argparse.ArgumentParser(description='Stream API Service for ChatGLM2-6B')parser.add_argument('--device', '-d', help='device,-1 means cpu, other means gpu ids', default='0')parser.add_argument('--host', '-H', help='host to listen', default='0.0.0.0')parser.add_argument('--port', '-P', help='port of this service', default=8000)args = parser.parse_args()start_server(args.host, int(args.port), args.device)
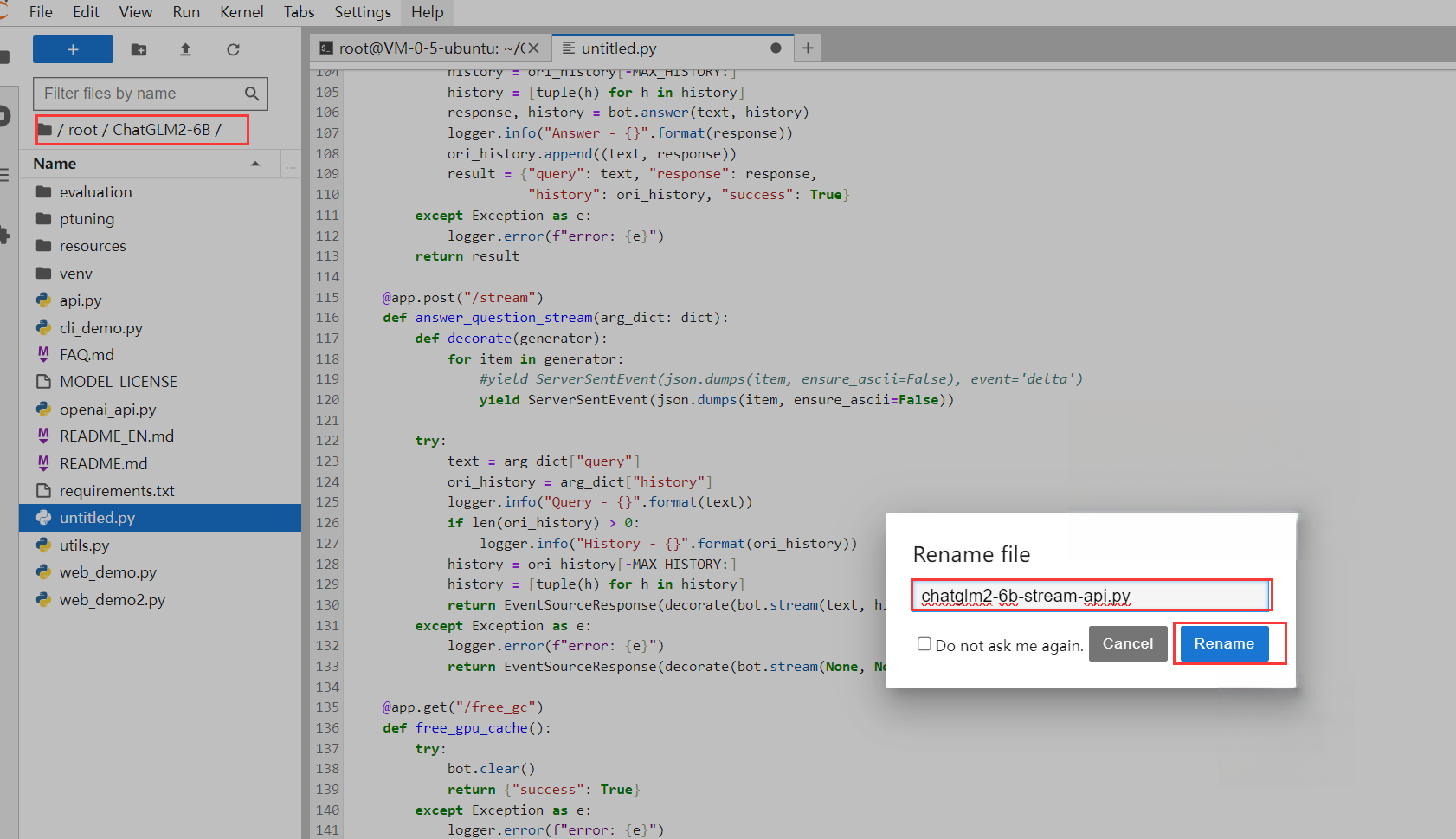
3. 在 JupyterLab 中完成文件的创建并重命名 chatglm2-6b-stream-api.py 成功:
4. 在 JupyterLab 终端界面 中输入命令开启 chatglm2-6b-stream-api.py 服务。
python chatglm2-6b-stream-api.py
注意:
请将上一个 API服务关闭,否则服务无法启动成功。

步骤二:使用 Cloud Studio 编写客户端代码
说明:
使用普通 Http 请求调用 /chat 接口。
1. 在 Cloud Studio 工作空间下继续创建 Python 代码文件 use_chatglm2-6b-stream-api.py。
注意:
请将代码中的地址和端口更改为实际的服务器地址和端口。
use_chatglm2-6b-stream-api.py 代码文件:
import requestsimport json# 设置服务器地址和端口server_address = "http://0.0.0.0" # 请将地址和端口更改为实际的服务器地址和端口server_port = 8000# 构造请求数据request_data = {"query": "你好,发热了怎么办?","history": []}# 发送HTTP POST请求到聊天端点response = requests.post(f"{server_address}:{server_port}/chat", json=request_data)# 处理响应if response.status_code == 200:result = response.json()if result["success"]:print("Response:", result["response"])print("History:", result["history"])else:print("Failed to get a valid response.")else:print("Failed to connect to the server. Status code:", response.status_code)
创建完成后运行并查看返回结果:
在菜单栏中点击 终端 选择 新建终端,输入命令执行代码。
python use_chatglm2-6b-stream-api.py
调用接口成功。
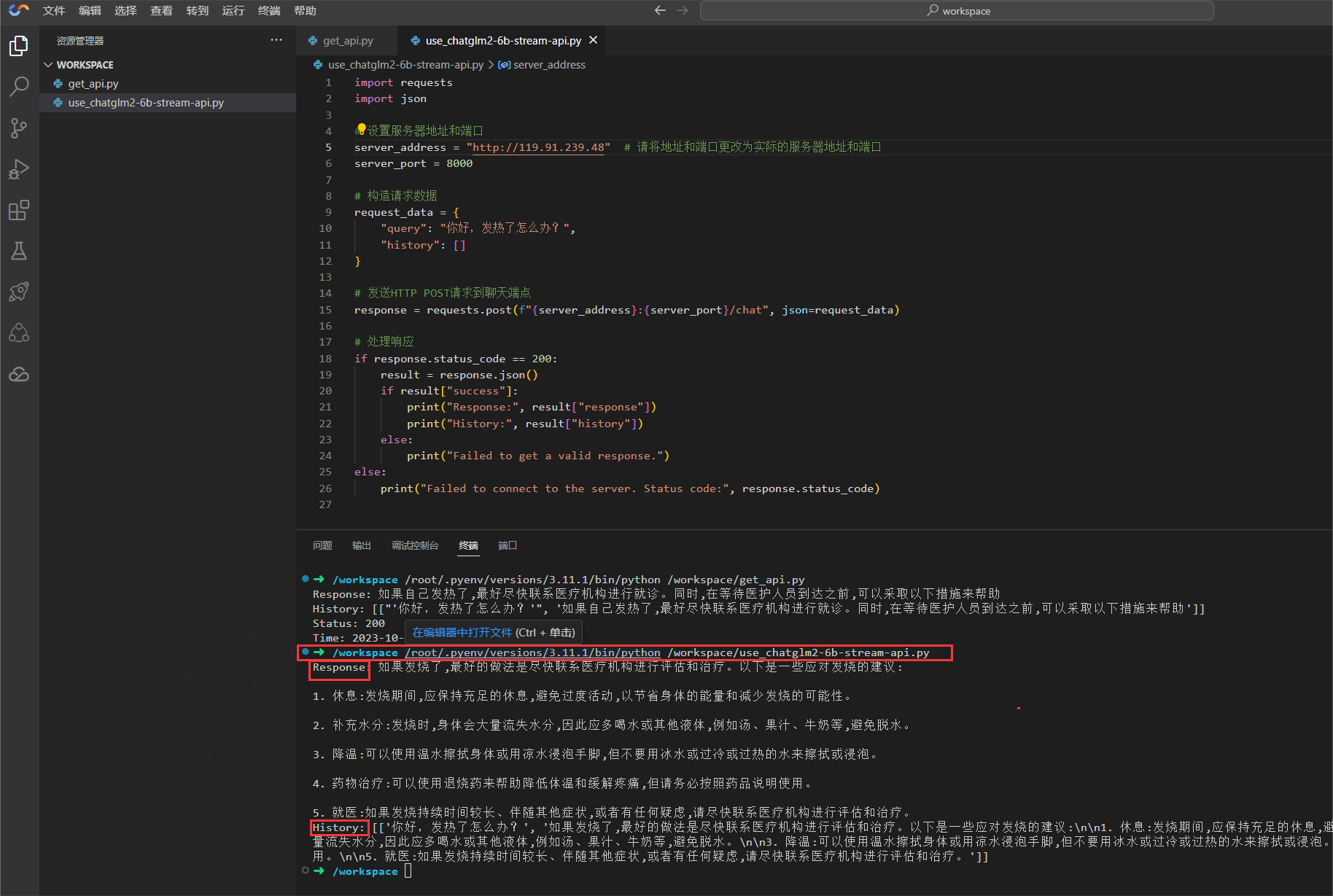
服务端查看记录:

说明:
使用 AioHttp 调用 /stream 流式接口。
2. 在 Cloud Studio 工作空间下继续创建 Python 代码文件 use_stream_chatglm2-6b-stream-api.py。
注意:
请将代码中的地址和端口更改为实际的服务器地址和端口
use_stream_chatglm2-6b-stream-api.py 代码文件:
import aiohttpimport jsonimport asyncioasync def main():async with aiohttp.ClientSession() as session:server_address = "http://0.0.0.0" # 请将地址更改为实际的服务器地址server_port = 8000endpoint = f"{server_address}:{server_port}/stream" # 流式处理端点request_data = {"query": "你好,发热怎么办?","history": []}try:async with session.post(endpoint, json=request_data, timeout=None) as response:if response.status == 200:async for line in response.content.iter_any():data = line.decode('utf-8')data = data.replace('event: delta\\r\\ndata: ','')data = data.replace('\\r\\n','')data = data.replace('data: ','')try:result = json.loads(data)if result.get("finished"):print("Response:", result["response"])print('\\r\\n')print("History:", result["history"])#else:# print("Delta:", result["delta"])except json.JSONDecodeError:print("Failed to parse JSON:")else:print(f"Failed to connect to the server. Status code: {response.status}")except aiohttp.ClientError as e:print(f"Client error occurred: {e}")await asyncio.sleep(1) # Avoid continuous failures, wait a bit before retryingprint(f"Unexpected error occurred: {e}")await asyncio.sleep(1) # Avoid continuous failures, wait a bit before retryingif __name__ == '__main__':asyncio.run(main())
在终端中输入命令 安装 aiohttp 模块。
pip install aiohttp
运行并查看返回结果:
在终端中输入命令执行代码。
python use_stream_chatglm2-6b-stream-api.py
使用 ChatGPT Next Web 模板启动
说明:
开发者使用 Cloud Studio 创建应用推荐 ChatGPT Next Web 开源项目 并快速开发调用 ChatGLM2-6B OpenAI API 服务。
1. 使用 JupyterLab 修改 openai_api.py 代码并开启服务。
注意:
打开 JupyterLab 后关闭上一次开启的 API 服务,使用 Ctrl+C 关闭服务。
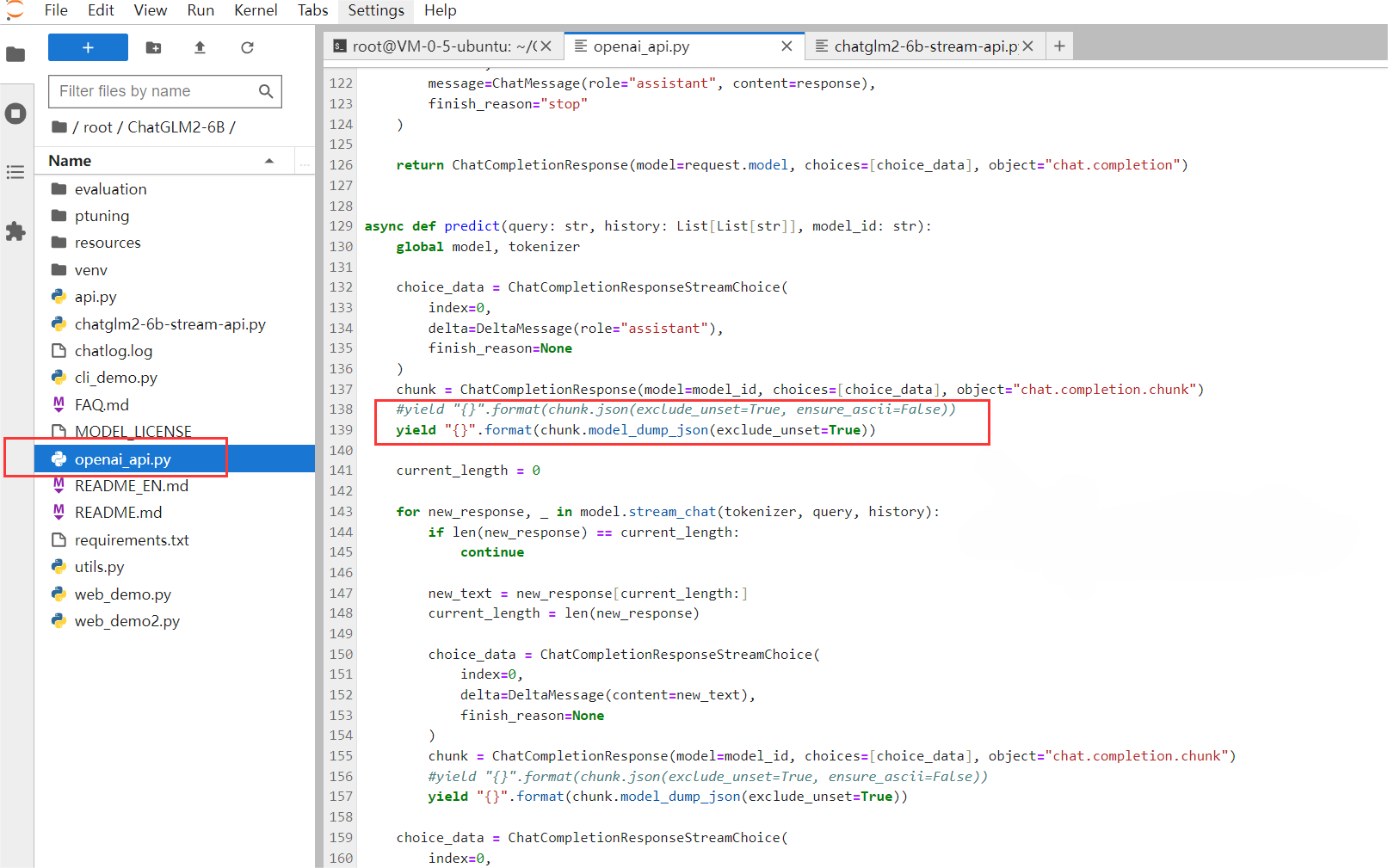
如果直接调用 openai_api.py 代码会报错,因此复制以下代码覆盖文件并保存文件。
# coding=utf-8# Implements API for ChatGLM2-6B in OpenAI's format. (https://platform.openai.com/docs/api-reference/chat)# Usage: python openai_api.py# Visit http://localhost:8000/docs for documents.import timeimport torchimport uvicornfrom pydantic import BaseModel, Fieldfrom fastapi import FastAPI, HTTPExceptionfrom fastapi.middleware.cors import CORSMiddlewarefrom contextlib import asynccontextmanagerfrom typing import Any, Dict, List, Literal, Optional, Unionfrom transformers import AutoTokenizer, AutoModelfrom sse_starlette.sse import ServerSentEvent, EventSourceResponse@asynccontextmanagerasync def lifespan(app: FastAPI): # collects GPU memoryyieldif torch.cuda.is_available():torch.cuda.empty_cache()torch.cuda.ipc_collect()app = FastAPI(lifespan=lifespan)app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],)class ModelCard(BaseModel):id: strobject: str = "model"created: int = Field(default_factory=lambda: int(time.time()))owned_by: str = "owner"root: Optional[str] = Noneparent: Optional[str] = Nonepermission: Optional[list] = Noneclass ModelList(BaseModel):object: str = "list"data: List[ModelCard] = []class ChatMessage(BaseModel):role: Literal["user", "assistant", "system"]content: strclass DeltaMessage(BaseModel):role: Optional[Literal["user", "assistant", "system"]] = Nonecontent: Optional[str] = Noneclass ChatCompletionRequest(BaseModel):model: strmessages: List[ChatMessage]temperature: Optional[float] = Nonetop_p: Optional[float] = Nonemax_length: Optional[int] = Nonestream: Optional[bool] = Falseclass ChatCompletionResponseChoice(BaseModel):index: intmessage: ChatMessagefinish_reason: Literal["stop", "length"]class ChatCompletionResponseStreamChoice(BaseModel):index: intdelta: DeltaMessagefinish_reason: Optional[Literal["stop", "length"]]class ChatCompletionResponse(BaseModel):model: strobject: Literal["chat.completion", "chat.completion.chunk"]choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]created: Optional[int] = Field(default_factory=lambda: int(time.time()))@app.get("/v1/models", response_model=ModelList)async def list_models():global model_argsmodel_card = ModelCard(id="gpt-3.5-turbo")return ModelList(data=[model_card])@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)async def create_chat_completion(request: ChatCompletionRequest):global model, tokenizerif request.messages[-1].role != "user":raise HTTPException(status_code=400, detail="Invalid request")query = request.messages[-1].contentprev_messages = request.messages[:-1]if len(prev_messages) > 0 and prev_messages[0].role == "system":query = prev_messages.pop(0).content + queryhistory = []if len(prev_messages) % 2 == 0:for i in range(0, len(prev_messages), 2):if prev_messages[i].role == "user" and prev_messages[i+1].role == "assistant":history.append([prev_messages[i].content, prev_messages[i+1].content])if request.stream:generate = predict(query, history, request.model)return EventSourceResponse(generate, media_type="text/event-stream")response, _ = model.chat(tokenizer, query, history=history)choice_data = ChatCompletionResponseChoice(index=0,message=ChatMessage(role="assistant", content=response),finish_reason="stop")return ChatCompletionResponse(model=request.model, choices=[choice_data], object="chat.completion")async def predict(query: str, history: List[List[str]], model_id: str):global model, tokenizerchoice_data = ChatCompletionResponseStreamChoice(index=0,delta=DeltaMessage(role="assistant"),finish_reason=None)chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")#yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))yield "{}".format(chunk.model_dump_json(exclude_unset=True))current_length = 0for new_response, _ in model.stream_chat(tokenizer, query, history):if len(new_response) == current_length:continuenew_text = new_response[current_length:]current_length = len(new_response)choice_data = ChatCompletionResponseStreamChoice(index=0,delta=DeltaMessage(content=new_text),finish_reason=None)chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")#yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))yield "{}".format(chunk.model_dump_json(exclude_unset=True))choice_data = ChatCompletionResponseStreamChoice(index=0,delta=DeltaMessage(),finish_reason="stop")chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")#yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))yield "{}".format(chunk.model_dump_json(exclude_unset=True))yield '[DONE]'if __name__ == "__main__":tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True)model = AutoModel.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True).cuda()# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量# from utils import load_model_on_gpus# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)model.eval()uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
修改后的 openai_api.py 示意图:
服务端开启服务:
python openai_api.py

2. 使用 Cloud Studio 快速创建 应用推荐 下的 ChatGPT Next Web 开源项目。
2.1 打开 Cloud Studio 开发空间下,我们创建的项目,并停止服务。

2.2 成功后,打开 应用推荐 选择 ChatGPT Next Web 项目。
选择 Fork。
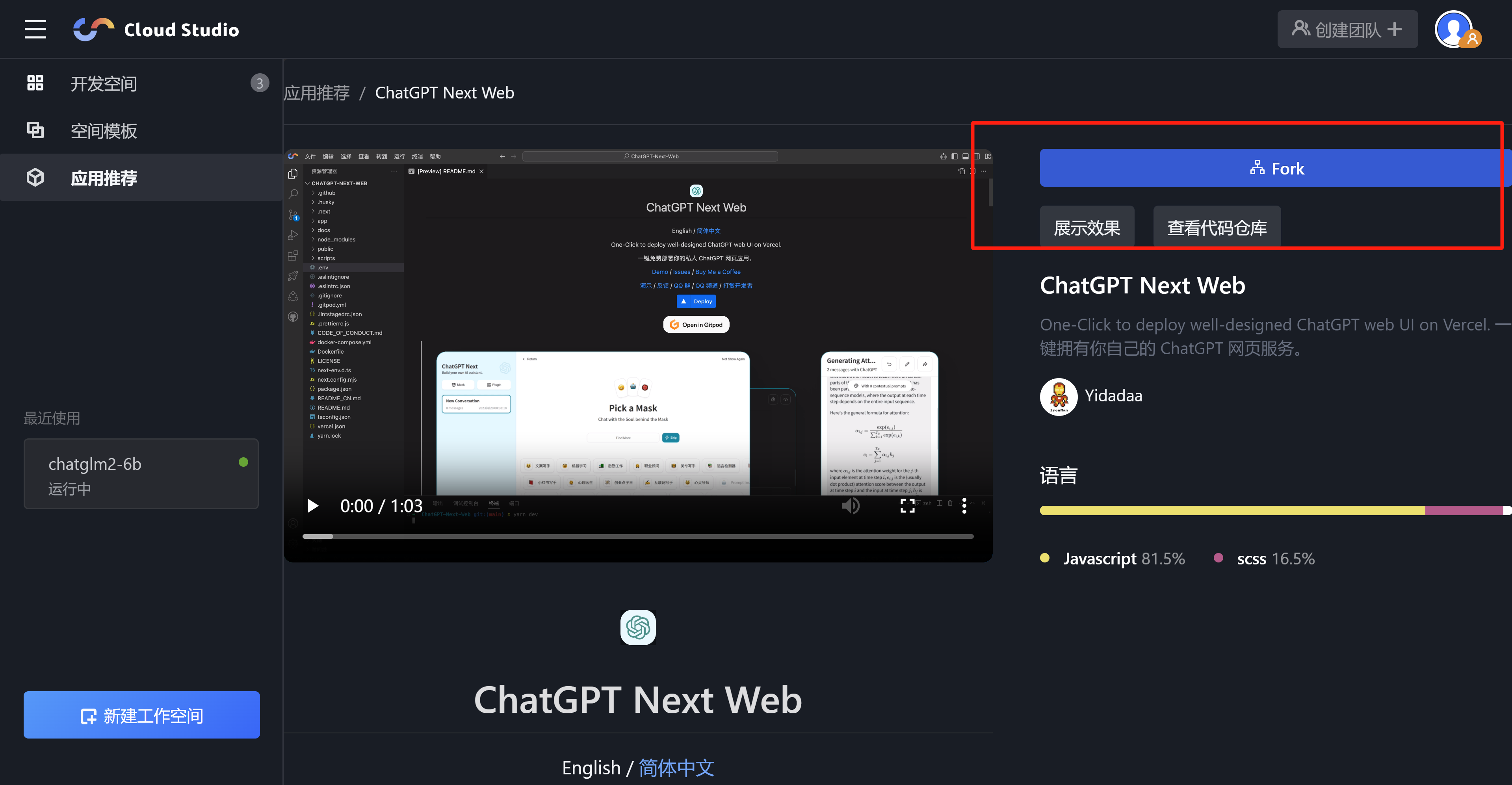
3. 使用 Cloud Studio 快速配置并启动项目。
3.1 Fork 完成后,选择 .env.template 文件,修改 OPENAI_API_KEY 为非空字符串,并配置 API 地址和端口,然后在终端输入命令:
npm install
3.2 依赖安装完成后,输入命令开启服务。
yarn dev
3.3 单击端口 ,可使用 浏览器或标签页 两种方式运行项目。

web浏览器测试:
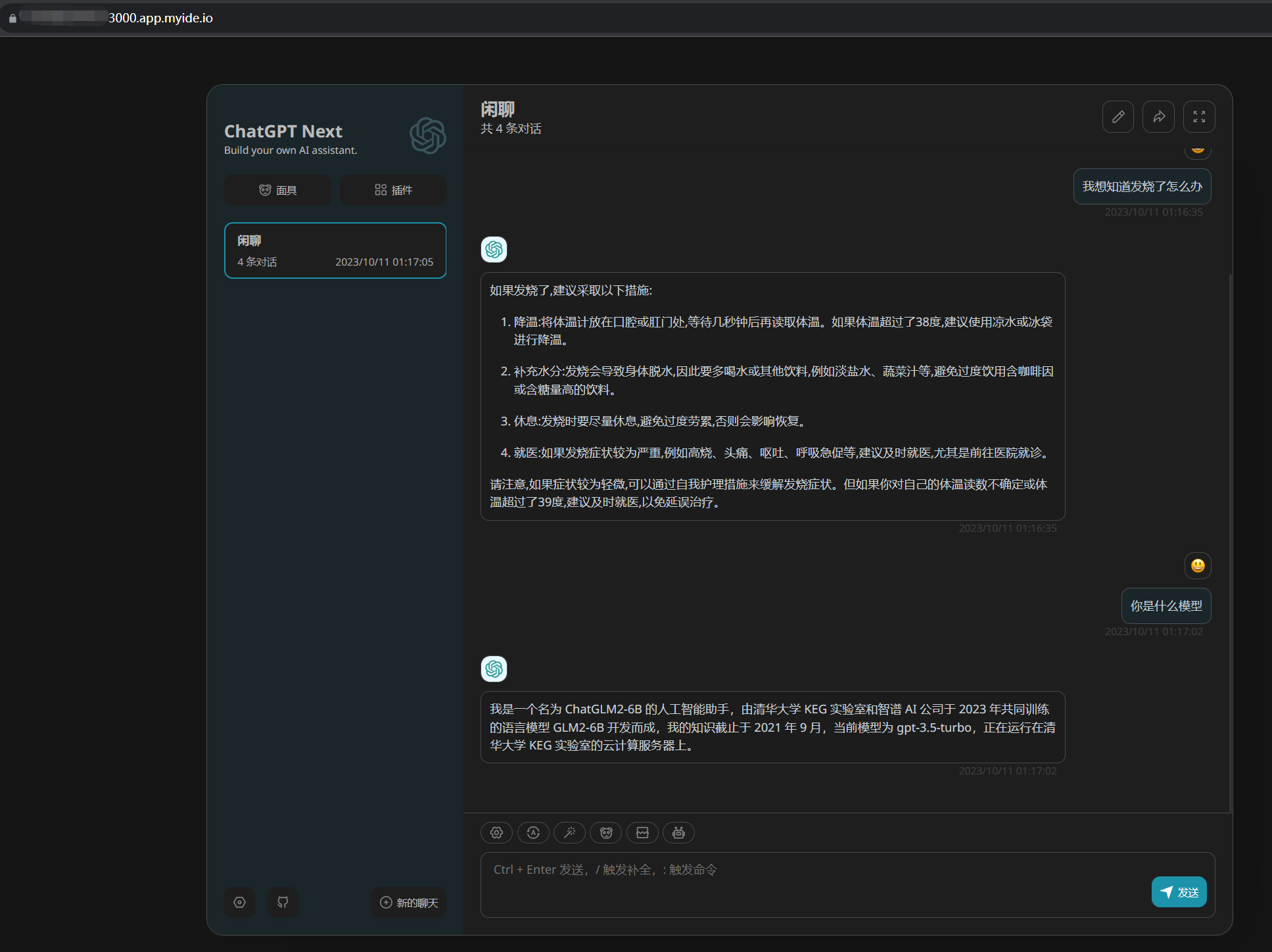
Cloud Studio 标签页查看:

服务端可查看相关的请求记录:




