部署架构
腾讯云向量数据库(Tencent Cloud VectorDB)采用分布式部署架构。客户端请求通过 Load balance 分发到各节点上。每个节点相互通信和协调,实现数据存储与检索。
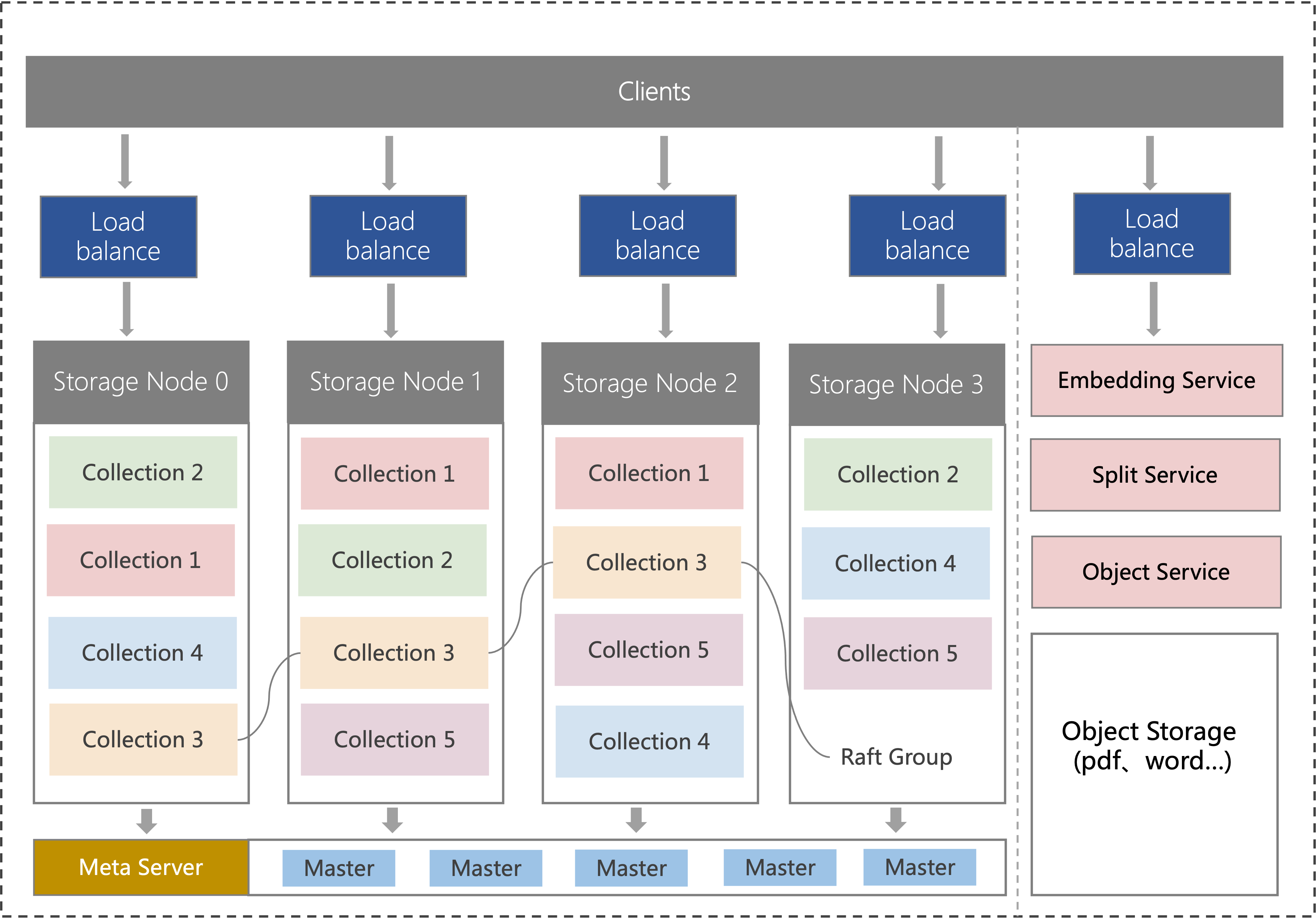
负载均衡(Load Balancer,LB):是对多台后端服务器进行流量分发的服务。向量数据库集群架构节点数量 >= 3,自动通过 Load balance 来均衡访问。
分布式 Storage Node:向量数据库集群由多个节点构成,每个节点均可直接进行读/写操作,负责数据的计算及存储。Collection 是向量数据的基本组织形式,将向量集合拆分成多个分片,并分配到不同的节点上进行存储和处理;每个分片还会在其他节点上同步产生多个副本,以保证数据库服务的可扩展性与高可用性。
Meta Server:集群管理模块,由一组 Master 节点组成,负责存储集群的节点信息、数据分片信息等元数据信息。
Embedding Service:是一种将非结构化数据(如文本、图像、音频等)转换为向量表示的服务,从而方便进行分析、聚类等操作。具体信息,请参见 Embedding 介绍。
Split Service:是一种将文本拆分成短语或句子等的服务。
Object Service:负责将数据批量导入到指定集合,支持多种数据导入格式。
Object Storage:用于存储和管理数据导入服务中上传的数据文件。
逻辑架构
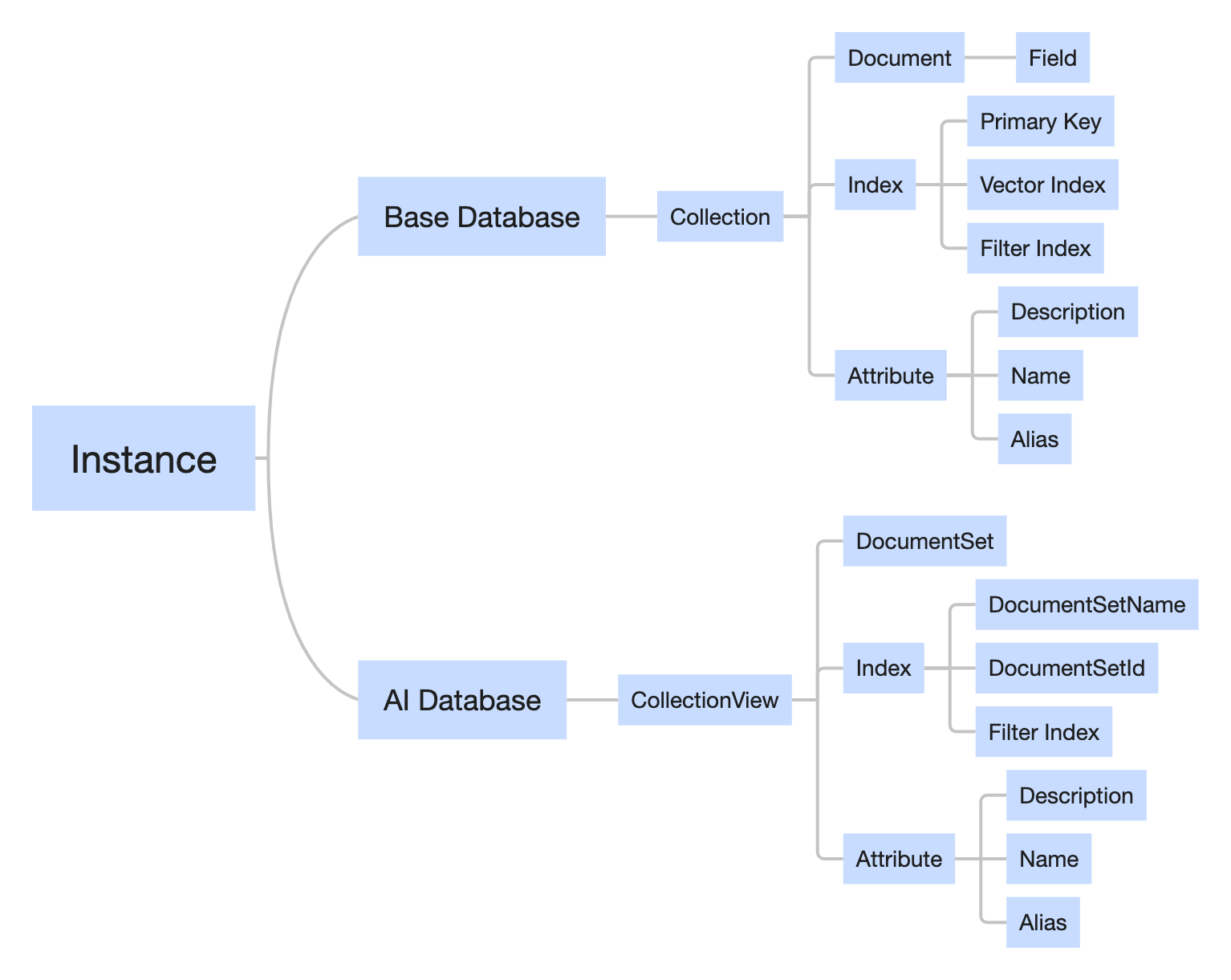
在 VectorDB 中,数据库实例是最高层级的容器,用于存储多个 Database,而一个 Database 包含多个集合。Collection 与 CollectionView 是具有相同数据结构和语义的 Document 容器。其逻辑结构,如下图所示。
基本概念 | 含义 |
实例(Instance) | 用户购买向量数据库服务的基本单位。 |
Base Database | 可直接操作向量数据的数据库,包含一系列相关 Collection 的集合。 该类数据库可直接写入向量数据,可对存储的向量数据进行修改、清理等。 该类数据库可写入文本信息,通过 Embedding 自动向量化,存储原始文本与向量数据,可修改原始文本信息,进而修改数据。 |
AI Database | 指专门用于 AI 套件上传并存储文件的向量数据库, 包含一系列相关 CollectionView 集合视图。该类数据库对已上传的文件不支持更新文件内容,无法直接对向量数据进行操作。 |
Collection | Base 类数据库具有相似属性文档组的集合,相当于关系型数据库中的表。一个 Database 中可以包含多个 Collection。 副本与分片:创建 Collection 时需根据预估数据规模和业务需求,指定集合所需的副本数和分片数。分片是将数据集合拆分为多个更小的部分,每个部分放在不同的节点,以提高系统性能;而副本则是对每一个数据分片的备份,保障系统的可靠性。 动态 Schema:创建 Collection 时支持根据数据属性按需自定义字段,设计灵活、易用。 |
CollectionView | AI 类数据库中一组具有相似属性的文档组集合,相当于关系型数据库中的表。只是 CollectionView 是针对 AI 类数据库文档组的集合视图,由多个 DocumentSet 组成。每个 DocumentSet 存储一组数据,对应一个文件。多个 DocumentSet 构成一个CollectionView。 副本与分片:创建 CollectionView 无需指定实例副本与分片,系统根据文件内容的大小自动调整分配资源。 动态 Schema:创建 CollectionView 支持灵活扩展文件 Metadata 信息的标量字段。 |
Document | Base 类数据库中一个 Collection 中可以包含多个 Document。每个 Document 由多个字段(Field)组成形成一条向量数据。每个 Field 以键值对(key:value)的形式存储,相当于关系型数据库中的数据字段。 说明: 动态 Schema:腾讯云向量数据库(Tencent Cloud VectorDB)支持在创建 Collection 时灵活扩展属性字段,同时支持在更新数据时新增字段。这意味着用户无需预先定义所有的字段,可以根据需要在插入数据时自动识别并调整模式。这种设计使得 VectorDB 更加灵活和易于使用,同时也避免了预定义所有字段带来的限制。 |
DocumentSet | DocumentSet 是 AI 类数据库中 CollectionView 中的一个概念,用于存储文件的单元。在 CollectionView 中,一个文件会被拆分成多个 Document,这些 Document 组成了一个完整的文件数据,也就是一个DocumentSet。DocumentSet 可看作是一组相关的 Document 的集合,它们对应着同一个文件的数据。 说明: 动态 Schema:腾讯云向量数据库(Tencent Cloud VectorDB)支持在创建 CollectionView 时灵活扩展文件 Meta 信息的标量字段,同时支持更新或新增标量字段。 |
Index | 一种用于加速检索的数据结构,分为主键检索、向量索引和 Filter 索引。 主键索引(Primary Key Index):是一种用于快速查找特定行的数据库索引类型。在主键索引中,每个行都有一个唯一的标识符,称为主键。主键索引使用这些主键来快速查找特定行,而不需要扫描整个表。腾讯云向量数据库默认将 Document id 或 DocumentSet ID 作为主键来构建主键索引。 向量索引(Vector Index):是一种用于快速查找相似向量的数据库索引类型。在向量索引中,每个向量都被索引,并且可以通过计算它们之间的相似度来快速查找最相似的向量。向量索引通常用于处理大规模的高维数据,当前所支持的相似度算法,请参见相似性计算。 Filter 索引(Filter Index):是建立在标量字段的索引。标量字段被建立 Filter 索引之后,向量检索时,将依据 Filter 指定的标量字段的条件表达式来查找相似向量,请参见 Filter 条件表达式。 |
属性(Attribute) | 标识 Collection 或 CollectionView 的其他属性,基本属性如下所示,可以根据具体需求进行自定义和扩展,以适应不同的业务场景和数据类型。 Name:集合名称。 Description:集合的备注信息,用于描述集合的业务属性或其他信息。 Alias:集合别名。别名可以是一个简短的字符串,方便标识和访问对应的集合。当使用别名访问时,用户不感知真实集合名的变化,适用于数据迁移到新集合后的一键切换场景。 |
安全设计
多副本设计:腾讯云向量数据库(Tencent Cloud VectorDB)的多副本设计是指将数据库的数据复制到多个副本中,以提高系统的可用性和容错性。在多副本设计中,用户可以在 Collection 级别指定副本数,每个副本分布在不同的节点。当某个节点发生故障时,系统可以自动从其他节点的副本中获取数据,从而保证系统的连续性和稳定性。同时,多副本设计还可以提高系统的性能和可扩展性。
多可用区:腾讯云向量数据库默认为多可用区分布式集群化部署,这意味着将数据的副本分布在多个可用区域,以确保系统的高可用性和容错性。每个可用区都是一个独立的数据中心,拥有自己的计算、存储和网络资源,避免单点故障和保证系统的稳定性。当前默认为多可用区部署,暂不支持用户自定义可用区。
登录鉴权:腾讯云向量数据库(Tencent Cloud VectorDB)使用账号(account)和 API 密钥(api_key)的组合进行鉴权,以验证用户身份并授权其访问。客户端向服务端发起 HTTP 请求时,需要在请求的 Header 中携带 account 和 api_key。服务端在接收到请求后,会对 api_key 的合法性进行判断。如果 api_key 合法,则服务端会根据请求的内容做出正确的响应。鉴权时 Token 的格式为
account=root&api_key=xxx。私有网络:腾讯云向量数据库运行于私有网络环境中。私有网络(Virtual Private Cloud,VPC)是一块在腾讯云上自定义的逻辑隔离网络空间,基于隧道技术,在物理网络上构造虚拟网络,使用虚拟化技术,实现不同私有网络之间内网完全隔离。这种网络环境为用户提供了独立、隔离的安全云网络,可以有效地保护用户的数据安全和隐私,确保数据库的安全性和可靠性。
安全组:一种虚拟防火墙,具备有状态的数据包过滤功能,用于设置云服务器、负载均衡、云数据库等实例的网络访问控制,控制实例级别的出入流量,是重要的网络安全隔离手段。腾讯云向量数据库支持配置安全组,以控制云数据库实例的网络访问,从而保护云资源的安全性。安全组支持基于 IP 地址、端口号、协议等多种条件进行访问控制,可以根据不同的业务需求,设置不同的访问规则。
访问管理(Cloud Access Management,CAM):腾讯云提供的一套 Web 服务,用于帮助客户安全地管理腾讯云账户的访问权限,资源管理和使用权限。腾讯云向量数据库通过 CAM 可以创建、管理和销毁用户(组),并通过身份管理和策略管理控制哪些人可以使用哪些数据库资源,资源细粒度控制,提供企业级的安全防护。
通信协议
腾讯云向量数据库(Tencent Cloud VectorDB)支持通过 HTTP 协议进行数据写入和查询等操作。您可以将不同类型的请求消息以 JSON 格式放入 HTTP 请求消息 Body 中,将请求发送到 VectorDB 的HTTP API 地址即可。VectorDB 将自动解析请求消息 Body 中的 JSON 数据,并将其存储到数据库中。
VectorDB 使用 HTTP 协议中的 GET、POST 等标准 HTTP 方法来执行不同的操作。同时,VectorDB 的 HTTP API 还使用 HTTP 状态码和响应头来表示请求的结果和状态,以及使用 URL 来标识资源。这种设计风格使得 VectorDB 的 HTTP API 易于使用和理解,并且可以方便地与其他系统进行集成。
VectorDB 通过提供 VPC 网络隔离和发送请求时在 HTTP 头部信息中携带实例账号和 API 密钥进行身份认证来保证数据的安全性,通过 JSON 格式的结构体进行数据交换,每个请求都会返回一个标准的 HTTP 响应状态码和响应内容。若操作失败,用户可以根据响应内容获取到具体错误信息。
在发送请求时,客户端在 HTTP 头部信息中携带账号和 API 密钥,这些信息会以 HTTP 参数的形式进行传递(HTTP 参数格式为account=root&api_key=xxx)。服务端会对 API 密钥的合法性进行判断,并根据判断结果做出相应的响应。
您可以使用
curl 命令发送 HTTP 请求消息,如下为创建数据库的请求示例。其中,请求头部信息中携带了账号和 API 密钥,分别为“root”和“abcdefg”。curl -i -X POST \\-H 'Content-Type: application/json' \\-H 'Authorization: Bearer account=root&api_key=abcdefg' \\http://10.0.X.X:80/database/create \\-d '{"database": "db-test"}'
参数 | 参数解释 |
curl | 执行命令 |
-X | 指定 HTTP 请求方法,常用的请求方法如下所示: GET:从数据库集群获取资源。 POST:向数据库提交数据,用于创建资源或处理数据。 |
-H | 指定 HTTP 请求头,该示例设置了两个请求头,含义如下所示: 'Content-Type: application/json' ,表示请求的消息 Body 是 JSON 格式的。 'Authorization: Bearer account=root&api_key=abcdefg' \\http://10.0.X.X:80/database/create,表示请求消息的安全认证信息。 account=root:向量数据库账号信息。数据库当前仅支持 root 账号。 api_key=abcdefg:API 请求密钥信息。 http://10.0.X.X:80/database/create:请求访问的 URL 地址。由以下参数拼接而成。 10.0.X.X:指向量数据库的内网 IP 地址。 80:向量数据库默认的访问端口。 /database/create:指创建向量数据库的 API 接口。 |
-d | 指定 HTTP 请求消息 Body。这里使用 JSON 格式传递了一个参数为"database",值为"db-test"的数据。 |



