工具介绍
工具脚本 | 说明 |
用于导入 Jsonl 类型的数据文件于向量数据库 |
python3.9 import_json_into_vdb.py\\--url="http://xx.xx.xx.xx:80"\\--key="xB2iQyVVFy9AtEFswF4ohQ******************"\\--db="db-test-0905" --collection="test-jsonl"\\--file="./test_json_XX.jsonl"\\--field_mappings="pk=id"
参数 | 参数含义 | 说明 |
url | 向量数据库实例的内网地址或外网地址。建议使用内网方式。 | |
key | 向量数据库实例 API 密钥,用于进行身份认证。 | |
db | 数据库名。 | - |
collection | 数据库集合名。 | - |
file | 预导入的 jsonl 文件的路径。 | 可以指定为绝对地址,也可以为相应程序运行的相对地址。 支持使用通配符,例如:--file="./test_*.jsonl"\\,将文件名包含 test_ 的 Jsonl 文件批量导入数据库。 |
field_mappings | 指定Jsonl 字段名与导入数据库字段的映射关系。 | Jsonl 字段与数据库字段名不一致需配置映射关系,一致则无需配置。 key = value,key 为 Jsonl 字段,value 为向量数据库字段名,切勿写反。 |
confirm_work | 标识是否通过 nohup 命令在后台运行数据导入任务。 Y:默认值,可在终端会话确认参数配置是否正确。 N:可以通过 nohup 的方式来在后台运行程序。 | 如果导入海量数据,建议先设置 confirm_work=Y 确认配置参数是否正确,提示 please check the parameters and field mappings [yes no]:输入 no 退出,再设置 confirm_work=N 配合 nohup 后台运行程序。 |
使用示例
1. 准备如下工作。
说明:
该脚本工具当前不支持 Embedding 文本向量化,需创建直接写入向量数据的集合。
创建集合时,请注意向量数据维度与 JSON 文件的向量数据维度一致,并根据业务需要指定必要的 Filter 字段。
2. 将数据导入工具的 Python 脚本上传于运行的操作环境,同时上传 Jsonl 文件。
说明:
JSON 文件格式,要求每一行一个 JSON 对象,例如:
{"pk":1,"name":"张三","vector":[0.11592275, -0.13876367, ...]}。向量数据字段支持如下两种表达格式。
float数组:[0.11, 0.23,...]。
float数组字符串:"[0.11, 0.23,...]"。
3. 根据 jsonl 文件业务数据与文件路径,在文本编辑器配置工具脚本参数,如下所示。
python3.9 import_json_into_vdb.py\\--url="http://10.0.xx.xx:80"\\--key="xB2iQyVVFy9AtEFswF4ohQP******************"\\--db="db-test-0905" --collection="test-jsonl"\\--file="./test_json*.jsonl"\\--field_mappings="pk=id"
4. 在操作环境运行脚本,显示如下信息,逐一确认相关参数,索引字段以及字段映射关系。
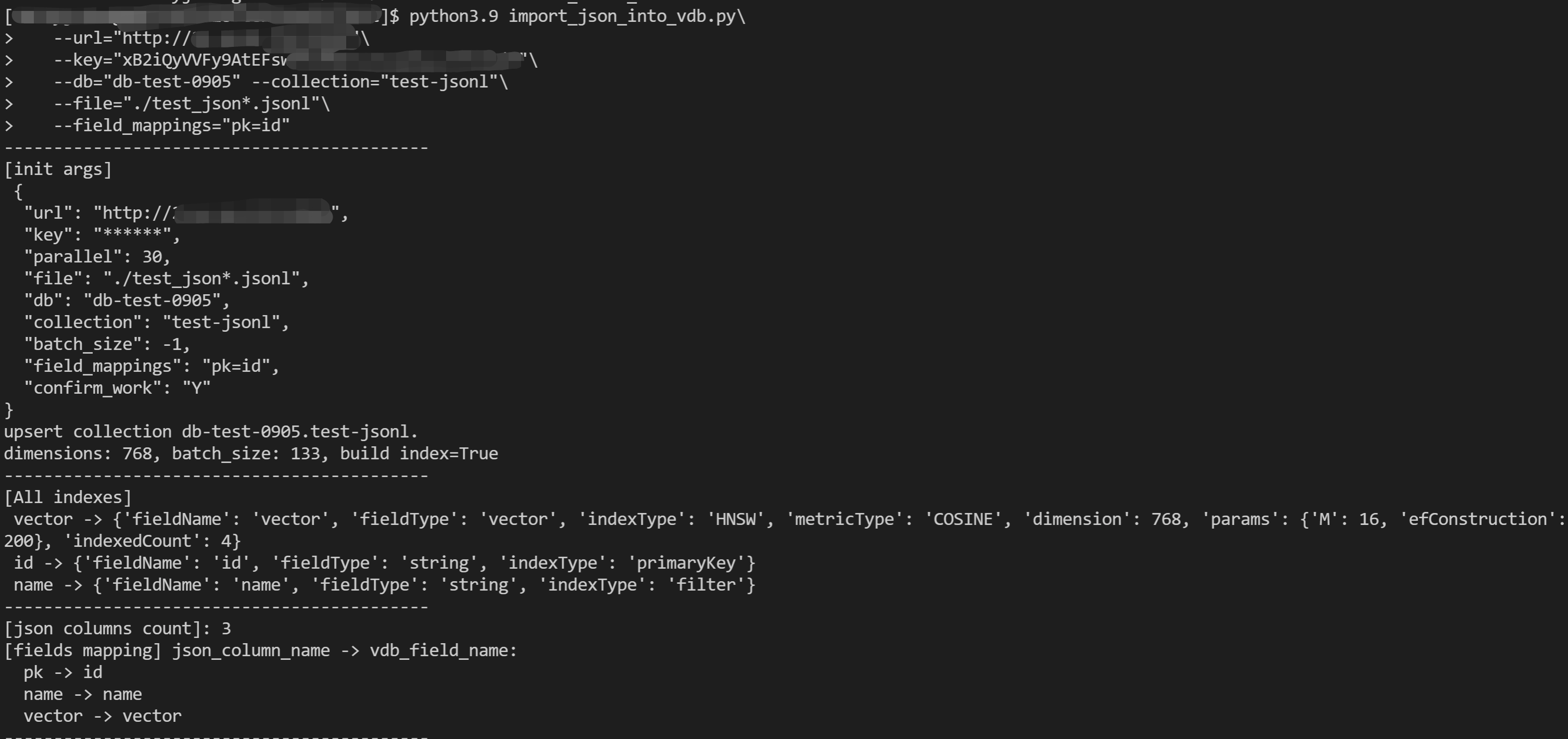
5. 提示
please check the parameters and field mappings [yes no]:,输入yes,启动数据导入任务。说明:
当导入数据量大时,推荐先使用默认值(confirm_work=Y)运行,在终端会话确认索引参数、映射字段设置正确,提示
please check the parameters and field mappings [yes no]:,输入 no,退出之后再指定 confirm_work=N,重新启动程序,在后台运行数据导入任务。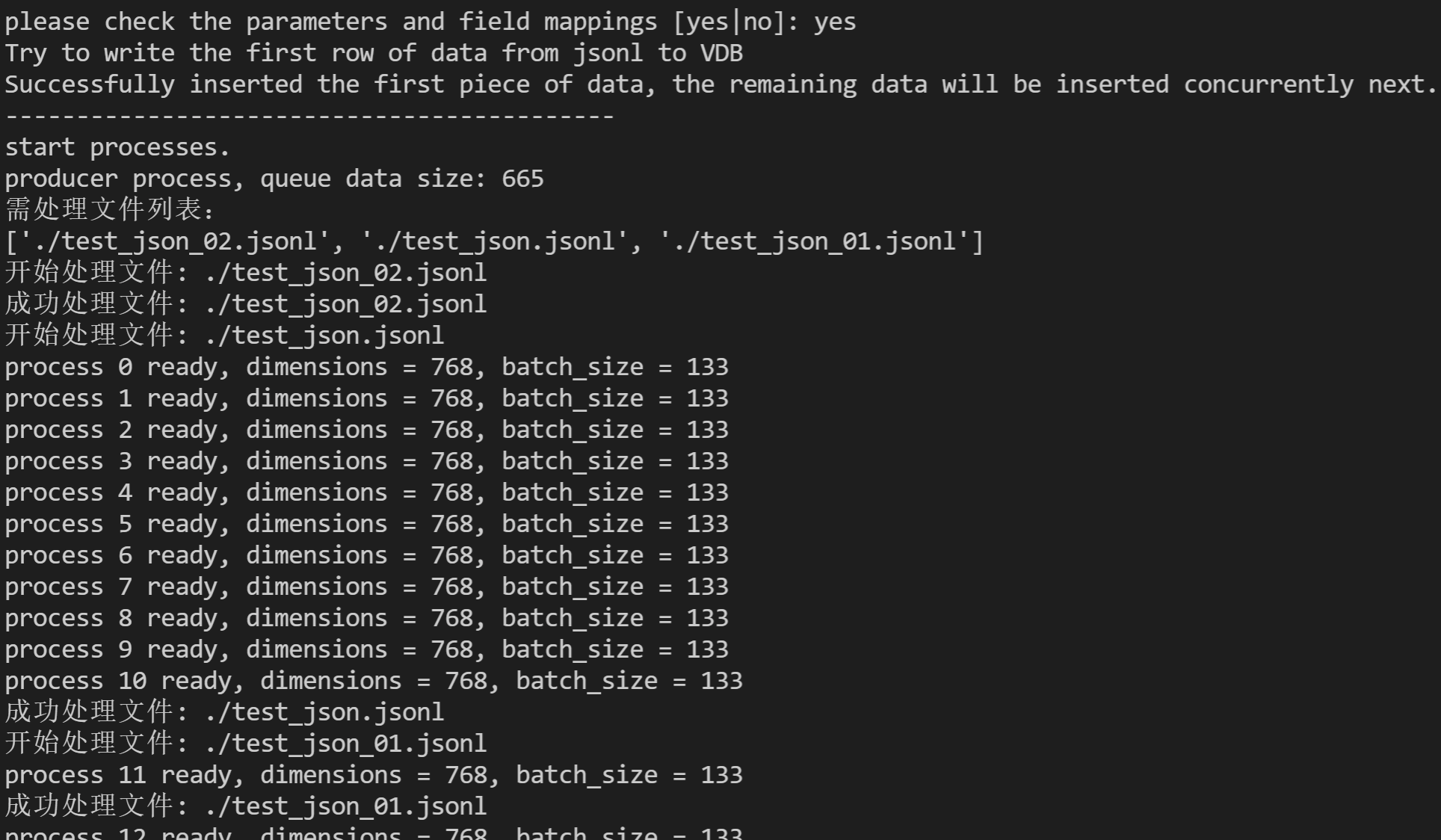
6. 等待提示类似如下信息,说明数据导入完成。
12 rows were successfully inserted into the VDB.avg batch latency: 4651.70ms, batch size: 133TPS: 40.056, dimensions: 768, parallel: 30



