概述
数据集成是指将不同来源与格式的数据逻辑上或物理上进行集成的过程,从而为企业提供全面的数据共享,以获得统一且更有价值的视图的过程,致力于帮助企业在复杂、异构的数据源中寻找正确的决策,提供高速稳定的数据环境。
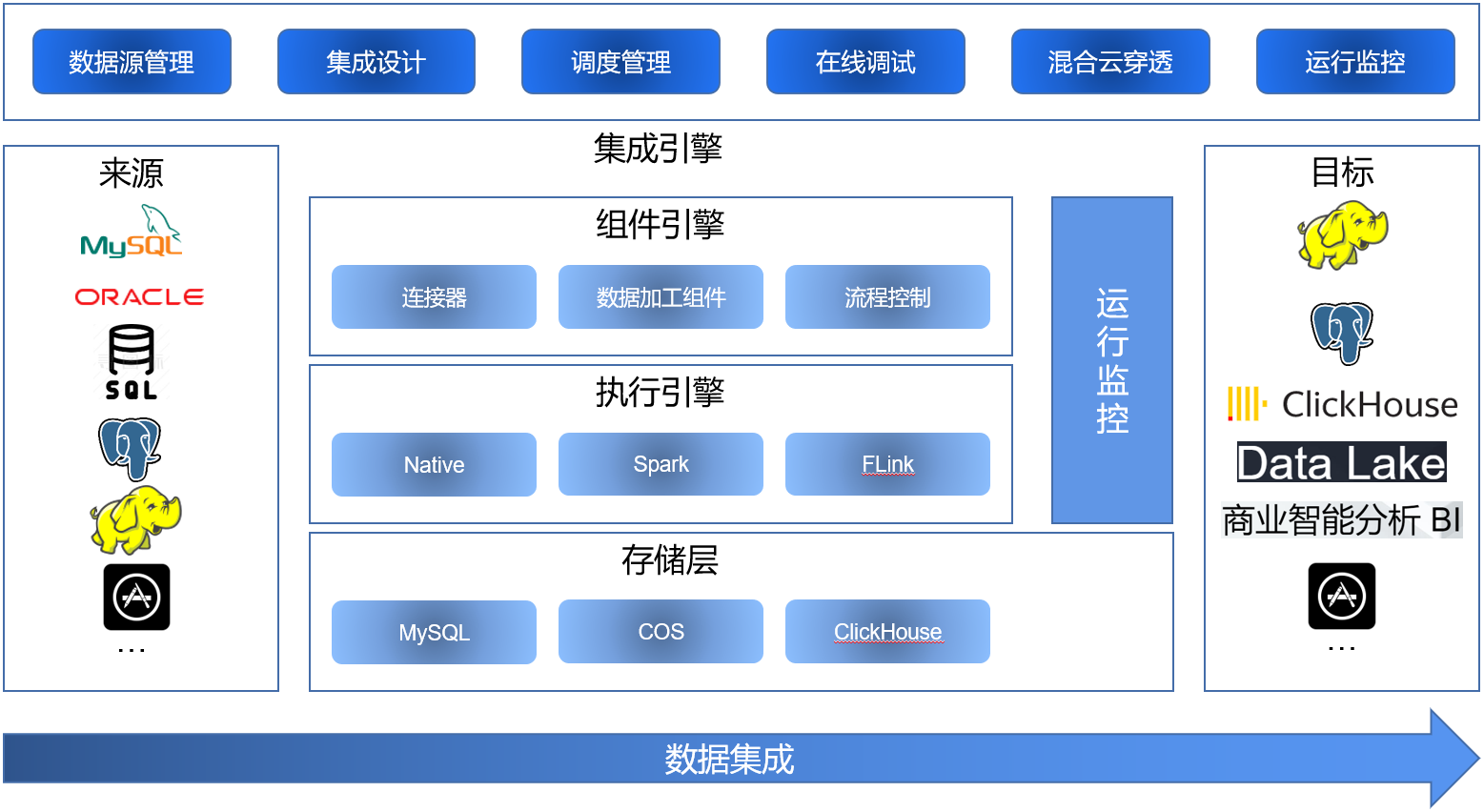
数据集成帮助企业安全充分的利用好数字资产,让数据来帮助智慧决策,让数据来驱动业务。
腾讯轻联数据集成可连接多种异构数据源,满足企业数据源多样、多版本的情况。
腾讯轻联支持定时、手工、事件触发机制,支持全量、增量的数据同步,支撑不同数据、不同场景的集成需求。
腾讯轻联提供丰富的数据加工组件帮助企业实现对原始数据的清洗加工,确保数据的高价值。
腾讯轻联支持大数据量的同步,帮助企业数据入湖、数仓,实现数据整合的价值最大化。
使用场景
数据湖开发:数据集成可以将数据从孤岛式的本地平台或 SaaS 服务同步到数据湖中,以提高数据价值。
数据仓储:数据集成可以将各种来源的数据整合到一个数据仓库中进行分析,为数据计算、分析做准备,以实现最终业务目的。
数智营销:数据集成可以将您的所有营销数据(例如客户人群特征、社交网络和网络分析数据)移动到一个地方以执行分析和相关操作。
工业物联网:数据集成有助于将多个物联网来源的数据整合到一个地方,便于您从中获取价值。
数据库复制:数据集成是将数据从 Oracle、SqlServer 或 MySQL 等源数据库复制到云数据仓库这一操作的核心部分。
应用一体化集成:通过主数据、业务单据的同步,实现 ERP、应用与 SaaS 服务的混合云业务一体化。
使用示例
数据库数据同步
从来源应用数据库(类型 MySQL)将一张或多张表数据同步到目标应用数据库。
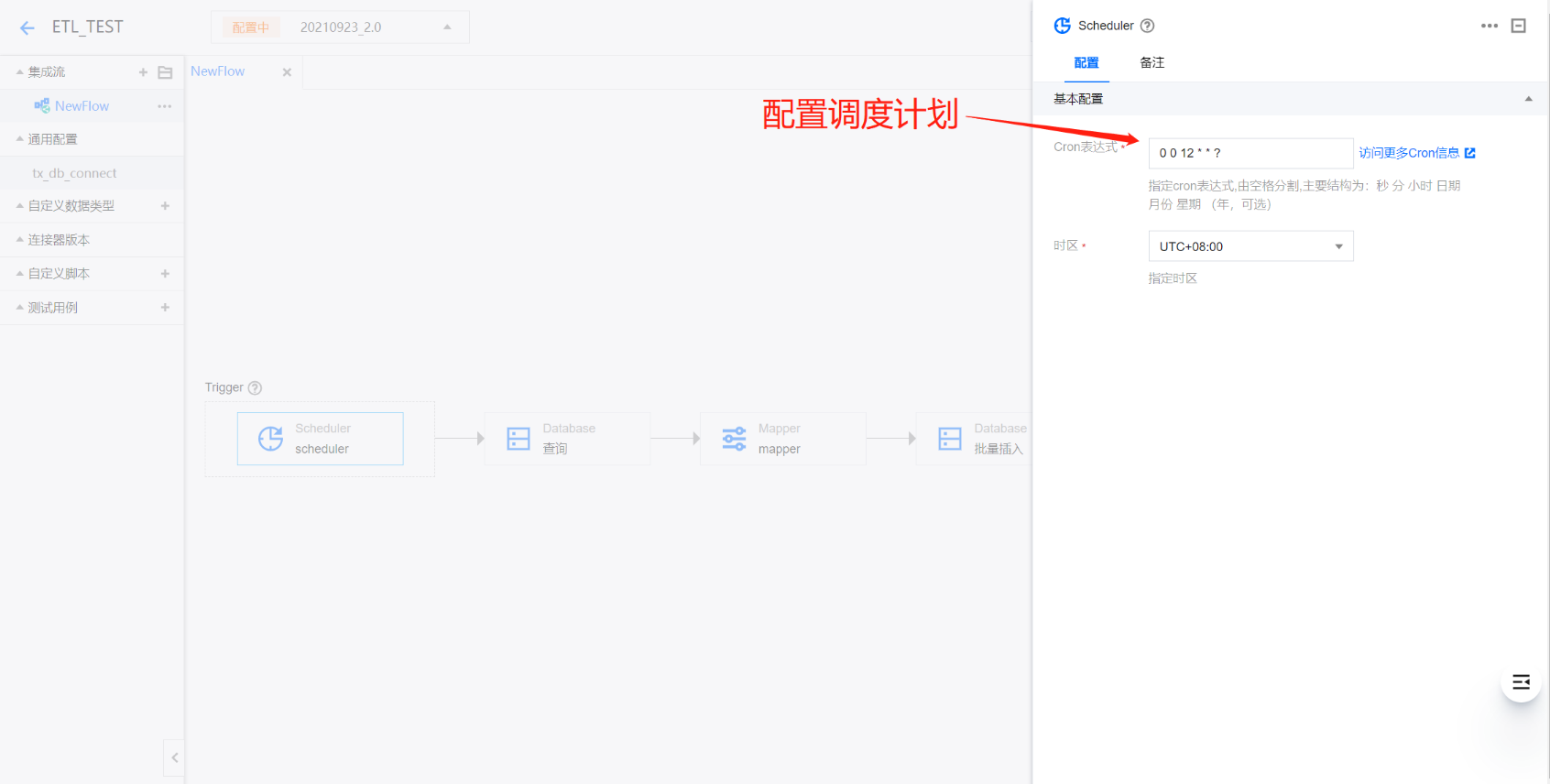
1. 通过 Scheduler 调度计划来定时同步数据。
2. 通过 Database 连接来源应用的数据库,配置同步的数据范围,包括行、列两个维度范围。同样,通过 Database 连接目标应用的数据库,配置数据同步插入的目标表。
3. 配置完来源和目标后,在来源和目标中间插入数据映射转换组件 Mapper,实现来源对象和目标对象的映射和转换配置,即将获取来源的数据根据 Mapper 的映射关系保存到目标数据库中。实现从来源应用数据库定时将数据抽取经过映射转换加载到目标应用数据库。

配置说明
1. 配置 Scheduler。在集成设计器画布中的 Triger 区域处单击,选择 Scheduler 组件,在右侧弹出的配置面板中输入定时执行的表达式,配置调度规则。例如:输入0 0 12 * * ?,则将在每天的12点调度执行此数据集成任务。
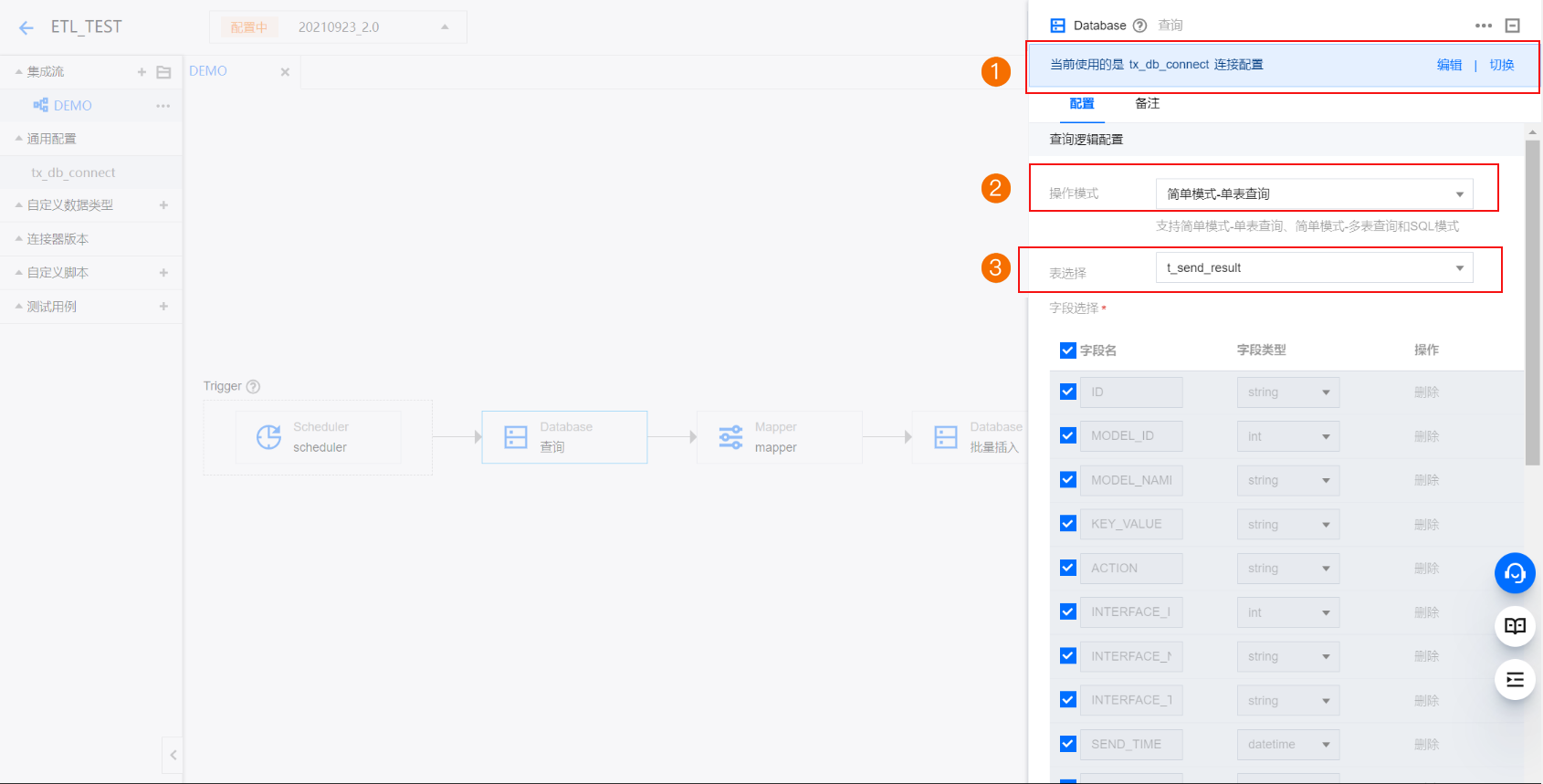
2. 配置来源应用数据库。设置从数据源中抽取数据,抽取数据交由后续组件处理,最终将抽取出来的数据进行加工后加载到目标数据库。具体操作如下:
2.1 在画布中的 Scheduler 组件后单击 +,在选择组件面板中搜索 Database,单击 Database 连接器,在操作面板中选择查询,将在画布中添加 Database 连接器,同时在右侧弹出配置面板:
2.1.1 配置数据源 DB 的链接。
2.1.2 选择获取数据的操作模式。
2.1.3 编写查询数据的 SQL 语句或选择数据来源表。
2.2 连接配置:数据源类型选择 MySql(根据实际应用场景选择不同的数据库),输入数据库的地址、端口号、需要查询数据的数据库、用户名、密码。
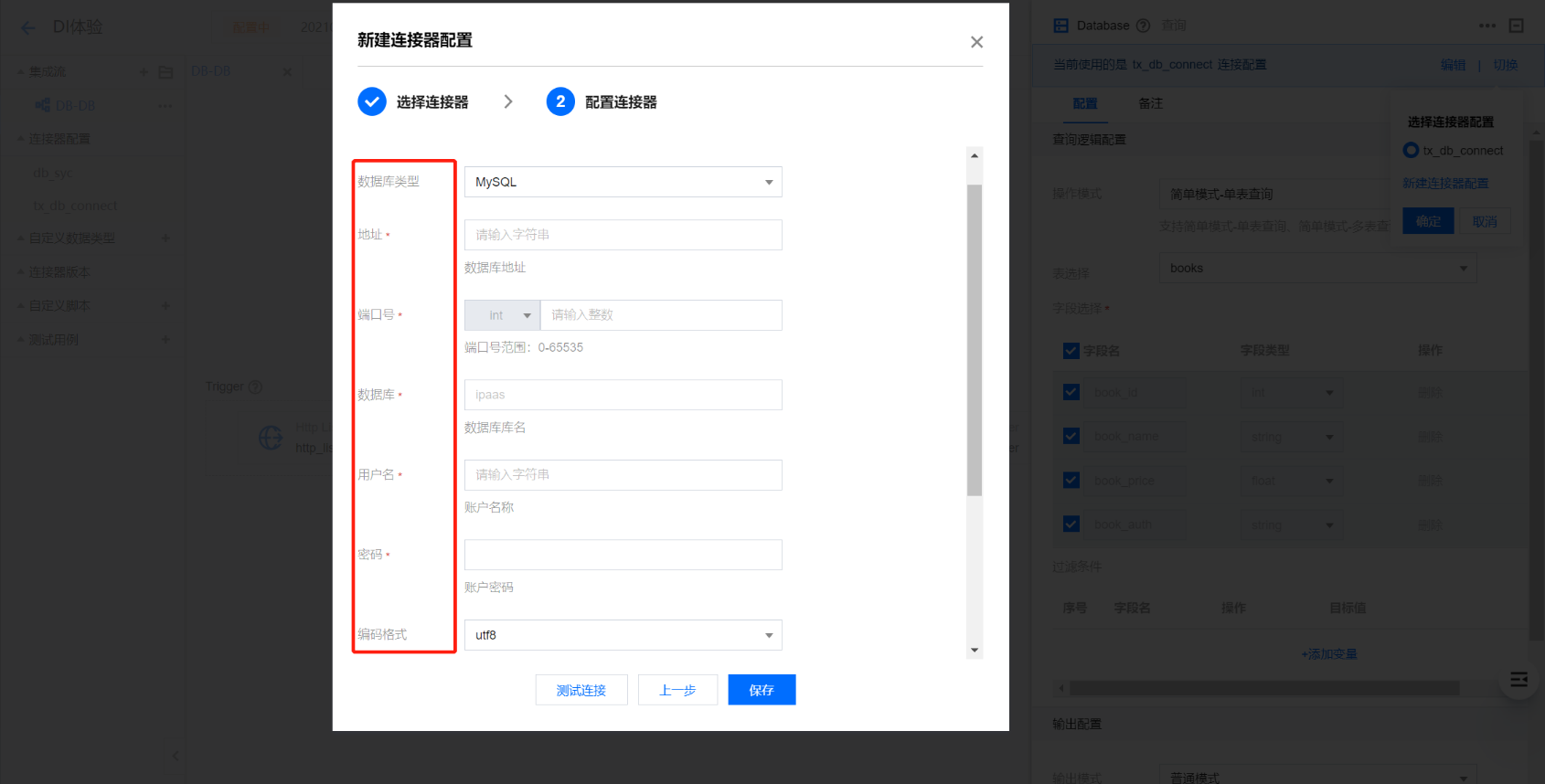
2.3 配置查询操作:操作模式分为简单模式-单表查询、简单模式-多表查询、SQL 模式。
选择单表查询后,Database 将读出指定连接数据库的所有表,可选择需要同步的数据源表。
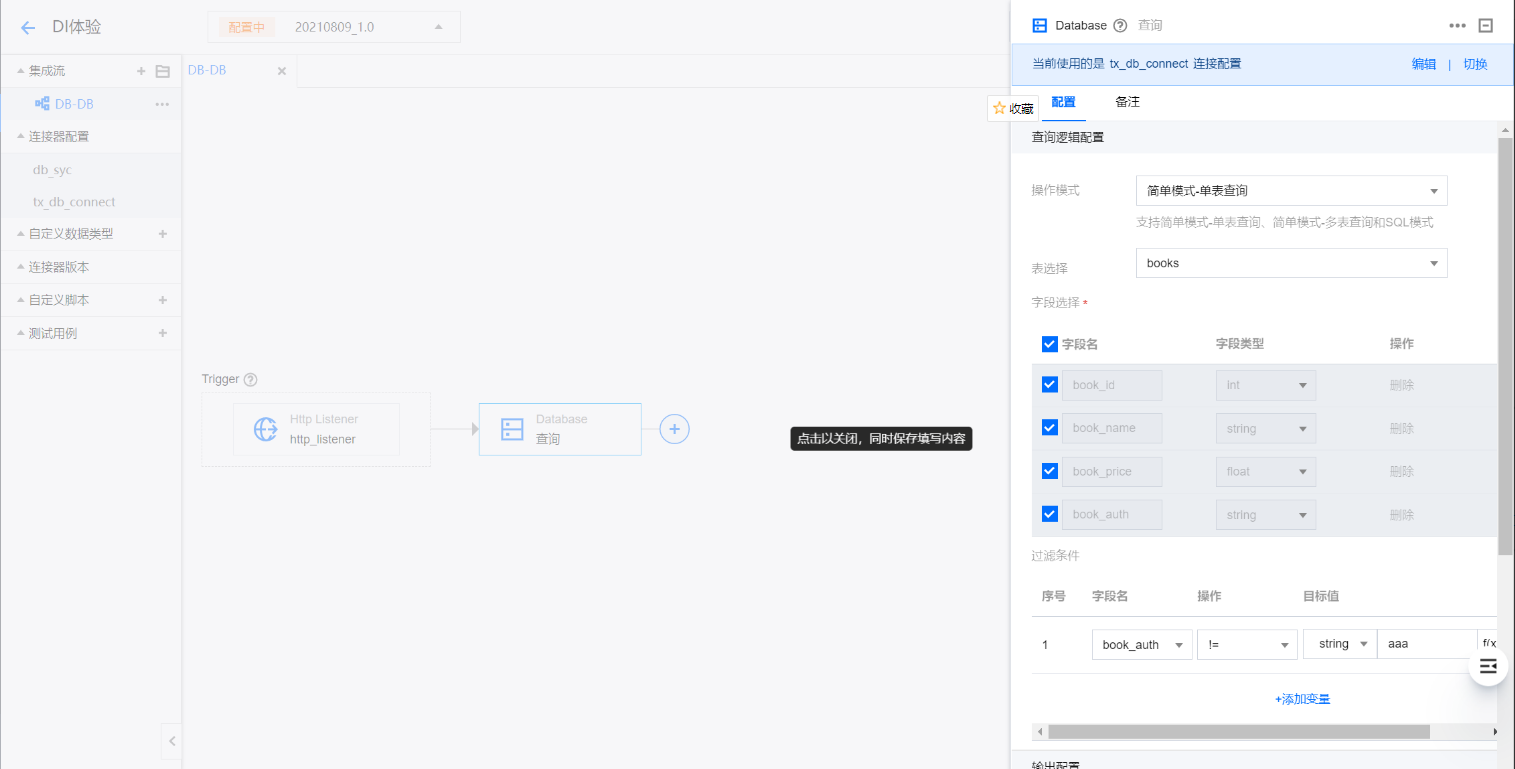
单表查询操作说明
1. 选择简单模式-单表查询。
2. 选择表。
3. 选择查询的字段。
4. 如果有需要,可配置查询条件,否则可跳过。
5. 输出配置中,输出模式选择 RecordSet 模式、是否缓存选择 false、分区数量默认为1。
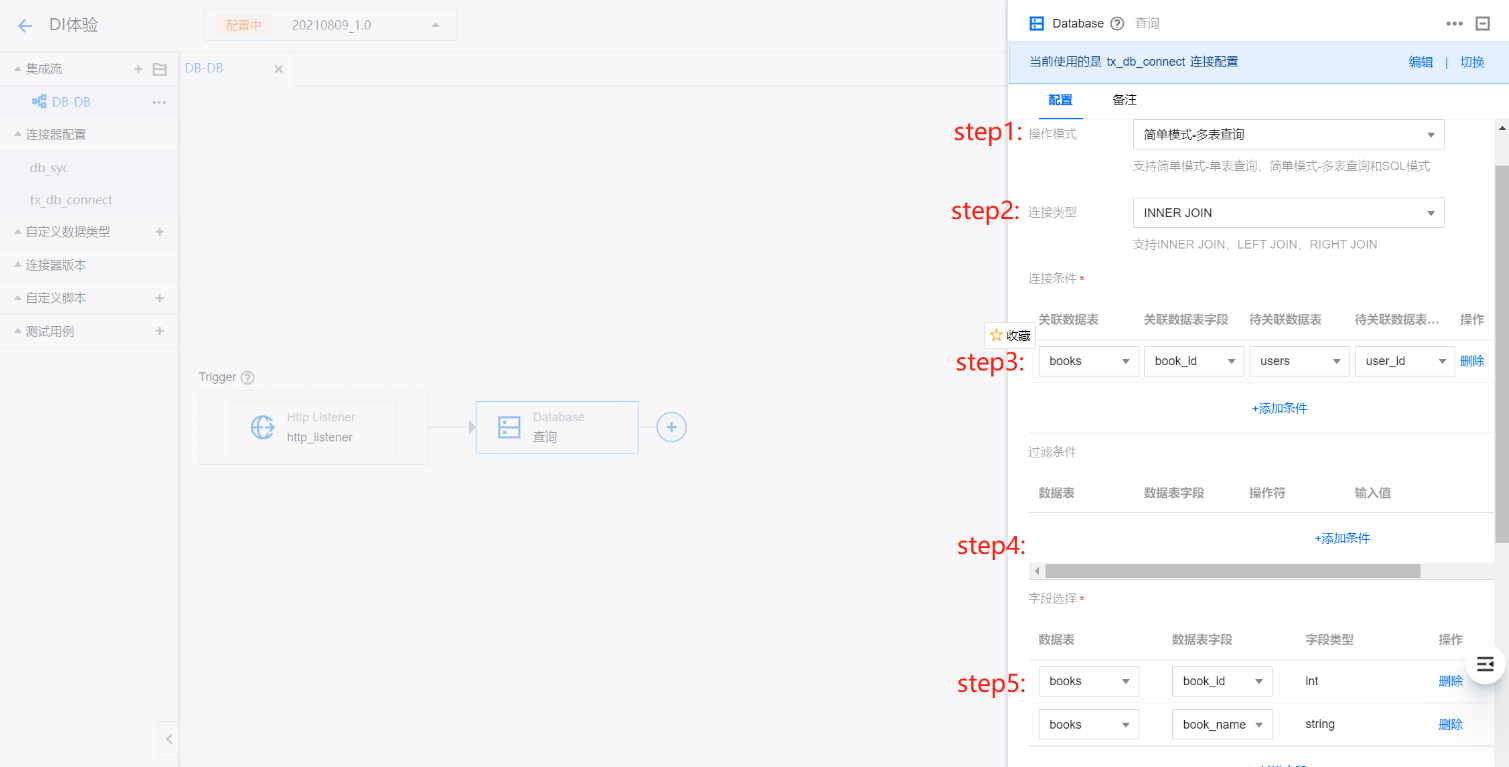
选择多表查询后,将通过 INNER JOIN、LEFT JOIN、RIGHT JOIN 多表联查获取数据。
多表查询操作说明
1. 选择简单模式-多表查询。
2. 选择多表关联的连接类型。
3. 设置关联条件。
4. 如果有需要,可配置查询条件,否则可跳过。
5. 设置查询的字段。
6. 输出配置中,输出模式选择 RecordSet 模式、是否缓存选择 false、分区数量默认为1。
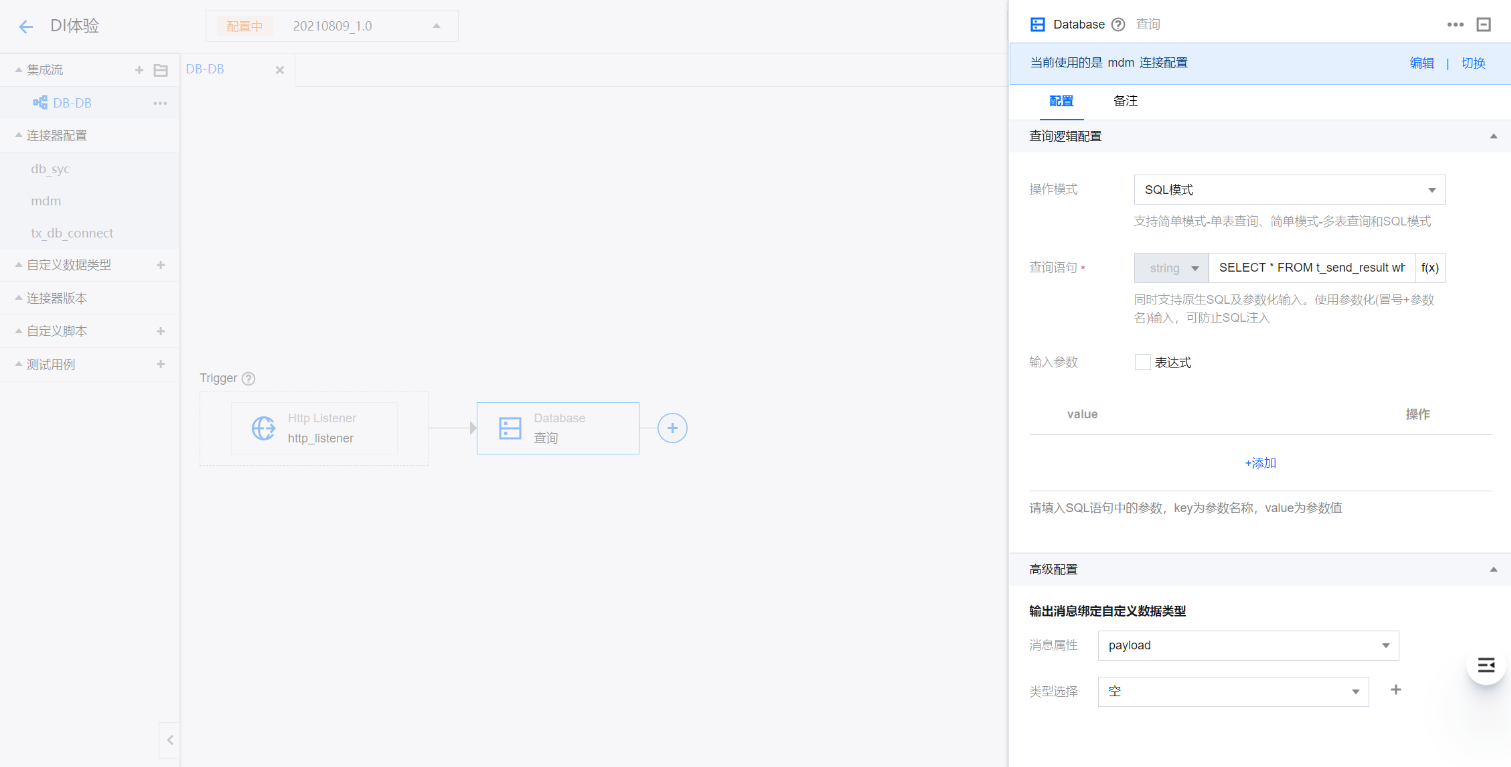
选择 SQL 模式后,可在查询语句中根据查询数据的需求来编写 SQL,可多表联合查询数据,也可在 SQL 语句中编写查询条件。
SQL 模式操作说明
1. 选择 SQL 模式。
2. 输入查询数据的 SQL 语句。
3. 维护 SQL 的参数。
3. 配置目标数据库。配置数据加载的目标数据库,设置将抽取的数据加载到那张表中。
3.1 在设计器画布中,来源 Database 后,单击 +,在选择组件面板中搜索 Database 连接器并在下一步操作面板中选择批量插入或批量合并。
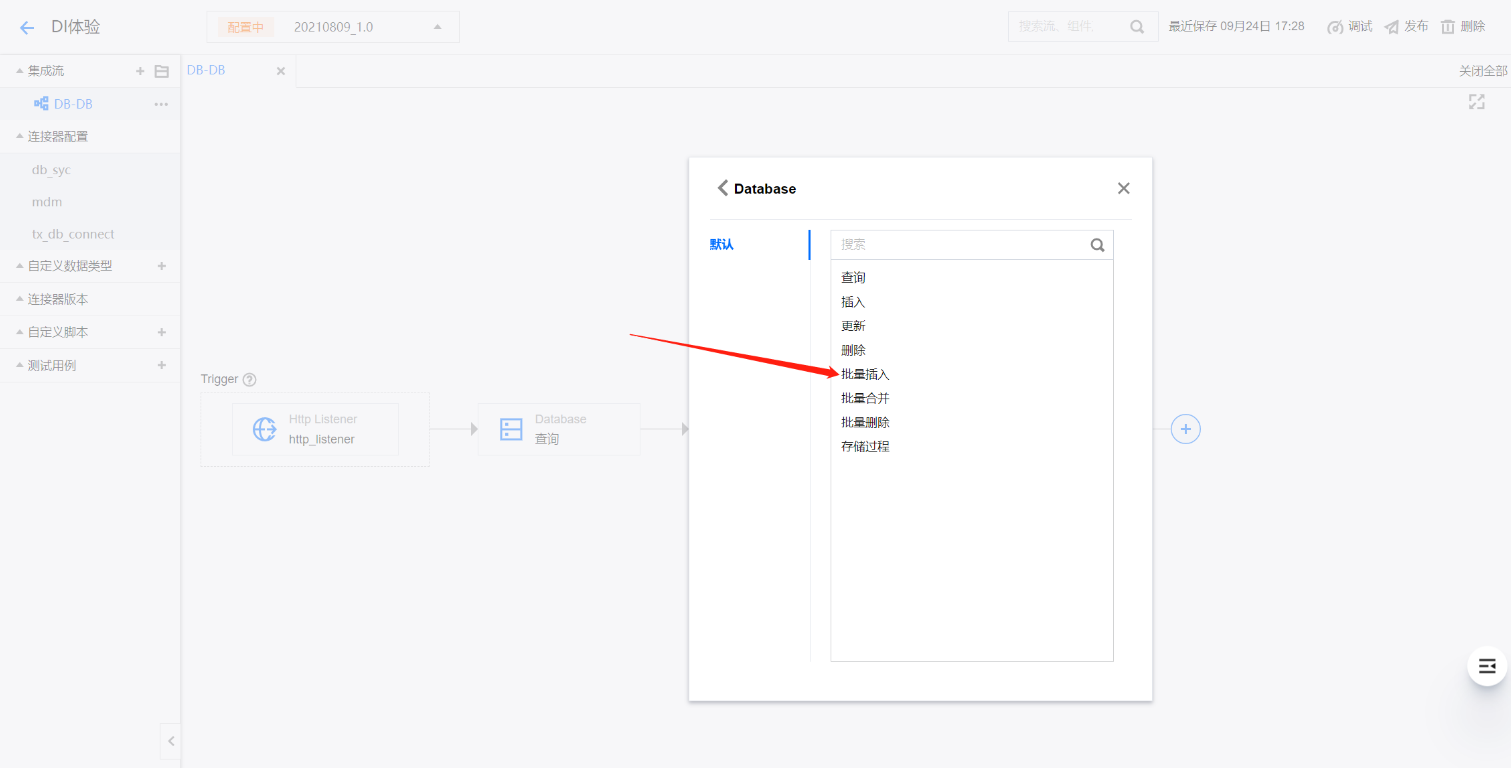
3.2 在 Database 批量插入面板中配置,具体配置步骤如下:
3.2.1 配置目标数据库的连接。
3.2.2 设置数据集,前一组件输出模式如果是 RecordSet,则此处为 return msg.payload。
3.2.3 选择目标数据库的表,将数据加载到此表。
3.2.4 设置抽取数据的字段与目标表字段的映射,未映射字段的数据将被抛弃。
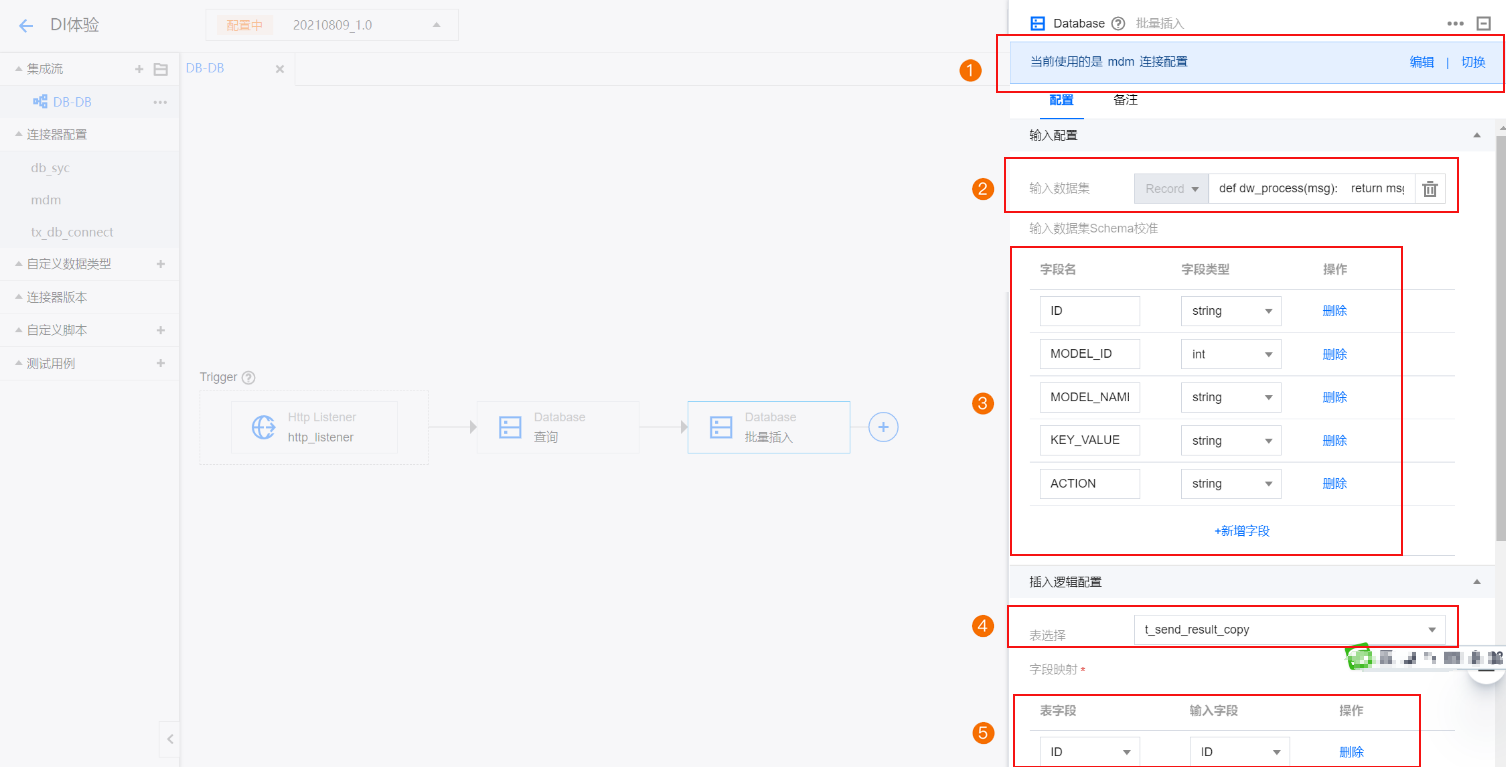
3.2.5 单击调度运行,即可体验效果。
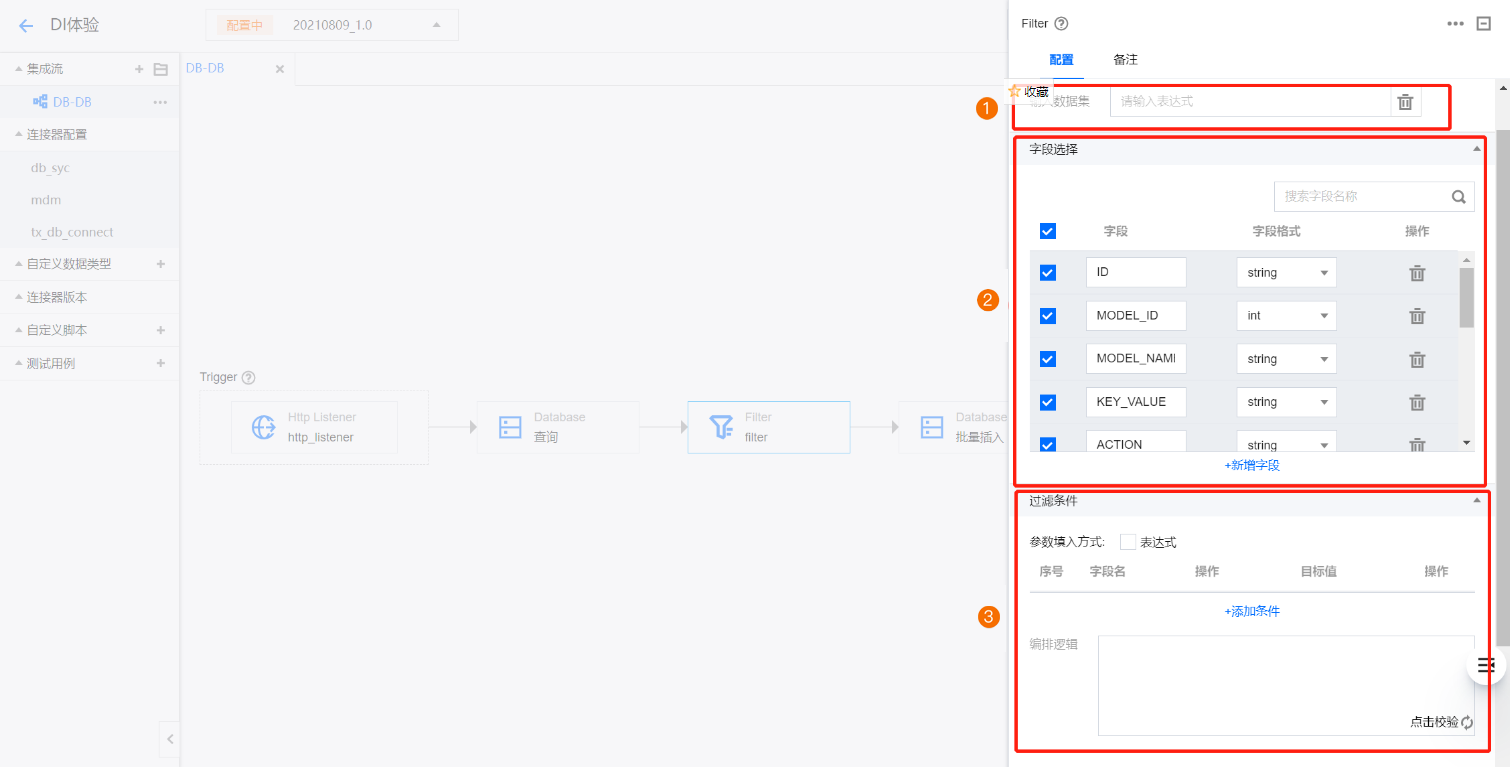
4. 数据过滤。如果需要对从数据源中抽取的数据进行再次过滤时,可在来源 Database 后插入 Filter 组件来配置对抽取的数据进行过滤处理。Filter 组件配置面板主要分为三部分:
4.1 输入的需要过滤的数据集成,数据集为 RecordSet 类型,不需要处理,默认为 msg.payload,可跳过此步。
4.2 配置过滤后输出的字段,如不需要某此字段的数据,可不勾取,组件将过滤此数据顶。
4.3 配置过滤条件,第二步是列的过滤,过滤条件则是行的过滤,通过字段及 ==,!=,>=,<=,>,<,StartWith,EndWith,Contain,In,NotIn,IsNull,IsNotNull 来过滤数据,如过滤掉取消状态的订单。
5. 数据映射。来源表、对象与目标表、对象在结构上往往不是简单的一一对应的关系,此时可根据抽取的字段数据与加载字段的对应关系来进行数据映射和转换。
5.1 在来源和目标连接器中间插入 Mapper 组件,配置来源对象字段与目标对象字段的映射转换逻辑。
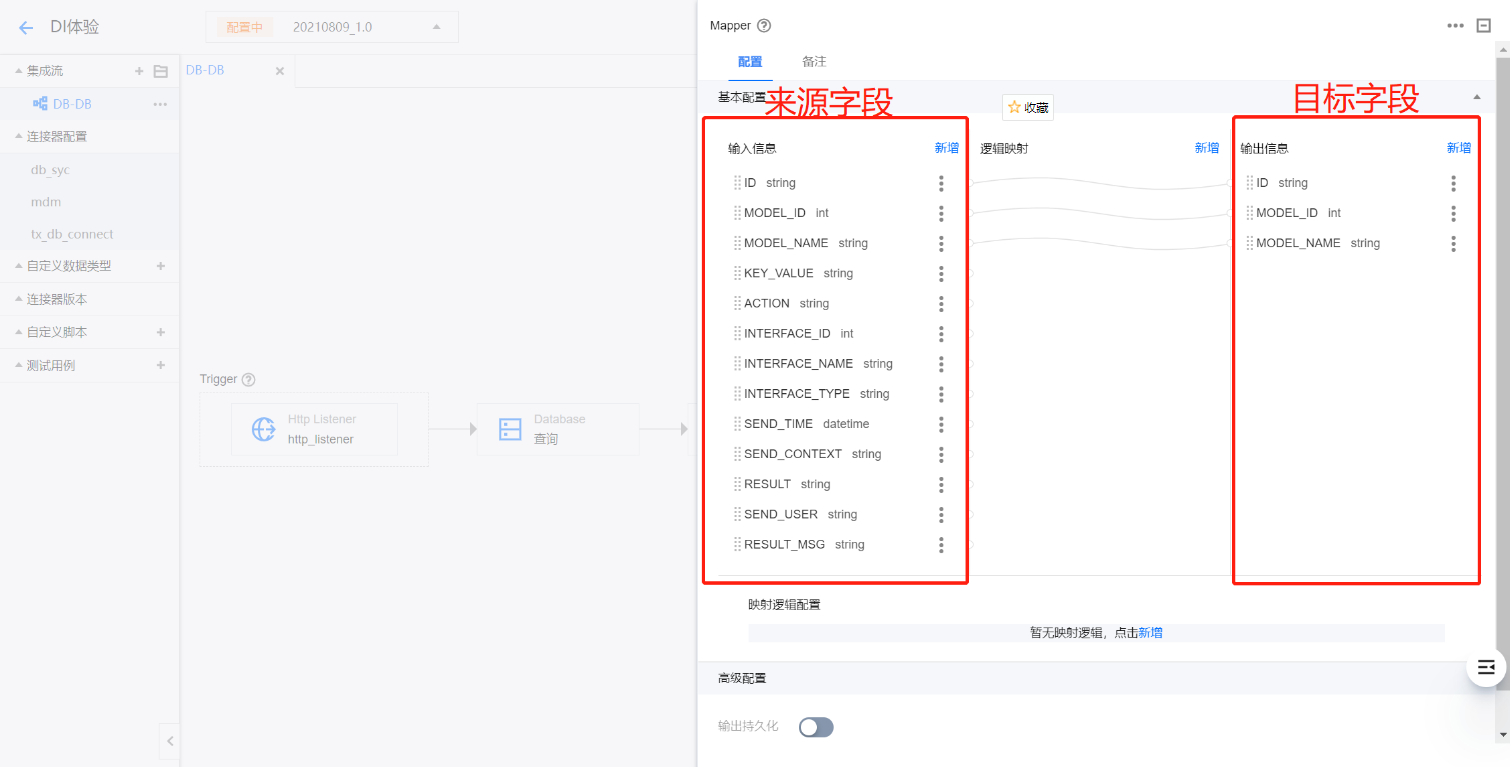
5.2 通过图形化拖拽输入信息(来源字段)与输出信息(目标字段)建立映射关系,当需要对来源数据进行加工时,可在逻辑映射区针对某字段新增加工处理的逻辑。



