简介
RDMA(Remote Direct Memory Access,远程直接内存访问)是一种高速网络互联技术,该技术旨在减少在数据传输过程中收发端的处理延迟以及资源消耗。RDMA 技术使计算机能够直接访问远程计算机的内存,在内存层面进行数据传输而无需 CPU 频繁介入,从而显著增强网络通信性能。
使用 RDMA,能够提高网络吞吐,降低网络时延,从而有效提升大规模 AI 推理和训练任务的性能。本文档介绍在 TKE 上如何使用 RDMA 网络方案加速各类 AI 工作负载。
适用场景
TKE RDMA 方案适用于以下 AI 场景:
分布式训练:多节点协同训练大规模模型,通过 RDMA 加速梯度同步和参数更新,显著缩短训练时间。
多机推理:跨节点部署大模型推理服务,利用 RDMA 实现低延迟的跨节点通信,提升推理吞吐。
分布式 KVCache:在多节点间共享 KV Cache,通过 RDMA 实现高速缓存访问,优化大模型推理性能。
Prefill/Decode 分离:将 Prefill 和 Decode 阶段分离到不同节点,通过 RDMA 高效传输中间状态,提升资源利用率。
方案特点
TKE RDMA 方案具有以下优势(本文基于独占 RDMA 模式):
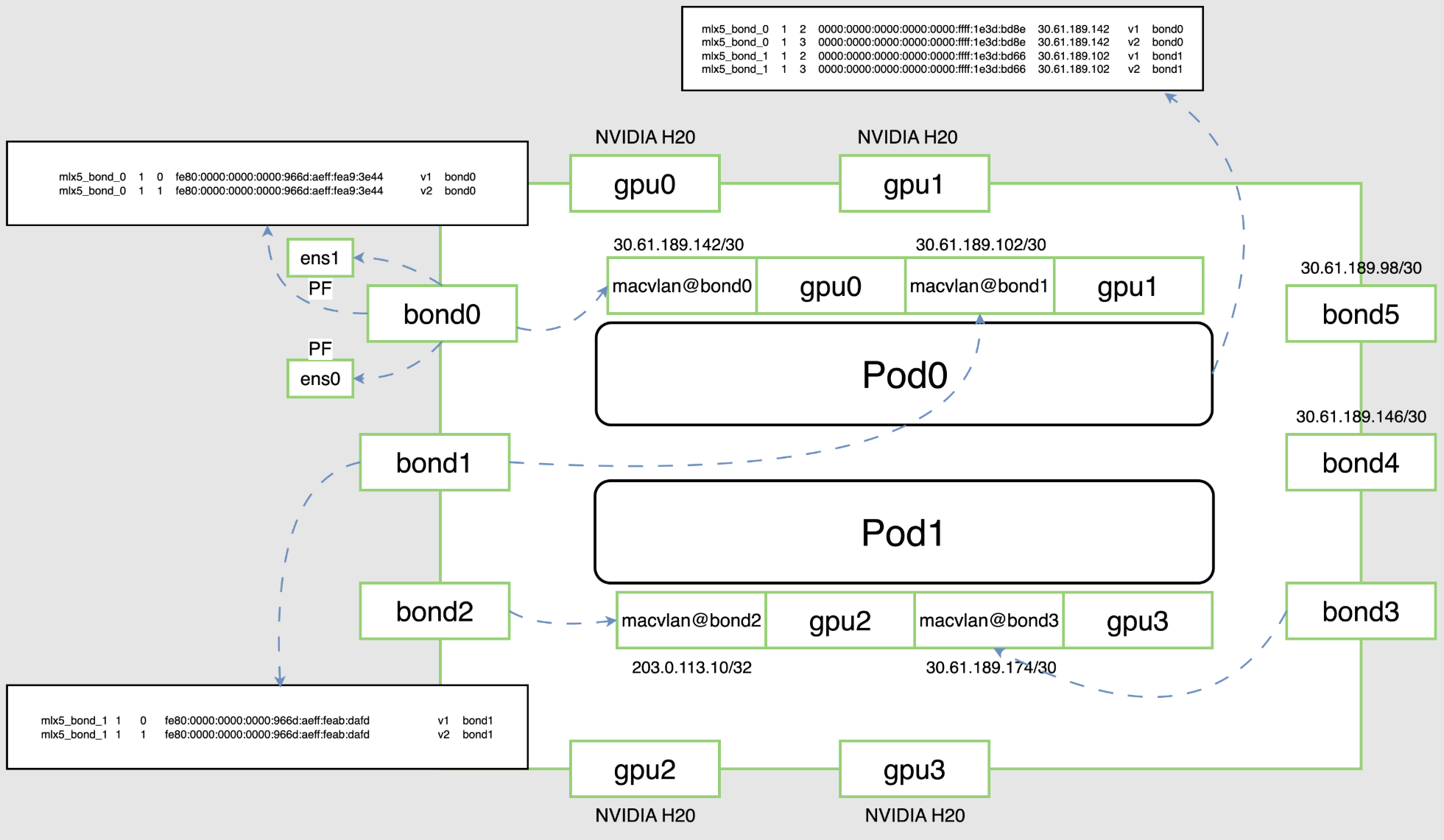
统一 GID Index:用户不用在 Pod 内引入额外的脚本动态获取 GID,简化分布式推理/训练时 NCCL 通信的配置。
优化用户体验:用户可直接通过原生节点加入 HCC 集群,在 TKE 使用 RDMA + GPU 进行训练/推理。
NUMA 亲和调度:实现 GPU 和 RDMA 设备的 NUMA 亲和分配,减少跨 NUMA 访问,提升性能。(不保证 PCIE-Switch 亲和)
环境准备
集群要求
已创建并部署好 TKE 集群。如果您还没有集群,请参见 创建集群。
已购买 RDMA 实例,RDMA netns 为 shared 模式。
Kubelet 启用 Topology Manager(推荐配置
topologyManagerPolicy: best-effort),以实现 NUMA 亲和调度。安装 rdma-agent 组件
安装步骤:
1. 登录容器服务控制台,选择左侧导航栏中的集群。
2. 在集群列表页面,单击目标集群 ID,进入集群详情页。
3. 选择左侧组件管理,单击新建。
4. 在组件列表中选择 rdma-agent,单击完成。
创建节点池
1. 在 容器服务控制台 的集群详情页中,选择节点管理 > 节点池,单击新建原生节点,新建 HCC 集群。
2. 在高级设置中,新增或修改节点池中节点的 label,默认需添加
feature.node.kubernetes.io/tke-shared-rdma=true: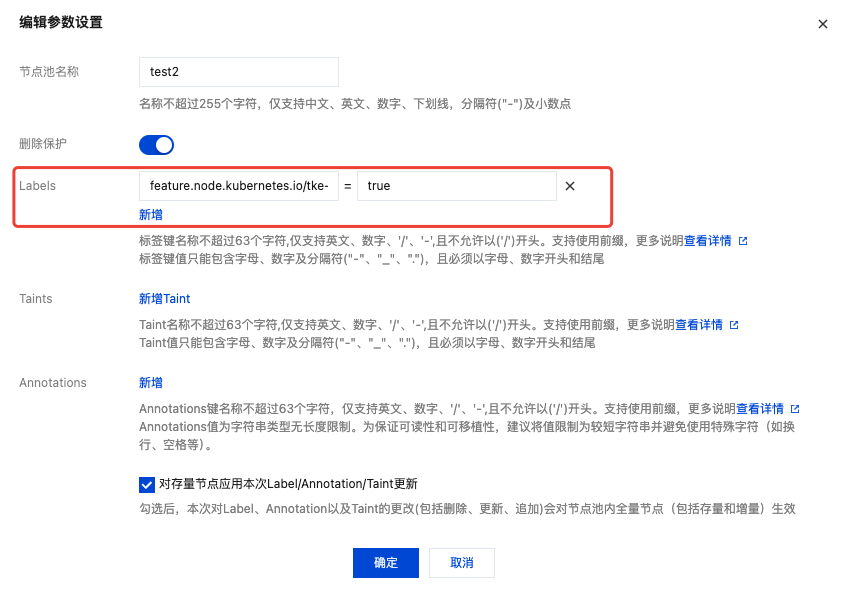
3. 在高级设置中,Management 中添加 Kubelet 的 topology-manager-policy 为 best-effort:

4. 添加、修改后,也可勾选“对存量节点应用本次 Label/Annotation/Taint 更新”,从而应用到存量节点。
5. 存量节点也可通过以下命令给节点添加 label,从而部署 rdma-agent 组件:
# <nodeName> 替换成存量节点的名称,通过 kubectl get node 可查询kubectl label node <nodeName> feature.node.kubernetes.io/tke-shared-rdma=true
组件参数配置说明
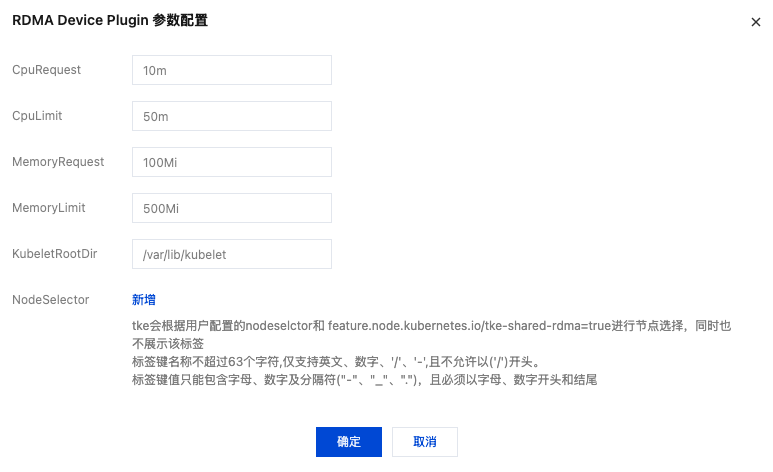
参数配置项 | 描述 |
CpuRequest | 组件在每个节点上运行时需要占用的 CPU,默认为 10m。 |
CpuLimit | 组件在每个节点上运行时最大占用的 CPU,默认为 50m。 |
MemoryRequest | 组件在每个节点上运行时需要占用的内存,默认为 100Mi。 |
MemoryLimit | 组件在每个节点上运行时最大占用的内存,默认为 500Mi。 |
KubeletRootDir | 组件运行所在节点的 kubelet 的根目录,默认为 /var/lib/kubelet,根目录修改时需同步修改组件的这个配置。 |
NodeSelector | 组件所需运行节点的 label 键值对,默认配置是 feature.node.kubernetes.io/tke-shared-rdma=true,若需自定义部署的节点 label,则需要修改这个配置。 |
环境验证
验证组件状态
组件部署后,等待安装成功,确保
tke-rdma-shared-agent 皆为 Running:kubectl -n kube-system get po -o wide -l k8s-app=tke-rdma-shared-agent
验证 RDMA 资源
检查 RDMA 节点 Capacity 和 Allocatable 资源,确保其中的
tke.cloud.tencent.com/tke-shared-rdma 不为 0:kubectl describe node <nodeName> | grep tke-shared-rdma
预期输出示例(显示实际的 bond 设备数量):
tke.cloud.tencent.com/tke-shared-rdma: 8
说明:
新版本会上报真实的 bond 设备数量(通常为 8 个)。
这使得 Kubernetes 调度器能够准确判断节点资源容量,避免资源超分配。
提交 RDMA 任务
YAML 关键配置
网络配置
指定 CNI,RDMA 网络平面和 VPC 网络平面是两个网络平面,为了使 Pod 能够同时连接 VPC 网络和 RDMA 网络,需要在工作负载的 Pod template 中指定以下 annotation 配置:
GlobalRouter(全局路由)网络模式集群:
annotations:tke.cloud.tencent.com/networks: "tke-bridge,tke-rdma-macvlan"
VPC-CNI 共享网卡模式集群:
annotations:tke.cloud.tencent.com/networks: "tke-route-eni,tke-rdma-macvlan"
集群的网络模式可以通过集群里的 cni-agent 配置来确定:
kubectl -n kube-system get cm tke-cni-agent-conf -o yaml | grep defaultDelegates
安全上下文配置
指定 securityContext 使能进程间通信:
securityContext:capabilities:add: ["IPC_LOCK"]
资源请求配置
设置 RDMA 和 GPU resource 资源请求:
resources:limits:nvidia.com/gpu: "8"tke.cloud.tencent.com/tke-shared-rdma: "8"
说明:
nvidia.com/gpu: 请求的 GPU 数量。tke.cloud.tencent.com/tke-shared-rdma: 请求的 RDMA 设备数量,推荐与 GPU 数量相等。共享内存配置
为了支持 NCCL 共享数据,需要为 IPC 和固定(页面锁定)系统内存资源共享系统内存:
测试验证
TKE RDMA 方案提供了两种测试方式:
1. RDMA 基础功能测试:部署测试 Pod,验证 RDMA 设备和网络连通性。
2. NCCL 通信测试:部署测试 Pod,验证 NCCL 在 RDMA 网络上的通信性能。
测试一:RDMA 基础功能测试
部署测试 Pod
部署 RDMA 基础功能测试 StatefulSet。
YAML 配置:
apiVersion: apps/v1kind: StatefulSetmetadata:labels:k8s-app: ibv-appname: ibv-appnamespace: defaultspec:replicas: 4selector:matchLabels:k8s-app: ibv-appqcloud-app: ibv-appserviceName: ""template:metadata:annotations:tke.cloud.tencent.com/networks: "tke-route-eni,tke-rdma-macvlan"creationTimestamp: nulllabels:k8s-app: ibv-appqcloud-app: ibv-appspec:containers:- command:- sh- -c- |ls -l /dev/infiniband /sys/class/infiniband /sys/class/netsleep 1000000image: ccr.ccs.tencentyun.com/tke-eni-test/mofed-5.4-3.1.0.0:ubuntu20.04-amd64-testimagePullPolicy: Alwaysname: ibv-app-ctrsecurityContext:capabilities:add: ["IPC_LOCK"]resources:limits:nvidia.com/gpu: "4"tke.cloud.tencent.com/tke-shared-rdma: "4"volumeMounts:- mountPath: /dev/shmname: dshmvolumes:- emptyDir:medium: MemorysizeLimit: 64Giname: dshm
将以上 YAML 保存为文件(例如
rdma-test.yaml),然后部署:kubectl apply -f rdma-test.yaml
等待 Pod 启动完成:
kubectl get pods -l k8s-app=ibv-app
登录测试 Pod
kubectl exec -it ibv-app-0 -- bash
验证 RDMA 设备
使用
ibv_devinfo 命令确认 RDMA 设备功能正常:# ibv_devinfohca_id: mlx5_bond_0transport: InfiniBand (0)fw_ver: 22.33.1048node_guid: 946d:ae03:00a9:3ed0sys_image_guid: 946d:ae03:00a9:3ed0vendor_id: 0x02c9vendor_part_id: 4125hw_ver: 0x0board_id: MT_0000000359phys_port_cnt: 1port: 1state: PORT_ACTIVE (4)max_mtu: 4096 (5)active_mtu: 4096 (5)sm_lid: 0port_lid: 0port_lmc: 0x00link_layer: Ethernet
使用
show_gids 命令获取 gid,在 TKE RDMA 方案下,GID index 统一为 Host GID Index:# show_gidsDEV PORT INDEX GID IPv4 VER DEV--- ---- ----- --- ------------ --- ---mlx5_bond_0 1 0 fe80:0000:0000:0000:401d:55ff:fe14:6ce8 v1 bond0mlx5_bond_0 1 1 fe80:0000:0000:0000:401d:55ff:fe14:6ce8 v2 bond0mlx5_bond_0 1 2 0000:0000:0000:0000:0000:ffff:1e3d:b4ac 30.61.180.172 v1 bond0mlx5_bond_0 1 3 0000:0000:0000:0000:0000:ffff:1e3d:b4ac 30.61.180.172 v2 bond0
RDMA 性能测试
以下测试需要在两个 Pod 之间进行,一个作为 Server 端,一个作为 Client 端。
连通性测试(ibv_rc_pingpong)
使用
ibv_rc_pingpong 命令测试 RDMA 连通性:Server 端配置(在 ibv-app-0 上执行):
# ibv_rc_pingpong -d mlx5_bond_0 -g 3local address: LID 0x0000, QPN 0x003a22, PSN 0xc882ae, GID ::ffff:30.61.130.20remote address: LID 0x0000, QPN 0x001234, PSN 0x58320b, GID ::ffff:30.61.180.1728192000 bytes in 0.01 seconds = 7687.51 Mbit/sec1000 iters in 0.01 seconds = 8.52 usec/iter
Client 端配置(在 ibv-app-1 上执行):
在 TKE RDMA 方案下,GID index 统一为 Host GID Index。
# ibv_rc_pingpong -d mlx5_bond_0 -g 3 30.61.130.20local address: LID 0x0000, QPN 0x001234, PSN 0x58320b, GID ::ffff:30.61.180.172remote address: LID 0x0000, QPN 0x003a22, PSN 0xc882ae, GID ::ffff:30.61.130.208192000 bytes in 0.01 seconds = 7924.55 Mbit/sec1000 iters in 0.01 seconds = 8.27 usec/iter
写带宽测试(ib_write_bw)
使用
ib_write_bw 命令测试 RDMA 写带宽:Server 端配置(在 ibv-app-0 上执行):
# ib_write_bw -d mlx5_bond_0 -x 3************************************* Waiting for client to connect... *************************************---------------------------------------------------------------------------------------RDMA_Write BW TestDual-port : OFF Device : mlx5_bond_0Number of qps : 1 Transport type : IBConnection type : RC Using SRQ : OFFCQ Moderation : 100Mtu : 4096[B]Link type : EthernetGID index : 3Max inline data : 0[B]rdma_cm QPs : OFFData ex. method : Ethernet---------------------------------------------------------------------------------------local address: LID 0000 QPN 0x3a25 PSN 0x8877cd RKey 0x00ca88 VAddr 0x007fb84630d000GID: 00:00:00:00:00:00:00:00:00:00:255:255:30:61:130:20remote address: LID 0000 QPN 0x1235 PSN 0xe2acbc RKey 0x007c3e VAddr 0x007f8f164b7000GID: 00:00:00:00:00:00:00:00:00:00:255:255:30:61:180:172---------------------------------------------------------------------------------------#bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps]65536 5000 97.50 97.49 0.185950---------------------------------------------------------------------------------------
Client 端配置(在 ibv-app-1 上执行):
# ib_write_bw -d mlx5_bond_0 -x 3 30.61.130.20 --report_gbits---------------------------------------------------------------------------------------RDMA_Write BW TestDual-port : OFF Device : mlx5_bond_0Number of qps : 1 Transport type : IBConnection type : RC Using SRQ : OFFTX depth : 128CQ Moderation : 100Mtu : 4096[B]Link type : EthernetGID index : 3Max inline data : 0[B]rdma_cm QPs : OFFData ex. method : Ethernet---------------------------------------------------------------------------------------local address: LID 0000 QPN 0x1235 PSN 0xe2acbc RKey 0x007c3e VAddr 0x007f8f164b7000GID: 00:00:00:00:00:00:00:00:00:00:255:255:30:61:180:172remote address: LID 0000 QPN 0x3a25 PSN 0x8877cd RKey 0x00ca88 VAddr 0x007fb84630d000GID: 00:00:00:00:00:00:00:00:00:00:255:255:30:61:130:20---------------------------------------------------------------------------------------#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]65536 5000 97.50 97.49 0.185950---------------------------------------------------------------------------------------
写延迟测试(ib_write_lat)
测试 RDMA 写操作的延迟:
Server 端:
ib_write_lat -d mlx5_bond_0 -x 3
Client 端:
ib_write_lat -d mlx5_bond_0 -x 3 <server-ip>
发送带宽测试(ib_send_bw)
测试 RDMA 发送操作的带宽:
Server 端:
ib_send_bw -d mlx5_bond_0 -x 3
Client 端:
ib_send_bw -d mlx5_bond_0 -x 3 <server-ip> --report_gbits
发送延迟测试(ib_send_lat)
测试 RDMA 发送操作的延迟:
Server 端:
ib_send_lat -d mlx5_bond_0 -x 3
Client 端:
ib_send_lat -d mlx5_bond_0 -x 3 <server-ip>
读带宽测试(ib_read_bw)
测试 RDMA 读操作的带宽:
Server 端:
ib_read_bw -d mlx5_bond_0 -x 3
Client 端:
ib_read_bw -d mlx5_bond_0 -x 3 <server-ip> --report_gbits
读延迟测试(ib_read_lat)
测试 RDMA 读操作的延迟:
Server 端:
ib_read_lat -d mlx5_bond_0 -x 3
Client 端:
ib_read_lat -d mlx5_bond_0 -x 3 <server-ip>
测试二:NCCL 通信测试
NCCL 测试用于验证 NCCL 库在 RDMA 网络上的通信性能,适用于分布式训练场景。
部署 NCCL 测试 Pod
部署 NCCL 通信测试 StatefulSet。
YAML 配置:
apiVersion: apps/v1kind: StatefulSetmetadata:labels:k8s-app: nccl-testname: nccl-testnamespace: defaultspec:replicas: 2selector:matchLabels:k8s-app: nccl-testqcloud-app: nccl-testserviceName: ""template:metadata:annotations:tke.cloud.tencent.com/networks: "tke-route-eni,tke-rdma-macvlan"creationTimestamp: nulllabels:k8s-app: nccl-testqcloud-app: nccl-testspec:containers:- command:- sh- -c- |ls -l /dev/infiniband /sys/class/infiniband /sys/class/netsleep 1000000image: ccr.ccs.tencentyun.com/qcloud-ti-platform/nccl_ofed:cu12.0imagePullPolicy: IfNotPresentname: nccl-testsecurityContext:capabilities:add: ["IPC_LOCK"]resources:limits:nvidia.com/gpu: "8"tke.cloud.tencent.com/tke-shared-rdma: "8"volumeMounts:- mountPath: /dev/shmname: dshmvolumes:- emptyDir:medium: MemorysizeLimit: 64Giname: dshm
将以上 YAML 保存为文件(例如
nccl-test.yaml),然后部署:kubectl apply -f nccl-test.yaml
等待 Pod 启动完成:
kubectl get pods -l k8s-app=nccl-test
配置 SSH 免密登录
mpirun 需要通过 ssh 登录到其他节点执行相关命令,所以需要配置免密登录。
在 nccl-test-0 上执行:
# 生成密钥ssh-keygen# 查看公钥cat ~/.ssh/id_rsa.pub
在 nccl-test-1 上执行:
# 创建 sshd 运行目录mkdir -p /run/sshd# 启动 sshd/usr/sbin/sshd# 创建 .ssh 目录mkdir -p ~/.ssh# 将 nccl-test-0 的公钥添加到 authorized_keys# <id_rsa.pub> 为 nccl-test-0 Pod 里 /root/.ssh/id_rsa.pub 的文件内容echo "<id_rsa.pub>" >> ~/.ssh/authorized_keys
测试免密登录:
在 nccl-test-0 上测试是否可以免密登录 nccl-test-1。假设 nccl-test-0 的 IP 为 172.21.4.8,nccl-test-1 的 IP 为 172.21.5.6:
# 在 nccl-test-0 上执行ssh root@172.21.5.6
如果能够无需密码直接登录,说明配置成功。
启动 NCCL 测试任务
在 nccl-test-0 上执行
mpirun 可启动 NCCL all_reduce_perf 测试任务:mpirun --allow-run-as-root -np 16 \\-npernode 8 -H 172.21.4.8:8,172.21.5.6:8 \\-mca btl_tcp_if_include bond0 \\-x NCCL_IB_DISABLE=0 \\-x NCCL_IB_GID_INDEX=3 \\-x NCCL_DEBUG=INFO \\/root/nccltest/all_reduce_perf -b 1G -e 1G -f 2 -g 1 -n 20
参数说明:
mpirun 参数:
--allow-run-as-root:允许以 root 用户运行。-np 16: 总进程数(2 个节点 × 8 个 GPU)。-npernode 8:每个节点的进程数。-H 172.21.4.8:8,172.21.5.6:8:指定主机和每个主机的进程数。MPI 环境变量:
btl_tcp_if_include:指定 OpenMPI 运行时通信使用的网卡。由于网络环境同时有多个网段(每个 RDMA 独属一个网段,eth0 一个网段),所以需要指定只使用 bond0 或者 eth0 进行通信。若该变量不设置会出现报错:Open MPI failed to TCP connect to a peer MPI process.NCCL 环境变量:
NCCL_IB_DISABLE:0 代表 NCCL 使用 IB/RoCE 传输,1 代表禁止 NCCL 使用 IB/RoCE 传输。此时 NCCL 将退回到使用 IP 套接字。NCCL_IB_GID_INDEX:指定 RoCE 模式中使用的全局 ID 索引。获取方法请参考本文中的 验证 RDMA 设备 部分。注意:只有在 NCCL 2.21 版本以前需要设置这个变量,而在 2.21 版本及以后,该值会被动态设置,不需要设置。详情请参见 NCCL 库官网文档。NCCL_DEBUG:NCCL_DEBUG 变量控制从 NCCL 显示的调试信息。NCCL 测试参数:
-b 1G:起始数据大小为 1GB。-e 1G:结束数据大小为 1GB。-f 2:数据大小增长因子。-g 1:每个进程使用的 GPU 数量。-n 20:迭代次数。测试结果
以上测试任务成功之后的回显结果类似为:
## out-of-place in-place# size count type redop root time algbw busbw #wrong time algbw busbw #wrong# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)1073741824 268435456 float sum -1 6455.8 166.32 311.85 0 6426.3 167.09 313.29 0# Out of bounds values : 0 OK# Avg bus bandwidth : 312.571#
结果说明:
size:数据大小(字节)。time:操作耗时(微秒)。algbw:算法带宽(GB/s)。busbw:总线带宽(GB/s)。Avg bus bandwidth:平均总线带宽,这是衡量 RDMA 性能的关键指标。如果看到类似上述输出,且
busbw 达到较高值(通常 > 300 GB/s),说明 RDMA 网络配置成功,可以用于分布式训练任务。使用限制
TKE RDMA 方案在 Pod 启动时会将分配的 bond 网卡 IP 从节点上摘除并分配给 Pod 使用,因此存在以下使用限制:
HostNetwork 模式限制
不建议在同一节点上混用 HostNetwork 模式和 RDMA Pod。
原因:RDMA Pod 启动时会摘除节点上的 bond IP,可能影响 HostNetwork Pod 的网络连通性。
建议:将 RDMA 工作负载和 HostNetwork 工作负载部署到不同的节点上。
资源容量限制
由于新版本上报真实的 bond 设备数量(通常为 8 个),节点的资源容量是有限的:
如果节点有 8 个 bond 设备,最多可以运行 1 个请求 8 个 RDMA 资源的 Pod。
或者最多可以运行 2 个请求 4 个 RDMA 资源的 Pod。
当资源不足时,Pod 会处于 Pending 状态,等待资源释放。
GID Index 使用说明
TKE RDMA 方案的一个重要优势是 GID Index 统一。在 TKE RDMA 方案下,所有 Pod 的 GID Index 都是固定的,可根据节点的 GID Index 获取,用户无需在 Pod 内引入额外的脚本动态获取 GID,简化了分布式训练和推理的配置。
关于 NCCL_IB_GID_INDEX 环境变量:
在 NCCL 2.21 版本以前,需要手动设置
NCCL_IB_GID_INDEX=3 环境变量。在 NCCL 2.21 版本及以后,该值会被动态设置,不需要手动设置。



