本文基于 speech-translate-demo 项目,采用 Go + WebSocket + 原生前端,封装腾讯云「同声传译」能力,提供麦克风实时流 / 本地音频文件两种输入方式,内建悬浮字幕与会议级 UI。
操作背景
业务场景
同声传译(Simultaneous Interpretation,SI)广泛应用于 跨国会议、跨境直播、海外客服、在线教育、出海带货 等场景。与"录完再翻"的离线翻译不同,SI 要求在演讲者开口后的 1–3 秒内 就给出译文,并随着演讲持续逐字、逐句增量更新。
本 Demo 能力矩阵
多输入源:浏览器麦克风实时流 / 本地 WAV/PCM 文件
语向覆盖(遵循官方接口限制):
源语言:
zh(中文)、en(英文)、zh_en(中英混)目标语言:
zh(中文)、en(英文)、zh_en(中英混)双翻译模型:
hunyuan-translation-lite(低时延,默认)/ hunyuan-translation(高质量)快速体验
环境依赖
Go 1.21+
浏览器(Chrome 、 Edge 、 Safari)
腾讯云账号 → 开通「语音识别 - 实时语音翻译」
音频规格(接口硬约束):16kHz 采样率、16bit 位深、单声道 PCM/WAV。
编辑配置文件
先拷贝一份配置文件:
cp config.json.example config.json
编辑配置文件
config.json:{"port": 8080,"appid": "您的AppID","secret_id": "您的SecretID","secret_key": "您的SecretKey"}
启动项目
运行以下命令后,打开浏览器访问 http://localhost:8080 即可使用
cd speech-translate-demogo mod tidygo run .
使用翻译功能
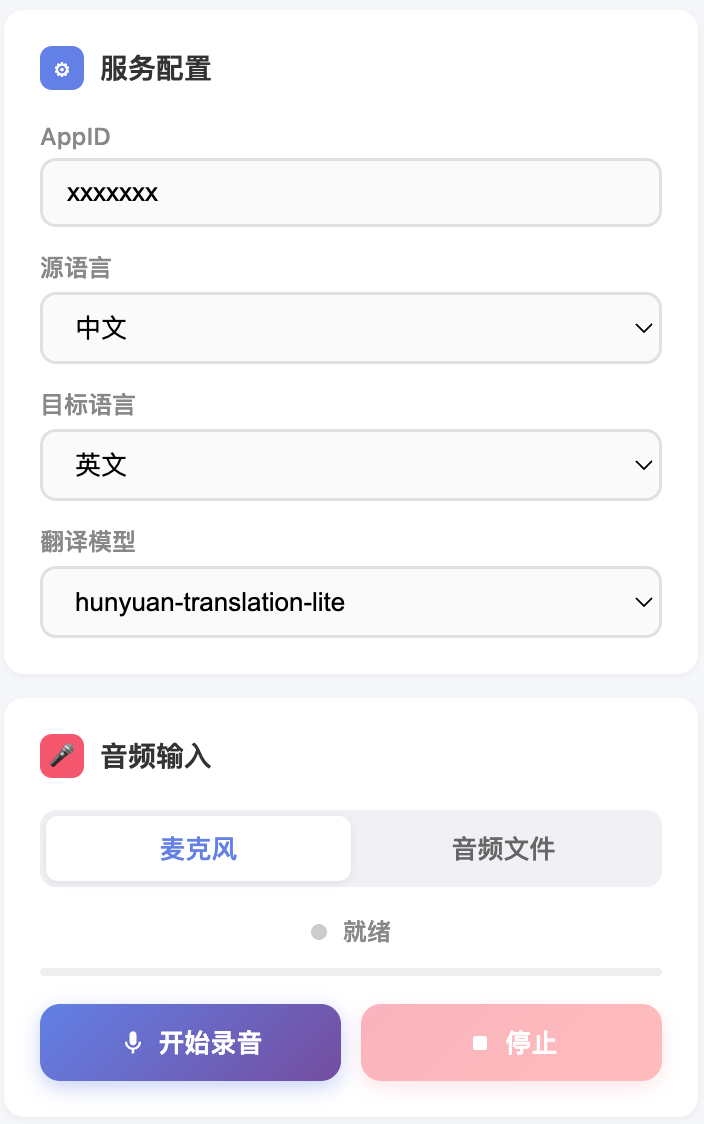
麦克风模式:选择源/目标语言 > 单击开始录音 > 授权麦克风 > 字幕实时出现。
文件模式:切换到音频文件 > 拖拽 WAV/PCM > 开始翻译。
悬浮字幕:单击悬浮字幕按钮,可拖拽到屏幕任意位置,适合叠加到直播/会议画面上。
项目整体架构
三层架构

目录结构
speech-translate-demo/├── main.go # 入口:加载配置 + 路由注册├── handler.go # WebSocket 业务层 & 音频处理├── sdk/│ └── speechtranslate.go # 自研 SDK:签名、协议、事件├── static/│ ├── index.html # 单页 UI│ ├── app.js # 麦克风采集 + WS 通信 + 字幕渲染│ └── style.css # 会议风样式├── config.json # 密钥配置(需自行创建)└── go.mod
数据流时序
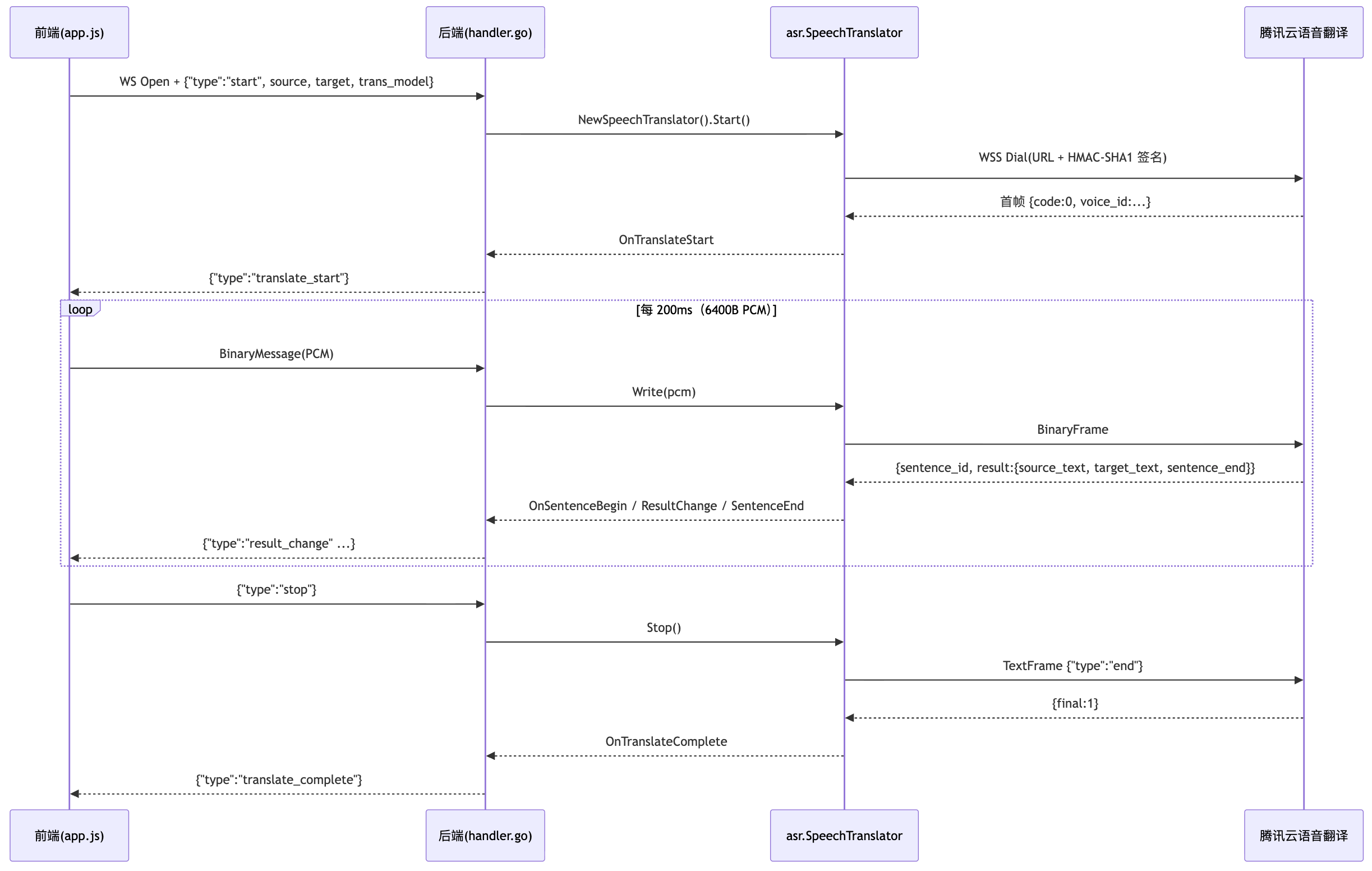
接入与实现
代码示例
credential := common.NewCredential(secretID, secretKey)listener := &MyListener{} // 实现 SpeechTranslateListener 接口translator := asr.NewSpeechTranslator(appID, credential,"zh", // 源语言"en", // 目标语言"hunyuan-translation-lite", // 翻译模型listener,)translator.VoiceFormat = 1 // PCM 格式translator.Start() // 建立连接translator.Write(pcmChunk) // 持续写入音频translator.Stop() // 结束翻译
实现
SpeechTranslateListener 接口即可接收全部事件:type SpeechTranslateListener interface {OnTranslateStart(*SpeechTranslateResponse)OnSentenceBegin(*SpeechTranslateResponse)OnTranslateResultChange(*SpeechTranslateResponse)OnSentenceEnd(*SpeechTranslateResponse)OnTranslateComplete(*SpeechTranslateResponse)OnFail(*SpeechTranslateResponse, error)}
注意:
OnSentenceBegin 和 OnSentenceEnd 可能在同一帧触发(短句场景)。当 sentence_id 变化且 sentence_end=true 时,SDK 会先发 Begin 再发 End。官方响应结构
每次回调收到的数据结构如下:
{"code": 0,"message": "success","voice_id": "xxx-uuid","sentence_id": "1","result": {"source": "zh","target": "en","source_text": "今天天气怎么样","target_text": "How is the weather today","start_time": 0,"end_time": 1800,"sentence_end": true},"final": 0}
字段 | 类型 | 说明 |
code | int | 0=成功;非 0 见错误码表 |
message | string | 错误描述 |
voice_id | string | 会话唯一 ID(排查必备) |
sentence_id | string | 当前句子 ID,同一句内不变 |
result.source_text | string | 识别到的源文(到目前为止完整内容,非增量) |
result.target_text | string | 译文(到目前为止完整内容,非增量) |
result.start_time/end_time | uint32 | 当前句相对会话开始的 ms 时间戳 |
result.sentence_end | bool | 当前句是否已终态 |
final | uint32 | 1=整个会话结束 |
两个关键标志
响应里有两个容易混淆的“结束”标志,粒度完全不同:
标志 | 粒度 | 含义 |
result.sentence_end=true | 句子级 | 当前句结束,还会有下一句 |
final=1(顶层) | 会话级 | 整个翻译流程结束,连接即将关闭 |
一次完整翻译会话中,多个句子的事件流如下:
┌──────────────────────────────────────────────────────────────┐│ 会话开始 (translate_start, voice_id="abc-123") ││ ││ ┌─ 句子1 (sentence_id="1") ──────────────────────────┐ ││ │ sentence_begin → result_change × N → sentence_end │ ││ └─────────────────────────────────────────────────────┘ ││ ││ ┌─ 句子2 (sentence_id="2") ──────────────────────────┐ ││ │ sentence_begin → result_change × N → sentence_end │ ││ └─────────────────────────────────────────────────────┘ ││ ││ ... 更多句子 ... ││ ││ 会话结束 (translate_complete, final=1) │└──────────────────────────────────────────────────────────────┘
“全量覆盖”语义
注意:
source_text / target_text 每次都是该句到目前为止的完整内容,并非增量片段。前端直接覆盖即可,切勿拼接。以一个完整句子的事件流为例:
时间轴 (sentence_id="1"):t1 result_change source_text="你" target_text="You"t2 result_change source_text="你好" target_text="Hello"t3 result_change source_text="你好世界" target_text="Hello world"t4 sentence_end source_text="你好世界。" target_text="Hello, world."^^^^^^^^^^^ 每次都是完整内容,直接覆盖即可
前端事件分发与字幕合并
核心数据结构使用
sentence_id 作为 key 的 Map + 有序数组:let sentences = {}; // { [sentence_id]: { source, target, final } }let sentenceOrder = []; // 保证渲染顺序
前端通过
handleServerMessage 的 switch-case 逐事件分发处理:function handleServerMessage(msg) {switch (msg.type) {case 'translate_start':// 会话就绪,麦克风模式下开始采集音频setStatus('录音中...', 'recording');if (inputMode === 'mic') startAudioCapture();break;case 'sentence_begin':// 新句子:以 sentence_id 为 key 创建条目、入队const sid1 = msg.data.sentence_id;if (!sentences[sid1]) {sentences[sid1] = { source: '', target: '', final: false };sentenceOrder.push(sid1);}renderSentences();break;case 'result_change':// 中间结果:全量覆盖 source/target(不是增量拼接!)const sid2 = msg.data.sentence_id;if (!sentences[sid2]) {sentences[sid2] = { source: '', target: '', final: false };sentenceOrder.push(sid2);}sentences[sid2].source = msg.data.result.source_text || '';sentences[sid2].target = msg.data.result.target_text || '';renderSentences();break;case 'sentence_end':// 终态:最后一次覆盖 + 标记 finalconst sid3 = msg.data.sentence_id;sentences[sid3].source = msg.data.result.source_text || '';sentences[sid3].target = msg.data.result.target_text || '';sentences[sid3].final = true;renderSentences();break;case 'translate_complete':// 整个会话结束:释放麦克风、AudioContext、定时器setStatus('已完成', 'connected');stopAudioCapture();break;case 'error':// 错误兜底setStatus('出错了', '');stopAudioCapture();break;}}
附录
效果调优建议
音频质量直接影响翻译效果,为保证从音频中提取正确语义,建议您从以下维度来提升音频质量。
维度 | 建议 |
降噪 | 开启浏览器 noiseSuppression: true |
回声消除 | 开启 echoCancellation: true,避免扬声器回传 |
采样率 | 优先以 16kHz 原生采集,避免额外重采样损耗 |
物理环境 | 使用指向性麦克风、远离噪声源、距离 20–40cm |
参考资料
同声传译完整工程



