数据库管理-第387期 吐槽一下OCP部署(20251110)

数据库管理-第387期 吐槽一下OCP部署(20251110)

胖头鱼的鱼缸
发布于 2026-07-02 14:54:00
发布于 2026-07-02 14:54:00
数据库管理-第387期 吐槽一下OCP部署(20251110)

914fcc7ad57defa7868c3be1ca7fb4f5.jpg
上周不是通过OCP部署了一套4.4.1社区版集群么,装完后就发现运行OCP的主机,MetaDB的可用内存已经100%分配了,运行也卡得很,因此想着将OCP主机配置调整为6C24G 100G磁盘重新部署一下,然后出现了下面的问题。
1 问题复现
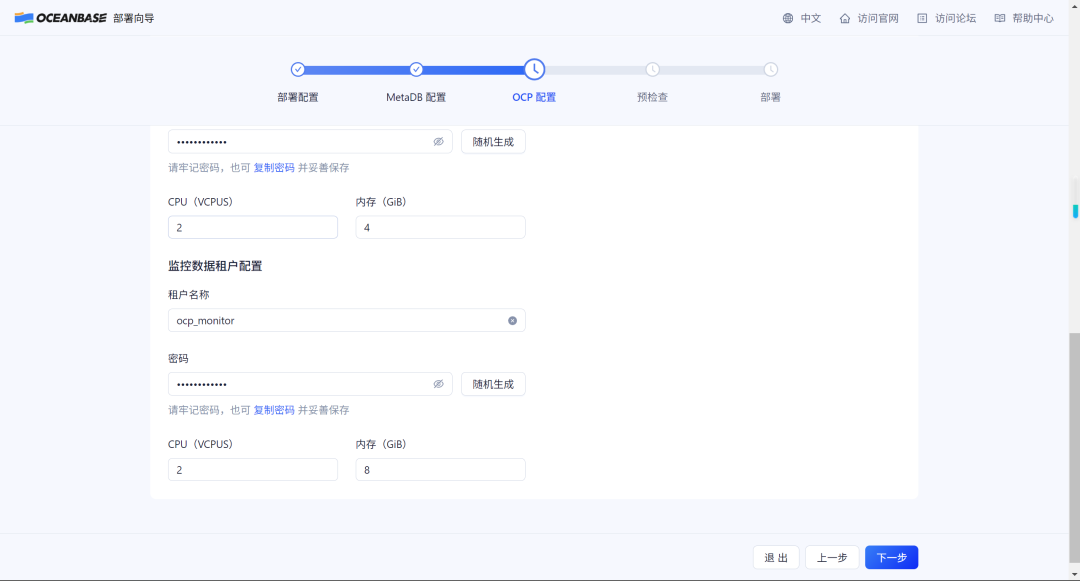
之前部署OCP的时候,在MetaDB配置租户ocp_monitor的时候,是将内存调整到了4G的(默认8G),如果按照默认方式配置则会在预检查时出现报错:
df4cace07d3a9a71418a0495532368a9.png
d598427d8010b4a6de6e7d851fcdd628.png
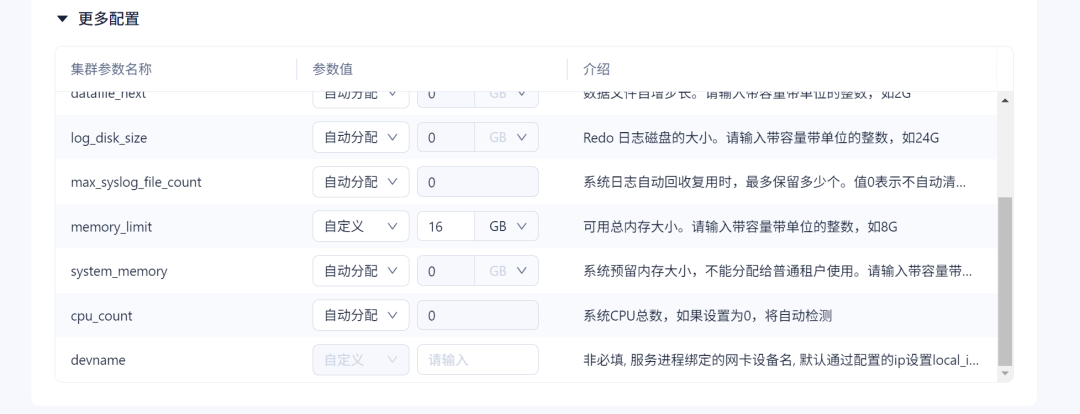
因此想着在MetaDB中将memory_limit调大。
663859c3fe85b90d58f3d57a419cc573.png
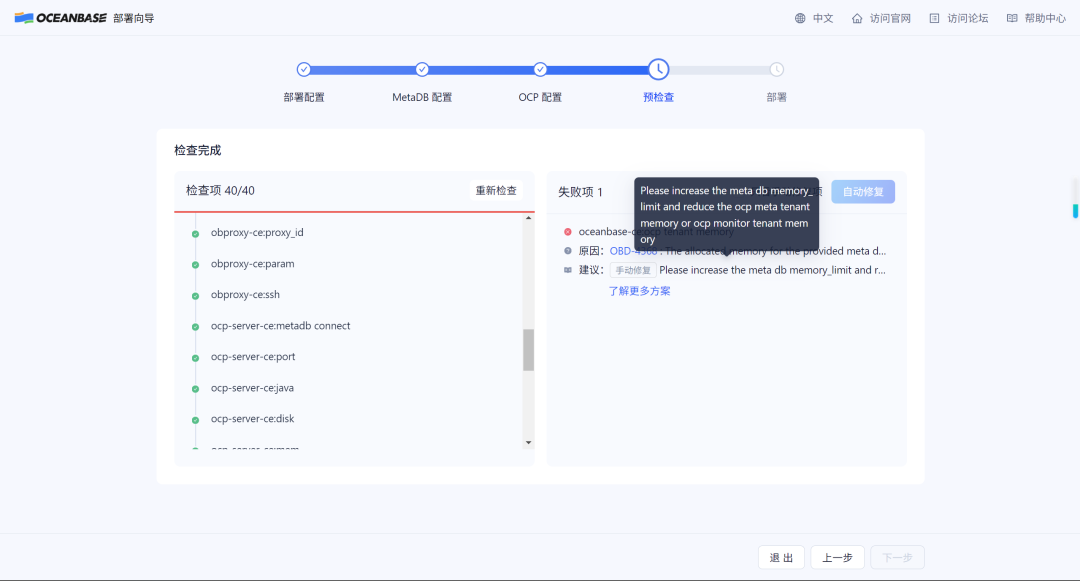
但是在实际部署中,在创建resource pool的时候仍然会报错。

0aff09e3a88a46ea33cba7147652c85b.png
检查日志和配置相关信息,即便是配置了新的memory_limit,实际部署过程中仍然会使用“自动分配”的大小,即小于租户ocp_meta默认4G+ocp_monitor默认8G,共12G÷0.8=15G的需求,不知这是一个我配置流程的问题,还是“自动分配”相关的BUG。
最后还是只能将ocp_monitor租户的内存配置调整成4G,完成安装。
2 调整内存
安装完成后MetaDB的内存分配依然是100%,我的目标仍然是将ocp_monitor的内存配置调整到默认的8G。
2.1 调整集群
首先需要将MetaBD本身的memory_limit调大:
image.png
image.png
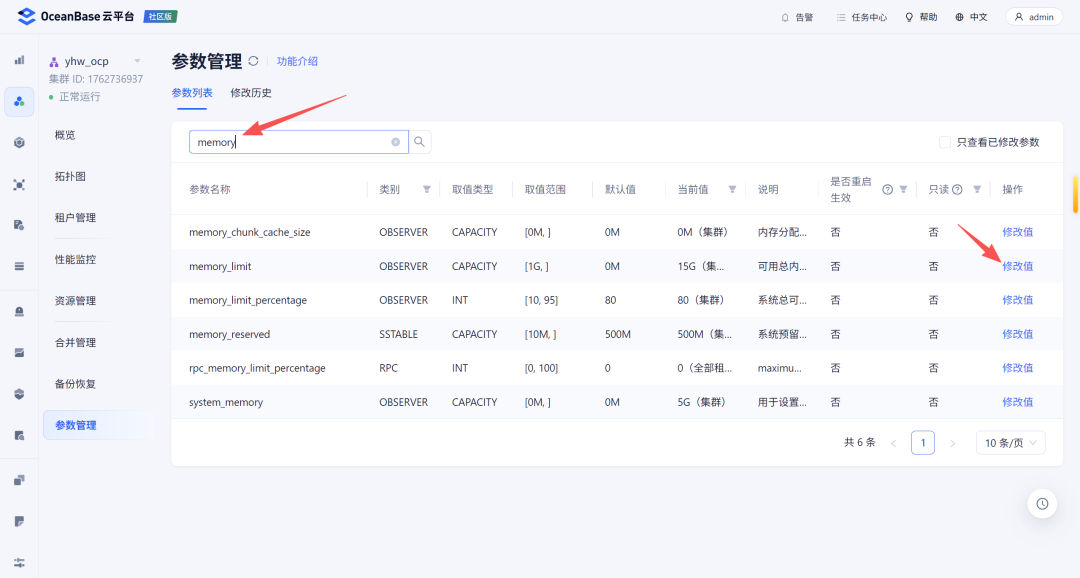
image.png
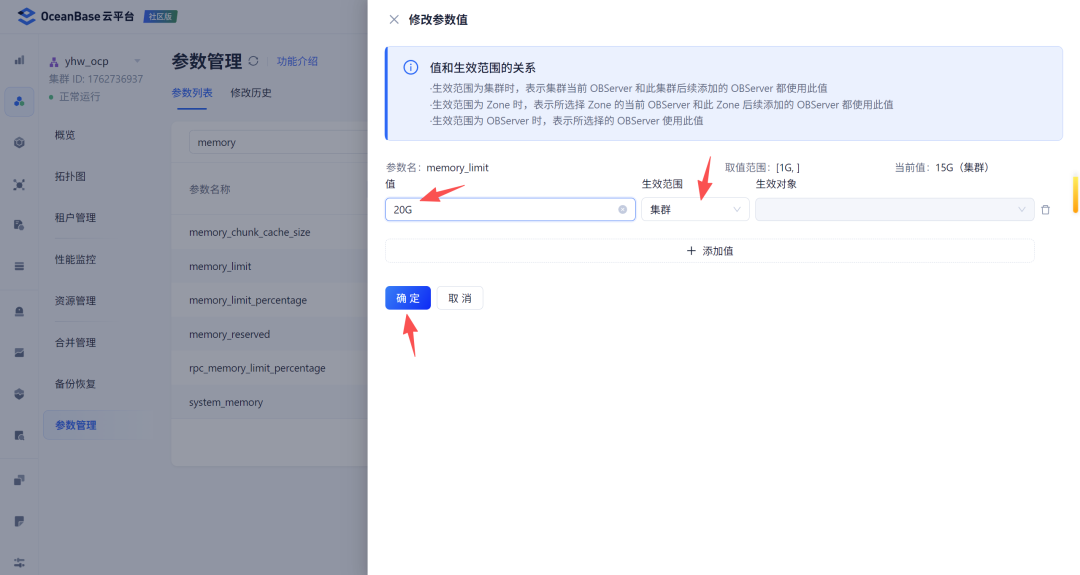
image.png
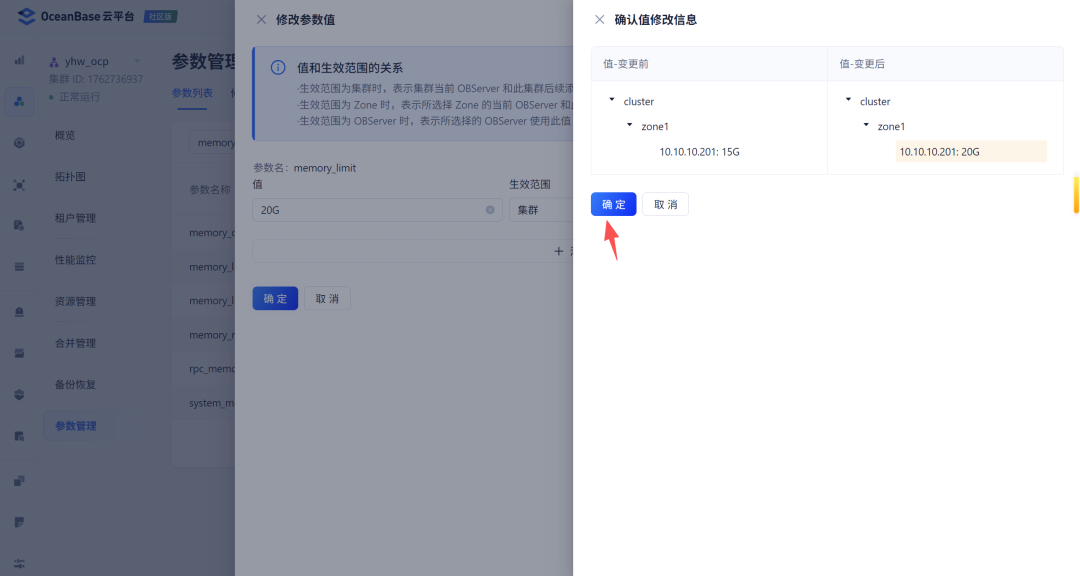
image.png
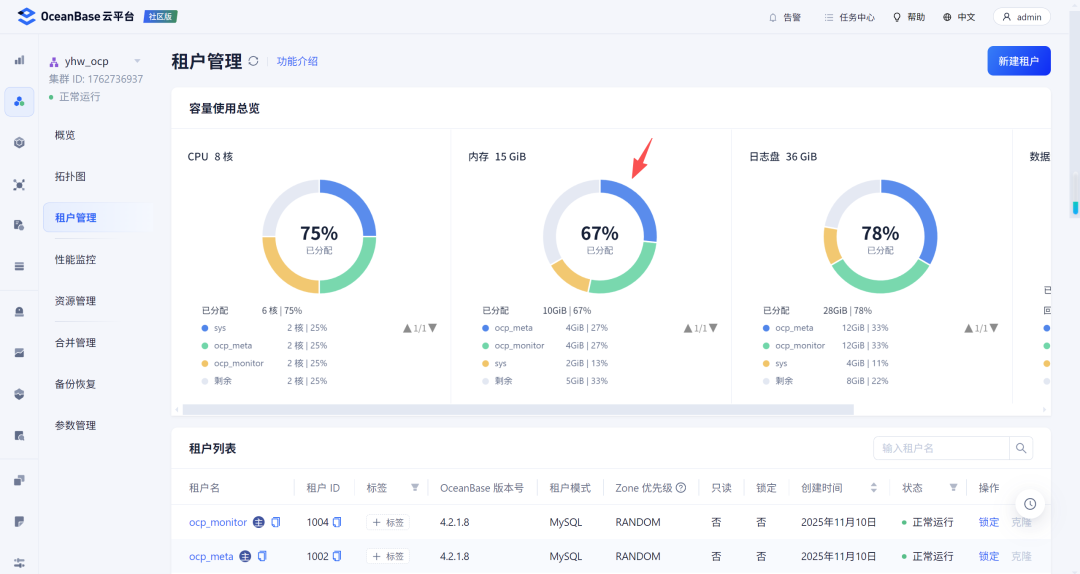
image.png
2.2 调整租户
然后调整ocp_monitor租户的内存配置:
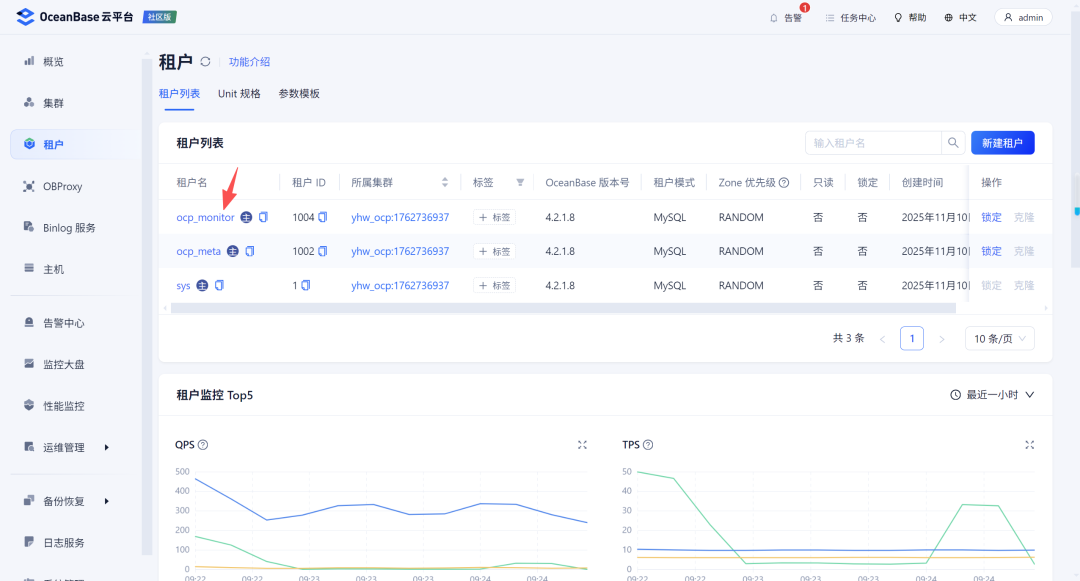
image.png
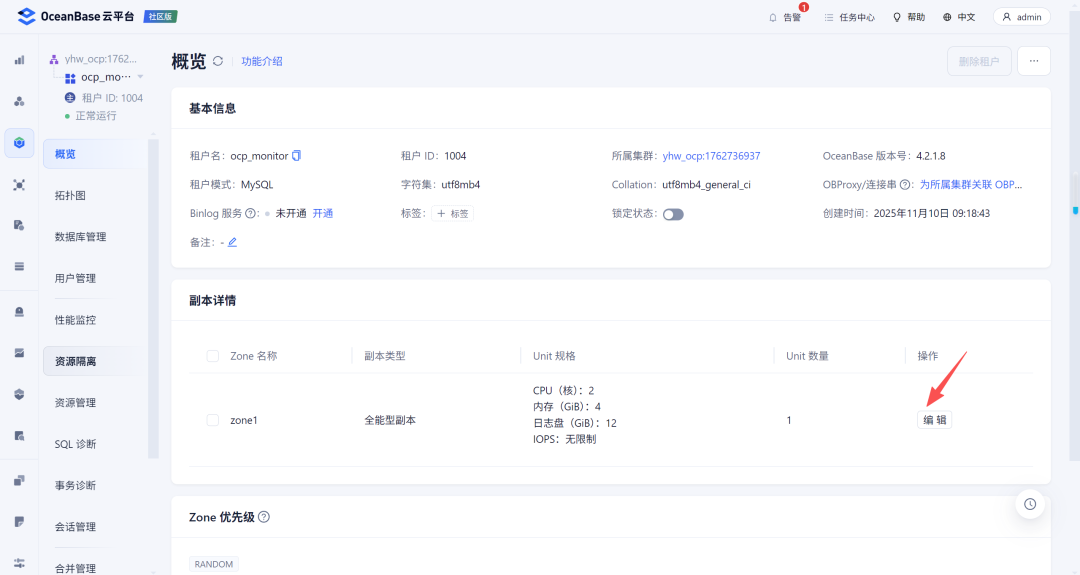
image.png
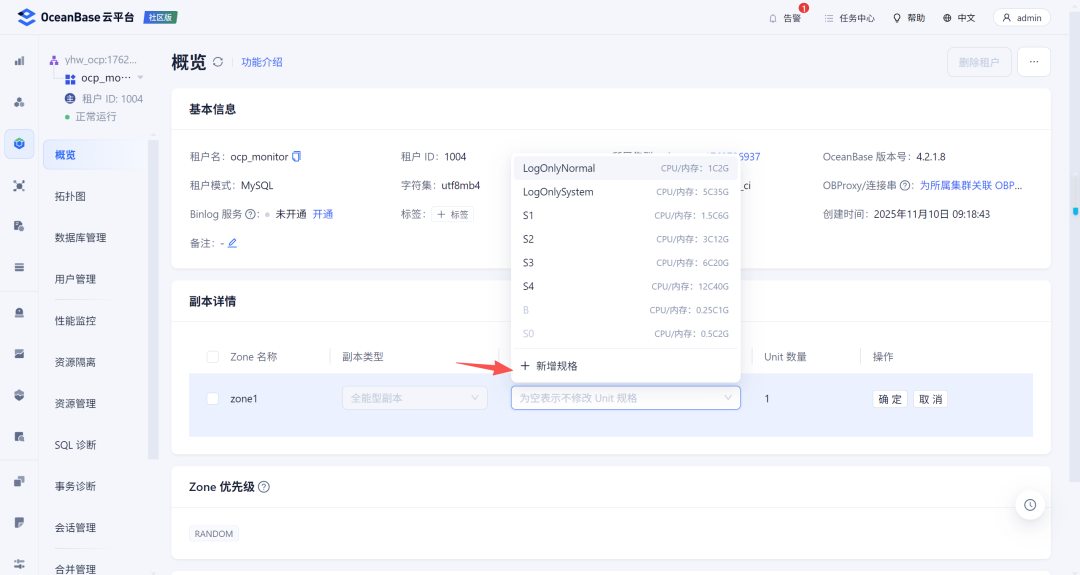
image.png
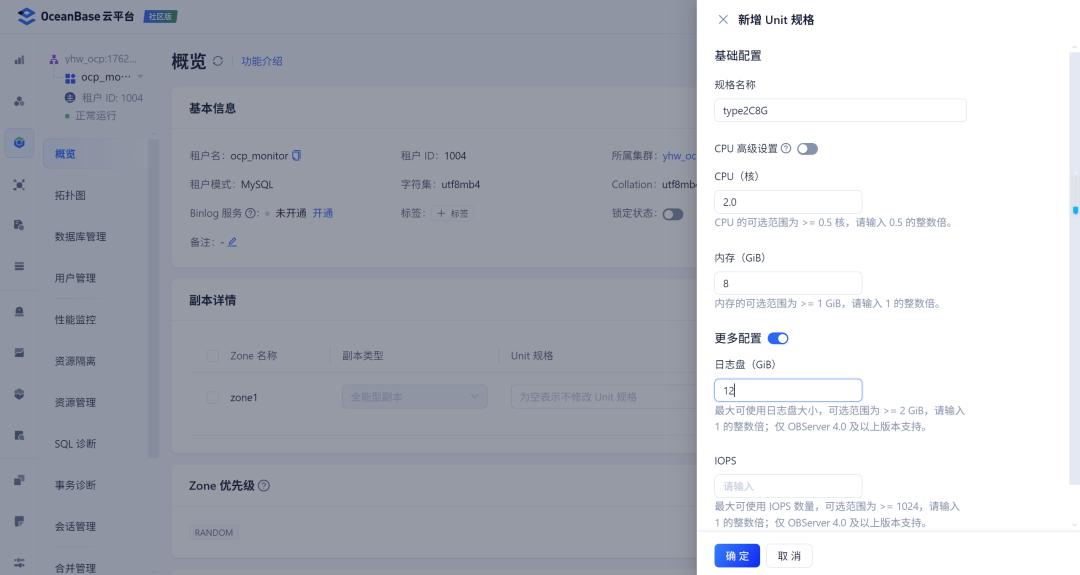
image.png
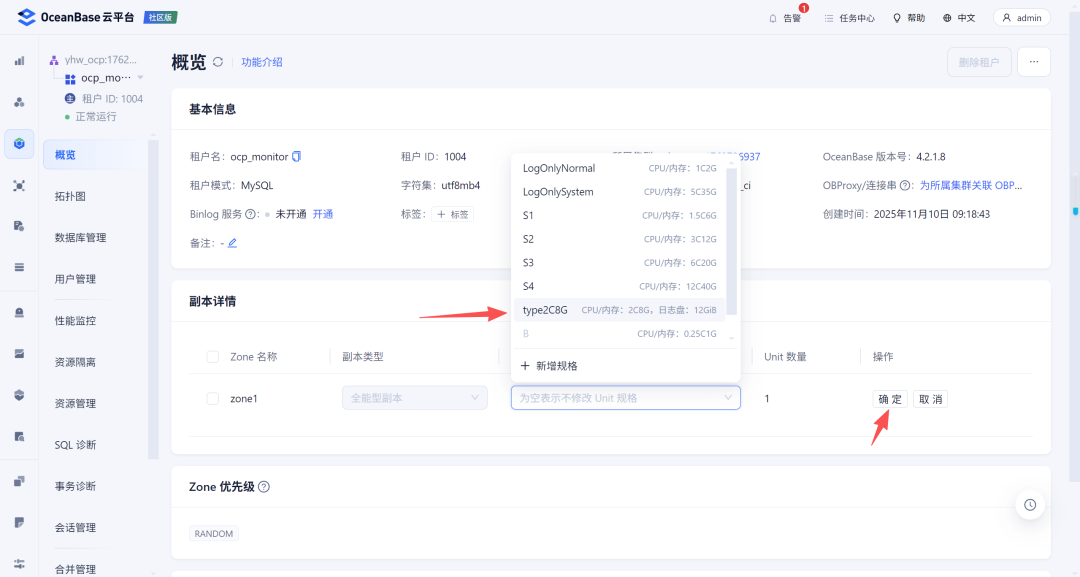
image.png
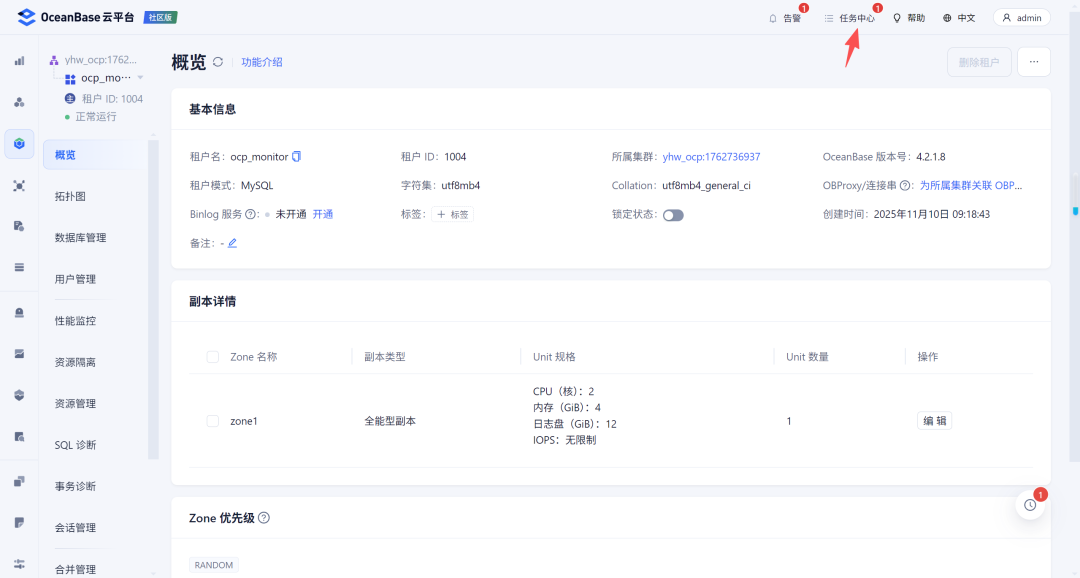
image.png
image.png
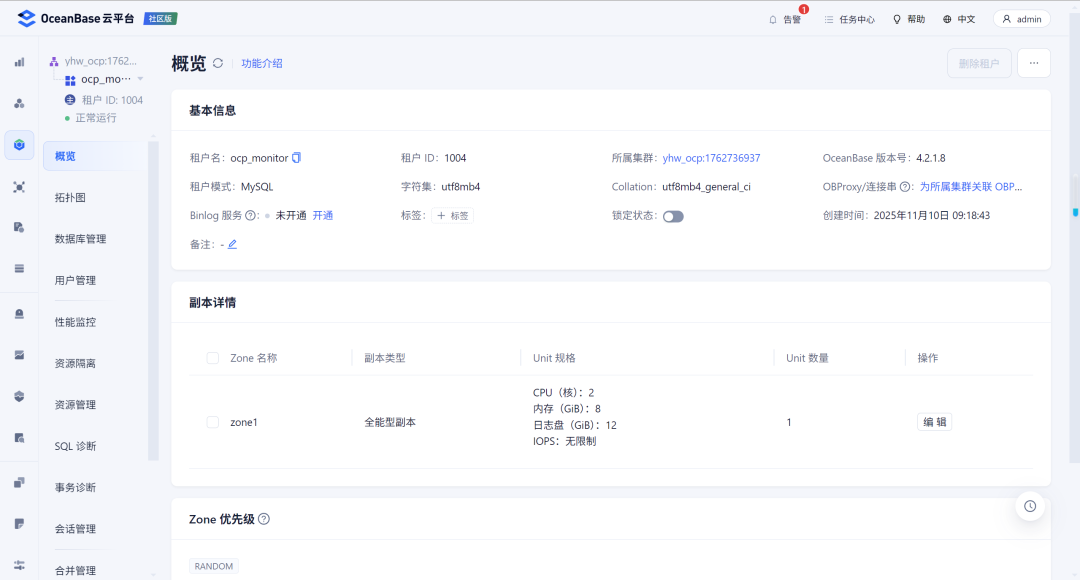
image.png
调整完成后MetaDB的内存分配如下:
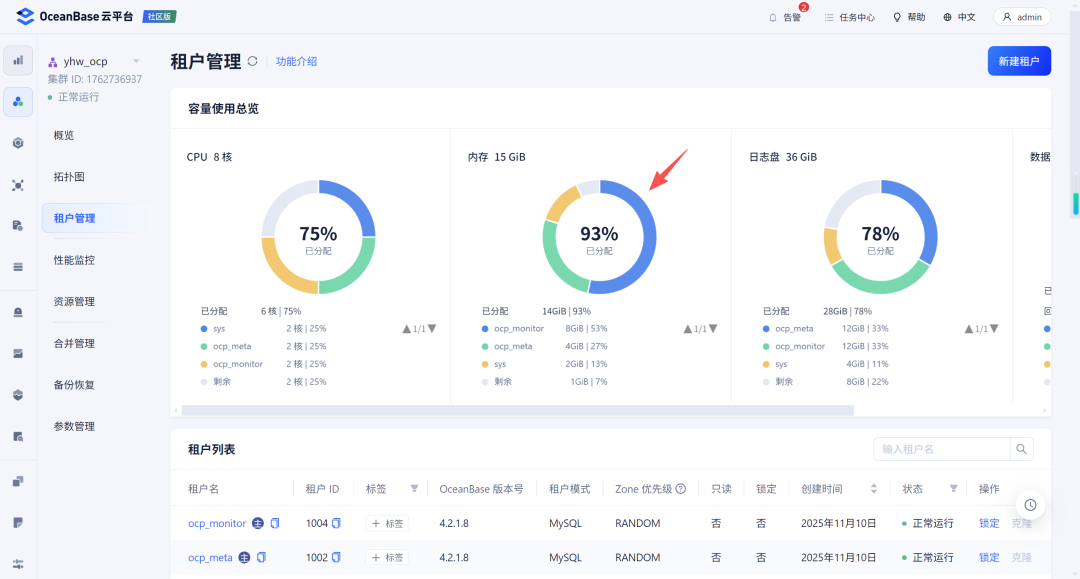
image.png
3 其他小问题
在上一篇文章,某个发布平台的评论中还发现了一个小的默认书写错误:
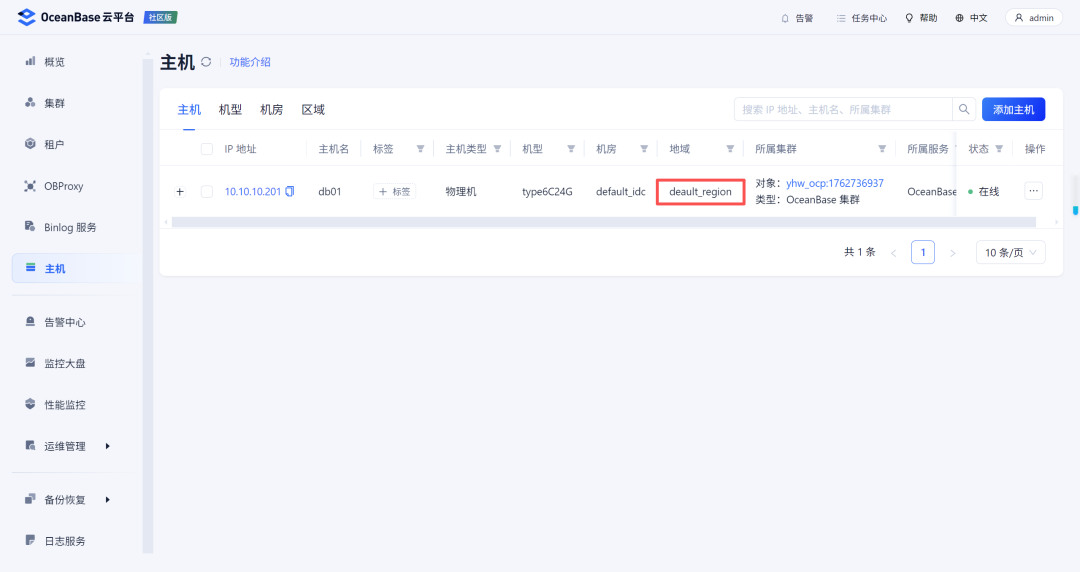
3f70b6d5d6dc958d4856114c918736d1.png
default少了个f。
总结
本文浅浅吐槽了一下OCP部署中MetaDB内存配置的问题。 老规矩,知道写了些啥。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号